MySQL的数据类型
- 一、数据类型分类
- 二、数值类型
- 1、整数类型
- 2、bit类型
- 3、小数类型
- 三、字符串类型
- 四、时间日期类型
- 五、enum和set类型
- enum和set查找
数据类型的作用:
- 决定了存储数据时应该开辟的空间大小和数据的取值范围。
- 决定了如何识别一个特定的二进制序列。
一、数据类型分类

MySQL中的数据类型与编程语言中的数据类型相似,在学习时我们不进行一 一演示,通过讲述一个或两个特定的类型,你也能够触类旁通。
二、数值类型
1、整数类型
MySQL为我们提供了不同占用不同字节大小的整数类型,以便于我们能够更好的使用数据和节省磁盘的空间。
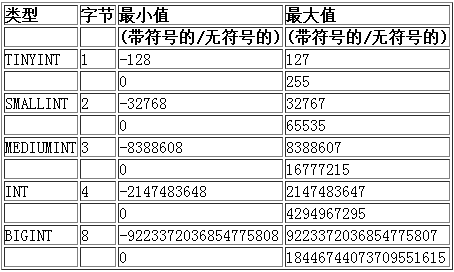
在MySQL中,整型可以指定是有符号的和无符号的,默认是有符号的,可以通过 UNSIGNED 来说明某个字段是无符号的。
这里我们以tinyint类型为例介绍数值类型:
在下面我们创建一张表,并向表中插入一些合法数据,一些非法数据。
create table tiny (num tinyint);
desc tiny;
insert into tiny values (0);
insert into tiny values (-128);
insert into tiny values (127);
insert into tiny values (-129);
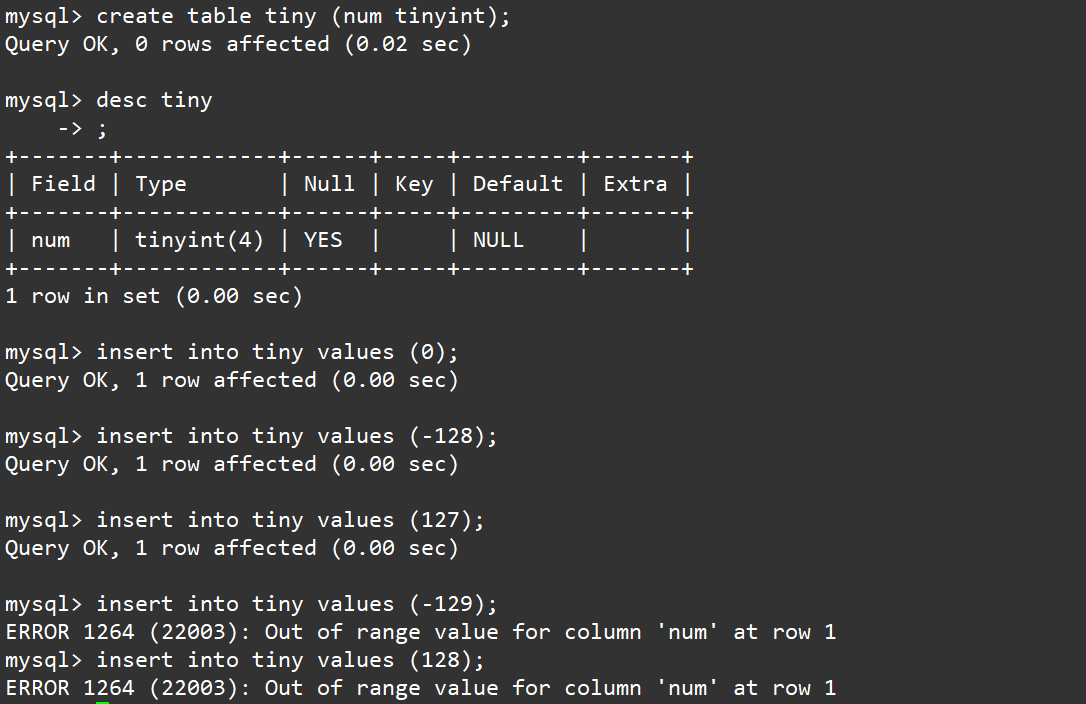
查看表中的内容,发现合法的数据被成功的插入了,非法的数据直接被拒绝插入,说明MySQL不会为我们的整形进行截断转换。
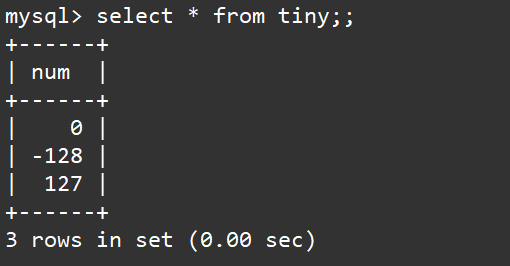
所以数据类型本身也是一种:约束,通过这种约束我们就能保证数据库中的数据是可预期,完整的;
2、bit类型
基本语法:
bit[(M)] : 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。
- bit类型的显示方式
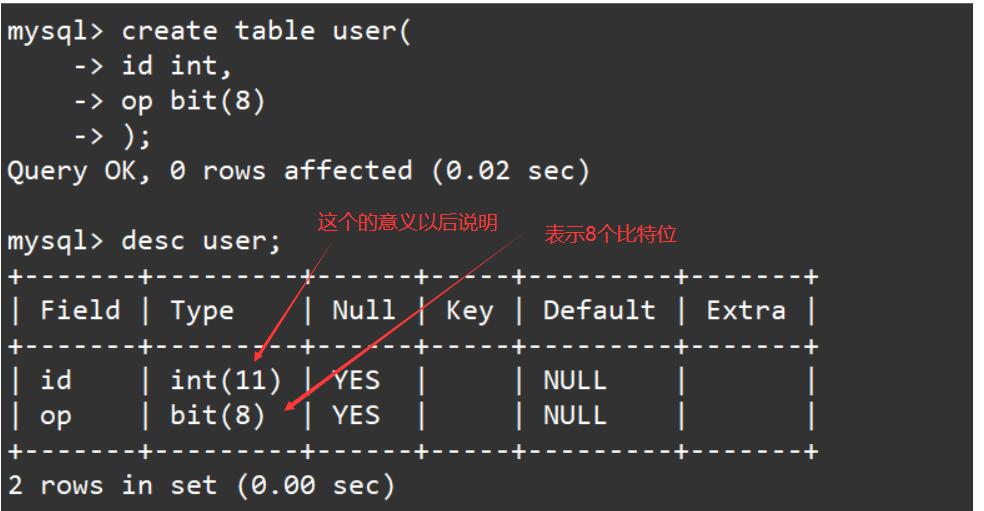
创建一个表,表当中包含一个int类型表示用户id,和一个8位bit类型表示一些选项。如下:
create table user(id int, op bit(8));
desc user;
向user表中插入一些数据并显示表中的内容:
insert into user values (124, 1);
insert into user values (127, 97);
select * from user;
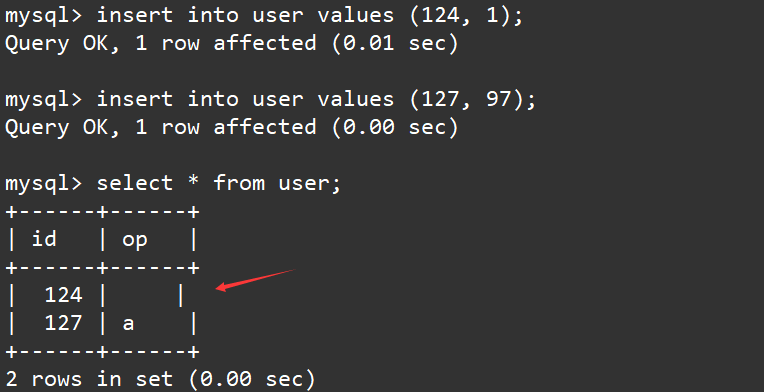
我们发现我们插入的1没有被显示,而我们插入的97却显示成了字符a,这因为bit类型在显示时,是按照ASCII码对应的值进行显示的,1是不可显示字符,97对应的就是a。
如果我们还是想要让bit类型能够像整数类型那样显示的话,我们可以在显示时对op字段加上hex(以16进制显示)。
select id, hex(op) from user;
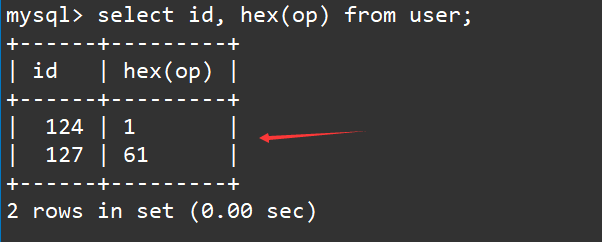
可以看到结构能够正常显示了!
