时序图聚类关联算法
A time resolved clustering method revealing longterm structures and their short-term internal dynamics
一种揭示长期结构及其短期内动力学的时间分辨聚类方法
arxiv2019
源码:
https://github.com/t4d-gmbh/MajorTrack/tree/master
https://github.com/j-i-l/pyAlluv/tree/master
摘要简介
摘要
挑战:跨时间识别模式
贡献:检测动态集群的新方法
- 基于对不同时间片之间多数重叠的自适应识别;
- 适应其他持久动态集群中的瞬态分解
优势:
- 能够检测具有内部动态的持久结构元素
- 可以应用于任何可分类的数据
背景
“数据聚类问题”——聚类可以应用于非关系数据和关系数据(图)
- 非关系数据中,聚类旨在根据某种相似性度量对数据源进行分组。
- 在关系数据中,聚类——也称为社区检测——侧重于识别在内部更密集连接的数据源集
时间数据:每个数据源可能对数据集贡献几个数据点,每个数据点都有不同的时间戳。——这种时间信息可以描绘系统的演变
典型的时间类型关系数据:社交媒体、移动订阅网络、共同作者关系
相关研究
两类名称:
- 进化聚类(evolutionary clustering)
- 动态社区检测(dynamic community detection)
常用分析方法:
时间数据表现为一系列快照(snapshot)的形式,对于关系型数据,叫做时间窗口图(time-window graphs)
——在单个快照中,单个数据源最多表现为与单个数据点,若有多个点,则采用聚合的形式表达。
-
优点:可以使用传统聚类分析方法
-
缺点:在聚合窗口中丢失有关数据源的所有时间信息
对时间快照的处理:
-
适应快照表示(如创建联合图)或 使用静态聚类的度量,或两者兼顾——
常见方案:定义规则来组合一系列静态聚类:自组织进化聚类(Ad hoc evolutionary clustering)——选用任意静态算法,更通用
方法简介
定义:
动态集群(dynamic clusters DCs):可能在几个快照上持续存在的集群(理想情况下是先验定义的)
方法:提出了一种特殊进化聚类方法来检测时间数据中的 DC
- 非常灵活,它只需要时序聚类结果,可以通过任何应用于关系或非关系数据的聚类方法来生成
- 利用多数作为检测 DC 的基础,允许调整时间尺度
- 允许捕获和研究短寿命的变化,例如簇内的自然波动、小扰动或小尺度过程,而不会在较长时间尺度上破坏动力学的轨迹
- 适用于“活”数据集,即具有连续生成的数据
下文:剖析 DC 的生命周期事件、指定了一组明确定义了健壮 DC的属性
动态集群的生命周期
DC 由一组数据源组成。我们将这些数据源称为 DC 的成员
六个基本事件:出生、死亡、生长、收缩、分裂和合并
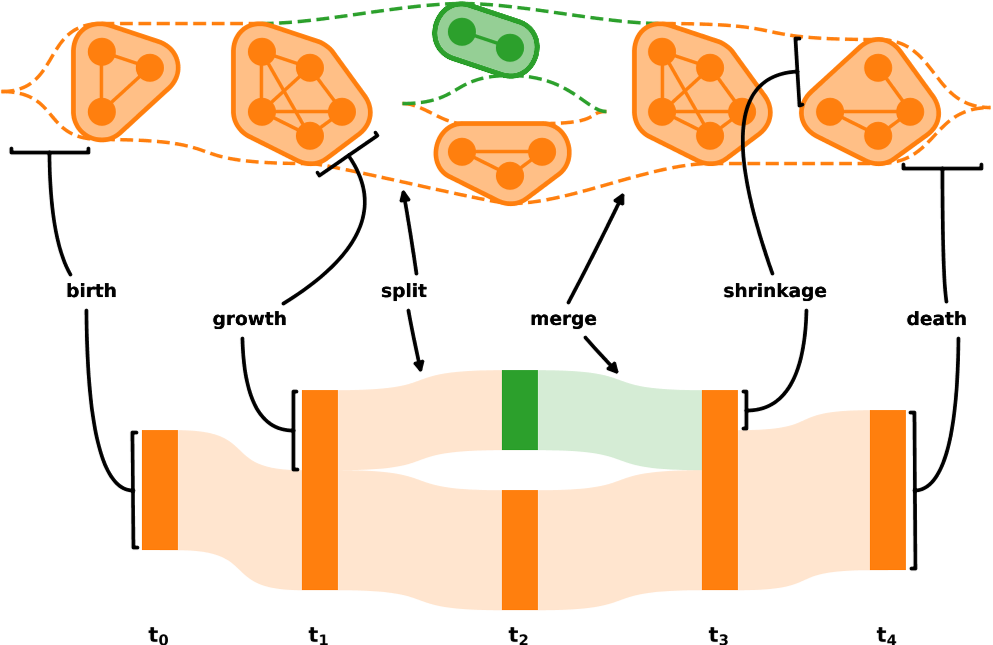
需要一组明确定义的规则来稳健地将观察到的模式与这些生命周期事件联系起来。
上半部分:动态集群演化,封闭的节点集对应于集群,颜色表示相关的 DC。虚线是随着时间的推移跟踪当前 DC 的视觉指南。
下半部分:冲击图(Alluvial diagram),每个块对应一个集群。块的高度代表簇的大小,宽度没有特定的含义。块之间的流说明了数据源如何在时间点之间重新分配。流入和流出的块高度对应于加入和删除的数据源数量。
稳定动态集群的定义
相邻快照间
简单直观的原则:基于多数的关联——集群成员的最大分数是过去或未来的其他一些点
方法:使用基于双射多数的关系——来自相邻时间点的集群彼此的最大成员比例相互保持,作为识别 DC 的第一个标准。
持久性和连续性
倾向于将 DC 识别为在几个连续的时间点上作为相关集群出现的数据源集
许多真正的系统容易产生不连续但持久的结构。
使用术语同质不连续性(homogeneous discontinuities)来描述 DC 短暂分解为子单元的情况,例:社会系统中的裂变融合模式
具有同质不连续性的两个基本模式:分裂(splintering)和转变(transitioning)
- 分裂:DC 的成员在时间上被分成几个子集群
- 转变:成员逐渐添加到 splinter 子集群,直到所有成员都已转换;不断增长的 splinter 集群有效地成为初始 DC
