目录
- 1. 网页分析
- 1.1 静态网页
- 1.2 静态网页的爬取案例
- 1.3 动态网页
- 1.4 Google翻译2023.7.18爬虫实例
- 1.4.1 基于网页分析的Google翻译2023.7.18爬虫实例
- 1.4.2 基于Selenium的Google翻译2023.7.18爬虫实例
1. 网页分析
网页分析即通过检查元素,确定想提取的内容的区域位置,以便后面通过标签id,name,class或其它属性提取内容。网页类型包括静态网页和动态网页:
- 静态网页的指数据直接存储在网页的 html 中,不论用户是否请求了数据,数据就 “静止” 在那里。
- 动态网页的数据则被 “藏” 起来了,用户每次请求后,动态网页才会有一个向远程数据库请求数据的“动作”,再把数据显示出来,但用户无法直接从网页的 html 中获取数据。
对于静态网页,浏览器右键“查看网页源代码”,这里能看到的就是GET能直接得到的HTML内容。从源代码看,静态网页的数据直接存在网页的源代码中,动态网页的数据不会出现在网页源代码中。从网址特征看,静态网页的数据不会 “动”,所以一个页面就是一个网址,翻页时网址会变化。动态网页自己会 “动”,所以哪怕请求新的数据 ,网址也不会变化。比如谷歌翻译每一次输入新的词汇。
网页主要有以下几种代码格式,这些格式通常一起使用,组成了现代网页的基本结构:
- HTML(Hypertext Markup Language):HTML是一种标记语言,用于创建网页的结构和内容。它使用标签(例如、、)来定义网页的不同部分,包括文本、图像、链接等。
- CSS(Cascading Style Sheets):CSS是一种样式表语言,用于控制网页的外观和布局。它定义了网页元素的样式、字体、颜色、大小、位置等属性,使网页能够呈现出所需的视觉效果。
- JavaScript:JavaScript是一种脚本语言,用于实现网页的交互和动态功能。通过JavaScript,可以对网页进行操作、响应用户的交互,以及动态地更新网页内容。
- JSON(JavaScript Object Notation):JSON是一种轻量级的数据交换格式,常用于在客户端和服务器之间传输数据。虽然它不是网页的格式,但在Web开发中经常用于通过API或AJAX技术获取和交换数据。
1.1 静态网页
静态网页的内容一般以HTML格式返回数据。请求静态网页时,服务器将返回包含HTML代码的响应,其中包含网页的各种元素,如文本、图像、链接等。解析静态网页可以使用HTML解析器(如BeautifulSoup)来解析HTML代码,并提取所需的数据或操作网页的各种元素。通常,静态网页的内容不以JSON格式返回数据,因为JSON主要用于传输结构化数据而不是网页内容的表示。
需要注意的是,有些网站可能会在静态网页中嵌入JSON数据,以便在前端JavaScript代码中使用。在这种情况下,您可能需要查找嵌入的JSON数据并提取所需的内容。
通过在静态网页中嵌入JSON数据,前端开发人员可以在网页加载时获取和操作数据,避免每次都向后端发送请求获取数据,从而提高网页的性能和响应速度。同时,通过使用JSON格式,数据可以以结构化的方式传输和交换,便于前端JavaScript代码解析、提取并使用嵌入的JSON数据。
1.2 静态网页的爬取案例
import requests
from bs4 import BeautifulSoupurl = "https://lianxh.cn/news/63ffc529caf31.html"
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67'
}
r = requests.get(url=url, headers=headers) # print(r.text)结果即静态网页源代码
soup = BeautifulSoup(r.content, 'html.parser')