- bit类型的范围测试
创建一个表,表当中包含用户id和用户性别gender,其中gender的类型可以指定为1位bit类型,因为性别只有男和女两种取值,使用1个比特位来表示用户的性别就可以节省空间。
create table user_info(id int, gender bit);
desc user_info;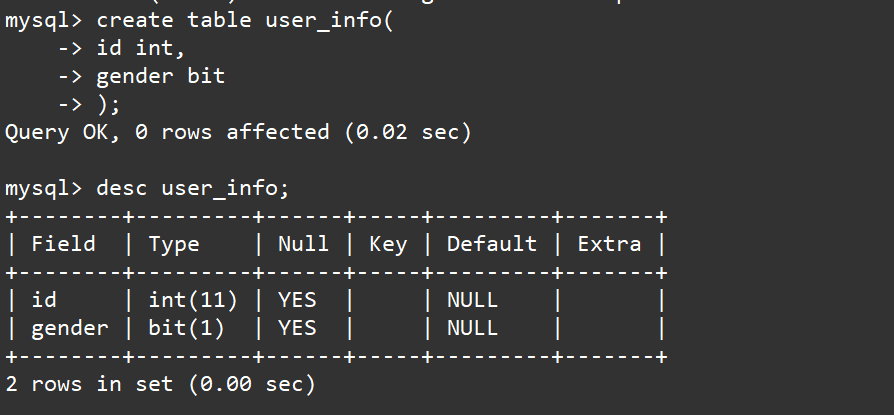
插入数据
insert into user_info values (12, 0);
insert into user_info values (13, 1);
insert into user_info values (13, 3);
insert into user_info values (14, 5);
select id, hex(gender) from user_info;
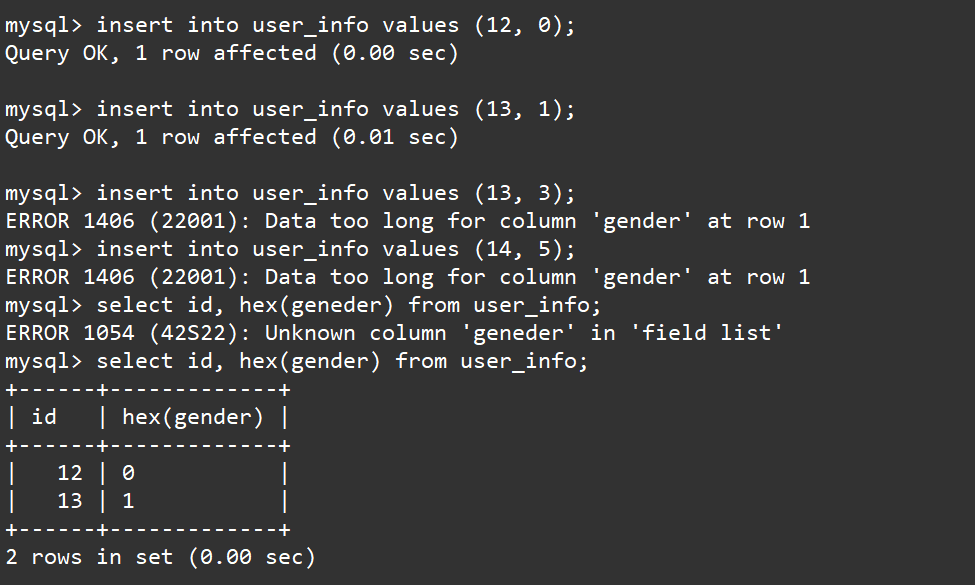
可以看到如果插入gender列的数据不是0或1,那么插入数据时就会产生报错。
建议:
- 虽然MySQL提供了位类型bit,但一般不建议将数据类型设置成位类型,除非将来这个数据本身就只是给程序看的,并且数据本身非常占用资源。
- 因为查询位类型数据时,默认会按照ASCII码对应的值进行显示,这对于将来数据库管理员维护数据库或程序员调试程序都是不太方便的。
3、小数类型
- float类型
语法:
float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节
特征:
- 对于小数部分如果超出了精度MySQL在保存值时会进行四舍五入,对于整数部分如果超出精度则拒绝插入。
- 对于有符号的
float的范围是去掉负数只留正数。 float表示的精度大约是小数点后7位,但是当float存储较高精度的数据时会出现误差。
案例
1:
我们创建一个float(4,2),类型,则这个类型可以表示的范围是-99.99 ~ 99.99,然后我们分别向这个表中插入 99.99, -99.99,23.655, -36.232, 100, -100。
create table ftable ( price float(4,2) );
desc ftable;
insert into ftable values (99.99);
insert into ftable values (-99.99);
insert into ftable values (23.655);
insert into ftable values (-36.232);
insert into ftable values (100);
insert into ftable values (-100);
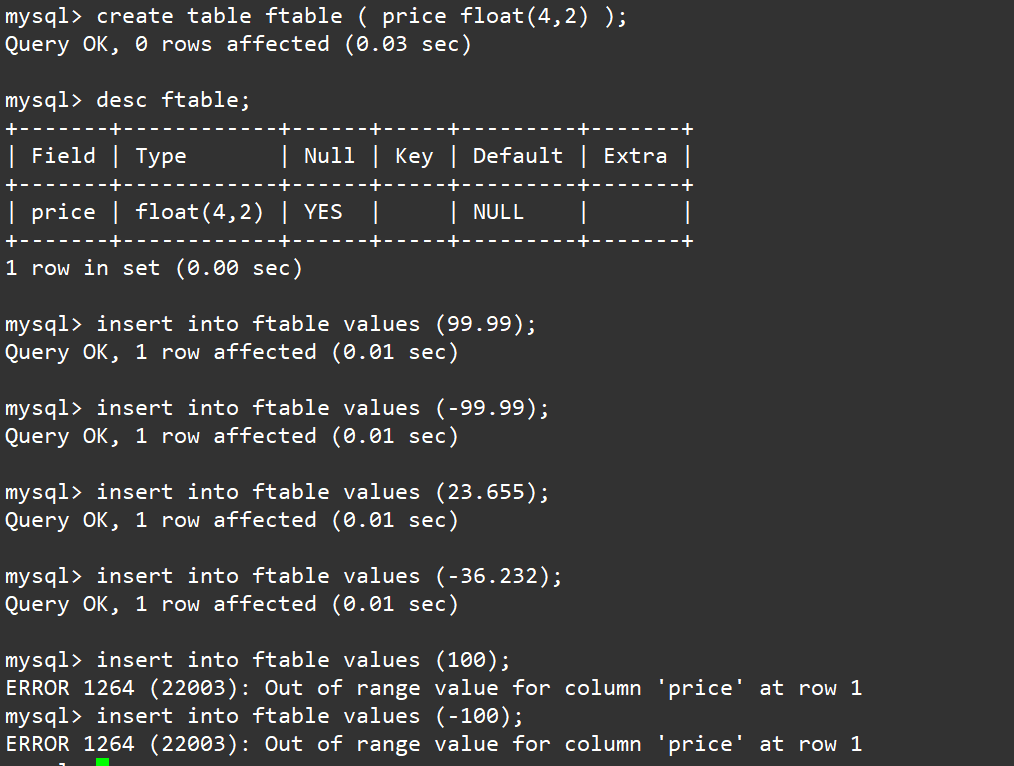
查看表中的内容:
select * from ftable;

结果符合我们的预期!
