1 日志接口
elog.c完成PG中日志的生产、记录工作,对外常用接口如下:
1.1 最常用的ereport和elog
ereport(ERROR,(errcode(ERRCODE_UNDEFINED_TABLE),errmsg("relation \"%s\" does not exist",relation->relname)));
elog(ERROR, "unexpected enrtype: %d", enrmd->enrtype);
其实都是在调用errstart和errfinish函数完成具体工作。
#define elog(elevel, ...) \ereport(elevel, errmsg_internal(__VA_ARGS__))#define ereport(elevel, ...) \ereport_domain(elevel, TEXTDOMAIN, __VA_ARGS__)#define ereport_domain(elevel, domain, ...) \do { \pg_prevent_errno_in_scope(); \if (__builtin_constant_p(elevel) && (elevel) >= ERROR ? \errstart_cold(elevel, domain) : \errstart(elevel, domain)) \__VA_ARGS__, errfinish(__FILE__, __LINE__, __func__); \if (__builtin_constant_p(elevel) && (elevel) >= ERROR) \pg_unreachable(); \} while(0)
2 日志数据结构
- 单条日志被抽象为ErrorData,记录了日志的全部信息。
- elog.c提供了一个深度为5的stack来存放最多五层的ErrorData,大部分场景下,stack只会使用一层:
#define ERRORDATA_STACK_SIZE 5
static ErrorData errordata[ERRORDATA_STACK_SIZE];

3 日志的工作流程
每一条日志都是经过errstart和errfinish函数处理的,分工大致为:
- errstart
- 在errdata堆栈中压入一个新的edata
- 为edata填充部分错误信息,例如错误等级、需要输出到server/client、按需升级错误等级(例如Crit区域中大于等于ERROR的需要变成PINIC)
- errfinish
- 在进入errfinish前,错误信息的文本经过errmsg或errmsg_internal函数中的EVALUATE_MESSAGE宏记入edata中的message中,内存用的是errfinish
- 三部分工作:
- 3.1 完成PG_TRY()、PG_CATCH()跳转功能,为errfinish添加try/catch功能
- 3.2 完成error_context_stack的回调功能,为errfinish增加报错信息
- 3.3 完成EmitErrorReport,为errfinish发送错误信息
3.1 完成PG_TRY()、PG_CATCH()跳转功能,为errfinish添加try/catch功能
注意PG_CATCH和PG_FINALLY是二选一的,区别是PG_FINALLY会在最后把异常重新抛出去,而PG_CATCH自己处理完了就不在向上抛了。
#define PG_TRY() \do { \sigjmp_buf *_save_exception_stack = PG_exception_stack; \ErrorContextCallback *_save_context_stack = error_context_stack; \sigjmp_buf _local_sigjmp_buf; \bool _do_rethrow = false; \if (sigsetjmp(_local_sigjmp_buf, 0) == 0) \{ \PG_exception_stack = &_local_sigjmp_buf#define PG_CATCH(...) \} \else \{ \PG_exception_stack = _save_exception_stack; \error_context_stack = _save_context_stack#define PG_FINALLY() \} \else \_do_rethrow = true; \{ \PG_exception_stack = _save_exception_stack; \error_context_stack = _save_context_stack#define PG_END_TRY() \} \if (_do_rethrow) \PG_RE_THROW(); \PG_exception_stack = _save_exception_stack; \error_context_stack = _save_context_stack; \} while (0)
我们先看一个PG中常规的报错流程,注意是不在PG_TRY中的elog(ERROR),发生>=ERROR级别的异常后,在errfinish中会抛出异常,jmp到PostgresMain函数中的sigsetjmp的位置,进入异常回收流程。