# 在这里可以使用BeautifulSoup提供的方法来提取网页内容
# 例如:soup.find('div', {'class': 'content'}) 查找具有class为'content'的<div>标签# 打印网页标题
print(soup.title.string)
网页https://lianxh.cn/news/63ffc529caf31.html标题输出结果为:
Python爬取静态网站:以历史天气为例| 连享会主页
1.3 动态网页
动态网页的数据往往根据用户请求进行响应后获得,无法直接从网页的 html 中直接获取。点击右键“查看网页源代码”,会发现有一部分网页上显示的内容,源代码里面没有对应的数据,而这部分就是通过ajax异步加载出来的。就比如CSDN的评论:
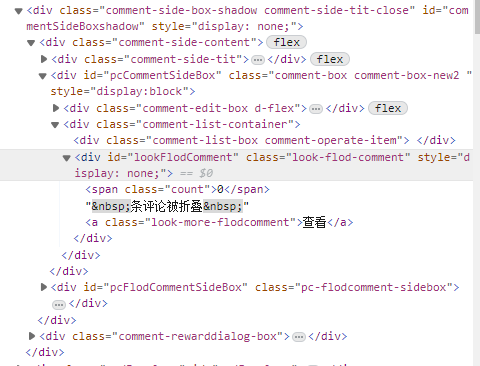 |  |
| Fig.1 评论区元素中看不到对应的评论数据 | Fig.2 但实际却是有一条评论 |
想要爬取这部分数据,需要分析出来加载动态网页的url。
想要爬取动态网站,第一步需要利用开发人员工具进行元素审查。
 |
| Fig.3 开发人员工具 |
 |
| Fig.4 开发工具常用模块介绍 |
元素(ELements):查看网页页面的所有元素。用于查看修改元素的属性、CSS 属性、监听事件以及断点等等。
控制台(Console):开发人员进行Web开发和调试的工具。例如使用控制台输出调试信息、日志消息和其他自定义消息。执行 JS 语句。显示网页加载过程中的网络请求,包括请求的URL、响应状态、响应头、请求时间等信息。
源代码(Sources):用于查看和编辑网页的HTML、CSS和JavaScript代码。
网络(Network):用于监视和分析网页加载过程中的网络请求和响应。
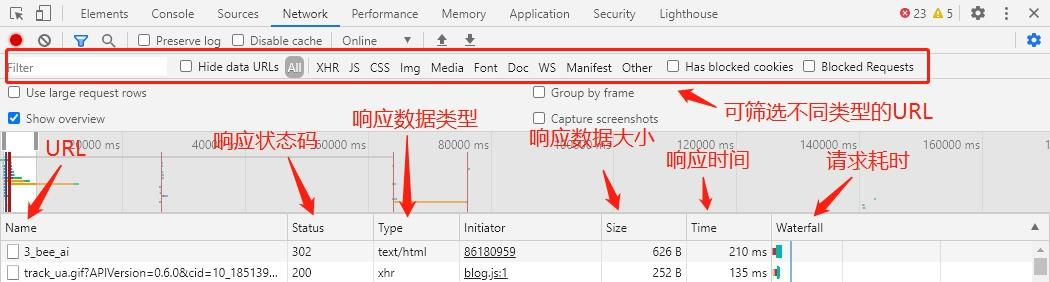
在网络面板上,Fetch/XHR、JS、CSS、Img等URL筛选是用于过滤和筛选特定类型的网络请求的选项。
- Fetch/XHR:用于筛选XMLHttpRequest(XHR)和Fetch API发送的网络请求,这些请求通常用于通过JavaScript进行数据交互和异步加载。
- JS:用于筛选JavaScript文件的网络请求,包括网页中引入的外部JavaScript文件、内联的JavaScript代码等。
- CSS:用于筛选CSS文件的网络请求,包括外部CSS文件和内联样式。
- Img:用于筛选图像文件(如JPEG、PNG、GIF等)的网络请求,包括通过 <img> \text{<img>} <img>标签加载的图像。
开发者工具可以用于:复制不可复制的文字、下载不能保存的图片、编辑页面上的任何文本、爬虫时审查元素等。
1.4 Google翻译2023.7.18爬虫实例
PS:我知道可以利用Google Cloud Translation API进行翻译,但这里是为了演示爬虫。
1.4.1 基于网页分析的Google翻译2023.7.18爬虫实例
参考流程:https://blog.csdn.net/cnds123321/article/details/103321859
参考代码:https://github.com/lushan88a/google_trans_new
1.4.2 基于Selenium的Google翻译2023.7.18爬虫实例
简单高效的抓取动态网页内容用动态网页抓取神器:Selenium
比如,常见反爬手段可粗略分为五大类:
- headers 字段:User-Agent、referer、cookie
- IP 地址
- js:js 实现跳转、js 生成请求参数或数据加密
- 验证码
- 其他:自定义字体(比如:猫眼电影)、CSS像素偏移(比如:去哪儿网)
而对于用户来说,既然你有「盾」护,那就只能以锋「矛」应对了。反反爬的主要思路是尽可能地模拟浏览器,浏览器如何操作,代码中就如何实现。所以反爬与反反爬其实就处于「动态博弈」之中。