案例
2
我们在创建一张无符号的float(4,2)表,然后我们插入正数99,100.00,和负数-22.01。
create table futable( price float(4,2) unsigned );
desc futable;
insert into futable values (99);
insert into futable values (100.00);
insert into futable values (-22.01);
select * from futable;
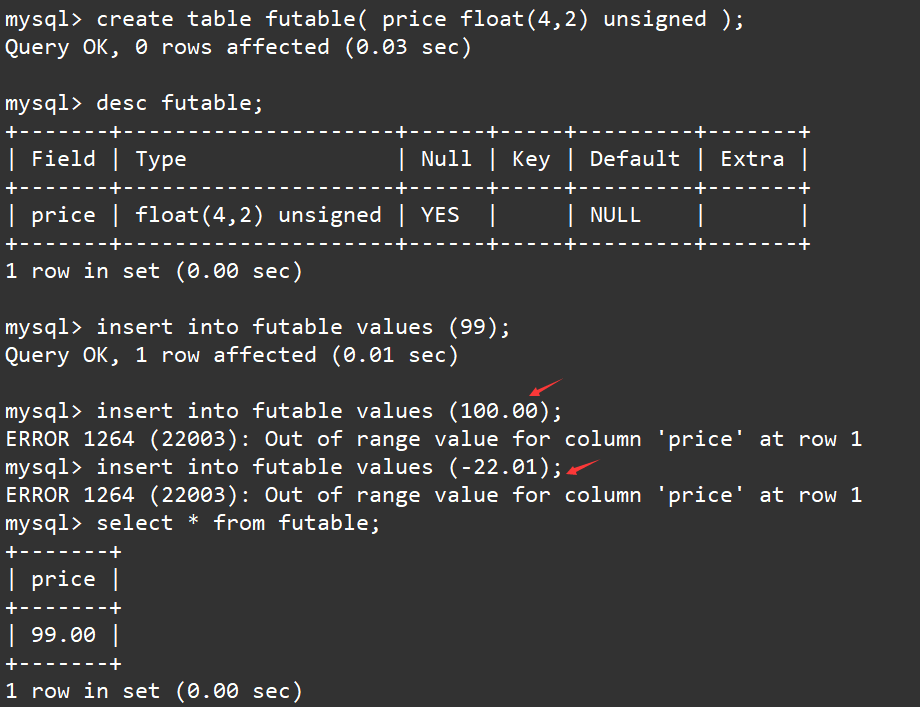
查看表的内容后,发现果然正数的范围没有改变,负数不能被插入。
案例
3
创建一张float类型的表,然后我们向其中插入2202.3,123456789,1.23456789,然后观察表中的结果。
create table fltable( num float );
insert into fltable values (2202.3);
insert into fltable values (2202.3);
insert into fltable values (123456789);
insert into fltable values (1.23456789);
select * from fltable;
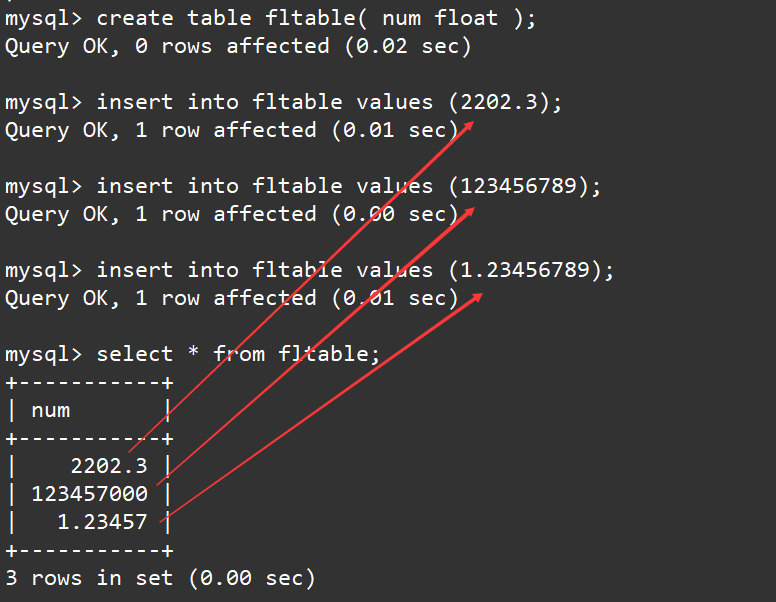
我们发现对于精度较高的数据,无论是正数部分太大,还是小数部分太多,都会导致float类型存储时出现误差。
- decimal类型
decimal和float类型的使用方式一样,但decimal的精度比float更高。
语法:
decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数
特征
decimal整数最大位数m为65。支持小数最大位数d是30。如果d被省略,默认为0,如果m被省略,默认是10。
创建一个表,表当中分别包含一个float(10,8)的列和一个decimal(10,8)的列。如下:
create table dectable( num float(10,8), num2 decimal(10,8) );
desc dectable;
向表当中插入一条记录,指定float和decimal的值均为23.12345612,但最终查表时会发现decimal保持了数据的原貌,而float则会存在一定的精度损失。如下:
