深度学习(24)——YOLO系列(3)
文章目录
- 深度学习(24)——YOLO系列(3)
- 1. BOF(bag of freebies)
- 2. Mosaic data augmentation
- 3. 数据增强
- 4. self-adversarial-training(SAT)
- 5. dropblock
- 6. label smoothing
- 7. 损失函数
- a. IOU损失
- b.GIOU
- c. DIOU
- d.CIOU
- 8. SPPNet(spatial pyramid pooling)
- 9. CSPNet(cross stage partial network)【更快】
- 10.CBAM & SAM
- 11.YOLO中的attention链接机制
- 12. PAN
- 13. PAN的连接方式
- 14. 激活函数
- 15. 网络结构
- 16.优点
今天YOLOv4理论版
1. BOF(bag of freebies)
- 只增强训练成本,但是能显著提高精度,但是不影响推理速度
- 数据增强:调整亮度,对比度,色调,随机缩放…
- 网络正则化的方法:dropout,dropblock
- 类别不平衡——>损失函数设计
2. Mosaic data augmentation
- 参考cutmix,以前就存在,将增强的四张图像拼接在一张进行训练(相当于间接增加batch)
3. 数据增强
- random erase:随机遮挡或擦除
- hide and seek:根据概率随机隐藏补丁
4. self-adversarial-training(SAT)
- 在原始图像中增加噪音点干扰
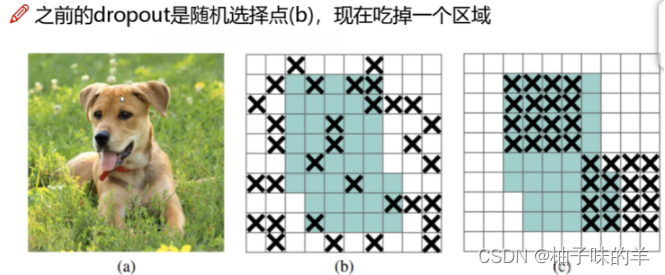
5. dropblock
dropout是随机选择一些点遮住(游戏难度增加不大),dropblock现在遮住一个区域(游戏难度增大)
6. label smoothing
- 神经网络最大的缺点,标签绝对,容易过拟合
- 使用之后,簇内更紧密,簇间更分离
7. 损失函数
a. IOU损失
- 相同的IOU却反映不出实际情况到底是怎么样的
- 当交集为0时,没有梯度无法计算(梯度消失)
b.GIOU
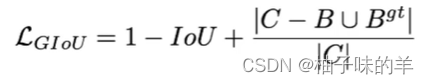
- 引入最小封闭框C(C可以把A,B包含在内)
- 在不重叠的情况下可以使预测框尽可能靠近真实框
- 解决了梯度下降的问题,但是重叠的时候失灵
