DeepSpeed数据并行研究
1. 技术调研
a. DeepSpeed
DeepSpeed是一个开源深度学习训练优化库,其中包含一个新的显存优化技术—— ZeRO(零冗余优化器)。该框架包含四个技术亮点:
用 3D 并行化实现万亿参数模型训练: DeepSpeed 实现了三种并行方法的灵活组合,它们分别为ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。
ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型:ZeRO-Offload背后的核心技术是在ZeRO-2的基础上将优化器状态和梯度卸至CPU内存,通过同时利用GPU和宿主CPU的计算和存储资源,提升了较少的GPU资源下可以高效训练的最大模型规模。
通过 DeepSpeed Sparse Attention 用6倍速度执行10倍长的序列: DeepSpeed提供了sparse attention kernel ——一种工具性技术,它可以支持长序列的模型输入,包括文本输入,图像输入和语音输入。与经典的稠密 Transformer 相比,它支持的输入序列长一个数量级,并在保持相当的精度下获得最高 6 倍的执行速度提升。但由于该技术仅支持A100显卡,因此现有的实验环境暂时无法将该技术投入公司应用。
OneBitAdam 减少 5 倍通信量: Adam 是一个在大规模深度学习模型训练场景下的高效的(也许是最广为应用的)优化器。然而,它与通信效率优化算法往往不兼容。因此DeepSpeed将误差补偿压缩的方法与Adam优化器相结合,提供了OneBitAdam优化器,大大减少了通信量并提升了训练速度。
b. ZeRO
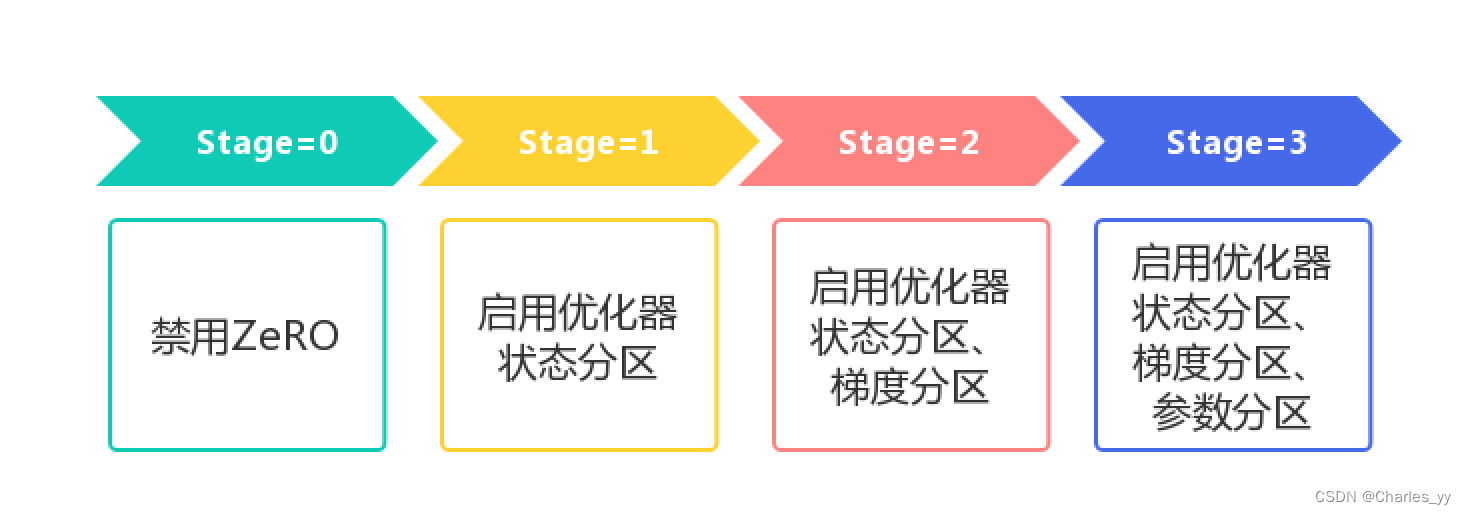