insert into dectable values (23.12345612, 23.12345612);
select * from dectable;
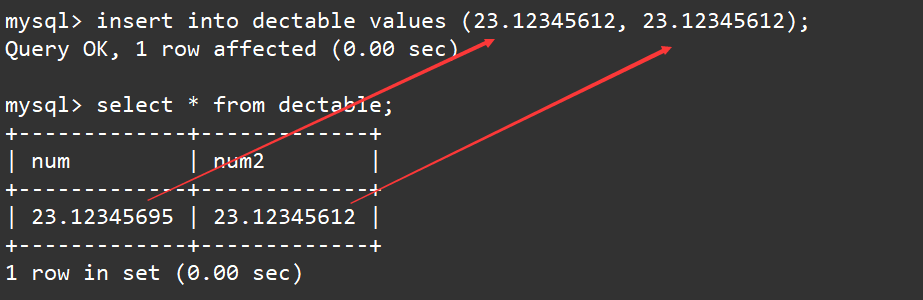
建议:如果希望小数的精度高,推荐使用decimal。
三、字符串类型
- char类型
语法:
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255。
特征
char类型的单位是字符,而不是字节,无论是英语a,还是汉语我,甚至感叹号!等都表示一个字符。
例如我们先创建一张表,包含一个chart字段,这个字段的类型我们设置为char(4),然后我们向其插入:
abc,你好啊~,A,你好,A,你好啊。
creat table ch (chart char(4));
desc ch;
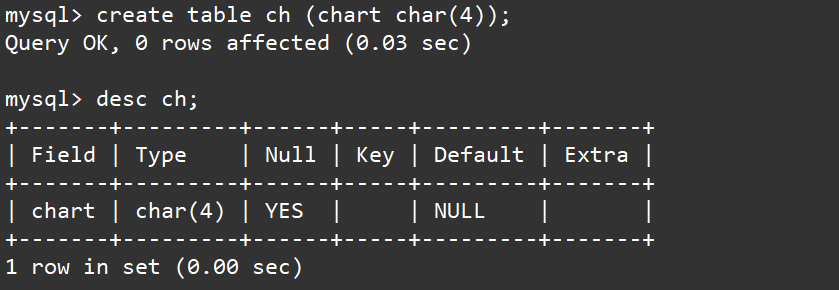
进行插入,并显示:
insert into chart values ('abc');
insert into ch values ('你好啊~');
insert into ch values ('A,你好');
insert into ch values ('A,你好啊');
select * from ch;
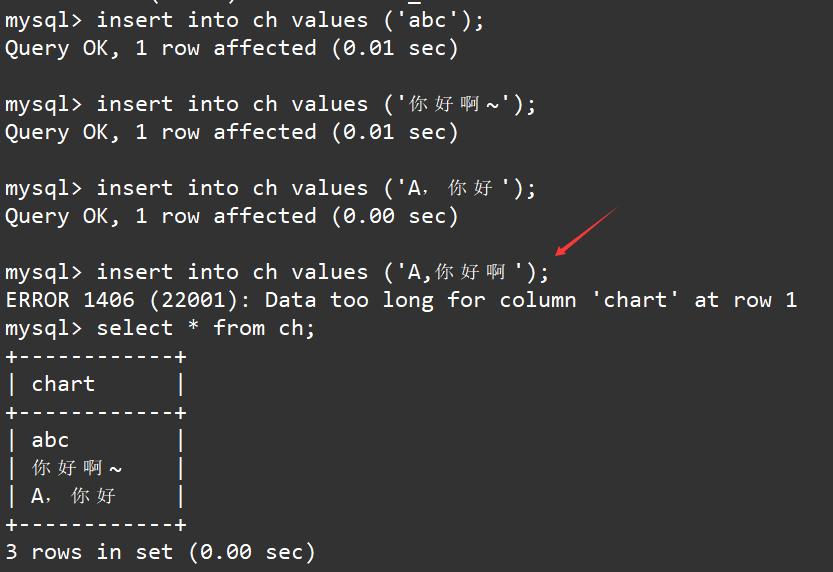
结果符合我们的预期,对于A,你好啊,这个数据的字符长度是大于4的所以不能够被正常插入。
优点:
在不同编码中,一个字符所占的字节个数是不同的,比如utf8中一个字符占3个字节,而gbk中一个字符占2个字节。MySQL限定字符的概念不是字节,这样用户就不用关心复杂的编码细节了。
- varchar类型
语法:
varchar(L): 可变长度字符串,L表示字符长度,最大长度65535个字节
说明:
varchar类型是可变长字符串类型,其使用与char并无区别,但是varchar能够更加节省空间。
在上面char类似的案例演示中,如果我们使用的是utf8编码,对于char(4),MySQL其实在底层默认给我们分配了: 4 ∗ 3 = 12 4 * 3 = 12 4∗3=12个字节, 上面的演示案例中,如果我们存放的是abc三个字符,其实我们只需要是使用了3个utf8字符,即9个字节,另外的3个字节被浪费了,而varchar出现就能改变这种状况。
特征
-
