官网:https://huggingface.co/docs/accelerate/package_reference/accelerator
Accelerate使用步骤
- 初始化accelerate对象accelerator = Accelerator()
- 调用prepare方法对model、dataloader、optimizer、lr_schedluer进行预处理
- 删除掉代码中关于gpu的操作,比如.cuda()、.to(device)等,让accelerate自行判断硬件设备的分配
- 将loss.backbard()替换为accelerate.backward(loss)
- 当使用超过1片GPU进行分布式训练时,在主进程中使用gather方法收集其他几个进程的数据,然后在计算准确率等指标
Accelerator对象初始化参数
- device_placement (bool, optional, defaults to True) — 是否让accelerate来确定tensor应该放在哪个device
- split_batches (bool, optional, defaults to False) — 分布式训练时是否对dataloader产生的batch进行split,如果True,那么每个进程使用的batch size = batch size / GPU数量,如果是False,那么每个进程使用就是batch size,总的batch size = batch size * GPU数量
- mixed_precision (str, optional) — 是否使用混合精度训练
- gradient_accumulation_steps (int, optional, default to 1) — 梯度累加的步数,也可以使用GradientAccumulationPlugin插件进行详细配置
- cpu (bool, optional) — 是否强制使用CPU执行
- deepspeed_plugin (DeepSpeedPlugin, optional) — 使用此参数调整与DeepSpeed相关的参数,也可以使用accelerate config直接配置
- fsdp_plugin (FullyShardedDataParallelPlugin, optional) — 使用此参数调整FSDP(Fully Sharded Data Parallel)相关参数,也可以使用accelerate config直接配置
- megatron_lm_plugin (MegatronLMPlugin, optional) — 使用此参数调整与MegatronLM相关的参数,可以使用accelerate config直接配置
- step_scheduler_with_optimizer (bool, *optional, defaults to True) – lr_scheduler是否和optimizer同步更新
- gradient_accumulation_plugin (GradientAccumulationPlugin, optional) — 梯度累积插件
Accelerate常用高阶用法
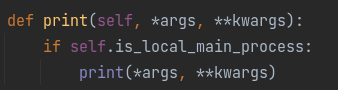
- accelerator.print()
当使用多片GPU训练时,打印每个进程的信息,替换python的print函数,这样在每个server上只打印一次,其实就是先使用is_local_main_process判断的print。
- accelerator.is_local_main_process
可以当做装饰器使用,在一个具有多片GPU的server上只执行一次,local表示每台机器。与is_local_main_process对应的是is_main_process,is_local_main_process每个server上的主进程,is_main_process是所有server的主进程。
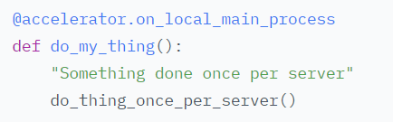

- wait_for_everyone()
同步控制,确保在后续操作之前所有前提操作已完成 - accelerator.save_model() / load_state_dict /
load_checkpoint_in_model
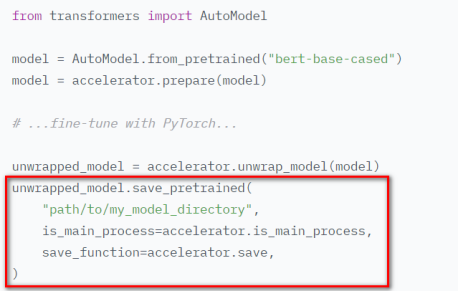
模型保存,自动去除掉由于分布式训练在模型上做的包装(调用unwrap_model),保存state_dict,并且可以对大模型文件进行分块存储。并加载保存的模型 - Accelerate与Transformers库搭配使用进行模型保存

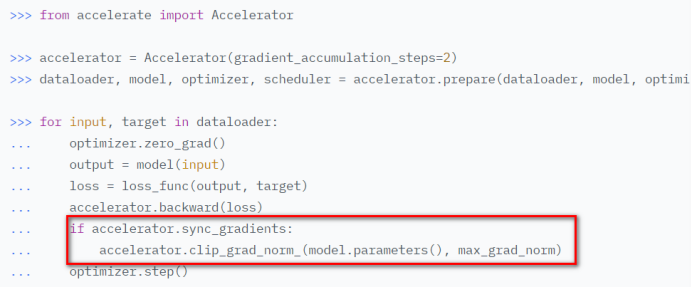
- 使用accelerator做梯度裁剪:

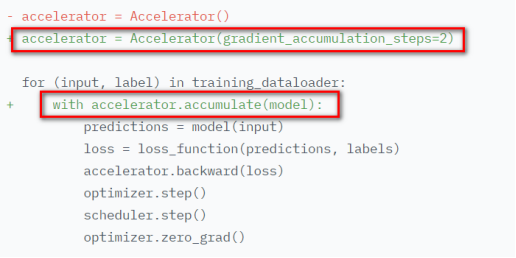
- 梯度累加gradient accumulation
尤其对于超大规模的模型,模型参数本来就已经很大了,如果再用很大的batch size进行训练,硬件资源吃不消,但是如果用很小的batch size训练的话模型稳定性很差,所以梯度累加gradient accumulation是一个这种的解决方案,其实就是连续执行多次forward前向过程,在多次执行期间不进行反向传播,每次都是很小的batch size,多次就累积成了比较大的batch size,然后在累积的结果上做反向传播。Accelerate在梯度累加期间暂停在不同GPU之间的梯度同步,进一步减少了通信数据量。
GradientAccumulationPlugin提供了更灵活梯度累加操作,除了能指定累加的步数,还能指定在累计过程中是否更新lr_scheduler调节器。

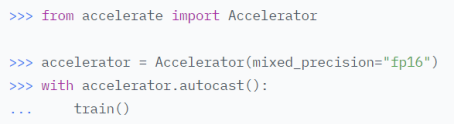
- autocast混合精度训练
对处于with上下文管理中的模块使用混合精度训练
- gather、gather_for_metrics
分布式训练时,在不同进程之间回收结果数据 - Prepare
为分布式训练和混合精度做准备,然后以相同的顺序返回它们。 - reduce:跨进程做tensor的reduce操作
- save_state / load_state:保存、加载模型的状态数据
- unscale_gradients:混合训练过程中不对梯度进行缩放

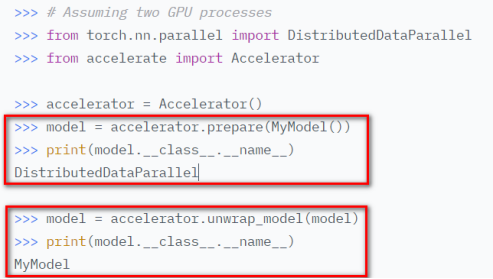
- unwrap_model
去掉模型上由prepare加上的用于做分布式训练的包装层,在保存模型的时候比较有用
4、使用accelerate执行分布式训练
- 执行accelerate config根据提问和实际硬件情况设置配置文件
- 执行accelerate test --config_file path_to_config.yaml验证环境配置是否正常
- 执行进行命令进行分布式训练,accelerate launch --config_file path_to_config.yaml path_to_script.py --args_for_the_script
5、使用Accelerate在低资源环境下加载大的模型
- 参考:https://huggingface.co/docs/accelerate/usage_guides/big_modeling