那么如果代码中的报错被PG_TRY、PG_CATCH包裹时,抛出异常会发生什么呢?
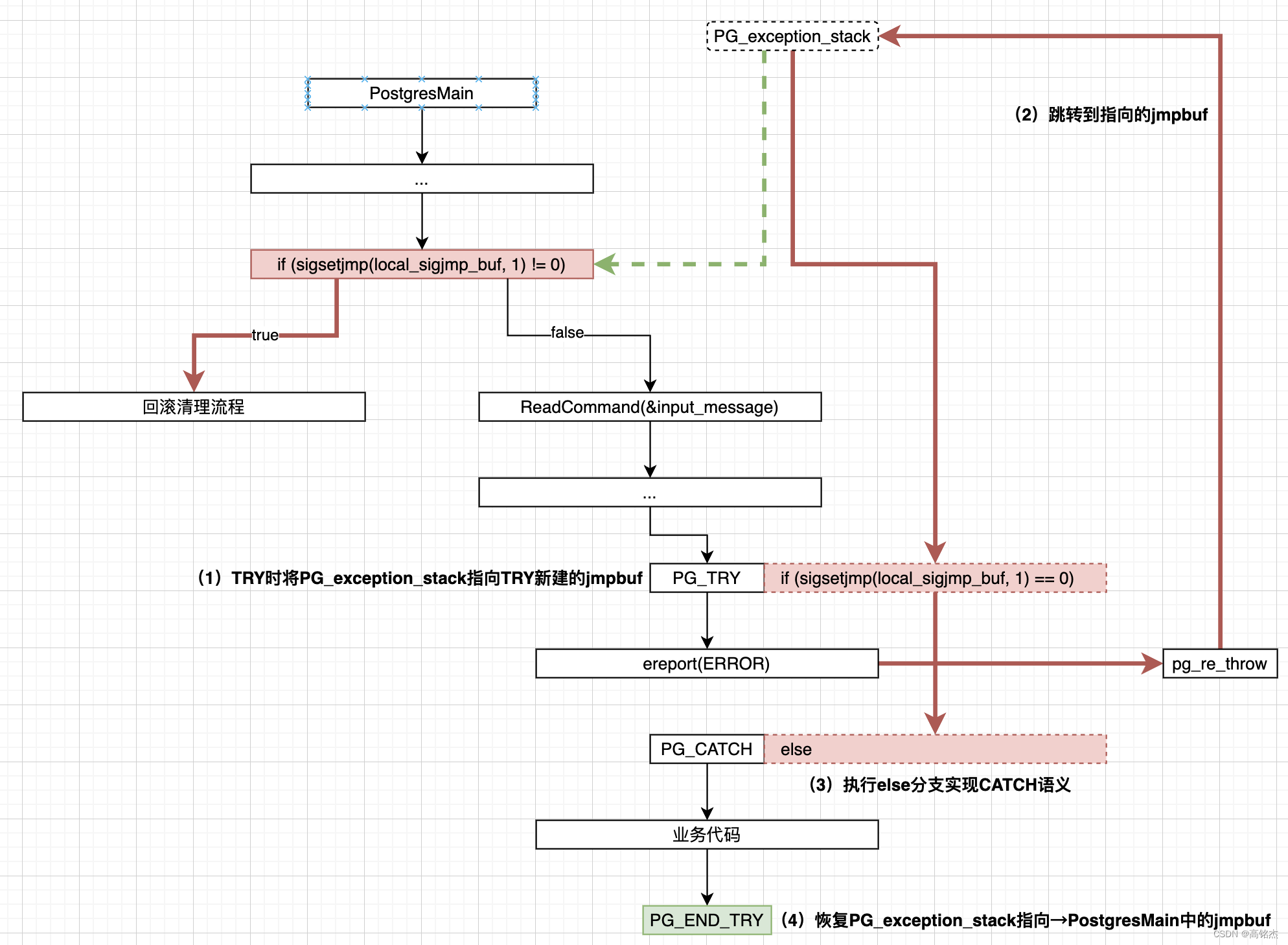
3.2 完成error_context_stack的回调功能,为errfinish增加报错信息
error_context_stack是一个Lisrt记录了回调函数回调函数的参数,这里的函数的作用是添加报错信息,因为这些函数会在errfinish时被调用,函数中往往都会使用errcontext_msg记录一些更详细的报错文本。
typedef struct ErrorContextCallback
{struct ErrorContextCallback *previous;void (*callback) (void *arg);void *arg;
} ErrorContextCallback;extern PGDLLIMPORT ErrorContextCallback *error_context_stack;
例如pl编译时配置的plpgsql_compile_error_callback函数,为了增加编译报错时,错误的发生的位置等:
do_compile...plerrcontext.callback = plpgsql_compile_error_callback;plerrcontext.arg = forValidator ? proc_source : NULL;plerrcontext.previous = error_context_stack;error_context_stack = &plerrcontext;...
static void
plpgsql_compile_error_callback(void *arg)
{if (arg){/** Try to convert syntax error position to reference text of original* CREATE FUNCTION or DO command.*/if (function_parse_error_transpose((const char *) arg))return;/** Done if a syntax error position was reported; otherwise we have to* fall back to a "near line N" report.*/}if (plpgsql_error_funcname)errcontext("compilation of PL/pgSQL function \"%s\" near line %d",plpgsql_error_funcname, plpgsql_latest_lineno());
}
error_context_stack和上面提到的PG_exception_stack都会在TRY中进行保存和恢复,为什么:
- PG_exception_stack比较好理解,因为TRY时会建一个新的jmpbuf用PG_exception_stack指向,之前的旧值需要记录下来,TRY完了需要恢复。
- error_context_stack的回调函数是在子模块中配置的,正常执行完子模块会把error_context_stack恢复原样,但一旦error发生了跳转,恢复逻辑就被跳过了。所以在TRY中自带了恢复error_context_stack的逻辑。
3.3 完成EmitErrorReport,为errfinish发送错误信息
errfinish......EmitErrorReport......
EmitErrorReport函数中会执行发送逻辑:
EmitErrorReport...if (edata->output_to_server && emit_log_hook)(*emit_log_hook) (edata);/* Send to server log, if enabled */if (edata->output_to_server)send_message_to_server_log(edata); // 写 write_syslog/* Send to client, if enabled */if (edata->output_to_client)send_message_to_frontend(edata); // 写libpq,发送到客户端或主进程
4 CopyErrorData / FlushErrorState / FreeErrorData
由于edata中的信息是在ErrorContext中申请的,在PG_CATCH时,是能拿到edata使用的,但在catch时不应该使用ErrorContext申请任何内存,所以惯用法是在PG_CATCH中用CopyErrorData把edata拷贝到当前的上下文中,在进行操作。然后把ErrorContext中的edata用FlushErrorState清理干净。
例如PL中的用法
PG_CATCH();{ErrorData *edata;....../* Save error info in our stmt_mcontext */MemoryContextSwitchTo(stmt_mcontext);// 拷贝edata到当前上下文中edata = CopyErrorData();// ErrorContext中的用完尽快释放FlushErrorState();......// 尽情使用使用edataexception_matches_conditions(edata, exception->conditions)......




![[node]Node.js 中REPL简单介绍](https://img-blog.csdnimg.cn/a8ec2c62d52d45e3b14891088f7a210c.png)