varchar类型最多占用65535字节,其中有1~2字节用来表示实际数据长度,还有1字节来存储其他控制信息,因此varchar类型的有效字节数最多是65532字节。
-
因此varchar类型可指定的字符个数上限,与表的编码格式有关:
- 对于utf8编码来说,一个字符占用三个字节,因此varchar(L)中的L最大可指定为 65532 ÷ 3 = 21844 。
- 对于gbk编码来说,一个字符占用两个字节,因此varchar(L)中的L最大可指定为 65532 ÷ 2 = 32766 。
- 案例
1
和char一样,我们先创建一张表,包含一个varchar字段,这个字段的类型我们设置为varchar(4),然后我们向其插入:
abc,你好啊~,A,你好,A,你好啊。
create table varch (varch varchar(4));
desc varch;
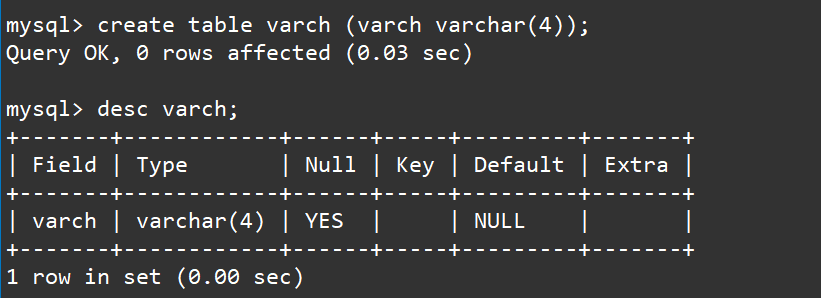
insert into varch values ('abc');
insert into varch values ('你好啊~');
insert into varch values ('A,你好');
insert into varch values ('A,你好啊');
select * from varch;
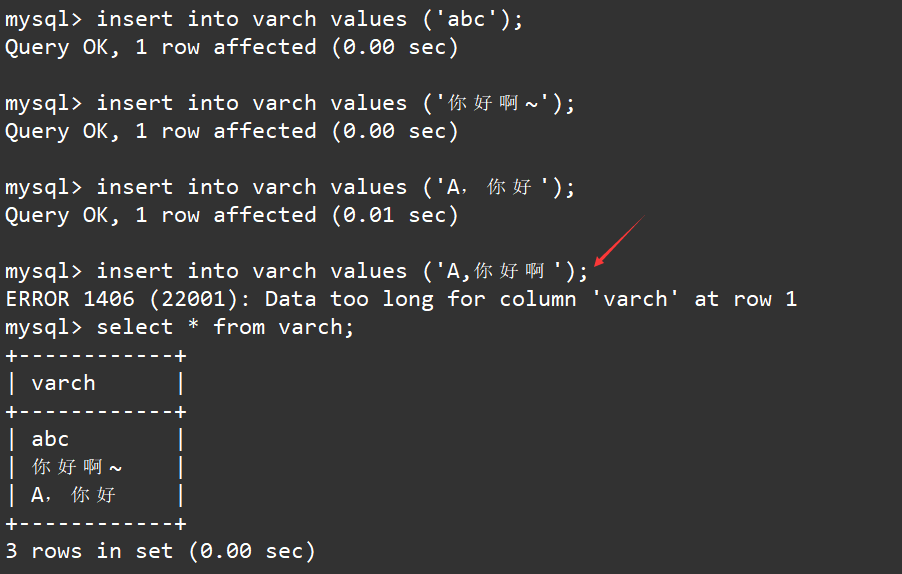
结果与使用char没有差别,差别在于使用utf8时底层varchar对于abc分配使用的空间相比于char要少。
- 案例
2
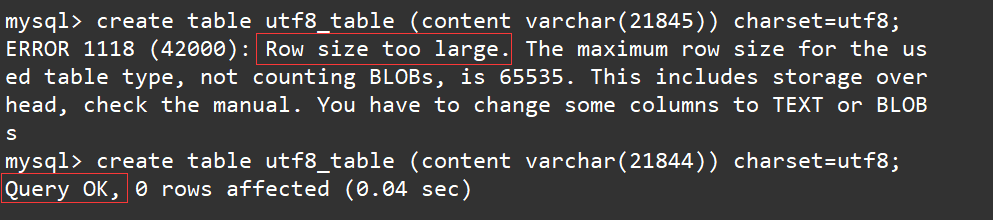
由于varchar类型的字节数限制,在定义编码格式为utf8的表时,varchar(L)中的L如果超过了21844,则会产生报错。如下:
create table utf8_table (content varchar(21845)) charset=utf8;
create table utf8_table (content varchar(21844)) charset=utf8;
由于varchar类型的字节数限制,在定义编码格式为gbk的表时,varchar(L)中的L如果超过了32766,则会产生报错。如下:
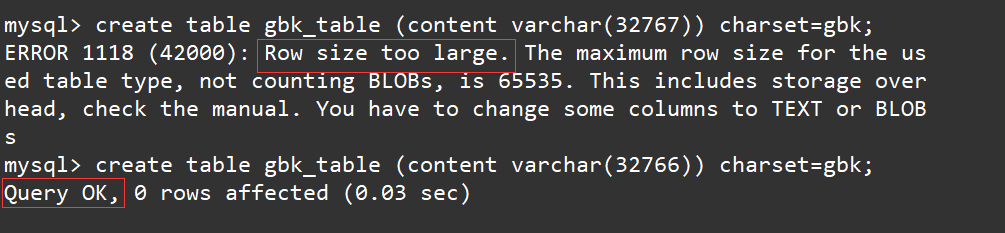
create table gbk_table (content varchar(32767)) charset=gbk;
