分类目录:《深入理解深度学习》总目录
UniLM和XLNet都尝试在一定程度上融合BERT的双向编码思想,以及GPT的单向编码思想,同时兼具自编码的语义理解能力和自回归的文本生成能力。由脸书公司提出的BART(Bidirectional and Auto-Regressive Transformers)也是如此,它是一个兼顾上下文信息和自回归特性的模型。不同的是,UniLM和XLNet的模型结构与BERT基本一致,通过修改训练过程让模型具备了一定的文本生成能力,故模型的主要功能依然是语义理解。BART使用了传统的Transformer结构,不仅继承了BERT的语义理解能力,更展现了强大的序列到序列的文本生成能力。与BERT相比,其改进点如下:
- 使用原始的Transformer Encoder-Decoder作为模型结构,区别于仅使用Transformer Encoder的BERT和仅使用Transformer Decoder的GPT。
- 使用多样化的噪声干扰方式,让模型更注重文本的语义理解而不是结构化信息。
在进行语义理解时,BERT会获得一些额外的结构信息,如被掩码词的位置、序列的长度等,这些格式化的信息会让模型直接利用句式结构信息来辅助语义理解,即削弱模型在训练过程中获得的语义理解能力。BART通过引入自回归训练Decoder和多样化噪声,来降低模型对结构化信息的依赖,更注重对文本的理解。同时,在引入Decoder之后,其文本生成能力得到了极大增强。
算法细节
模型结构
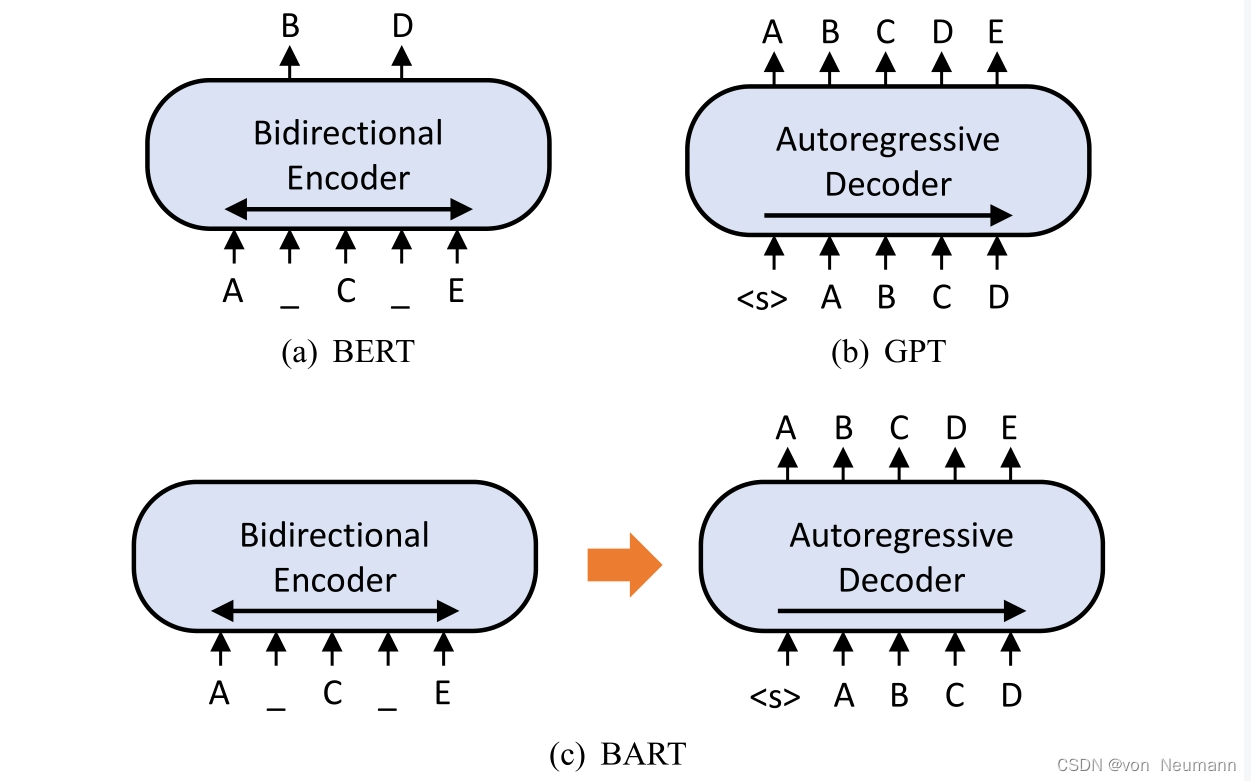
BART使用了原始的Transformer Encoder-Decoder结构,具体模型结构和《深入理解深度学习——Transformer》系列文章中描述的基本一致,唯一的不同在于将激活函数从默认的ReLU改为GeLU。原始的Transformer被提出后用于机器翻译,由于其强大的语义提取能力,GPT将Transformer Decoder作为模型主结构,用于文本生成任务,BERT将Transformer Encoder作为模型主结构,用于文本理解任务。而BART将BERT与GPT合并,即直接使用原始的Transformer结构。三者的模型结构对比如下图所示,下图(a)为BERT的模型结构示意图,其模型结构主体使用双向编码器(Transformer Encoder),输入是带掩码的文本序列,输出是在掩码位置的词;下图(b)为GPT的模型结构示意图,其模型主体使用自回归解码器(Transformer Decoder),输入是正常的句子,输出是每个词的下一个词;下图©是BART的模型结构示意图,其模型主体同时使用双向编码器和自回归解码器(即完整的Transformer结构),输入是带掩码的文本序列,输出是在掩码位置填补预测词的完整序列。
噪声预训练
为了尽可能地减少模型对结构化信息的依赖,BART使用了5种不同的噪声方式进行训练,如下图所示。
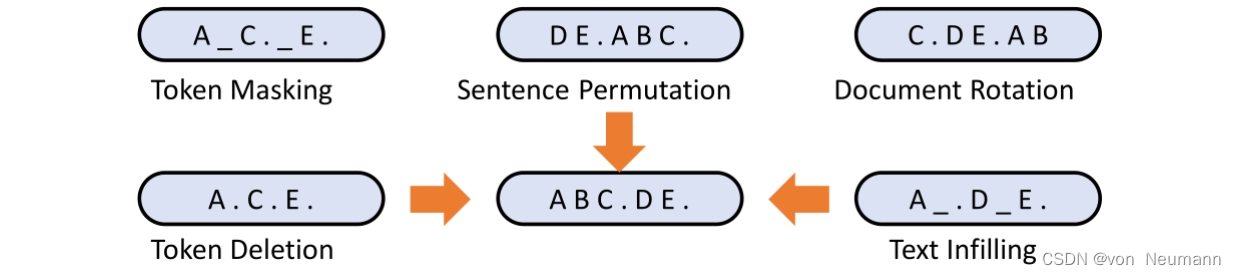
- Token Masking:与BERT一样,将个别词随机替换成
[MASK],训练模型推断单个词的能力 - Token Deletion:随机删除个别词,训练模型推断单个词及位置的能力。
- Text Infilling:将一段连续的词随机替换成
[MASK],甚至可以凭空添加[MASK],训练模型根据语义判断[MASK]包含的词及其长度。 - Sentence Permutation:随机打乱文本序列的顺序,加强模型对词的关联性的提取能力。
- Document Rotation:将文本序列连成圈,随机选择序列的起始词(保留序列的有序性,随机选择文本起始点),以此训练模型识别句首的能力。
值得注意的是,所有的噪声都添加在Encoder的输入文本上。
下游任务微调
-
序列分类任务:序列分类任务的微调改写与GPT的极为相似,即将输出序列最后一个词预测的token作为分类标签进行训练(序列的终止符一般为
<EOS>),该终止符等效于BERT的分类标签[CLS],如下图所示: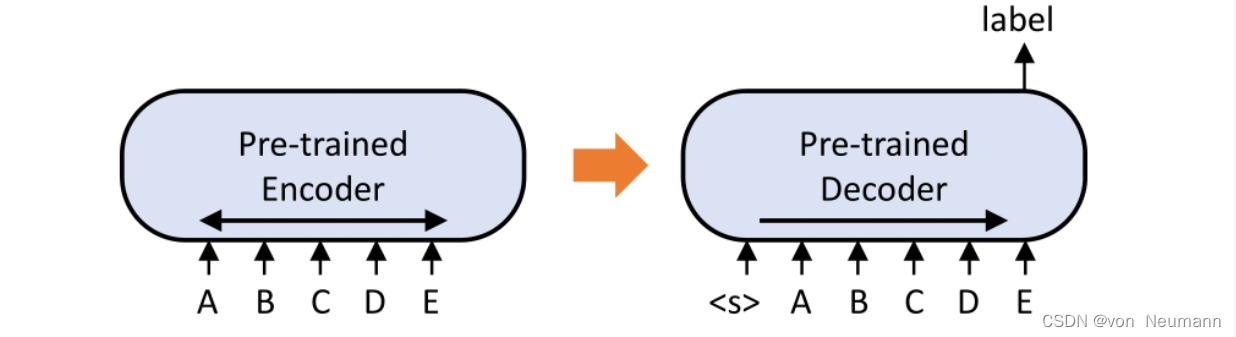
-
单词级别的分类和标注任务:直接将Decoder对应的每一个输出作为分类标签。如下图所示,对于由5个词 A B C D E ABCDE ABCDE组成的句子,在预训练过程中,若Decoder的输入为词 A A A,则训练目标为词 B B B。在单词分类(标注)任务的微调训练过程中,若Decoder的输入为词 A A A,则训练目标为词 A A A对应的类别标签。
-
序列到序列任务:由于BART的结构是传统的Transformer,故天然适合做序列到序列任务,不需要额外的改动。
综上所述,BART通过使用多样化的噪声干扰方式进行训练,在文本理解任务上达到与RoBERTa持平的效果,更通过引入Transformer Decoder结构,在多个生成式任务上达到SOTA效果,其模型体积仅比BERT大10%,算是性价比极高的模型。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.