c. DIOU
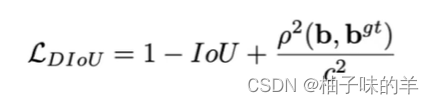
- 附加项的分子项:预测框与真实框中心点的欧氏距离
- 附加项的分母项:最小封闭框的对角线长度C
- 直接优化距离,速度更快,并解决GIOU
d.CIOU
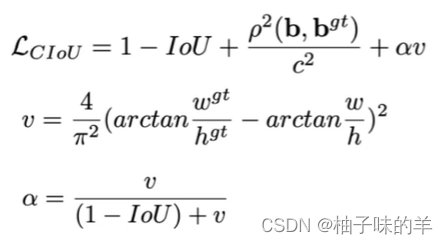
-
考虑三个几何因素:
- 重叠面积
- 中心点距离
- 长宽比(v)
8. SPPNet(spatial pyramid pooling)
- 为了更好满足不同输入大小,训练的时候要改变输入数据的大小
- SPP其实就是用最大池化来满足最终输入特征一致即可
9. CSPNet(cross stage partial network)【更快】
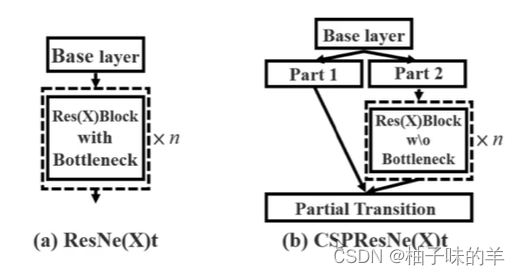
- 每个block 按照特征图的channel维度拆分成两部分
- 一份正常走网络,另一份直接concat到这个block的输出
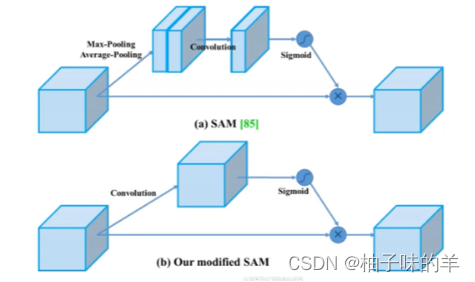
10.CBAM & SAM
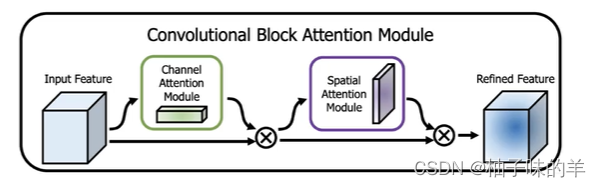
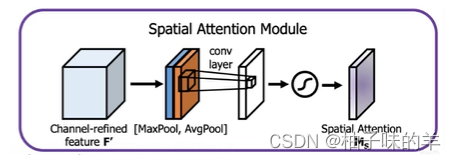
- 计算量太大!所以在V4中,引入SAM ,没有channel之间的attention,只有spatial空间attention(attention可以让模型更好学习特征)
11.YOLO中的attention链接机制
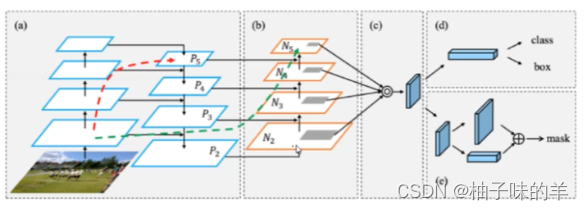
12. PAN
- FPN是自顶向下的模式,将高层特征传下来,高层逐层向下兼容下层(单向)
- 缺少底层到高层,PAN登场
- 引入自底向上的路径,使得底层信息更容易传到顶部
- 还是一个捷径,红色的可能要走100+层,绿色只需要几层就OK
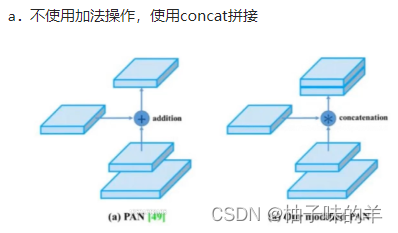
13. PAN的连接方式
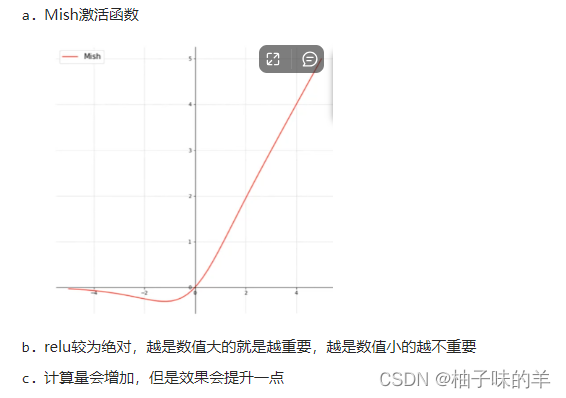
14. 激活函数
15. 网络结构
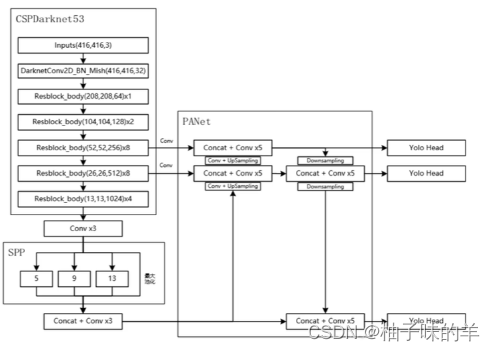
16.优点
- 使用单个GPU就可以训练很好
- 量大核心方法:数据层面+网络层面
- 消融实验
- 速度快,性能高!