create table gbk_table (content varchar(32766)) charset=gbk;
- char和varchar比较
char和varchar的区别如下:
char类型可存储字符上限为255,varchar类型可存储字符上限与表的编码格式有关。char(L)定义后,无论存储的字符串长度是否到达L,都会开辟用于存储L个字符的定长空间,如果存储的字符串长度超过L则会报错。varchar(L)定义后,会根据存储字符串的长度按需开辟空间,并且需要使用1-3字节的空间用于表示存储字符串的长度以及其他控制信息,如果存储的字符串长度超过L则会报错。
char和varchar的优缺点如下::
char类型的数据是定长的,因此磁盘空间比较浪费,但是效率高(直接访问定长的空间)。varchar类型的数据是变长的,因此磁盘空间比较节省,但是效率低(需要先读取存储字符串的长度,再访问指定长度的空间)。
如果要存储的数据是定长的,那就使用char类型进行存储,比如身份证号码、手机号、md5等。如果要存储的数据是变长的,那就使用varchar类型进行存储,比如名字、地址等。
四、时间日期类型
常用的三种时间日期类型如下:
date:日期格式为YYYY-MM-DD,占用三字节。datetime:时间日期格式为YYYY-MM-DD HH:MM:SS,占用八字节。timestamp:时间戳,格式为YYYY-MM-DD HH:MM:SS,占用四字节,值得注意的是这个字段,我们不主动修改的话,此字段就会自动插入当前的时间戳。
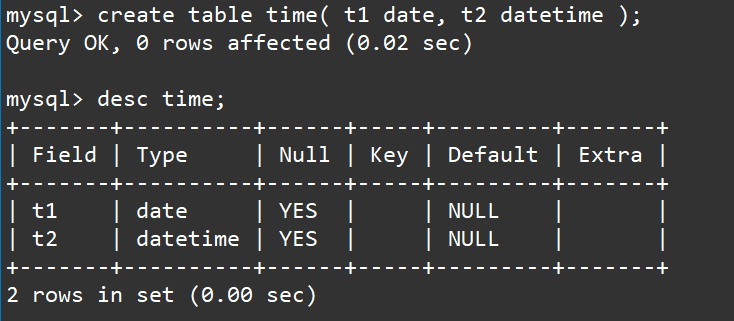
创建一个表,表当中包含date、datetime两种时间日期类型的列。如下:
create table time( t1 date, t2 datetime );
desc time;
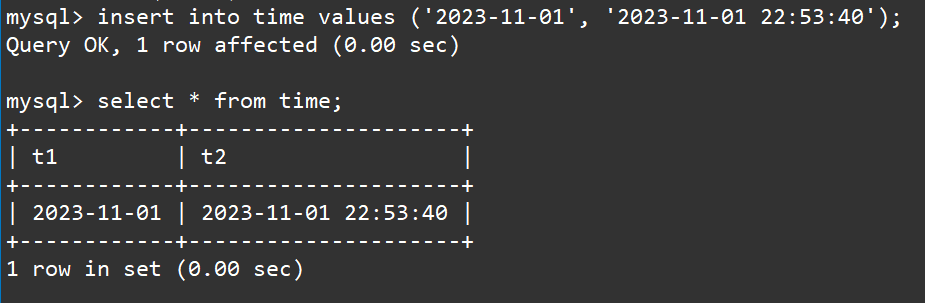
insert into time values ('2023-11-01', '2023-11-01 22:53:40');
select * from time;
- timestamp类型使用案例
利用timestamp会自动更新时间的特性,我们可以创建一个评论表,表当中包含评论人的昵称、评论的内容和评论的发布时间。如下:
create table comment_table ( name varchar(20), content text(100), publish_time timestamp);desc comment_table;