DeepSpeed提供了ZeRO内存优化技术供用户使用。ZeRO主要是参考了Megatron-LM中张量并行的思想,对训练过程中的优化器状态、梯度、模型参数进行分区,减少了冗余内存,实现了内存的优化。以下是DeepSpeed配置中Zero参数Stage的含义:
zero_stage=0表示禁用ZeRO;
zero_stage=1表示启用优化器状态分区;
zero_stage=2表示启用优化器状态分区和梯度分区;
zero_stage=2表示启用优化器状态分区、梯度分区和参数分区。
c. 模型简介:opt-1.3b
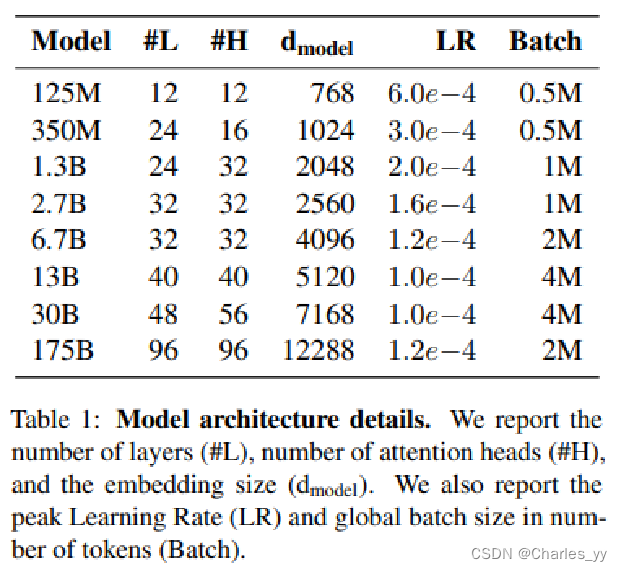
为了使得测试过程中获取实验结果的效率更高,基于DeepSpeed框架进行的实验采用的模型是opt-1.3b,接下来对该模型进行简要介绍。OPT(Open Pre-trained Transformer Language Models)是由FaceBook的研究人员发布并开源的大语言模型,其参数规模高达1750亿,与GPT-3几乎一样。由于GPT-3并未开源,使得研究人员无法对这个强大的模型进行进一步探索,在这样的背景下,OPT模型诞生了,其完成任务的水平几乎与GPT-3的水平一致。OPT模型版本如表格所示:
d. 数据集简介:Dahoas/rm-static
用于opt-1.3b有监督精调的数据集为rm-static,其数据样本如下表所示。由于有监督微调以问答对的形式进行指令对齐,因此样本需要以问答对的形式出现。其中,Promp表示给定的上下文或情境,是对话或文本的背景信息,可以帮助模型更好地理解对话或者文本的语义语境;Response则表示模型需要生成的回复或文本,是模型需要预测的目标。

2. DeepSpeed调参实验
为了获取适用于实验环境的DeepSpeed参数,为后续实验提供参考,我们进行了基于DeepSpeed框架的调参实验。为了使得测试过程中获取实验结果的效率更高,我们选取了参数较少的模型opt-1.3b进行实验,测试其有监督微调的实验过程。调参实验主要分为两大部分,分别为基于OneBitAdam优化器相关参数的调参实验和基于ZeRO相关参数的调参实验,下面将对其进行详细介绍。