——两个事件都必须是短暂的(根据具体情况定义时间尺度),否则初始 DC 不能被认为持续存在。
下图说明了时间尺度限制中的两个极端选择如何影响 DC 的检测
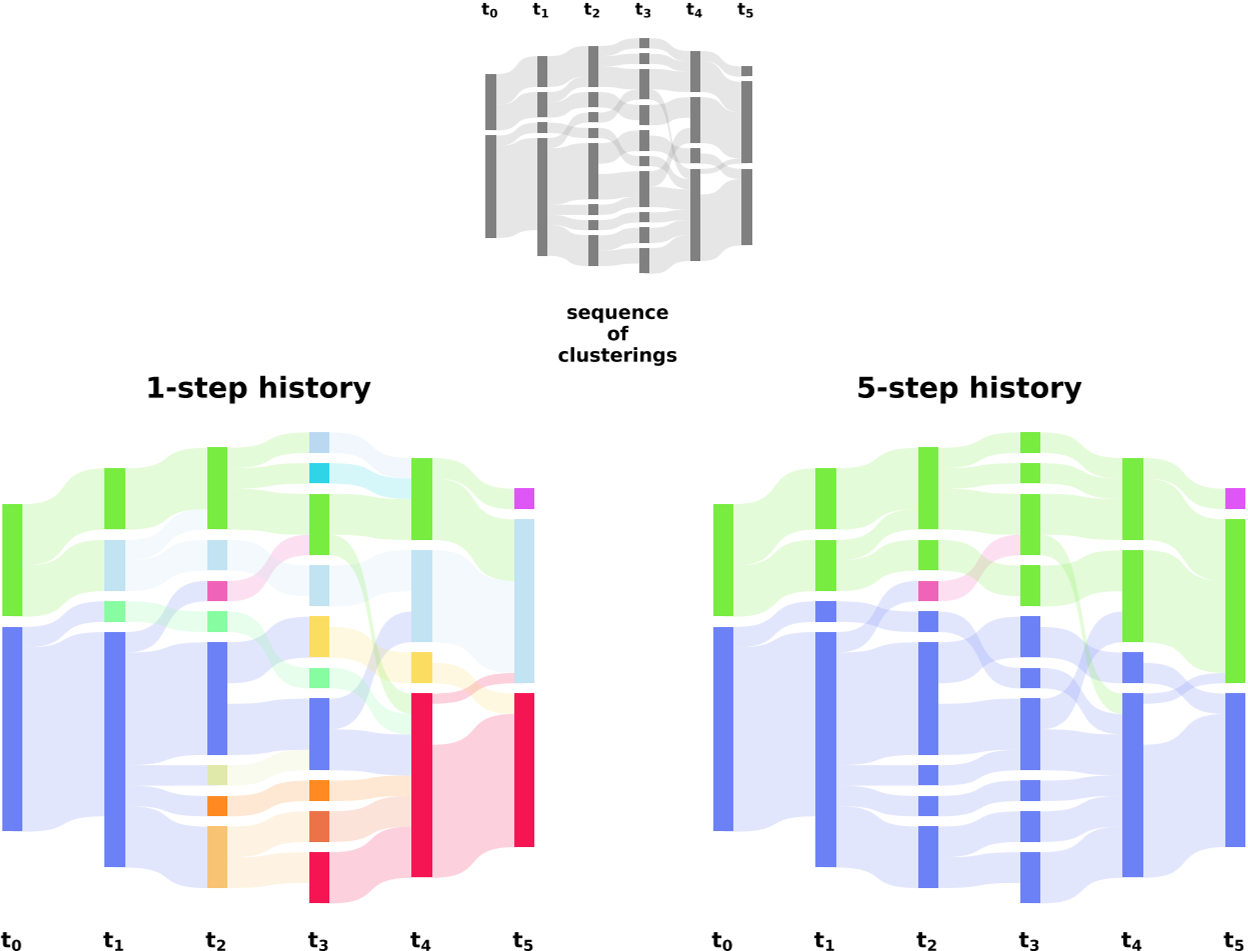
- 顶部:表示集群演化的冲积图——下方是两个极端,每种颜色代表一个DC
- 左边:DC 连续性条件——整个生命周期中任意连续存在;集群的关联基于相邻时间点之间的简单双射多数规则
- 右边:连续性的条件被放宽——必须在有限数量的时间点内检测到特定的 DC(5个);关联标准仍然基于双射多数规则,但可以推广到遥远的时间点。
定义一个动态集群的特征组:
- 基于多数:相互持有彼此最大成员分数的集群应该属于同一个 DC。
- 渐进增长:DC必须基于现有数据,并且能够将新生成的数据合并到现有结构中——DC只可能基于当前和历史数据。
- 对高转换率具有鲁棒性:对数据集中数据源引入和消失的最小依赖性——DC仅遵循结构变化,不受数据源的周转支配。
- 结构一致:最近的 DC 结构应该始终与该快照中检测到的聚类一致。
- 抵抗同质不连续:同质不连续的持久结构仍应被识别为 DC。
- 对不连续时间尺度的敏感性:不连续被认为是瞬态的时间尺度是特定于上下文的,因此需要适应。
渐进式检测算法:
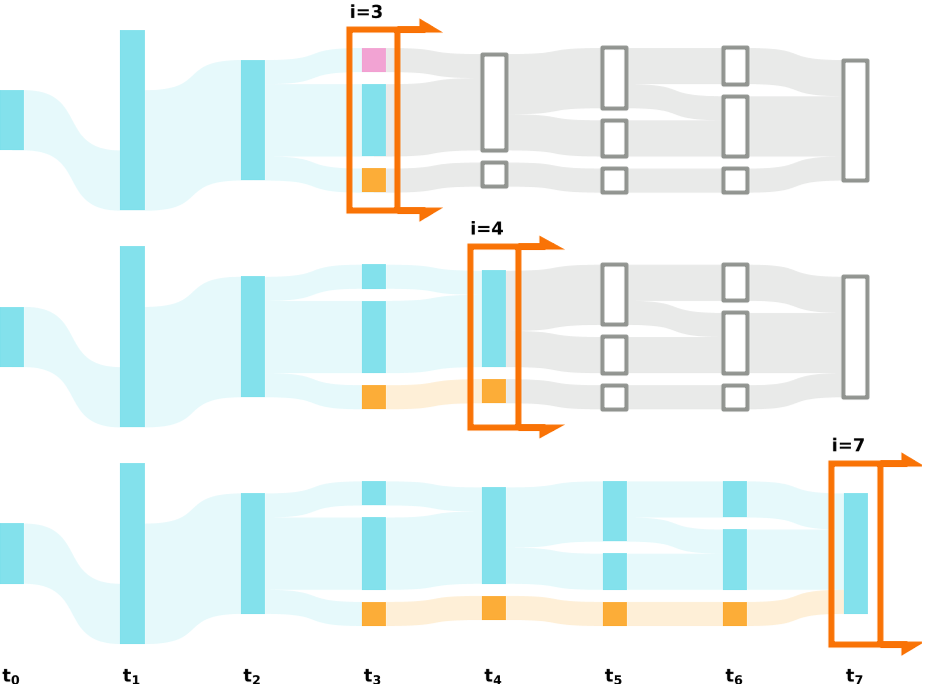
——算法在观察时的状态使用橙色箭头框表示,并由时间索引 i 指定。
定义的特征如下所示:
- 基于多数:ti 时刻现有 DC 的簇关联基于与早期时间点集群的双射多数匹配(第四节说明)。
- 渐进性:灰色元素对应于未来的数据,因此与 DC 检测算法无关。
- 对周转的鲁棒性:DC的剧烈尺寸波动(例如,从 t1 到 t2 的增长超过 100%,t2 和 t3 之间的收缩)不应影响 DC 的识别。
- 结构一致性:算法应该生成与当前聚类一致的 DC 结构。算法当前阶段的每个集群都有一个单独的颜色,如步骤 i = 3 所示。
- 分裂集群弹性:从 i = 3 识别的三个 DC 中,最顶部的集群在 i = 4 处回顾性识别为 splinter 子集群,因此被重新集成到蓝色 DC 中。
- 转换弹性:在第 i = 5 阶段,蓝色 DC分裂。在阶段 i = 7 ,分裂集群完全吸收了 DC 的其余部分,有效地重新组合了它。
- 瞬态不连续:在 i = 3 的两个较小的 DC 中,只有上(粉红色)被归类为 splinter。橙色的保持不变,直到 t7 合并进蓝色 DC 中,因此本身被视为 DC。
一种新的自组织进化聚类方法
关联相邻的快照
从不同时间点识别集群的大多数公共部分将确定 DC 的机械定义。
-
从连续的快照中评估两个集群的相似性:
-
使用共享成员的比例,只考虑驻留成员
-
将两个簇的交集大小分别除以另一个簇的数量——不受成员周转影响的相似性度量
-
可以看作众所周知的指标:Jaccard系数的非对称变化
f i m ( g i − 1 , α , g i , β ) = ∣ g i − 1 , α ∩ g i , β ∣ ∣ g i − 1 , α ∪ g i , β ∣ f i m → ( g i − 1 , α , g i , β ) = ∣ g i − 1 , α ∩ g i , β ∣ ∣ g i − 1 , α ∣ f i m ← ( g i − 1 , α , g i , β ) = ∣ g i − 1 , α ∩ g i , β ∣ ∣ g i , β ∣ , \begin{aligned}fim\left(g_{i-1, \alpha}, g_{i, \beta}\right) & =\frac{\left|g_{i-1, \alpha} \cap g_{i, \beta}\right|}{\left|g_{i-1, \alpha} \cup g_{i, \beta}\right|} \\fim_{\rightarrow}\left(g_{i-1, \alpha}, g_{i, \beta}\right) & =\frac{\left|g_{i-1, \alpha} \cap g_{i, \beta}\right|}{\left|g_{i-1, \alpha}\right|} \\fim_{\leftarrow}\left(g_{i-1, \alpha}, g_{i, \beta}\right) & =\frac{\left|g_{i-1, \alpha} \cap g_{i, \beta}\right|}{\left|g_{i, \beta}\right|},\end{aligned} fim(gi−1,α,gi,β)fim→(gi−1,α,gi,β)fim←(gi−1,α,gi,β)=∣gi−1,α∪gi,β∣∣gi−1,α∩gi,β∣=∣gi−1,α∣∣gi−1,α∩gi,β∣=∣gi,β∣∣gi−1,α∩gi,β∣,
-
-
确定相邻快照中最相似的集群:使用双射多数匹配,即集群是其自身映射集群的跟踪集群,作为将连续快照中的两个集群相互关联并最终关联到同一个 DC 的条件。
——后面的集群可以追溯多个历史集群,所以在识别双射多数匹配时考虑集群集合。
对远间隔时间片之间关系的概括
- 先识别出一个簇集合(它形成一个双射多数匹配),再逐步将集群与该集合中的集群相关联
- 迭代地在连续时间点之间进行匹配,进行几个时间快照之后,构造跟踪路径和反向的映射路径(tracing path、mapping path)
- 如果在某个深度或递归下,集群的跟踪路径等同于该集合,并且来自集合的映射路径将集合等同于后面的集群作为其唯一成员,则集群与较早时间点的一组集群形成双射多数匹配。
- 可以用参数的形式限制匹配的最长时间,确定跟踪和映射路径的最大递归深度
- 该参数允许将限制设置为 DC 进程内的持续时间
- 通过比较在不同该参数的限制下生成的 DC 结构来研究数据中存在的瞬态分解类型
集群总是至少与自身形成双射多数匹配,如果集群与早期快照中的集群集形成双射多数匹配,我们将集群与最早的源集(source set)的 DC 相关联。
目标集群的身份流(identity flow):跟踪路径和映射路径中的所有集群的组合可以看作是 DC 的身份随时间传播的簇集序列
如下图所示,跨越两个以上的快照的身份流可以包含集群集序列,些嵌入序列必然短于识别流的最大长度,并满足我们的瞬态齐次不连续条件。因此,我们将属于嵌入序列的簇识别为嵌入 DC 的边缘部分。
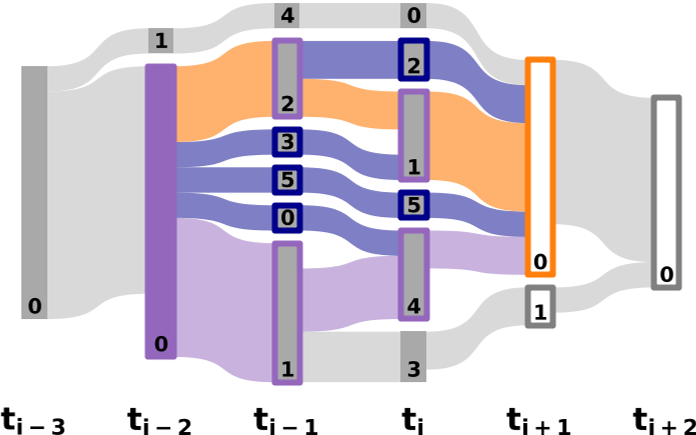
DC集群关联(考虑3步历史信息)——算法过程的可视化说明
-
橙色框是 ti+1 处的目标集群,它将与 ti-1 处集群源集的 DC 相关联(紫色部分)
-
给定历史参数,源集被定义为双射匹配的最早候选集(0)
-
以橙色突出显示的通量显示了目标集群的跟踪流
-
紫色突出显示的通量描述了来自源集的映射流——这些通量称为恒等流
-
蓝色着色的通量指定跟踪或映射路径,这些路径专门连接到来自身份流的集群——这些通量对 DC 的身份传播没有贡献,因此称为边际流
动态集群的定义
DC 定义为一组簇满足以下条件之一:
- 都有一个身份流,其中源集包含在 DC 中;
- 包含在属于 DC 的簇的身份流中;
- 是簇的一部分,由属于 DC 的其他簇的识别流边缘化
聚类源集的识别以双射多数匹配的最大长度为条件,该匹配必须通过方法的参数化先验确定。
算法程序
遍历快照序列,从最早的时间点开始,为当前快照中的每个集群执行两个不同的任务:
- 将集群及其身份流中的所有集群与其源集的 DC 相关联。
- 根据身份流引起的边缘化,从先前的时间步中纠正现有的 DC 聚类关联。
设置参数来确定该过程如何及时确定目标集群的源集。
——该参数可以被认为是该方法的历史视界,必须以时间步数给出。此后,我们将该方法的特定配置称为 x 步历史(x-step history),其中 x 指定算法在时间上回溯的快照数量。
附录 表1 算法详细步骤
在时间序列 t0 开始时,所有当前集群都与新创建的表示不同集群的 DC 相关联。
- 从尚未与 DC 关联的时间步 ti+1 中选择一个目标集群。
- 确定目标集群的跟踪集。如果目标集群的跟踪集的映射集是目标集群,则可以构造一个跟踪流。如果没有,目标集群与新创建的 DC 相关联。
- 迭代构造跟踪流:在每次迭代中识别跟踪流中最后一组的下一个跟踪集。如果下一个跟踪集有一个映射流,该映射流位于跟踪流中包含的某个时间点,则将其添加到跟踪流中。
- 跟踪流要么在没有进一步的跟踪集的情况下结束,要么终止在历史限制处或时间序列中的第一个时间点t0。
- 沿着跟踪流识别所有潜在的源集。
- 确定源集:从最早的潜在源集开始并检查源集中的组是否属于单个 DC。如果没有潜在的源集满足条件,则为目标集群创建一个新的 DC 身份。
- 识别身份流,即来自目标集群的跟踪流和源集的映射流的所有集群。
- 迭代地确定源集的跟踪流(tracer flow)直到ti+1。跟踪流中的下一组由上一组的示踪集给出,从源集开始。
- 迭代地确定目标集群的映射流(mapper flow)直到源集的时间点。映射流中的下一个集合由前一个集合的映射集给出,从仅包含目标簇的集合开始。
- 在每个时间步,计算跟踪(第 7 阶段)和映射(第 8 阶段)流的集合之间的交集。确定边缘簇,即不属于身份流的交叉点中的簇(从第 6 阶段)。
- 将身份集群(来自阶段 6)和边缘集群(从第 9 阶段)与源集的 DC 相关联。
进化聚类的一致性
质量评估的一个更客观的方法是探索时间点成员的自相关:
C ( i ) = ∣ c i ∩ c i + 1 ∣ ∣ c i ∪ c i + 1 ∣ C(i)=\frac{\left|c_i \cap c_{i+1}\right|}{\left|c_i \cup c_{i+1}\right|} C(i)=∣ci∪ci+1∣∣ci∩ci+1∣
其中ci和ci+1分别是 c 在时间点i,i + 1在DC中的成员集合,|x|表示集合x的基数。
——也称为 Jaccard 指数,表示当前所有成员中相同成员的比例
我们将动态聚类的总一致性定义为平均自相关:
C t o t = ∑ c ∈ D C ∑ i = 0 n − 1 ∣ c i ∩ c i + 1 ∣ c i ∪ c i + 1 ∣ ∣ ∑ c ∈ D C ∣ c ∣ − ∣ D C ∣ C_{t o t}=\frac{\sum_{\mathbf{c} \in \mathbf{D C}} \sum_{i=0}^{n-1} \frac{\left|c_i \cap c_{i+1}\right|}{c_i \cup c_{i+1} \mid} \mid}{\sum_{\mathbf{c} \in \mathbf{D C}}|\mathbf{c}|-|\mathbf{D C}|} Ctot=∑c∈DC∣c∣−∣DC∣∑c∈DC∑i=0n−1ci∪ci+1∣∣ci∩ci+1∣∣
其中 n 是快照的总数,DC 是所有动态集群的集合,|c| DC 中存在的快照c的数量。
——此定义不包括创建和销毁事件,因此,它表明了现有结构的整体一致性。
——此处没有指定最大时间步参数,在此情况下该准则最合适。
用例
- 美国参议员对美国整个历史的投票行为——用作测试用例
- 一组自由范围房屋小鼠的接触结构
-
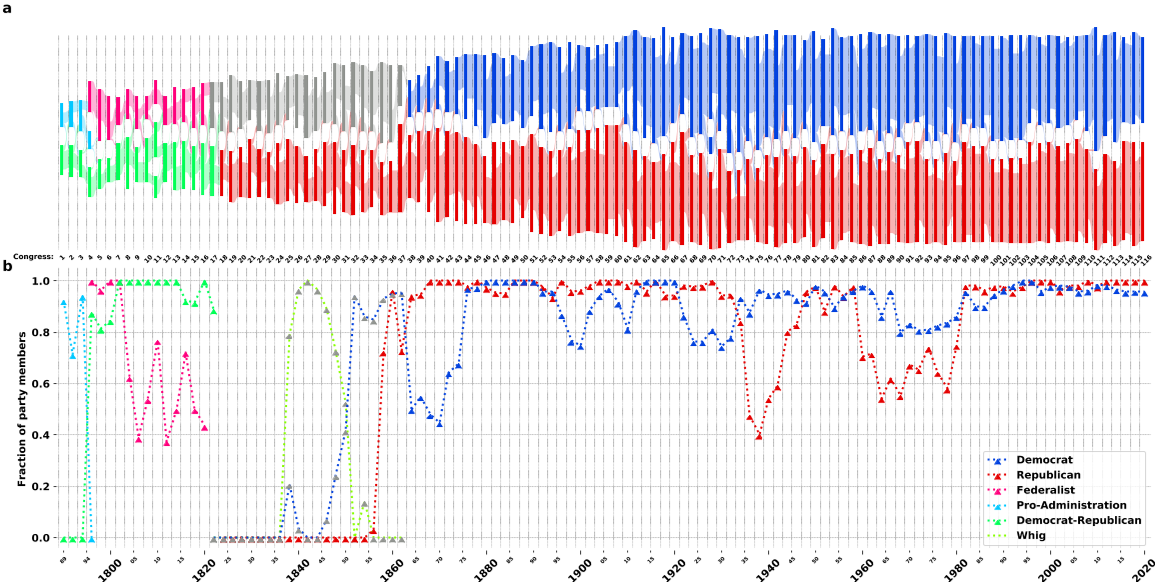
议员投票:
- 每个国会作为该序列中的时间点。为了为单个国会创建关系数据集
- 将国会期间两个参议员之间的连接强度定义为所有场合中相同选票的比例
结果:
- 除了极少数例外(第 4、11 和第 70 个国会),每个国会始终有两个投票社区。
- 从美国参议院的第 38 个国会基本上被划分为相同的两个动态投票社区。
- 双方系统在近 170 年的时间里主导着国会
- 一些行为与历史事件的印证
-
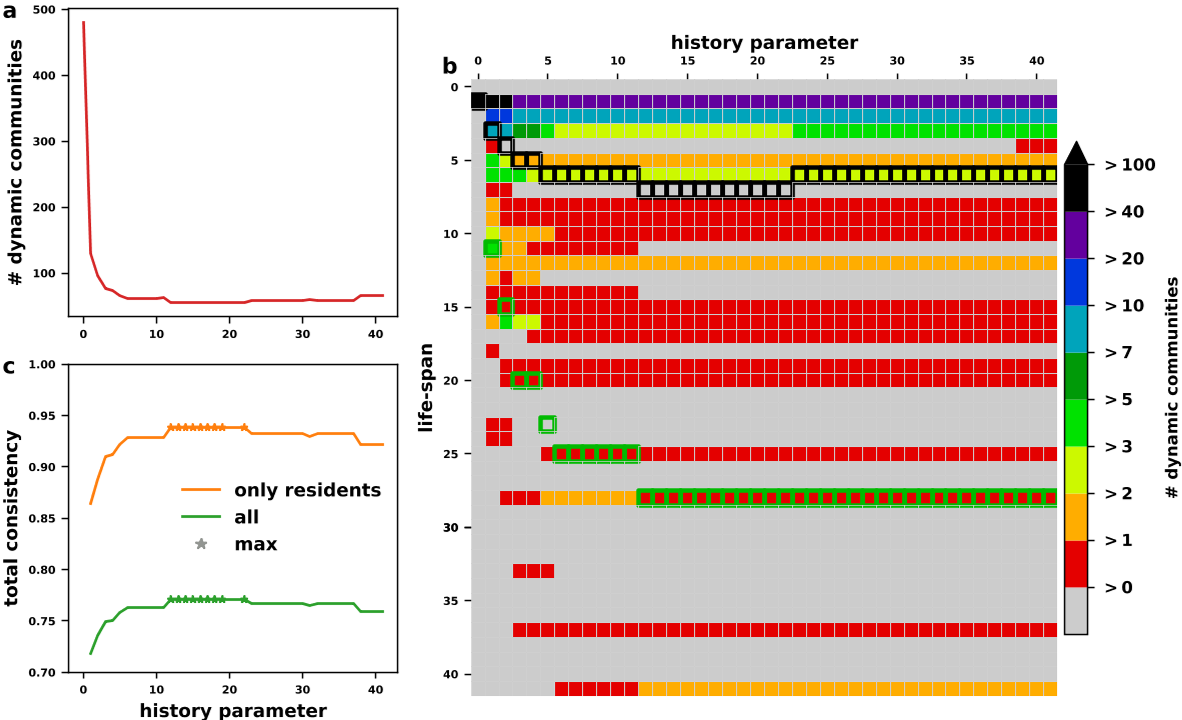
野生家鼠的社会网络分析
- 将小鼠用芯片标记,使用社区检测算法对每个时间片进行聚类
- 分析历史参数的不同值如何影响动态聚类结构
结果:
- 虽然不同的动态社区的数量在 0 到 5 步的参数范围内急剧下降,但对于更高的值,它仍然非常稳定。
- 超过 5 个时间步长(即超过 70 天)的齐次不连续性很少见,但发现有少数大于 5 个时间步长的动态社区持续存在。
- c 显示了历史参数应用范围的总一致性分数。参数范围从 12 到 22 步最大,这也对应于寿命的一系列一致分布。
讨论
提出了一种算法,该算法在一系列时间戳数据的快照中检测动态集群 (DC)。
- DC的生命周期:形成、消失、收缩、增长或短暂拆分和合并
- 仅依赖于集群关联的时间序列,因此与任何非关系和关系数据的聚类方法兼容——自定义聚类算法
- 具有数据集大小的有效可扩展性,不太可能作为时间数据分析中的计算瓶颈
定义了动态集群的特征,明确如何衡量两个集群更相似。
定义了总一致性度量,不仅允许客观地参数化新方法而且允许定量地比较不同的动态聚类。
允许在较长时间尺度上存在的动态集群中检测瞬态齐次分解。