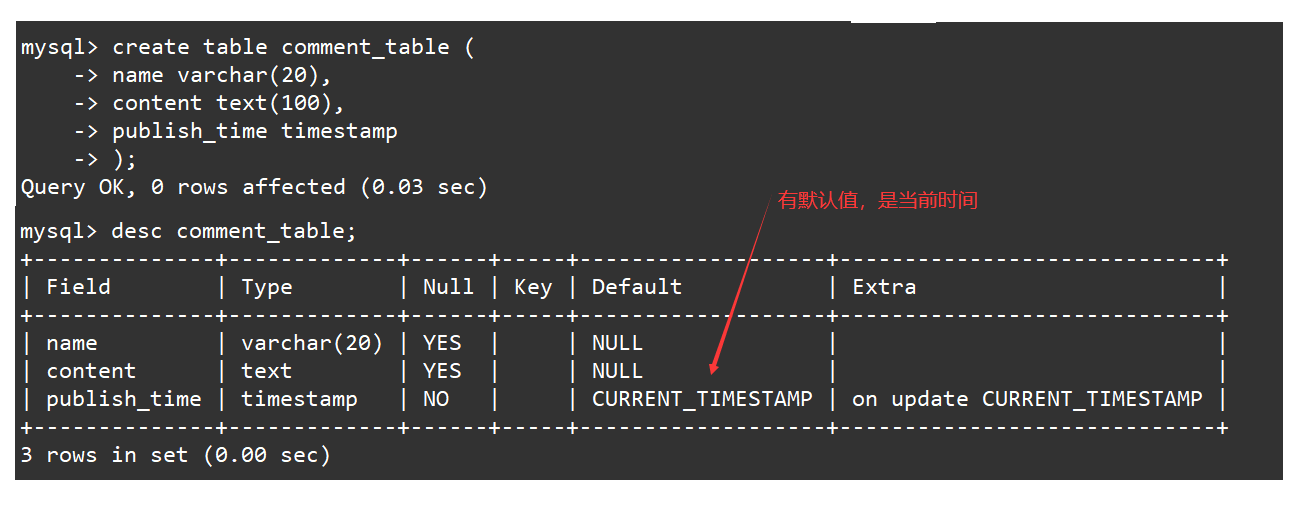
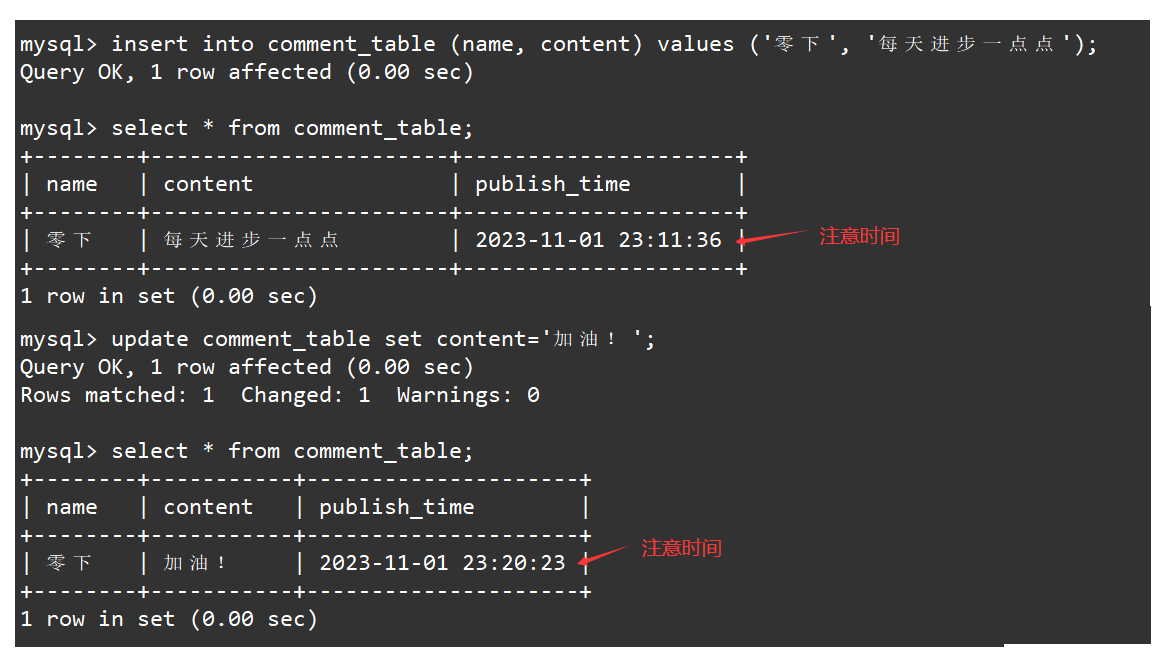
如果评论人修改了评论内容,那么就需要对评论表进行更新,更新表的同时评论的发布时间也会更新为修改表的时间。如下
update comment_table set content='加油!';
select * from comment_table;
五、enum和set类型
enum和set类型的区别如下:
- 在定义
enum字段时需要提供若干个选项的值,在设置enum字段值时只允许选取其中的一个值。 - 在定义
set字段时需要提供若干个选项的值,在设置set字段值时可以选取其中的一个或多个值。
语法:
- enum
enum('选项1', '选项2', '选项3',...);
该设定只是提供了若干个选项的值,最终一个单元格中,实际只存储了其中一个值;而且出于效率考虑,这些值在MySQL内部实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,3,…最多65535
个;当我们添加枚举值时,也可以添加对应的数字编号。
- set
set('选项值1','选项值2','选项值3', ...);
该设定只是提供了若干个选项的值,最终一个单元格中,设计可存储了其中任意多个值;而且出于效率考虑,这些值在MySQL内部实际存储的是“数字”,因为这些选项的每个选项值依次对应如下数字:1,2,4,8,16,32,…最多64个。(即每个比特位都不相等的「位图结构」)
调查表案例
我们现在需要做一个爱好调查表,包含名称,性别,爱好。
分析:
- 名称我们可以定义为
varchar类型以节省空间。 - 人的性别只能从男和女中进行二选一,因此可以定义成
enum类型。 - 人的爱好在提供的选项中可能存在多个,因此可以定义成
set类型。
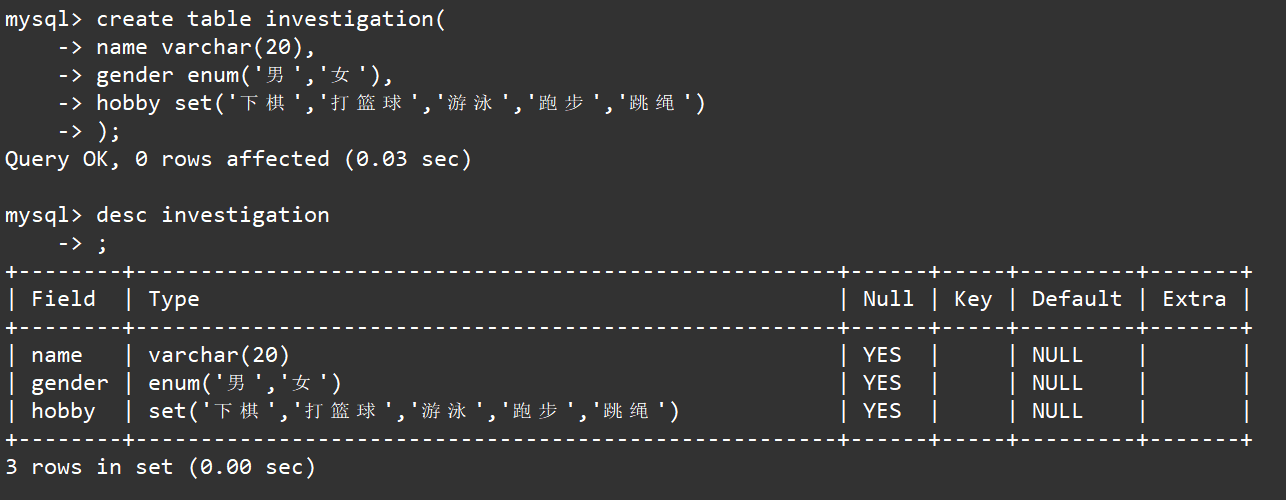
创建一个调查表,表当中包含被调查人的姓名、性别和爱好。如下:
create table investigation( name varchar(20), gender enum('男','女'), hobby set('下棋','打篮球','游泳','跑步','跳绳'));desc investigation;
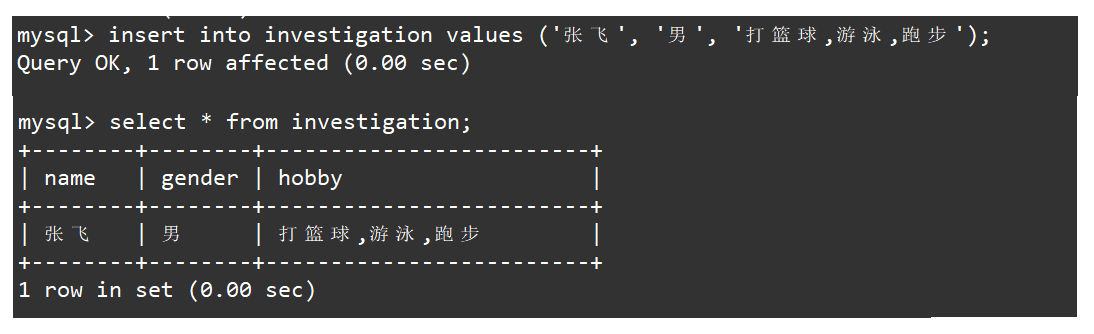