a. OneBitadam
大模型(如 BERT 和 GPT-3)的扩展训练需要基于模型设计,体系结构和系统功能的细致优化。从系统的角度来看,通信效率已成为主要的瓶颈。解决该问题需要压缩通信,而压缩通信的最有效方法之一是误差补偿压缩,即使在1比特压缩下,它也可以提供稳定的收敛速度。但是,最新的误差补偿技术仅适用于一些和梯度线性相关的简单优化器,例如随机梯度下降(SGD)和 Momentum SGD。这些技术无法和 Adam 之类的非线性优化器整合,后者在许多任务(包括训练类似 BERT 的模型)中带来了最好的收敛率和精度。
因此DeepSpeed提供了OneBitAdam优化器,它是DeepSpeed博客中介绍的4大亮点之一。博客中介绍到,他能够减少5倍的通信量并提升3.4倍的训练速度,因此我们基于该优化器进行了实验,观察GPU Memory-Usage和CurrSamplesPerSec能否取得提升。
ⅰ. 实验结果
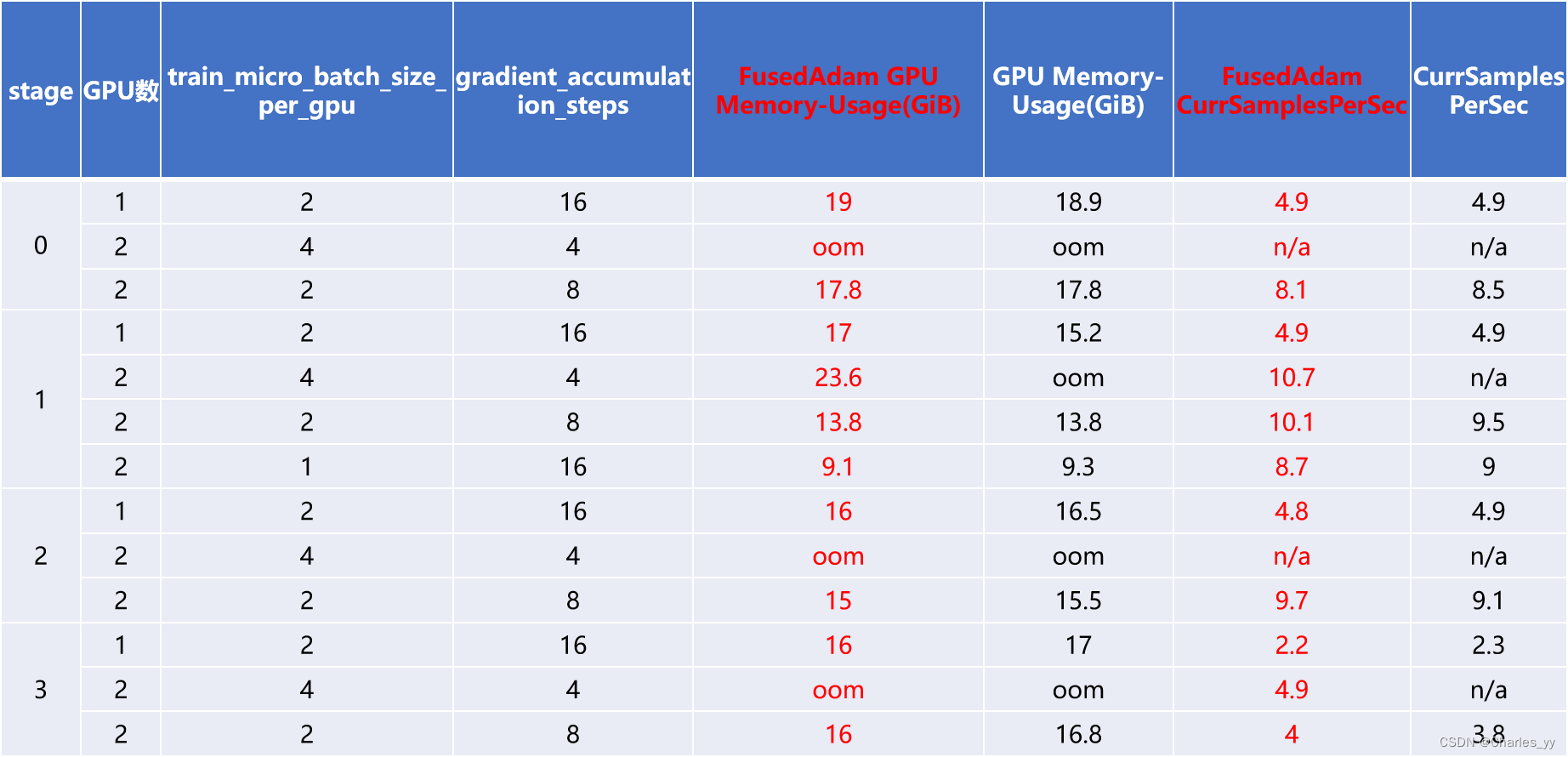
ⅱ. 实验结论
OneBitAdam优化器主要影响的是模型的训练过程,对于GPU Memory-Usage(GiB)、CurrSamplesPerSec这些关键参数影响不大。
b. ZeRO
在调参实验中,我们先对ZeRO相关的所有参数做了一次实验,单次实验只改变一个实验参数,最后锁定了与zero_stage=3相关的三个参数以及参数reduce_bucket_size,针对这些参数进行了一系列调参实验。在各个调参实验中,针对各个参数示例代码中的值以及官方文档中的默认值确定实验参数变化的上下阈值,再在实验过程中找出一个变化约呈线性的范围,观察实验结果。最后确定一个GPU内存使用较小,每秒钟处理的样本数又较多的值作为后续试验的参考值。
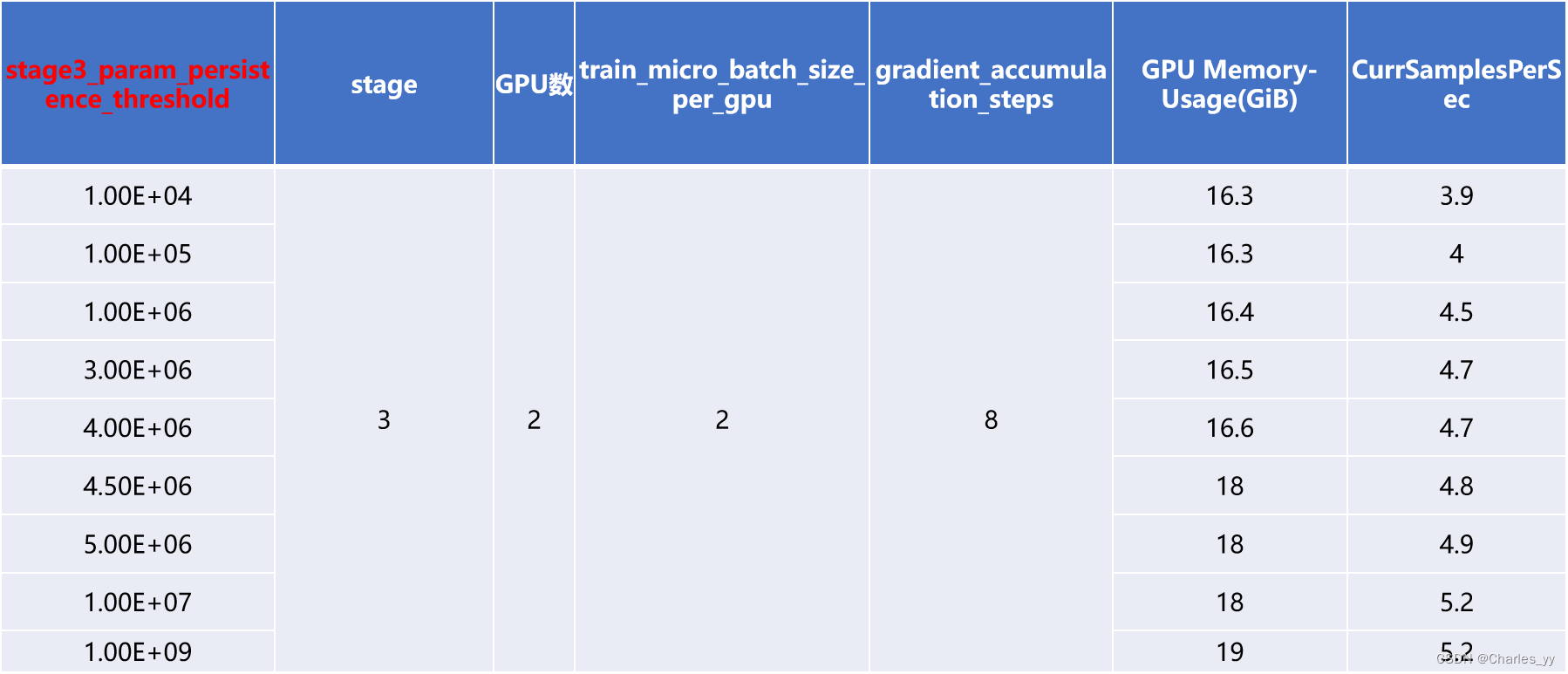
ⅰ. stage3_param_persistence_threshold
stage3_param_persistence_threshold表示进行参数分区时,当参数量小于该阈值,则不进行参数分区,参数量高于该阈值才进行参数分区。因此较小的值使用较少的内存,但可以大大减少通信代价。以下是基于该参数进行调参实验获得的实验结果:
ⅱ. stage3_max_live_parameters
stage3_max_live_parameters表示释放前每个GPU允许驻留的最大参数数量。较小的值使用较少的内存,但执行更多的通信。以下是基于该参数进行调参实验获得的实验结果:

ⅲ. stage3_prefetch_bucket_size
stage3_prefetch_bucket_size表示用于预取参数的缓冲区的参数数量。较小的值使用较少的内存,但可能会因通信而增加停顿。以下是基于该参数进行调参实验获得的实验结果:
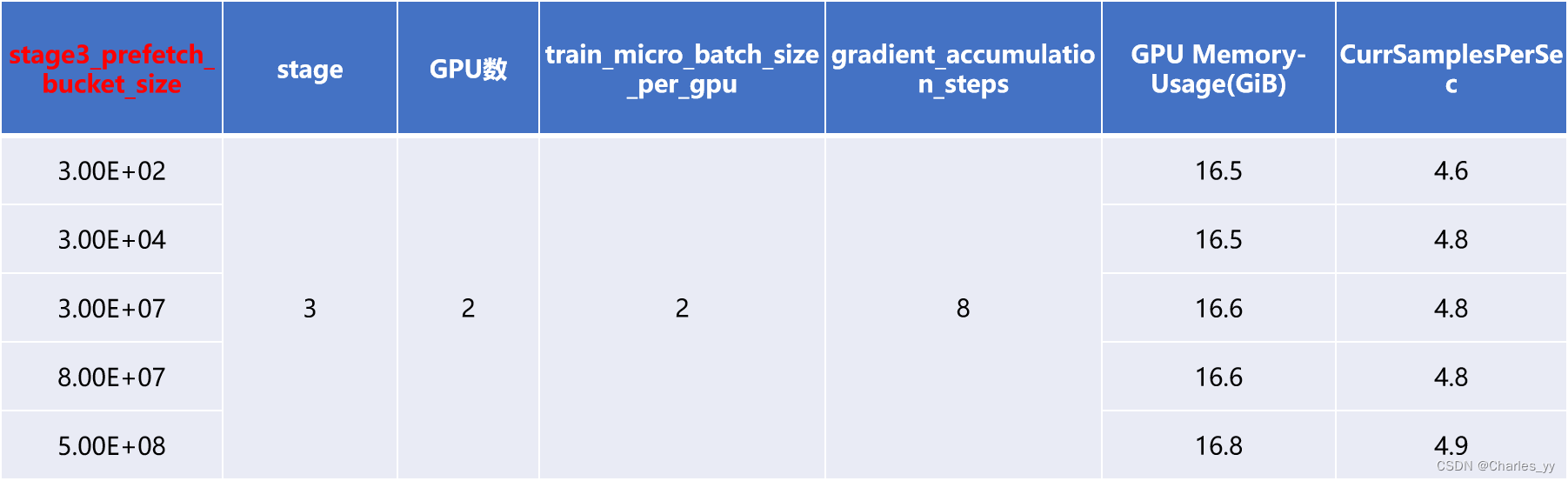
ⅳ. reduce_bucket_size
除了以上三个参数外,还对参数reduce_bucket_size进行了调参实验,该参数表示一次reduced/allreduced的元素数量。限制大模型进行allgather所需的内存。 以下是基于该参数进行调参实验获得的实验结果:

c. 实验结论
ZeRO相关参数调参实验结论:stage3_param_persistence_threshold、stage3_max_live_parameters、reduce_bucket_size等参数对内存影响较大,当内存遇到out of memory的情况时可以适当调节以上参数使得程序能够正常进行。最后的参数确定为如下值:

3. DeepSpeed工具模块的探索学习
a. Autotuning
ⅰ. 功能概述
Autotuning是DeepSpeed提供的一个可用于自动参数调节的工具库, 但是其可自动调节参数较少,仅包括ZeRO stage, micro-batch size per GPU和ZeRO configurations (offloading is not yet supported)。要想得到更细致的调参结果,还需依赖于人工调参实验。
ⅱ. 运行结果
目前的实验条件显存不足,暂时无法调用该工具库

b. Flops Profiler
ⅰ. 功能概述
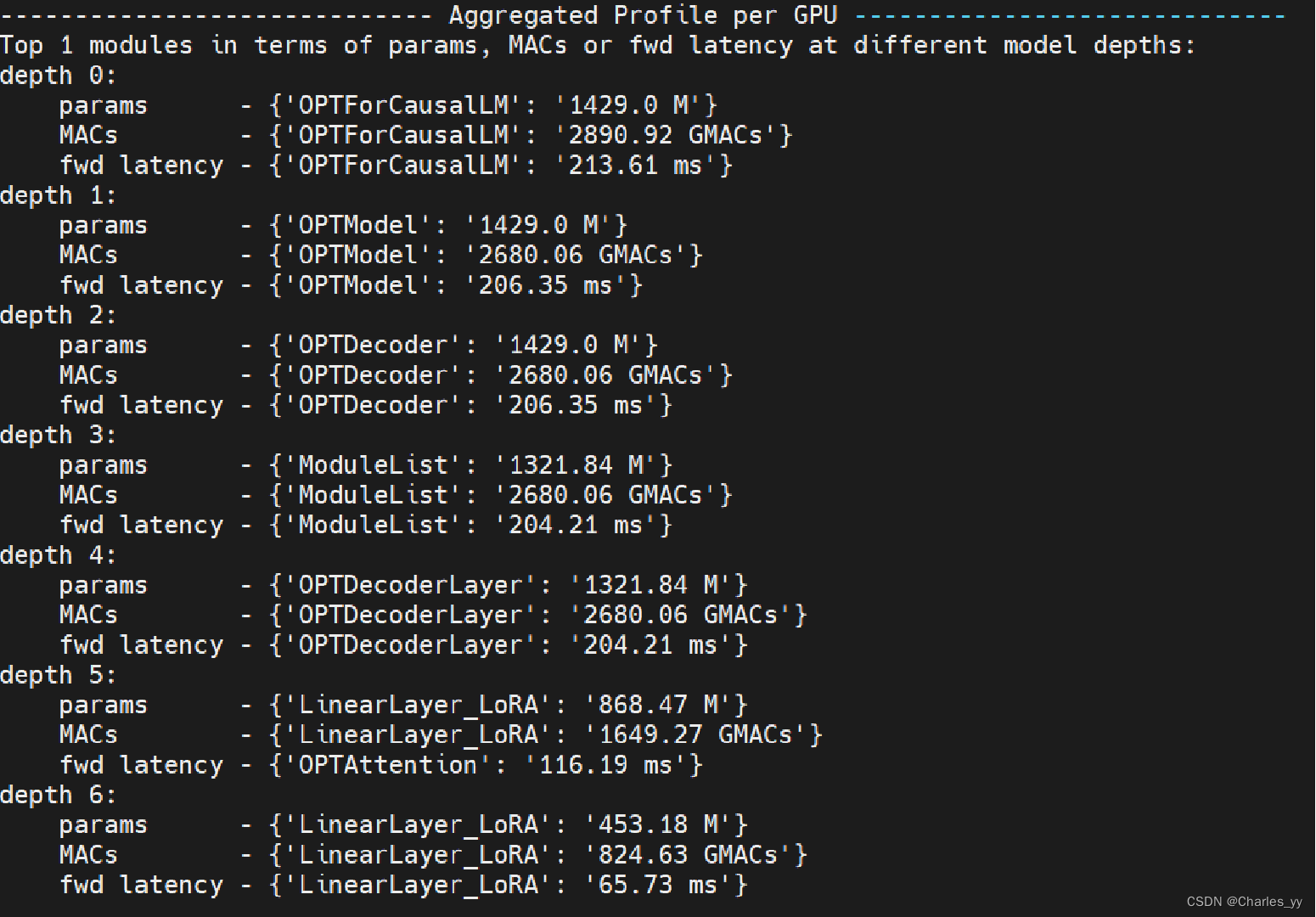
DeepSpeed Flops Profiler 是由DeepSpeed提供的一个分析器,可帮助用户测量模型及其子模块的模型训练/推理速度(延迟、吞吐量)和效率(每秒浮点运算数,即 FLOPS),着眼于消除现有实验中的低效率问题。DeepSpeed Flops Profiler 能够输出模型的参数数量、浮点运算 (flops)、FLOPS、延迟和吞吐量(以样本/秒为单位),帮助用户调整训练或推理设置以获得更好的性能。用户可以了解每个层或子模块如何对整体模型复杂性/性能做出的贡献,从而调整或重构模型设计以提高性能。例如,使用分析器,DeepSpeed 用户可以定量地判断堆叠较小的层是否比堆叠较大的层更轻或性能更高。
ⅱ. 实验结果
以下为调用该工具的效果截图。该分析工具能输出对一些基本信息的概述,还同时也会显示在不同模型深度下参数量、加乘运算或前向计算延迟排名前1的模块。

c. Data Efficiency
ⅰ. 功能概述
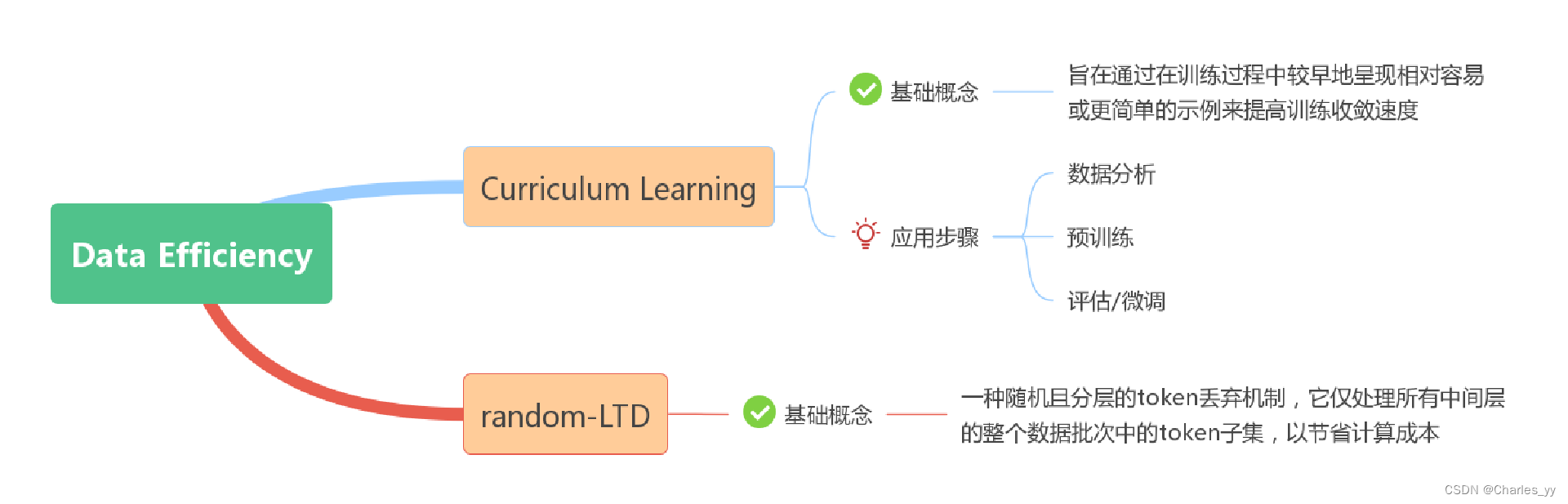
DeepSpeed 数据效率库是一个可组合框架,可以更好地利用数据、提高训练效率并提高模型质量。DeepSpeed Data Efficiency 考虑了可扩展性、灵活性和可组合性,具体体现了以下创新:通过课程学习进行有效的数据采样;提出了一种称为随机分层令牌丢弃(随机LTD)的新颖数据路由技术,以跳过所有中间层输入令牌子集的计算。
其中,课程学习旨在通过在训练过程中较早地呈现相对容易或更简单的示例来提高训练收敛速度。要运用课程学习,共包含三个应用步骤,分别是数据分析、预训练、评估/微调。
而 random-LTD是一种随机且分层的token丢弃机制,它仅处理所有中间层的整个数据批次中的token子集,以节省计算成本。
实现难点:由于课程学习的应用步骤并非并列的关系,且现有的实验环境不足以支持模型的预训练,因此该工具无法直接用于微调,仅作了解。
4. DeepSpeed双机四卡的有监督微调实验
代码在A和B服务器上都有部署。该实验使用的是Dahoas/rm-static数据集对opt-1.3b模型进行有监督微调,使用的虚拟环境为peft,共跑通了两组多机并行实验:
双机双卡:A:GPU1@B:GPU1
双机四卡:A:GPU0,GPU1@B:GPU0,GPU1
a. 如何运行脚本文件
ⅰ. 打开防火墙端口以便双机通信,在终端输入以下命令:
sudo firewall-cmd --zone=public --add-port=33000-65000/tcp --permanent
sudo firewall-cmd --reload
ⅱ. 确定要使用的GPU,修改parallelism_main_sft.sh
ⅲ. 直接在终端运行./parallelism_main_sft.sh。
ⅳ. 为保证服务器安全,实验结束后需要关闭端口,在终端输入以下命令:
sudo firewall-cmd --zone=public --remove-port=33000-65000/tcp --permanent
sudo firewall-cmd --reload
b. 多机环境配置问题汇总
ⅰ. ssh免密通信配置(参考:https://www.cnblogs.com/zpzp7878/p/10466973.html)
本机的sshkey也要拷贝到自己的authorized_keys中,步骤与上一条所述相同(可做可不做),我做到上一步已经可以实现ssh免密通信。
ⅱ. hostfile的编辑
直接写ip地址,不需要写server1、server2,其中slots表示每台服务器上可用的GPU个数
ⅲ. nccl通信问题
要想详细查看NCCL的日志输出从而锁定问题,需要配置环境变量NCCL_DEBUG,在.bash文件头加上环境变量:
export NCCL_DEBUG=INFO:
export NCCL_SOCKET_IFNAME=eth1,eno2
则在程序运行的过程中会依次找名字为eth1,eno2的网卡。
- 查看防火墙状态: 这会显示防火墙是否正在运行以及当前的防火墙策略;
-
- systemctl status firewalld
- 查看防火墙规则: 这会列出当前设置的防火墙规则,包含被允许通信的端口。
-
- firewall-cmd --list-all
- 其余防火墙配置参考本节 a(i) 即可。
c. 实验结果
以下为基于DeepSpeed框架,采用Dahoas/rm-static对opt-1.3b模型进行有监督微调获得的实验结果:

实验结论:使用单机双卡每秒钟处理的样本数为10.1。由于通讯的问题,使用双机双卡会使得每秒钟处理的样本数约为单机双卡的一半;双机四卡相较于双机双卡会使得每秒钟处理的样本数有所提升,但并非呈线性增长;双机四卡相较于双机双卡每块GPU消耗显存有所减少。
5. 基于现有实验环境对于LORA精调全参数微调llama2-7b的测试实验
掌握了DeepSpeed多机并行的运行方法后,我们结合现有的实验环境,进行了一系列测试实验,为后续实验以及算力资源的购置提供参考。
a. opt-1.3b的全参数微调测试
ⅰ. 实验结果
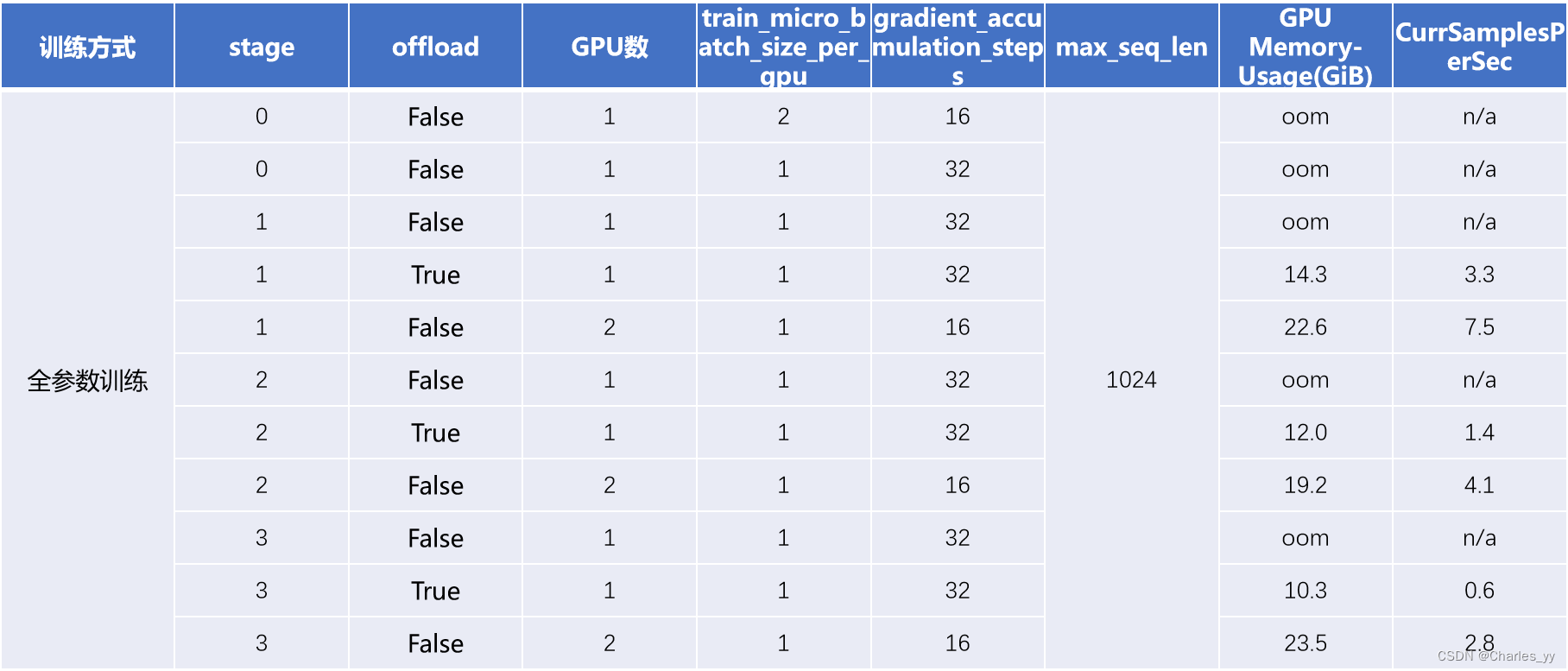
ⅱ. 实验结论
若不启用ZeRO-Offload技术,以现有的实验资源无法进行opt-1.3b的全参数微调。
b. llama2-7b的全参数精调测试
ⅰ. 实验结果
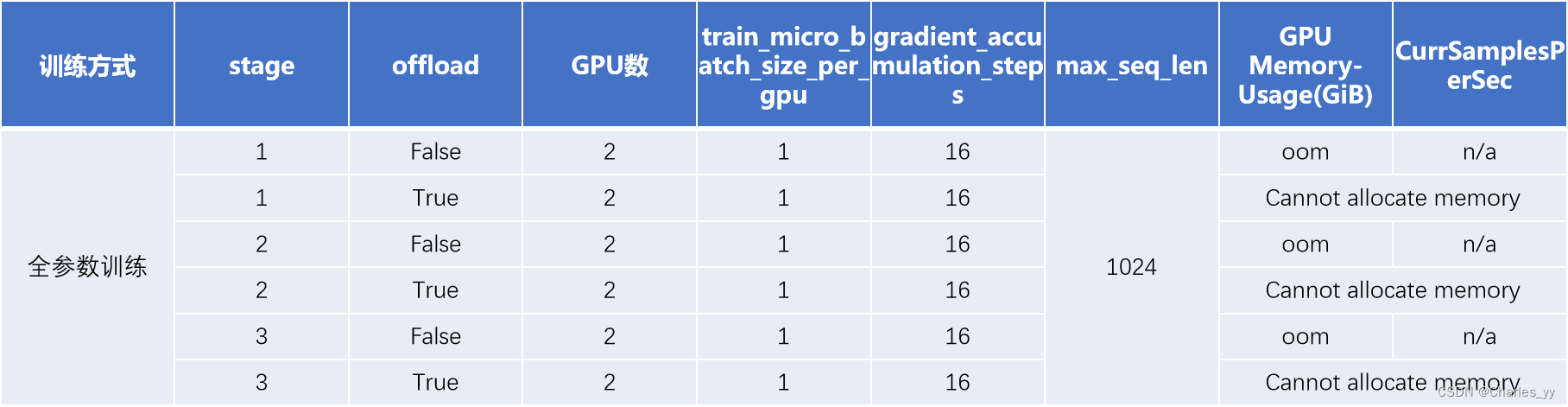
ⅱ. 实验结论
以现有的实验资源无法进行llama2-7b的全参数微调。
c. llama2-7b的LORA精调测试(max_seq_len=1024)
ⅰ. 实验结果
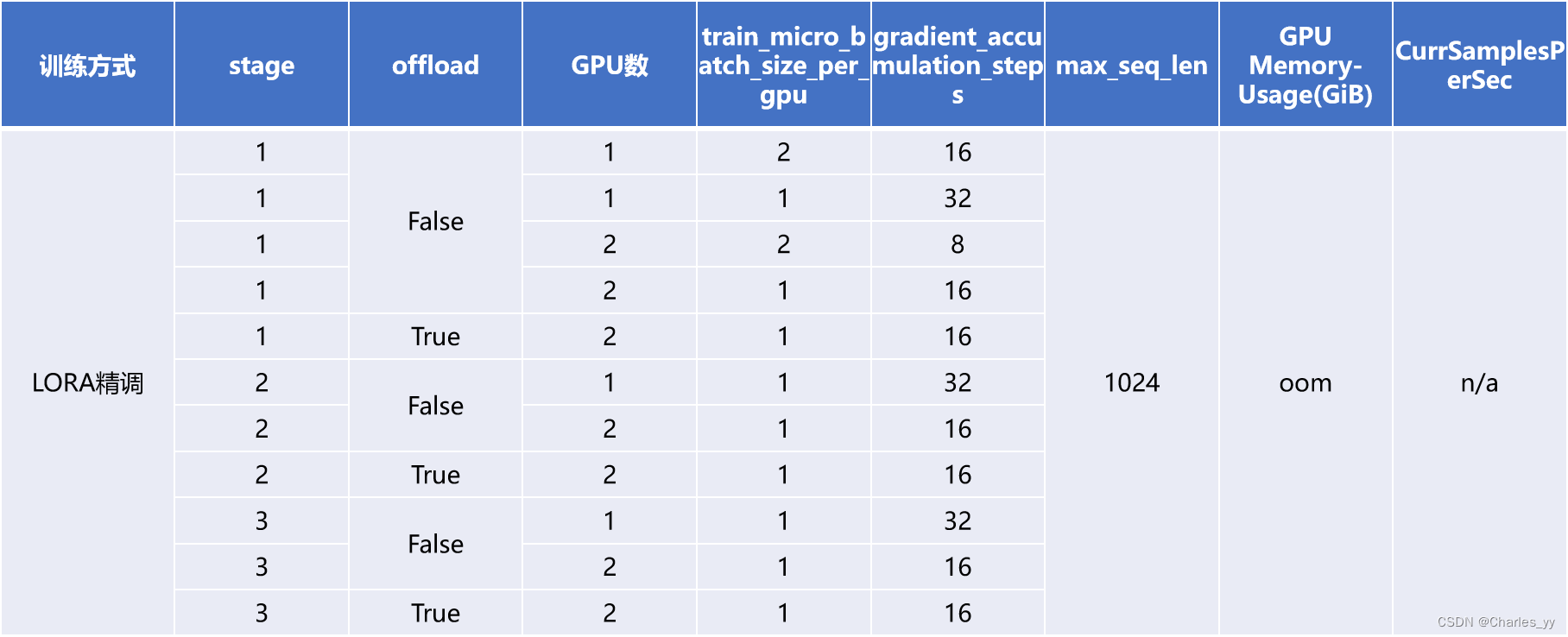
ⅱ. 实验结论
以现有的实验资源,若固定max_seq_len=1024,则无法进行llama2-7b的全参数微调。
d. llama2-7b的LORA精调测试(改变max_seq_len)
ⅰ. 实验结果
在实验过程中,固定batch_size=1,改变最大序列长度max_seq_len,测试在不同的zero_stage、不同的卡数下不同微调方法能够支持最大的序列长度。
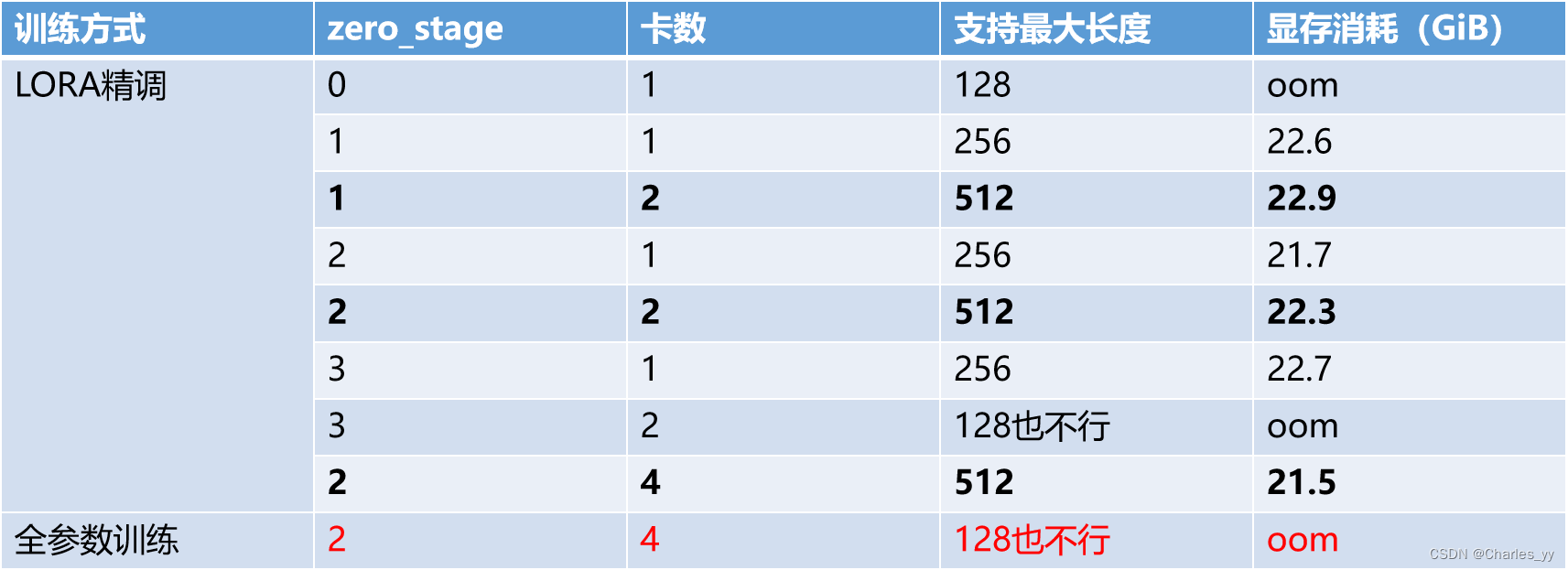
ⅱ. 实验结论
从表格中我们可以看到,对于llama2-7b模型,除zero_stage为0以外,单机单卡对该模型进行LORA精调支持的最大长度都为256,zero_stage为1或2时,单机双卡和双机四卡对llama2-7b模型进行LORA精调的最大长度都为512。而对于llama2-7b模型的全参数训练,现有的实验环境双机四卡也无法实现。
现有的实验环境仅支持llama2-7b模型的LORA精调,且训练中最大序列长度仅为512;只有当train_micro_batch_size_per_gpu为1时,精调才能够运行起来,但同时每秒钟能处理的样本数也极小。





![单词接龙[中等]](https://img-blog.csdnimg.cn/direct/ecdc160d132d4d6983fd3aaf2ab4dc2c.png)


