任务目标
基于给定数据集,采用三层bp神经网络方法,编写程序并构建分类模型,通过给定特征实现预测的书籍评分的模型。
选取数据
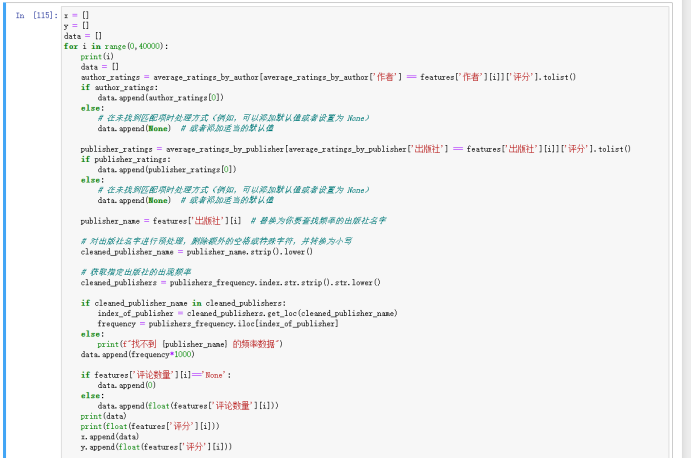 在各项指标中,我认为书籍的评分和出版社、评论数量还有作者相关,和其他属性的关系并大。所以,对于出版社,我选取了出版社的平均评分和出版社在这个表格中出现的频率作为出版社的评价指标。对于作者选择了平均评分作为指标。此外,选择了前40000条数据作为训练集,考虑到运算的时间成本,后续只选择了剩下20000条数据中的五千条作为测试集。
在各项指标中,我认为书籍的评分和出版社、评论数量还有作者相关,和其他属性的关系并大。所以,对于出版社,我选取了出版社的平均评分和出版社在这个表格中出现的频率作为出版社的评价指标。对于作者选择了平均评分作为指标。此外,选择了前40000条数据作为训练集,考虑到运算的时间成本,后续只选择了剩下20000条数据中的五千条作为测试集。
数据处理
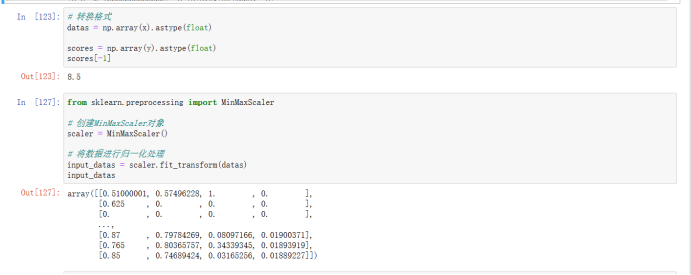 首先将数据转为tensor格式,然后进行归一化操作,既Xnormalized=max(X)−min(X)X−min(X) 这样处理便于训练过程的稳定。
首先将数据转为tensor格式,然后进行归一化操作,既Xnormalized=max(X)−min(X)X−min(X) 这样处理便于训练过程的稳定。
模型构建
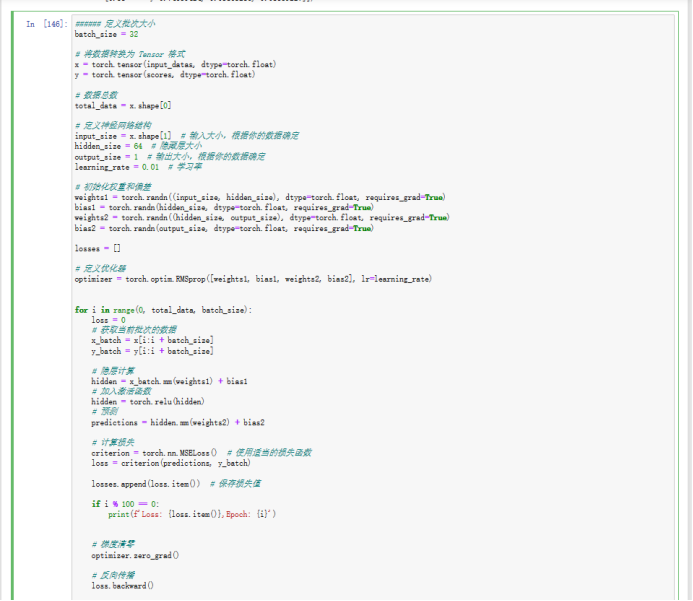 这里构建三层神经网络,中间层设置了64个结点,激活函数采用的是ReLu函数。由于数据规模庞大,选择在一批数据进行训练得到损失值后,再进行一次参数更新,每批次选择32个数据。损失函数选择选择均方误差函数,并且选择随机梯度下降法进行优化。 绘制出损失值变化的折线图
这里构建三层神经网络,中间层设置了64个结点,激活函数采用的是ReLu函数。由于数据规模庞大,选择在一批数据进行训练得到损失值后,再进行一次参数更新,每批次选择32个数据。损失函数选择选择均方误差函数,并且选择随机梯度下降法进行优化。 绘制出损失值变化的折线图 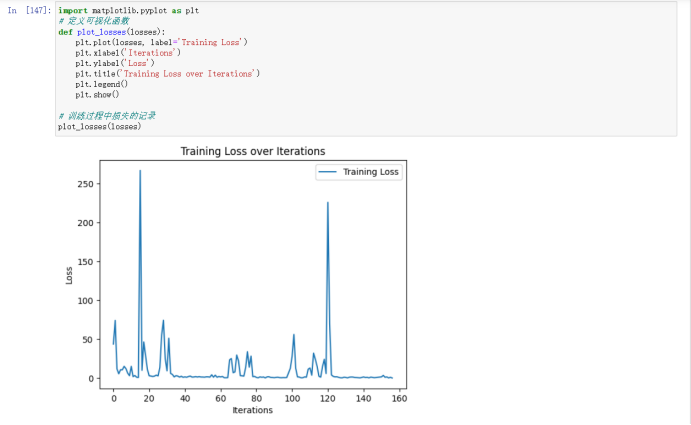
结果评估
 选择5000个数据,将他们放入模型中,计算出他们与真实结果的偏差的和,并求出平均偏差。得到平均的偏差为0.165,说明模型可以正确预测出书本评分
选择5000个数据,将他们放入模型中,计算出他们与真实结果的偏差的和,并求出平均偏差。得到平均的偏差为0.165,说明模型可以正确预测出书本评分
完整代码
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")# In[30]:features = pd.read_csv('book.csv')features['作者'][54101]# In[31]:average_ratings_by_author = features.groupby('作者')['评分'].mean().reset_index()
average_ratings_by_publisher = features.groupby('出版社')['评分'].mean().reset_index()
# 打印每位作者的平均评分
print(average_ratings_by_publisher)# In[32]:# specific_author_rating = average_ratings_by_author[average_ratings_by_author['作者'] == name]['评分']
# a = specific_author_rating.tolist()# In[33]:publishers_frequency = features['出版社'].str.lower().value_counts(normalize=True)
publishers_frequency# In[34]:# 输入你想要查找频率的出版社名字(这里以示例出版社名 '某某出版社' 为例)
publisher_name = 'Harper Collins Publishers ' # 替换为你要查找频率的出版社名字# 对出版社名字进行预处理,删除额外的空格或特殊字符,并转换为小写
cleaned_publisher_name = publisher_name.strip().lower()# 获取指定出版社的出现频率
cleaned_publishers = publishers_frequency.index.str.strip().str.lower()if cleaned_publisher_name in cleaned_publishers:index_of_publisher = cleaned_publishers.get_loc(cleaned_publisher_name)frequency = publishers_frequency.iloc[index_of_publisher]print(frequency)
else:print(f"找不到 {publisher_name} 的频率数据")# In[115]:x = []
y = []
data = []
for i in range(0,40000):print(i)data = []author_ratings = average_ratings_by_author[average_ratings_by_author['作者'] == features['作者'][i]]['评分'].tolist()if author_ratings:data.append(author_ratings[0])else:# 在未找到匹配项时处理方式(例如,可以添加默认值或者设置为 None)data.append(None) # 或者添加适当的默认值publisher_ratings = average_ratings_by_publisher[average_ratings_by_publisher['出版社'] == features['出版社'][i]]['评分'].tolist()if publisher_ratings:data.append(publisher_ratings[0])else:# 在未找到匹配项时处理方式(例如,可以添加默认值或者设置为 None)data.append(None) # 或者添加适当的默认值publisher_name = features['出版社'][i] # 替换为你要查找频率的出版社名字# 对出版社名字进行预处理,删除额外的空格或特殊字符,并转换为小写cleaned_publisher_name = publisher_name.strip().lower()# 获取指定出版社的出现频率cleaned_publishers = publishers_frequency.index.str.strip().str.lower()if cleaned_publisher_name in cleaned_publishers:index_of_publisher = cleaned_publishers.get_loc(cleaned_publisher_name)frequency = publishers_frequency.iloc[index_of_publisher]else:print(f"找不到 {publisher_name} 的频率数据")data.append(frequency*1000)if features['评论数量'][i]=='None':data.append(0)else:data.append(float(features['评论数量'][i]))print(data)print(float(features['评分'][i]))x.append(data)y.append(float(features['评分'][i]))# In[123]:# 转换格式
datas = np.array(x).astype(float)scores = np.array(y).astype(float)
scores[-1]# In[127]:from sklearn.preprocessing import MinMaxScaler# 创建MinMaxScaler对象
scaler = MinMaxScaler()# 将数据进行归一化处理
input_datas = scaler.fit_transform(datas)
input_datas# In[146]:###### 定义批次大小
batch_size = 32# 将数据转换为 Tensor 格式
x = torch.tensor(input_datas, dtype=torch.float)
y = torch.tensor(scores, dtype=torch.float)# 数据总数
total_data = x.shape[0]# 定义神经网络结构
input_size = x.shape[1] # 输入大小,根据你的数据确定
hidden_size = 64 # 隐藏层大小
output_size = 1 # 输出大小,根据你的数据确定
learning_rate = 0.01 # 学习率# 初始化权重和偏差
weights1 = torch.randn((input_size, hidden_size), dtype=torch.float, requires_grad=True)
bias1 = torch.randn(hidden_size, dtype=torch.float, requires_grad=True)
weights2 = torch.randn((hidden_size, output_size), dtype=torch.float, requires_grad=True)
bias2 = torch.randn(output_size, dtype=torch.float, requires_grad=True)losses = []# 定义优化器
optimizer = torch.optim.RMSprop([weights1, bias1, weights2, bias2], lr=learning_rate)for i in range(0, total_data, batch_size):loss = 0# 获取当前批次的数据x_batch = x[i:i + batch_size]y_batch = y[i:i + batch_size]# 隐层计算hidden = x_batch.mm(weights1) + bias1# 加入激活函数hidden = torch.relu(hidden)# 预测predictions = hidden.mm(weights2) + bias2# 计算损失criterion = torch.nn.MSELoss() # 使用适当的损失函数loss = criterion(predictions, y_batch)losses.append(loss.item()) # 保存损失值if i % 100 == 0:print(f'Loss: {loss.item()},Epoch: {i}')# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 梯度裁剪
# torch.nn.utils.clip_grad_norm_([weights1, bias1, weights2, bias2], max_grad_norm)# 参数更新optimizer.step()# In[147]:import matplotlib.pyplot as plt
# 定义可视化函数
def plot_losses(losses):plt.plot(losses, label='Training Loss')plt.xlabel('Iterations')plt.ylabel('Loss')plt.title('Training Loss over Iterations')plt.legend()plt.show()# 训练过程中损失的记录
plot_losses(losses)# In[149]:x_1 = []
y_1 = []
data_1 = []
for i in range(40000,45000):print(i)data_1 = []author_ratings = average_ratings_by_author[average_ratings_by_author['作者'] == features['作者'][i]]['评分'].tolist()if author_ratings:data_1.append(author_ratings[0])else:# 在未找到匹配项时处理方式(例如,可以添加默认值或者设置为 None)data_1.append(None) # 或者添加适当的默认值publisher_ratings = average_ratings_by_publisher[average_ratings_by_publisher['出版社'] == features['出版社'][i]]['评分'].tolist()if publisher_ratings:data_1.append(publisher_ratings[0])else:# 在未找到匹配项时处理方式(例如,可以添加默认值或者设置为 None)data_1.append(None) # 或者添加适当的默认值publisher_name = features['出版社'][i] # 替换为你要查找频率的出版社名字# 对出版社名字进行预处理,删除额外的空格或特殊字符,并转换为小写cleaned_publisher_name = publisher_name.strip().lower()# 获取指定出版社的出现频率cleaned_publishers = publishers_frequency.index.str.strip().str.lower()if cleaned_publisher_name in cleaned_publishers:index_of_publisher = cleaned_publishers.get_loc(cleaned_publisher_name)frequency = publishers_frequency.iloc[index_of_publisher]else:print(f"找不到 {publisher_name} 的频率数据")data_1.append(frequency*1000)if features['评论数量'][i]=='None':data_1.append(0)else:data_1.append(float(features['评论数量'][i]))print(data_1)x_1.append(data_1)y_1.append(float(features['评分'][i]))x_1,y_1# In[150]:# 转换格式
datas = np.array(x_1).astype(float)scores = np.array(y_1).astype(float)from sklearn import preprocessing# 特征标准化处理
input_datas = preprocessing.StandardScaler().fit_transform(datas)
scores# In[152]:import torch
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score# 将预处理后的特征数据和标签数据转换为 PyTorch 的 Tensor 格式
x_test = torch.tensor(input_datas, dtype=torch.float)
y_test = torch.tensor(scores, dtype=torch.float)
total_loss = 0for i in range(0, total_data, batch_size):# 获取当前批次的数据x_batch = x_test[i:i + 1]y_batch = y_test[i:i + 1]# 隐层计算hidden = x_batch.mm(weights1) + bias1# 加入激活函数hidden = torch.relu(hidden)# 预测predictions = hidden.mm(weights2) + bias2# 计算损失criterion = torch.nn.MSELoss() # 使用适当的损失函数loss = criterion(predictions, y_test) # 这里的 predictions 和 labels 是每个批次的预测值和真实标签# 将损失值累积到 total_loss 变量中total_loss += loss.item()
print(total_loss/5000)
本文由博客一文多发平台 OpenWrite 发布!