向表中插入记录时,被调查人的性别只能从男和女中进行二选一,被调查人的爱好可以从提供的若干个选项中进行多选一或多选多,多个爱好之间需要通过英文逗号隔开。如下:
insert into investigation values ('张飞', '男', '打篮球,游泳,跑步');
select * from investigation;
在插入记录时,除了通过指明男女来设置性别,还可以通过插入数字1和2来设置性别。如下:
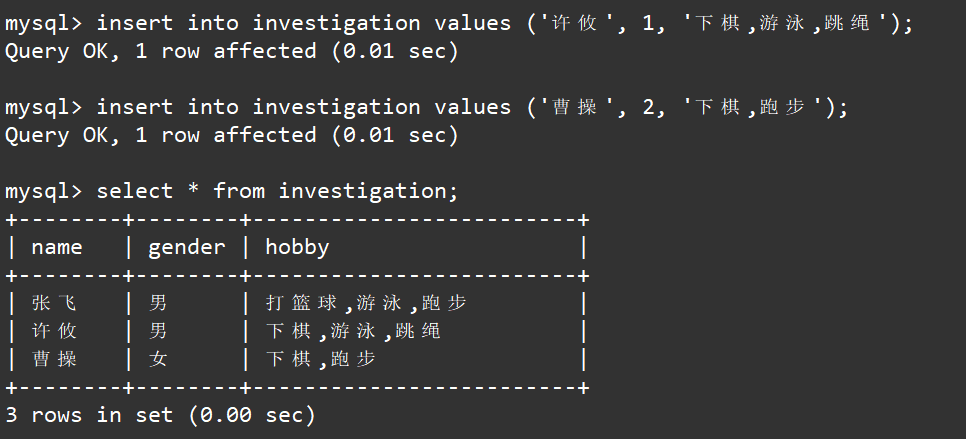
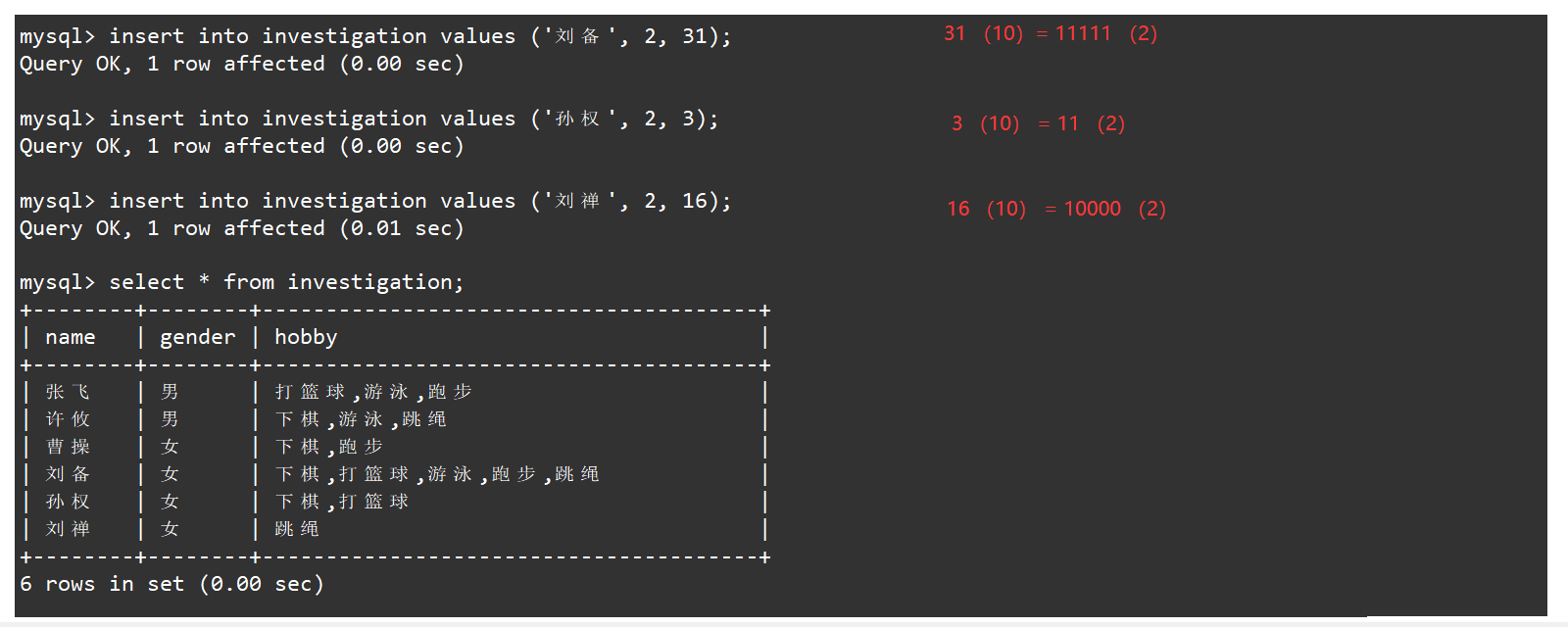
在插入记录时,除了通过指明多个选项来设置爱好,还可以通过数字的方式来设置,(对应的比特位进行映射,例如31的比特位为全1,对应的就是五个爱好全部插入)。如下:
enum和set查找
where子句进行 「行匹配」
SELECT 选项 表名称 WHERE 字段=想要匹配的信息
如果想要筛选出调查表中所有女生的信息,那么直接在select筛选时指明gender='女'即可。
select * from investigation where gender='女';

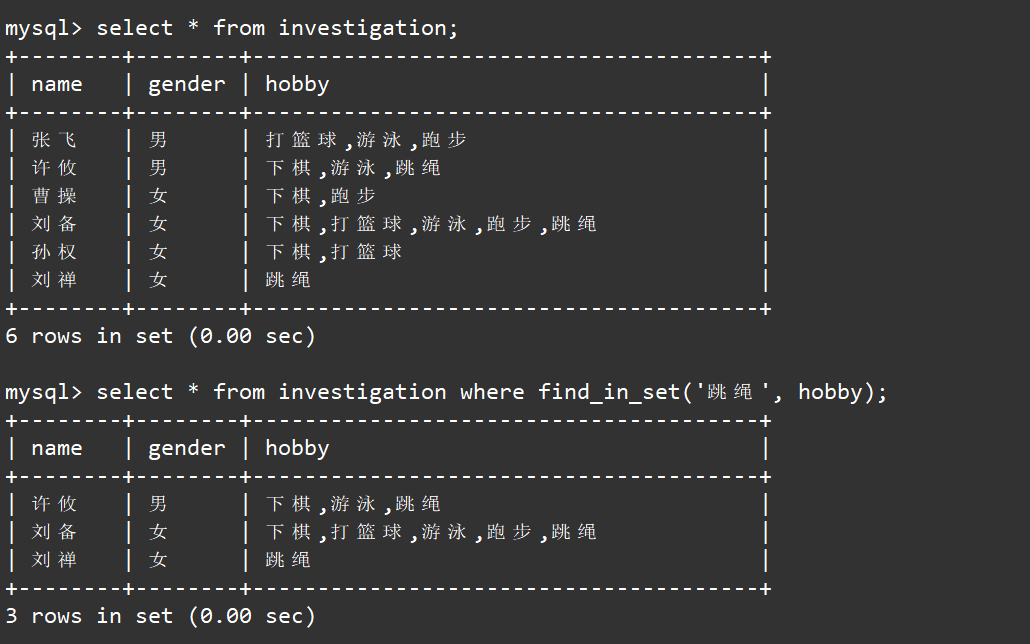
但是对于set类型我们使用where子句,进行的匹配是严格匹配,例如我们想要筛选出所有喜欢跳绳的人:
select * from investigation where hobby='跳绳';
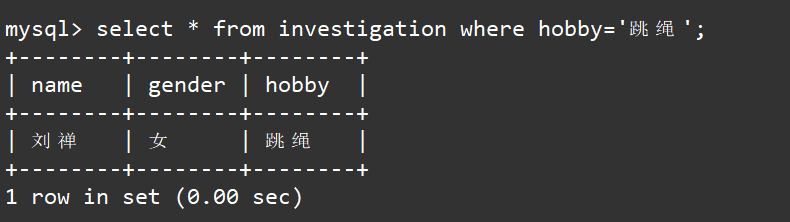
我们只是匹配到了刘禅,而没有匹配到其他人,要解决这个问题我们就要要借助MySQL给我们提供的find_in_set(str,strlist)函数了。
find_in_set(str,strlist)集合查找
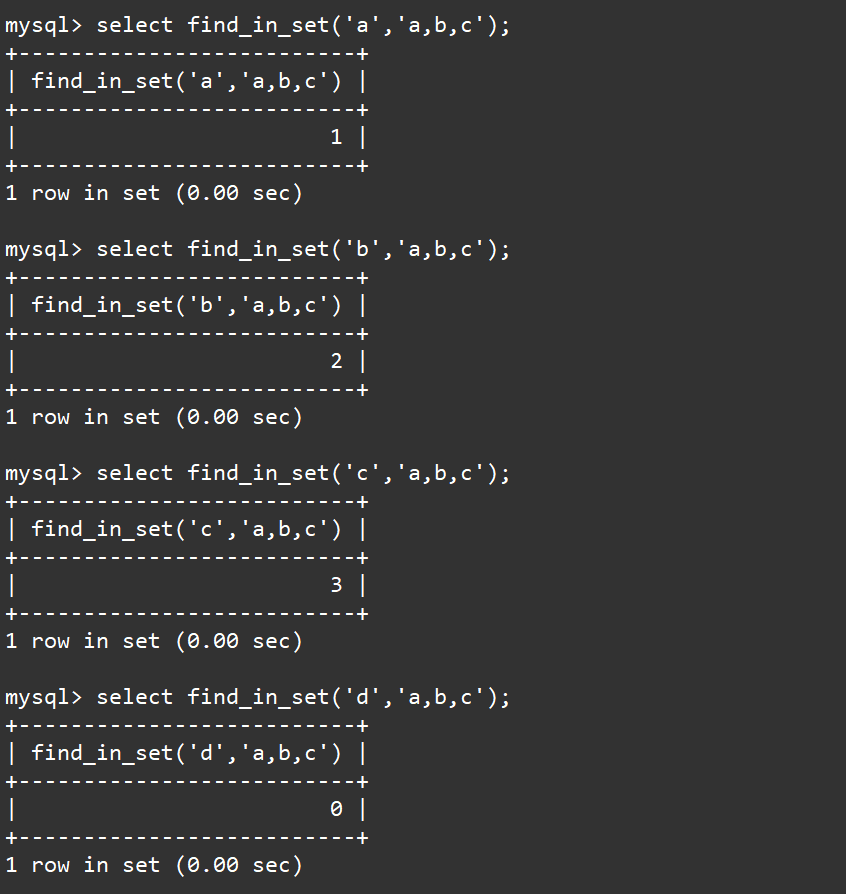
该函数的作用是查询strlist中是否包含str,如果包含则返回str在strlist中的位置(从1开始),否则返回0。
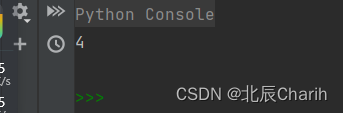
通过select可以对find_in_set函数进行验证,依次查找集合a,b,c中是否包含字符a、b、d,这时在查找字符a和b时就会得到其在集合中的下标,而在查找字符d时就会得到0值。如下:
这时就可以通过select搭配find_in_set函数,来筛选出爱好包含跳绳的人的信息了。如下: