特征工程系列:特征选择的综合指南
特征选择是从一个较大的特征集中选择最佳数量的特征的过程。这个特征选择过程有几个优点,也有各种各样的技术可用于这个特征选择过程。在这个内核中,我们将看到这些优点和各种特征选择技术。
目录
- 特征选择简介
- 过滤方法
- 2.1. 基本方法
- 2.1.1 移除常量特征
- 2.1.2 移除准常量特征
- 2.2 单变量选择方法
- 2.2.1 SelectKBest
- 2.2.2 SelectPercentile
- 2.3 信息增益
- 2.4 Fisher得分(卡方实现)
- 2.5 ANOVA F值特征选择
- 2.6 带热力图的相关矩阵
- 包装方法
- 3.1 前向选择
- 3.2 后向消除
- 3.3 穷举特征选择
- 3.4 递归特征消除
- 3.5 带交叉验证的递归特征消除
- 嵌入方法
- 4.1 LASSO回归
- 4.2 随机森林重要性
- 如何选择合适的特征选择方法
- 特征选择的技巧和窍门
- 参考文献
1. 特征选择简介
目录
特征选择
- 特征选择或变量选择是从数据集中选择与机器学习算法构建相关特征或变量的子集的过程。
选择特征的优势
-
特征选择过程具有各种优势。如下所示:
- 提高准确性
- 简单模型更易于解释。
- 训练时间更短
- 通过减少过拟合来增强泛化能力
- 软件开发人员更易于实现
- 通过模型使用减少数据错误的风险
- 变量冗余
- 高维空间中的不良学习行为
特征选择 - 技术
-
特征选择技术分为3种类型。如下所示:
- 过滤方法
- 包装方法
- 嵌入方法
过滤方法
-
过滤方法包括以下各种技术:-
- 基本方法
- 单变量方法
- 信息增益
- Fischer分数
- 带有热图的相关矩阵
包装方法
-
包装方法包括以下技术:-
- 正向选择
- 后向消除
- 全部特征选择
- 递归特征消除
- 带交叉验证的递归特征消除
嵌入方法
-
嵌入方法包括以下技术:-
- LASSO
- 岭回归
- 树重要性
-
现在,我们将详细讨论这些方法。
2. 过滤方法
目录
-
过滤方法通常用作预处理步骤。特征选择与任何机器学习算法无关。相反,特征是根据它们在各种统计测试中与结果变量的相关性得分来选择的。这些方法的特点如下:
- 这些方法依赖于数据的特征(特征的特点)
- 它们不使用机器学习算法。
- 它们是模型无关的。
- 它们往往计算成本较低。
- 它们通常给出比包装器方法更低的预测性能。
- 它们非常适合快速筛选和删除不相关的特征。
-
过滤方法包括以下各种技术:
- 2.1. 基本方法
- 2.2. 单变量特征选择
- 2.3. 信息增益
- 2.4. Fischer得分
- 2.5. 特征选择的ANOVA F-值
- 2.6. 带有热图的相关矩阵
-
可以通过以下图形来解释过滤方法:

2.1 基本方法
目录
- 在基本方法中,我们移除常数和准常数特征。
2.1.1 移除常量特征
目录
-
常量特征是指在数据集的所有观察中都显示相同值的特征。也就是说,数据集的所有行都具有相同的值。这些特征不提供任何信息,无法让机器学习模型进行区分或预测目标。
-
识别和移除常量特征是进行特征选择和更易解释的机器学习模型的简单第一步。要识别常量特征,我们可以使用sklearn中的VarianceThreshold函数。
-
使用Kaggle上的Santander客户满意度数据集来识别常量特征。
-
来源:
-
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.VarianceThreshold.html
-
https://scikit-learn.org/stable/modules/feature_selection.html
# 导入所需的库
import numpy as np # 线性代数库
import pandas as pd # 数据处理库,用于CSV文件的读写
import matplotlib.pyplot as plt # 数据可视化库
import seaborn as sns # 数据可视化库# 输入数据文件在"/kaggle/input/"目录下
# 例如,运行以下代码(点击运行或按Shift+Enter)将列出输入目录下的所有文件
import os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))# 将任何结果写入当前目录,保存为输出文件。
/kaggle/input/mushroom-classification/mushrooms.csv
/kaggle/input/santander-customer-satisfaction/train.csv
/kaggle/input/santander-customer-satisfaction/test.csv
/kaggle/input/santander-customer-satisfaction/sample_submission.csv
/kaggle/input/house-prices-advanced-regression-techniques/train.csv
/kaggle/input/house-prices-advanced-regression-techniques/test.csv
/kaggle/input/house-prices-advanced-regression-techniques/sample_submission.csv
/kaggle/input/house-prices-advanced-regression-techniques/data_description.txt
# 忽略警告信息import warnings
warnings.filterwarnings('ignore')
# 导入Kaggle上的Santander客户满意度数据集# 从Kaggle上读取训练数据集train.csv的前35000行,并将其存储在变量X_train中
X_train = pd.read_csv('/kaggle/input/santander-customer-satisfaction/train.csv', nrows=35000)# 从Kaggle上读取测试数据集test.csv的前15000行,并将其存储在变量X_test中
X_test = pd.read_csv('/kaggle/input/santander-customer-satisfaction/test.csv', nrows=15000)
# 从X_train中删除'TARGET'标签列# 使用drop函数删除指定的标签列'TARGET',axis=1表示按列删除,inplace=True表示在原数据上进行修改
X_train.drop(labels=['TARGET'], axis=1, inplace=True)
# 检查训练集和测试集的形状# 输出训练集的形状
X_train.shape# 输出测试集的形状
X_test.shape
((35000, 370), (15000, 370))
重要提示
- 在所有特征选择过程中,通过仅检查训练集来选择特征是一个好的实践。这样做是为了避免过拟合。
使用sklearn中的方差阈值
- sklearn中的方差阈值是一种简单的特征选择基准方法。它会移除所有方差不满足某个阈值的特征。默认情况下,它会移除所有方差为零的特征,即在所有样本中具有相同值的特征。
# 导入所需的库
from sklearn.feature_selection import VarianceThreshold# 创建一个VarianceThreshold对象,设置阈值为0
sel = VarianceThreshold(threshold=0)# 使用训练集数据拟合VarianceThreshold对象
sel.fit(X_train)# fit方法用于找到方差为零的特征
VarianceThreshold(threshold=0)
# get_support是一个布尔向量,指示哪些特征被保留
# 如果我们对get_support求和,我们可以得到不是常数的特征数量
sum(sel.get_support())
319
# 获取X_train数据集的列名,并通过sel.get_support()方法找到非常数特征的索引
# sel.get_support()方法返回一个布尔数组,其中True表示对应的特征是非常数特征,False表示对应的特征是常数特征
# X_train.columns[sel.get_support()]将返回非常数特征的列名
# len(X_train.columns[sel.get_support()])返回非常数特征的数量
319
# 打印常量特征的数量
print(len([x for x in X_train.columnsif x not in X_train.columns[sel.get_support()]]))# 打印不在支持特征集合中的特征列表
[x for x in X_train.columns if x not in X_train.columns[sel.get_support()]]
51['ind_var2_0','ind_var2','ind_var18_0','ind_var18','ind_var27_0','ind_var28_0','ind_var28','ind_var27','ind_var34_0','ind_var34','ind_var41','ind_var46_0','ind_var46','num_var18_0','num_var18','num_var27_0','num_var28_0','num_var28','num_var27','num_var34_0','num_var34','num_var41','num_var46_0','num_var46','saldo_var18','saldo_var28','saldo_var27','saldo_var34','saldo_var41','saldo_var46','delta_imp_amort_var18_1y3','delta_imp_amort_var34_1y3','imp_amort_var18_hace3','imp_amort_var18_ult1','imp_amort_var34_hace3','imp_amort_var34_ult1','imp_reemb_var13_hace3','imp_reemb_var17_hace3','imp_reemb_var33_hace3','imp_trasp_var17_out_hace3','imp_trasp_var33_out_hace3','num_var2_0_ult1','num_var2_ult1','num_reemb_var13_hace3','num_reemb_var17_hace3','num_reemb_var33_hace3','num_trasp_var17_out_hace3','num_trasp_var33_out_hace3','saldo_var2_ult1','saldo_medio_var13_medio_hace3','saldo_medio_var29_hace3']
-
我们可以看到,有51列/变量是常数。这意味着51个变量在训练集的所有观察中都显示相同的值,只有一个值。
-
然后我们使用transform函数来减少训练和测试集。
# 将sel对象应用于X_train数据集,以选择指定的特征列
X_train = sel.transform(X_train)# 将sel对象应用于X_test数据集,以选择指定的特征列
X_test = sel.transform(X_test)
# 检查训练集和测试集的形状# X_train是训练集的特征矩阵,X_test是测试集的特征矩阵
# shape属性用于获取矩阵的形状,返回一个元组,元组中的第一个元素表示矩阵的行数,第二个元素表示矩阵的列数
# X_train.shape返回训练集特征矩阵的形状,X_test.shape返回测试集特征矩阵的形状
# 通过查看形状可以了解训练集和测试集的样本数量和特征数量X_train.shape, X_test.shape
((35000, 319), (15000, 319))
- 我们可以看到,通过删除常量特征,我们成功地大大减少了特征空间。
2.1.2 移除准常量特征
目录
-
准常量特征是指在数据集的大多数观测中显示相同值的特征。一般来说,这些特征提供的信息很少,甚至没有任何信息可以让机器学习模型进行区分或预测目标。但也有例外情况。因此,在移除这类特征时,我们应该小心。识别和移除准常量特征是进行特征选择和更易解释的机器学习模型的简单第一步。
-
要识别准常量特征,我们可以再次使用sklearn中的VarianceThreshold函数。
-
在这里,使用Santander客户满意度数据集来识别准常量特征。
# 导入Kaggle上的Santander客户满意度数据集# 从指定路径读取训练数据集,读取前35000行
X_train = pd.read_csv('/kaggle/input/santander-customer-satisfaction/train.csv', nrows=35000)# 从指定路径读取测试数据集,读取前15000行
X_test = pd.read_csv('/kaggle/input/santander-customer-satisfaction/test.csv', nrows=15000)
# 从X_train中删除目标标签# 使用drop函数删除指定的标签列,labels参数指定要删除的列名为'TARGET'
# axis参数指定删除的方向,这里为1表示按列删除
# inplace参数指定是否在原数据上进行修改,这里为True表示在原数据上进行修改
X_train.drop(labels=['TARGET'], axis=1, inplace=True)
# 检查训练集和测试集的形状# 输出训练集的形状
X_train.shape# 输出测试集的形状
X_test.shape
((35000, 370), (15000, 370))
移除准常量特征
使用sklearn中的方差阈值
-
sklearn中的方差阈值是一种简单的特征选择基准方法。它会移除所有方差不满足某个阈值的特征。默认情况下,它会移除所有零方差特征,即在所有样本中具有相同值的特征。
-
在这里,将更改默认阈值以移除几乎/准常量特征。
# 导入VarianceThreshold类# 创建一个VarianceThreshold对象,设置阈值为0.01,表示保留方差大于0.01的特征
sel = VarianceThreshold(threshold=0.01)# 使用训练集数据拟合VarianceThreshold模型,找出方差较低的特征
sel.fit(X_train)
VarianceThreshold(threshold=0.01)
# sel.get_support()是一个布尔向量,用于指示哪些特征被保留。
# 如果我们对get_support进行求和,我们可以得到非准常量特征的数量。
sum(sel.get_support())
263
# 以上方法的替代方法
len(X_train.columns[sel.get_support()])
263
# 打印准常量特征的数量
print(len([x for x in X_train.columnsif x not in X_train.columns[sel.get_support()]]))# 打印不在sel.get_support()返回的特征列表中的特征
[x for x in X_train.columns if x not in X_train.columns[sel.get_support()]]
107['ind_var1','ind_var2_0','ind_var2','ind_var6_0','ind_var6','ind_var13_largo','ind_var13_medio_0','ind_var13_medio','ind_var14','ind_var17_0','ind_var17','ind_var18_0','ind_var18','ind_var19','ind_var20_0','ind_var20','ind_var27_0','ind_var28_0','ind_var28','ind_var27','ind_var29_0','ind_var29','ind_var30_0','ind_var31_0','ind_var31','ind_var32_cte','ind_var32_0','ind_var32','ind_var33_0','ind_var33','ind_var34_0','ind_var34','ind_var40','ind_var41','ind_var39','ind_var44_0','ind_var44','ind_var46_0','ind_var46','num_var6_0','num_var6','num_var13_medio_0','num_var13_medio','num_var18_0','num_var18','num_op_var40_hace3','num_var27_0','num_var28_0','num_var28','num_var27','num_var29_0','num_var29','num_var33','num_var34_0','num_var34','num_var41','num_var46_0','num_var46','saldo_var18','saldo_var28','saldo_var27','saldo_var34','saldo_var41','saldo_var46','delta_imp_amort_var18_1y3','delta_imp_amort_var34_1y3','delta_imp_aport_var33_1y3','delta_num_aport_var33_1y3','imp_amort_var18_hace3','imp_amort_var18_ult1','imp_amort_var34_hace3','imp_amort_var34_ult1','imp_reemb_var13_hace3','imp_reemb_var17_hace3','imp_reemb_var33_hace3','imp_trasp_var17_out_hace3','imp_trasp_var33_out_hace3','ind_var7_emit_ult1','ind_var7_recib_ult1','num_var2_0_ult1','num_var2_ult1','num_aport_var33_hace3','num_aport_var33_ult1','num_var7_emit_ult1','num_meses_var13_medio_ult3','num_meses_var17_ult3','num_meses_var29_ult3','num_meses_var33_ult3','num_meses_var44_ult3','num_reemb_var13_hace3','num_reemb_var13_ult1','num_reemb_var17_hace3','num_reemb_var17_ult1','num_reemb_var33_hace3','num_reemb_var33_ult1','num_trasp_var17_in_hace3','num_trasp_var17_in_ult1','num_trasp_var17_out_hace3','num_trasp_var17_out_ult1','num_trasp_var33_in_hace3','num_trasp_var33_in_ult1','num_trasp_var33_out_hace3','num_trasp_var33_out_ult1','num_venta_var44_hace3','saldo_var2_ult1','saldo_medio_var13_medio_hace3','saldo_medio_var29_hace3']
- 我们可以看到,107个列/变量几乎是恒定的。这意味着在训练集的观察中,107个变量中有大约99%的变量主要显示一个值。
# 统计X_train中'ind_var31'列的不同取值的观察次数的百分比# 使用value_counts()函数统计'ind_var31'列中每个不同取值的观察次数,并返回一个Series对象
# Series对象的索引是'ind_var31'列的不同取值,值是对应取值的观察次数
# value_counts()函数默认按照观察次数从大到小进行排序
value_counts = X_train['ind_var31'].value_counts()# 使用len()函数获取X_train的长度,即X_train中的观察次数
# 使用np.float()函数将长度转换为浮点数,以便进行除法运算
total_count = np.float(len(X_train))# 将每个不同取值的观察次数除以总观察次数,得到每个取值的观察次数的百分比
# 通过除法运算,得到的结果是一个Series对象,索引是'ind_var31'列的不同取值,值是对应取值的观察次数的百分比
percentage = value_counts / total_count# 返回结果,即每个不同取值的观察次数的百分比
percentage
0 0.996286
1 0.003714
Name: ind_var31, dtype: float64
- 我们可以看到,超过99%的观测值显示一个值,即0。因此,这个特征几乎是恒定的。
# 首先,我们可以使用sel.transform()方法从训练集和测试集中移除特征
X_train = sel.transform(X_train) # 从训练集中移除特征
X_test = sel.transform(X_test) # 从测试集中移除特征
# 检查训练集和测试集的形状# X_train.shape 返回训练集X_train的形状,即训练集的行数和列数
# X_test.shape 返回测试集X_test的形状,即测试集的行数和列数X_train.shape, X_test.shape
((35000, 263), (15000, 263))
- 通过删除常数和准常数特征,我们将特征空间从370减少到263。我们可以看到,当前数据集中有100多个特征被删除。
2.2 单变量选择方法
目录
-
单变量特征选择方法通过基于单变量统计检验(如ANOVA)选择最佳特征。它可以被视为估计器的预处理步骤。Scikit-learn将特征选择例程公开为实现transform方法的对象。
-
基于F检验的方法估计两个随机变量之间的线性依赖程度。它们假设特征和目标之间存在线性关系。这些方法还假设变量遵循高斯分布。
-
在这个类别下有4种方法:
- SelectKBest
- SelectPercentile
- SelectFpr、SelectFdr或家族错误选择SelectFwe
- GenericUnivariateSelection
来源:https://scikit-learn.org/stable/modules/feature_selection.html
- 在这里,我将限制讨论在实践中最常用的SelectKBest和SelectPercentile两种方法。
2.2.1 SelectKBest
目录
-
这个方法根据最高的k个分数选择特征。
-
例如,我们可以对样本进行卡方检验,从鸢尾花数据集中仅获取两个最佳特征,如下所示:
来源:https://scikit-learn.org/stable/modules/feature_selection.html
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectKBest.html#sklearn.feature_selection.SelectKBest
# 导入所需的库
from sklearn.datasets import load_iris # 导入load_iris函数,用于加载鸢尾花数据集
from sklearn.feature_selection import SelectKBest, chi2 # 导入SelectKBest和chi2函数,用于特征选择# 加载鸢尾花数据集
X, y = load_iris(return_X_y=True) # 使用load_iris函数加载鸢尾花数据集,并将特征矩阵赋值给X,目标向量赋值给y# 输出特征矩阵的形状
X.shape # 打印特征矩阵X的形状,即样本数量和特征数量
(150, 4)
# 导入SelectKBest和chi2函数
# SelectKBest函数用于选择最好的k个特征
# chi2函数用于计算卡方统计量# 使用SelectKBest函数选择最好的两个特征
# 将X数据集中的特征经过SelectKBest函数处理后,得到新的特征集X_new
# fit_transform函数用于拟合数据并进行转换# 输出X_new的形状
# shape函数用于获取数组的形状,返回一个元组,元组的每个元素表示数组在对应维度上的大小
(150, 2)
- 因此,我们从鸢尾花数据集中选择了两个最佳特征。
2.2.2 SelectPercentile
目录
- 根据最高分数的百分位选择特征。
来源:https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.SelectPercentile.html#sklearn.feature_selection.SelectPercentile
# 导入load_digits函数,用于加载手写数字数据集
from sklearn.datasets import load_digits
# 导入SelectPercentile和chi2函数,用于特征选择
from sklearn.feature_selection import SelectPercentile, chi2# 使用load_digits函数加载手写数字数据集,并将特征矩阵和目标向量分别赋值给X和y
X, y = load_digits(return_X_y=True)# 输出特征矩阵X的形状
print(X.shape)
(1797, 64)
# 导入所需的库和模块
# 不需要增加import语句# 选择特征的百分位数
# 使用卡方检验(chi2)方法,选择前10%的特征
# 将选择的特征应用于数据集X和目标变量y,并返回新的数据集X_new
X_new = SelectPercentile(chi2, percentile=10).fit_transform(X, y)# 打印新的数据集X_new的形状
# X_new.shape返回一个元组,包含新数据集的行数和列数
print(X_new.shape)
(1797, 7)
- 我们可以看到只有7个特征位于前10百分位数,因此我们相应地选择它们。
重要信息
-
这些对象接受一个返回单变量得分和p值(或仅对于SelectKBest和SelectPercentile仅返回得分)的评分函数作为输入:
-
对于回归任务:f_regression,mutual_info_regression
-
对于分类任务:chi2,f_classif,mutual_info_classif
基于F检验的方法估计了两个随机变量之间的线性依赖程度。另一方面,互信息方法可以捕捉任何类型的统计依赖关系,但由于是非参数方法,它们需要更多的样本来进行准确估计。
稀疏数据的特征选择
- 如果您使用稀疏数据(即表示为稀疏矩阵的数据),chi2、mutual_info_regression、mutual_info_classif 将在不使数据变得密集的情况下处理数据。
来源:https://scikit-learn.org/stable/modules/feature_selection.html
警告
- 注意不要在分类问题中使用回归评分函数,你将得到无用的结果。
2.3 信息增益
目录
-
信息增益或互信息衡量了特征的存在/缺失对于正确预测目标的贡献有多大。
-
根据wikipedia的解释:
- 互信息衡量了X和Y之间共享的信息:它衡量了知道其中一个变量如何减少对另一个变量的不确定性。例如,如果X和Y是独立的,那么知道X不会提供任何关于Y的信息,反之亦然,所以它们的互信息为零。另一方面,如果X是Y的确定性函数,Y是X的确定性函数,那么X传递的所有信息都与Y共享:知道X确定了Y的值,反之亦然。因此,在这种情况下,互信息与Y(或X)单独包含的不确定性相同,即Y(或X)的熵。此外,这个互信息与X的熵和Y的熵相同。(这是X和Y是相同随机变量的一个非常特殊的情况。)
mutual_info_classif
-
它用于估计离散目标变量的互信息。
-
两个随机变量之间的互信息(MI)是一个非负值,它衡量变量之间的依赖关系。当且仅当两个随机变量独立时,它等于零,而较高的值意味着更高的依赖性。
-
此函数依赖于基于k最近邻距离的熵估计的非参数方法。
-
它可用于单变量特征选择。
-
来源:
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.mutual_info_classif.html#sklearn.feature_selection.mutual_info_classif
mutual_info_regression
-
估计连续目标变量的互信息。
-
两个随机变量之间的互信息(MI)是一个非负值,它衡量变量之间的依赖关系。当且仅当两个随机变量独立时,它等于零,而较高的值意味着更高的依赖性。
-
该函数依赖于基于k最近邻距离的熵估计的非参数方法。
-
它可用于单变量特征选择
-
来源:
https://scikit-learn.org/stable/modules/generated/sklearn.feature_selection.mutual_info_regression.html#sklearn.feature_selection.mutual_info_regression
2.4 Fisher Score (卡方实现)
目录
-
这是scikit-learn中的卡方实现。它计算每个非负特征与类之间的卡方统计量。
-
这个分数应该用于评估分类任务中的分类变量。它将目标Y的不同类别的观察分布与特征的不同类别的预期分布进行比较,而不考虑特征的类别。
# 导入所需的库
from sklearn.datasets import load_iris # 导入load_iris函数,用于加载鸢尾花数据集
from sklearn.feature_selection import SelectKBest, chi2 # 导入SelectKBest和chi2函数,用于特征选择# 加载鸢尾花数据集
iris = load_iris()# 提取特征和目标变量
X = iris.data # 特征变量
y = iris.target # 目标变量# 使用卡方检验选择K个最佳特征
selector = SelectKBest(chi2, k=2) # 创建SelectKBest对象,使用卡方检验作为评估指标,选择2个最佳特征
X_new = selector.fit_transform(X, y) # 使用fit_transform方法对特征进行选择,返回选择后的特征矩阵# 打印选择后的特征矩阵
print(X_new)
# 加载数据
# 加载鸢尾花数据集
iris = load_iris()# 创建特征和目标
X = iris.data # 特征数据
y = iris.target # 目标数据# 将数据转换为分类数据,将数据转换为整数类型
X = X.astype(int) # 将特征数据转换为整数类型
# 导入所需的库
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2# 创建一个SelectKBest对象,使用chi2作为评估指标,选择k=2个特征
chi2_selector = SelectKBest(chi2, k=2)# 使用SelectKBest对象对特征矩阵X和目标变量y进行拟合和转换
X_kbest = chi2_selector.fit_transform(X, y)# 返回经过特征选择后的特征矩阵X_kbest,其中只包含k=2个最佳特征
# 打印原始特征数量
print('原始特征数量:', X.shape[1])
# 打印降维后的特征数量
print('降维后的特征数量:', X_kbest.shape[1])
Original number of features: 4
Reduced number of features: 2
- 我们可以看到上述代码帮助我们基于Fisher得分选择了2个最佳特征。
2.5 特征选择的ANOVA F值
目录
-
计算给定样本的ANOVA F值。
-
如果特征是分类的,我们将计算每个特征与目标向量之间的卡方统计量。然而,如果特征是定量的,我们将计算每个特征与目标向量之间的ANOVA F值。
-
F值分数检查了当我们将数值特征按目标向量分组时,每个组的均值是否显著不同。
# 导入所需的库
from sklearn.datasets import load_iris # 导入load_iris函数,用于加载鸢尾花数据集
from sklearn.feature_selection import SelectKBest # 导入SelectKBest类,用于特征选择
from sklearn.feature_selection import f_classif # 导入f_classif函数,用于计算特征的F值和p值# 加载鸢尾花数据集
iris = load_iris()# 创建特征选择器对象,设置要选择的特征数量为2
selector = SelectKBest(score_func=f_classif, k=2)# 使用特征选择器对数据集进行特征选择
X_new = selector.fit_transform(iris.data, iris.target)# 打印选择的特征
print(X_new)
# 加载鸢尾花数据集
iris = load_iris()# 创建特征和目标变量
X = iris.data # 特征变量,包含了鸢尾花的四个特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度
y = iris.target # 目标变量,包含了鸢尾花的类别:0代表山鸢尾、1代表变色鸢尾、2代表维吉尼亚鸢尾
# 选择具有最佳ANOVA F-值的特征# 创建一个SelectKBest对象,用于选择具有两个最佳ANOVA F-值的特征
fvalue_selector = SelectKBest(f_classif, k=2)# 将SelectKBest对象应用于特征和目标变量
X_kbest = fvalue_selector.fit_transform(X, y)
# 打印原始特征数量
print('原始特征数量:', X.shape[1])
# 打印降维后的特征数量
print('降维后的特征数量:', X_kbest.shape[1])
Original number of features: 4
Reduced number of features: 2
- 我们可以看到上述代码帮助我们基于ANOVA F-Value选择了2个最佳特征。
2.6 相关矩阵与热力图
目录
-
相关性是衡量2个或多个变量之间线性关系的指标。通过相关性,我们可以从一个变量预测另一个变量。
-
好的变量与目标变量高度相关。
-
相关的预测变量提供了冗余信息。
-
变量应与目标变量相关,但彼此之间不相关。
-
相关特征选择根据以下假设评估特征子集:
- “好的特征子集包含与目标变量高度相关但彼此之间不相关的特征”。
-
在本节中,我将演示如何基于两个特征之间的相关性选择特征。我们可以找到彼此相关的特征。通过识别这些特征,我们可以决定哪些特征要保留,哪些要删除。
-
使用皮尔逊相关系数,我们得到的系数值将在-1和1之间变化。
-
如果两个特征之间的相关性为0,这意味着改变这两个特征中的任何一个都不会影响另一个特征。
-
如果两个特征之间的相关性大于0,这意味着增加一个特征中的值也会增加另一个特征中的值(相关系数越接近1,这两个不同特征之间的关联就越强)。
-
如果两个特征之间的相关性小于0,这意味着增加一个特征中的值会减少另一个特征中的值(相关系数越接近-1,这两个不同特征之间的关系就越强)。
-
在这个分析中,我们将检查所选变量是否与彼此高度相关。如果是这样,我们将只保留其中一个相关的变量并丢弃其他变量。
# 导入sklearn中的load_iris模块,用于加载鸢尾花数据集
from sklearn.datasets import load_iris
# 使用load_iris()函数加载鸢尾花数据集,并将其赋值给变量iris
iris = load_iris()# 创建特征和目标变量
# 将鸢尾花数据集中的特征数据赋值给变量X
X = iris.data
# 将鸢尾花数据集中的目标变量赋值给变量y
y = iris.target
# 将特征矩阵转换为DataFrame
df = pd.DataFrame(X)# 查看数据框
print(df)
0 1 2 3
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
.. ... ... ... ...
145 6.7 3.0 5.2 2.3
146 6.3 2.5 5.0 1.9
147 6.5 3.0 5.2 2.0
148 6.2 3.4 5.4 2.3
149 5.9 3.0 5.1 1.8[150 rows x 4 columns]
# 创建相关系数矩阵
corr_matrix = df.corr()# 打印相关系数矩阵
print(corr_matrix)
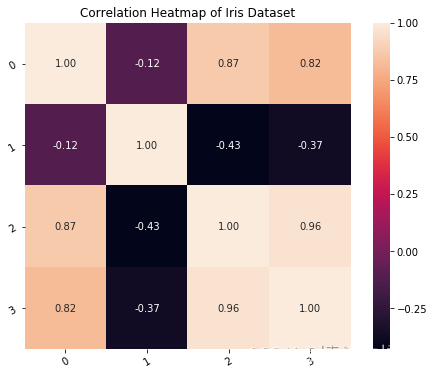
0 1 2 3
0 1.000000 -0.117570 0.871754 0.817941
1 -0.117570 1.000000 -0.428440 -0.366126
2 0.871754 -0.428440 1.000000 0.962865
3 0.817941 -0.366126 0.962865 1.000000
# 创建一个图形窗口
plt.figure(figsize=(8,6))# 设置图形标题
plt.title('Iris数据集的相关性热力图')# 使用seaborn库中的heatmap函数创建相关性热力图
# corr_matrix是一个包含相关系数的矩阵
# square=True表示将热力图的方格设置为正方形
# annot=True表示在热力图中显示相关系数的值
# fmt='.2f'表示将相关系数的值保留两位小数
# linecolor='black'表示热力图中方格之间的分割线颜色为黑色
a = sns.heatmap(corr_matrix, square=True, annot=True, fmt='.2f', linecolor='black')# 设置x轴标签的旋转角度为30度
a.set_xticklabels(a.get_xticklabels(), rotation=30)# 设置y轴标签的旋转角度为30度
a.set_yticklabels(a.get_yticklabels(), rotation=30)# 显示图形
plt.show()
# 选择相关系数矩阵的上三角部分
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
upper
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | NaN | -0.11757 | 0.871754 | 0.817941 |
| 1 | NaN | NaN | -0.428440 | -0.366126 |
| 2 | NaN | NaN | NaN | 0.962865 |
| 3 | NaN | NaN | NaN | NaN |
# 遍历upper的每一列,使用列表推导式将相关性大于0.9的特征列的索引添加到to_drop列表中
to_drop = [column for column in upper.columns if any(upper[column] > 0.9)]
print(to_drop)
[3]
# Drop Marked Features
# 删除标记的特征列
# df.drop()函数用于删除指定的列
# df.columns[to_drop]表示要删除的列的索引
# axis=1表示按列删除
df1 = df.drop(df.columns[to_drop], axis=1)
# 打印删除后的DataFrame
print(df1)
0 1 2
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
.. ... ... ...
145 6.7 3.0 5.2
146 6.3 2.5 5.0
147 6.5 3.0 5.2
148 6.2 3.4 5.4
149 5.9 3.0 5.1[150 rows x 3 columns]
任务:请翻译以下markdown为中文,请保留markdown的格式,并输出翻译结果。
语料:
- We can see that we have dropped the third column from the original dataset.
翻译结果:
- 我们可以看到我们已经从原始数据集中删除了第三列。
3. 包装方法
目录
-
在包装方法中,我们尝试使用一部分特征来训练模型。根据我们从先前模型中得出的推论,我们决定向子集中添加或删除特征。这个问题本质上被简化为一个搜索问题。这些方法通常计算成本很高。
-
一些常见的包装方法示例包括:
-
- 正向选择(Forward selection)
-
- 逆向消除(Backward elimination)
-
- 全特征选择(Exhaustive feature selection)
-
- 递归特征消除(Recursive feature elimination)
-
- 带交叉验证的递归特征消除(Recursive feature elimination with cross-validation)
-
-
可以通过以下图形来解释包装方法:
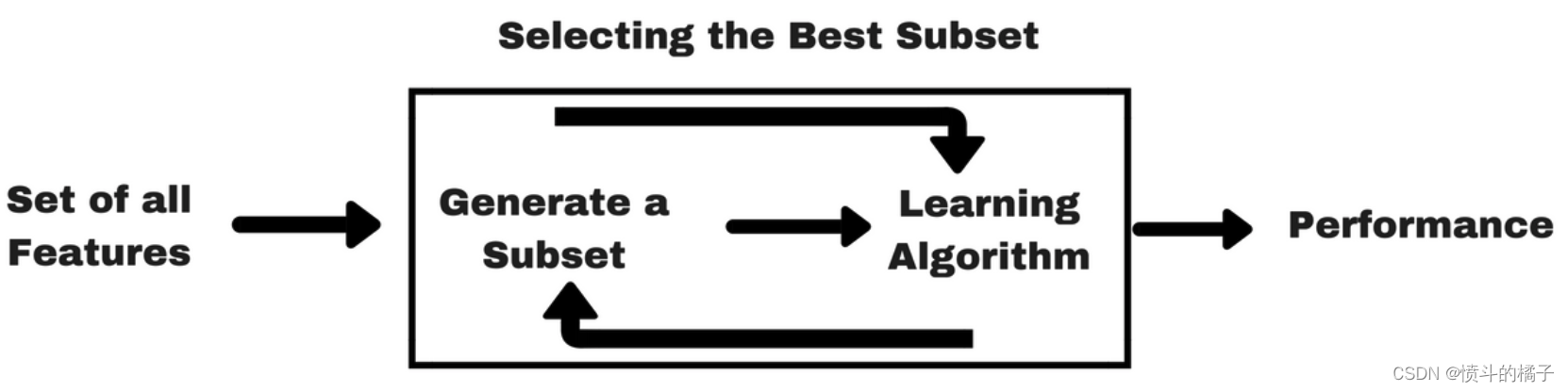
3.1 前向选择
目录
-
前向选择是一种迭代方法,我们从模型中没有任何特征开始。在每次迭代中,我们都会添加最能改善模型的特征,直到添加新变量不再改善模型的性能。
-
该过程从一个空特征集[缩减集]开始。确定最佳的原始特征,并将其添加到缩减集中。在每个后续迭代中,将剩余原始属性中最佳的特征添加到集合中。
-
步进特征选择从单独评估所有特征开始,并选择根据预设的评估标准生成最佳性能算法的特征。在第二步中,它评估所选特征和第二个特征的所有可能组合,并根据相同的预设标准选择产生最佳性能算法的一对特征。
-
预设标准可以是分类的roc_auc,回归的r squared等。
-
这种选择过程被称为贪婪,因为它评估所有可能的单个、双重、三重等特征组合。因此,它在计算上非常昂贵,有时,如果特征空间很大,甚至是不可行的。
-
有一个专门的Python包实现了这种类型的特征选择:mlxtend。
-
在mlxtend实现的步进特征选择中,停止标准是一个任意设置的特征数量。因此,当达到所选特征的期望数量时,搜索将结束。
-
我将使用House Price数据集演示mlxtend中的步进特征选择算法。
# 导入所需的库和模块# 从sklearn库中导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split# 从sklearn库中导入RandomForestRegressor类,用于构建随机森林回归模型
from sklearn.ensemble import RandomForestRegressor# 从sklearn库中导入r2_score函数,用于评估回归模型的性能
from sklearn.metrics import r2_score# 从mlxtend库中导入SequentialFeatureSelector类,用于进行逐步前向特征选择
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 加载数据集
data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')# 输出数据集的形状(行数和列数)
data.shape
(1460, 81)
# 代码目的:选择数据集中的数值型变量,并将数据集中的其他变量删除。# 通常情况下,在数据预处理之后应该进行特征选择,这样所有的分类变量都会被编码为数字,
# 然后可以评估它们对目标变量的确定性程度。# 这里为了简单起见,只使用数值型变量。
# 选择数值型列:# 定义数值型数据类型列表
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
# 选择数据集中的数值型变量列
numerical_vars = list(data.select_dtypes(include=numerics).columns)
# 保留数据集中的数值型变量列,删除其他变量列
data = data[numerical_vars]
# 输出数据集的形状
data.shape
(1460, 38)
# 导入train_test_split函数用于将数据集分为训练集和测试集# 使用train_test_split函数将数据集分为训练集和测试集,并将分割后的数据分别赋值给X_train, X_test, y_train, y_test
# 参数data.drop(labels=['SalePrice'], axis=1)表示将data中的'SalePrice'列删除后作为特征数据
# 参数data['SalePrice']表示将data中的'SalePrice'列作为目标数据
# 参数test_size=0.3表示将数据集中的30%作为测试集,70%作为训练集
# 参数random_state=0表示设置随机种子,保证每次运行代码时得到的分割结果一致# 打印训练集的形状和测试集的形状,即打印X_train的形状和X_test的形状
X_train, X_test, y_train, y_test = train_test_split(data.drop(labels=['SalePrice'], axis=1),data['SalePrice'],test_size=0.3,random_state=0)X_train.shape, X_test.shape
((1022, 37), (438, 37))
# 导入所需的库# 定义一个函数,用于找到并移除相关特征
def correlation(dataset, threshold):col_corr = set() # 存储相关列的名称的集合corr_matrix = dataset.corr() # 计算特征之间的相关系数矩阵for i in range(len(corr_matrix.columns)):for j in range(i):if abs(corr_matrix.iloc[i, j]) > threshold: # 判断绝对值大于阈值的相关系数colname = corr_matrix.columns[i] # 获取相关列的名称col_corr.add(colname) # 将相关列的名称添加到集合中return col_corr# 调用correlation函数,找到相关特征
corr_features = correlation(X_train, 0.8)# 打印相关特征的数量
print('correlated features: ', len(set(corr_features)))
correlated features: 3
# 删除相关特征
# 在训练集中删除相关特征
X_train.drop(labels=corr_features, axis=1, inplace=True)
# 在测试集中删除相关特征
X_test.drop(labels=corr_features, axis=1, inplace=True)# 打印训练集和测试集的形状
print(X_train.shape, X_test.shape)
((1022, 34), (438, 34))
# 使用fillna方法对X_train进行缺失值填充
# 参数0表示将缺失值填充为0
# inplace=True表示在原数据上进行修改,而不是返回一个新的数据副本
X_train.fillna(0, inplace=True)
# 导入所需的库
from mlxtend.feature_selection import SequentialFeatureSelector as SFS# 创建一个SequentialFeatureSelector对象
# 参数说明:
# RandomForestRegressor():使用的模型为随机森林回归模型
# k_features=10:选择的特征数量为10个
# forward=True:使用前向选择的方式
# floating=False:不使用浮动的方式
# verbose=2:输出详细的信息
# scoring='r2':评估指标为R2分数
# cv=3:交叉验证的折数为3
sfs1 = SFS(RandomForestRegressor(), k_features=10, forward=True, floating=False, verbose=2,scoring='r2',cv=3)# 使用训练集的特征和标签进行特征选择
sfs1 = sfs1.fit(np.array(X_train), y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 34 out of 34 | elapsed: 2.5s finished[2020-11-18 15:27:17] Features: 1/10 -- score: 0.6660625424149279[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 33 out of 33 | elapsed: 2.5s finished[2020-11-18 15:27:19] Features: 2/10 -- score: 0.7226746946693089[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 32 out of 32 | elapsed: 2.6s finished[2020-11-18 15:27:22] Features: 3/10 -- score: 0.7372751573305495[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 31 out of 31 | elapsed: 2.7s finished[2020-11-18 15:27:25] Features: 4/10 -- score: 0.7546369061839346[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 30 out of 30 | elapsed: 2.6s finished[2020-11-18 15:27:27] Features: 5/10 -- score: 0.7704192647844806[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 29 out of 29 | elapsed: 3.0s finished[2020-11-18 15:27:30] Features: 6/10 -- score: 0.8033042335146621[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 28 out of 28 | elapsed: 3.2s finished[2020-11-18 15:27:33] Features: 7/10 -- score: 0.8128199669893345[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 27 out of 27 | elapsed: 3.3s finished[2020-11-18 15:27:37] Features: 8/10 -- score: 0.8228549634821061[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 26 out of 26 | elapsed: 3.2s finished[2020-11-18 15:27:40] Features: 9/10 -- score: 0.8302142712276996[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 25 out of 25 | elapsed: 3.4s finished[2020-11-18 15:27:43] Features: 10/10 -- score: 0.8426238460482622
# 定义一个变量sfs1,表示一个对象
# 这个对象有一个属性k_feature_idx_,表示特征的索引值
(4, 7, 12, 14, 16, 17, 18, 23, 24, 27)
# 获取特征选择后的训练数据的列名
X_train.columns[list(sfs1.k_feature_idx_)]
Index(['OverallQual', 'YearRemodAdd', 'TotalBsmtSF', '2ndFlrSF', 'GrLivArea','BsmtFullBath', 'BsmtHalfBath', 'Fireplaces', 'GarageCars','EnclosedPorch'],dtype='object')
任务:请翻译以下markdown为中文,请保留markdown的格式,并输出翻译结果。
语料:
- We can see that forward feature selection results in the above columns being selected from all the given columns.
翻译结果:
- 我们可以看到,前向特征选择导致上述列从所有给定的列中被选择出来。
3.2 后向消除
目录
-
在后向消除中,我们从所有特征开始,并在每次迭代中删除最不显著的特征,以提高模型的性能。我们重复这个过程,直到删除特征后没有观察到改进。
-
该过程从完整的属性集开始。在每个步骤中,它删除剩余集合中最差的属性。
# 导入所需的库
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.ensemble import RandomForestRegressor
import numpy as np# 创建一个SFS对象,使用随机森林回归器作为评估器
# 设置要选择的特征数量为10
# 设置为向后选择特征
# 设置不使用浮动特征选择
# 设置显示详细信息
# 设置评分指标为r2
# 设置交叉验证折数为3
sfs1 = SFS(RandomForestRegressor(), k_features=10, forward=False, floating=False, verbose=2,scoring='r2',cv=3)# 使用训练集的特征和标签进行特征选择
sfs1 = sfs1.fit(np.array(X_train), y_train)
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 34 out of 34 | elapsed: 8.6s finished[2020-11-18 15:27:52] Features: 33/10 -- score: 0.8440655710190595[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 33 out of 33 | elapsed: 8.2s finished[2020-11-18 15:28:00] Features: 32/10 -- score: 0.8501137164652176[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.3s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 32 out of 32 | elapsed: 7.8s finished[2020-11-18 15:28:08] Features: 31/10 -- score: 0.8487485330398848[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 31 out of 31 | elapsed: 7.4s finished[2020-11-18 15:28:16] Features: 30/10 -- score: 0.8475315934104577[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 30 out of 30 | elapsed: 7.1s finished[2020-11-18 15:28:23] Features: 29/10 -- score: 0.8478491109825423[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 29 out of 29 | elapsed: 6.6s finished[2020-11-18 15:28:29] Features: 28/10 -- score: 0.8485940187665665[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 28 out of 28 | elapsed: 6.2s finished[2020-11-18 15:28:36] Features: 27/10 -- score: 0.8496186537697984[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 27 out of 27 | elapsed: 5.8s finished[2020-11-18 15:28:41] Features: 26/10 -- score: 0.848796221384783[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 26 out of 26 | elapsed: 5.4s finished[2020-11-18 15:28:47] Features: 25/10 -- score: 0.850171275327683[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 25 out of 25 | elapsed: 5.1s finished[2020-11-18 15:28:52] Features: 24/10 -- score: 0.8449011689872418[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 24 out of 24 | elapsed: 4.8s finished[2020-11-18 15:28:57] Features: 23/10 -- score: 0.8465281618965282[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 23 out of 23 | elapsed: 4.5s finished[2020-11-18 15:29:01] Features: 22/10 -- score: 0.8501821835072528[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 22 out of 22 | elapsed: 4.3s finished[2020-11-18 15:29:05] Features: 21/10 -- score: 0.8566365529117371[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 21 out of 21 | elapsed: 3.8s finished[2020-11-18 15:29:09] Features: 20/10 -- score: 0.8499549410021953[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 20 out of 20 | elapsed: 3.7s finished[2020-11-18 15:29:13] Features: 19/10 -- score: 0.8466996086440761[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 19 out of 19 | elapsed: 3.4s finished[2020-11-18 15:29:16] Features: 18/10 -- score: 0.852507884934626[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 18 out of 18 | elapsed: 3.2s finished[2020-11-18 15:29:19] Features: 17/10 -- score: 0.852772483493152[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 17 out of 17 | elapsed: 3.0s finished[2020-11-18 15:29:22] Features: 16/10 -- score: 0.8522002965350178[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 16 out of 16 | elapsed: 2.7s finished[2020-11-18 15:29:25] Features: 15/10 -- score: 0.8504359639328686[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 15 out of 15 | elapsed: 2.3s finished[2020-11-18 15:29:27] Features: 14/10 -- score: 0.8529543833671349[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 14 out of 14 | elapsed: 2.0s finished[2020-11-18 15:29:29] Features: 13/10 -- score: 0.8467727793555498[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 13 out of 13 | elapsed: 1.8s finished[2020-11-18 15:29:31] Features: 12/10 -- score: 0.8388217986847307[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 12 out of 12 | elapsed: 1.6s finished[2020-11-18 15:29:33] Features: 11/10 -- score: 0.8406774604150073[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.1s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 11 out of 11 | elapsed: 1.4s finished[2020-11-18 15:29:34] Features: 10/10 -- score: 0.8229574357298898
# 定义一个变量sfs1.k_feature_idx_,用来存储特征的索引值列表sfs1.k_feature_idx_
(1, 4, 5, 8, 9, 12, 16, 17, 24, 30)
# 获取特征选择后的训练数据的列名
X_train.columns[list(sfs1.k_feature_idx_)]
Index(['MSSubClass', 'OverallQual', 'OverallCond', 'MasVnrArea', 'BsmtFinSF1','TotalBsmtSF', 'GrLivArea', 'BsmtFullBath', 'GarageCars', 'PoolArea'],dtype='object')
- 因此,向后特征消除的结果是选择了以下列。
3.3 全面特征选择
目录
-
在全面特征选择中,通过优化指定的性能度量来选择最佳的特征子集,该度量是针对某个机器学习算法的。例如,如果分类器是逻辑回归,数据集包含4个特征,算法将评估以下所有15种特征组合:
- 所有可能的1个特征的组合
- 所有可能的2个特征的组合
- 所有可能的3个特征的组合
- 所有4个特征
并选择导致逻辑回归分类器性能最佳(例如分类准确度)的特征组合。
-
这是另一种贪婪算法,因为它评估所有可能的特征组合。它计算成本较高,有时,如果特征空间很大,甚至是不可行的。
-
有一个专门用于Python的包实现了这种类型的特征选择:mlxtend。
-
在mlxtend实现的全面特征选择中,停止条件是任意设置的特征数量。因此,当达到所需的选定特征数量时,搜索将结束。
-
这在某种程度上是任意的,因为我们可能选择了一个次优的特征数量,或者同样地,选择了一个较高的特征数量。
3.4 递归特征消除
目录
-
递归特征消除是一种贪婪优化算法,旨在找到性能最佳的特征子集。它重复创建模型,并在每次迭代中保留最佳或最差的特征。它使用剩余的特征构建下一个模型,直到所有特征都用完。然后,它根据消除的顺序对特征进行排名。
-
递归特征消除通过贪婪搜索来找到性能最佳的特征子集。它迭代地创建模型,并确定每次迭代中的最佳或最差的特征。它使用剩余的特征构建后续模型,直到所有特征都被探索。然后,它根据消除的顺序对特征进行排名。在最坏的情况下,如果数据集包含N个特征,RFE将对2N个特征组合进行贪婪搜索。
-
来源:https://scikit-learn.org/stable/auto_examples/feature_selection/plot_rfe_digits.html#sphx-glr-auto-examples-feature-selection-plot-rfe-digits-py
3.5 交叉验证的递归特征消除
目录
-
交叉验证的递归特征消除(RFECV) 特征选择技术通过迭代地使用递归特征消除方法,从0到N个特征中选择最佳的特征子集用于估计器。
-
然后根据模型的准确性、交叉验证分数或roc-auc选择最佳的特征子集。递归特征消除技术通过多次拟合模型并在每一步中去除最弱的特征来消除n个特征。
-
来源:https://scikit-learn.org/stable/auto_examples/feature_selection/plot_rfe_with_cross_validation.html#sphx-glr-auto-examples-feature-selection-plot-rfe-with-cross-validation-py
4. 嵌入方法
目录
-
嵌入方法是迭代的,它关注模型训练过程的每一次迭代,并仔细提取那些对特定迭代的训练最有贡献的特征。正则化方法是最常用的嵌入方法,它们根据系数阈值对特征进行惩罚。
-
这就是为什么正则化方法也被称为惩罚方法,它们在预测算法(如回归算法)的优化中引入额外的约束,使模型偏向于较低的复杂性(较少的系数)。
-
这些方法中最受欢迎的例子是LASSO和RIDGE回归,它们具有内置的惩罚函数来减少过拟合。
-
嵌入方法可以通过以下图形来解释:
4.1 LASSO回归
目录
-
Lasso回归执行L1正则化,其添加的惩罚项等于系数的绝对值的大小。
-
正则化是向机器学习模型的不同参数添加惩罚,以减少模型的自由度,换句话说,避免过拟合。在线性模型正则化中,惩罚应用于乘以每个预测变量的系数。在不同类型的正则化中,Lasso或l1具有将某些系数收缩为零的特性。因此,该特征可以从模型中删除。
-
我将演示如何使用Lasso正则化在Kaggle的房价数据集上选择特征。
# 导入所需的库
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.linear_model import Lasso # 使用Lasso回归模型
from sklearn.feature_selection import SelectFromModel # 用于特征选择
from sklearn.preprocessing import StandardScaler # 用于特征缩放
# 加载数据集
data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')# 打印数据集的形状
print(data.shape)(1460, 81)
"""
1. 首先,我们需要进行数据预处理,将所有的分类变量编码为数字,然后才能评估它们对目标变量的确定性程度。
2. 为了简化代码,这里只使用数值型变量。
3. 定义了一个包含数值型数据类型的列表numerics,其中包括'int16'、'int32'、'int64'、'float16'、'float32'和'float64'。
4. 使用data.select_dtypes(include=numerics)选择数据集中的数值型列,并将其列名存储在numerical_vars列表中。
5. 使用data[numerical_vars]将数据集中的数值型变量提取出来,并赋值给data。
6. 最后,输出data的形状(行数和列数)。
"""numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numerical_vars = list(data.select_dtypes(include=numerics).columns)
data = data[numerical_vars]
data.shape
(1460, 38)
# 导入train_test_split函数用于将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data.drop(labels=['SalePrice'], axis=1),data['SalePrice'],test_size=0.3,random_state=0)X_train.shape, X_test.shape
((1022, 37), (438, 37))
# 导入StandardScaler类,用于特征缩放
# StandardScaler类可以将特征缩放到均值为0,方差为1的标准正态分布
scaler = StandardScaler()
scaler.fit(X_train.fillna(0))
StandardScaler(copy=True, with_mean=True, with_std=True)
# 创建一个Lasso线性回归模型,并设置alpha参数为100,用于惩罚项
# alpha参数越大,惩罚项的影响越大,会强制算法收缩一些系数
sel_ = SelectFromModel(Lasso(alpha=100))
sel_.fit(scaler.transform(X_train.fillna(0)), y_train)
SelectFromModel(estimator=Lasso(alpha=100, copy_X=True, fit_intercept=True,max_iter=1000, normalize=False, positive=False,precompute=False, random_state=None,selection='cyclic', tol=0.0001,warm_start=False),max_features=None, norm_order=1, prefit=False, threshold=None)
# 获取sel_对象的get_support()方法的返回值
sel_.get_support()
array([False, True, True, True, True, True, True, True, True,True, True, False, True, False, True, True, True, True,True, True, True, True, True, True, True, True, True,True, True, True, True, True, True, True, False, True,True])
# 选取特征并打印输出
selected_feat = X_train.columns[(sel_.get_support())] # 选取特征print('total features: {}'.format((X_train.shape[1]))) # 打印总特征数
print('selected features: {}'.format(len(selected_feat))) # 打印选取的特征数
print('features with coefficients shrank to zero: {}'.format(np.sum(sel_.estimator_.coef_ == 0))) # 打印系数收缩至零的特征数
total features: 37
selected features: 33
features with coefficients shrank to zero: 4
-
我们可以看到,Lasso正则化有助于从数据集中删除非重要特征。因此,增加惩罚将导致删除的特征数量增加。因此,我们需要注意并监控,不要设置过高的惩罚,以至于删除了重要特征,也不要设置过低,以至于没有删除非重要特征。
-
如果惩罚过高,导致删除了重要特征,我们将会注意到算法性能下降,然后意识到我们需要减少正则化。
4.2 随机森林重要性
目录
-
随机森林是最受欢迎的机器学习算法之一。它们之所以如此成功,是因为它们通常具有良好的预测性能、低过拟合和易解释性。这种可解释性是由于可以直接推导出每个变量对树决策的重要性。换句话说,可以很容易地计算出每个变量对决策的贡献程度。
-
随机森林由4-12个决策树组成,每个决策树都是在从数据集中随机抽取的观测和特征上构建的。并非每棵树都看到所有的特征或所有的观测,这保证了树之间的相关性较低,因此更不容易过拟合。每棵树也是一系列基于单个或多个特征的是-否问题。在每个节点(即每个问题)上,树将数据集分成两个桶,每个桶中的观测彼此之间更相似,与另一个桶中的观测不同。因此,每个特征的重要性是通过每个桶的“纯度”来衡量的。
-
对于分类问题,不纯度的度量可以是基尼不纯度或信息增益/熵。对于回归问题,不纯度的度量是方差。因此,在训练一棵树时,可以计算每个特征降低不纯度的程度。特征降低不纯度的程度越大,特征的重要性就越高。在随机森林中,可以对每个特征的不纯度减少进行树之间的平均,以确定变量的最终重要性。
-
为了更好地理解,通常在树的顶部选择的特征比在树的末端节点选择的特征更重要,因为通常顶部的分割导致更大的信息增益。
-
使用蘑菇分类数据集来演示这个过程,如下所示:-
# 导入所需的库
from sklearn import preprocessing # 数据预处理库
from sklearn.preprocessing import LabelEncoder # 标签编码库
from sklearn.preprocessing import StandardScaler # 数据标准化库
from sklearn.model_selection import train_test_split # 数据集划分库
from sklearn import tree # 决策树库
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器库# 读取数据集
df = pd.read_csv('/kaggle/input/mushroom-classification/mushrooms.csv')
# 从数据框df中删除'class'列,得到特征向量X
X = df.drop(['class'], axis = 1)# 从数据框df中获取'class'列,作为目标变量y
y = df['class']
# 对分类变量进行编码
X = pd.get_dummies(X, prefix_sep='_') # 使用pd.get_dummies()函数对X进行独热编码,将分类变量转换为二进制的特征向量,并在特征名之间使用下划线作为前缀分隔符# 对目标变量进行标签编码
y = LabelEncoder().fit_transform(y) # 使用LabelEncoder()函数对y进行标签编码,将目标变量转换为从0开始的整数编码表示
# 标准化特征向量
# 使用StandardScaler对特征向量X进行标准化处理
# StandardScaler会将特征向量X的每个特征值减去均值,然后除以标准差,使得特征向量的均值为0,方差为1
# fit_transform方法会计算特征向量X的均值和标准差,并进行标准化处理
X2 = StandardScaler().fit_transform(X)
# 导入train_test_split函数用于划分数据集# 划分数据集
# X2为特征矩阵,y为目标变量
# test_size为测试集所占比例,这里设置为0.30,即测试集占总数据集的30%
# random_state为随机种子,用于保证每次划分的结果一致
X_train, X_test, y_train, y_test = train_test_split(X2, y, test_size = 0.30, random_state = 0)
# 使用n_estimators = 100实例化分类器
clf = RandomForestClassifier(n_estimators=100, random_state=0)
# 将分类器拟合到训练集上# X_train是训练集的特征向量
# y_train是训练集的目标变量clf.fit(X_train, y_train) # 使用训练集对分类器进行拟合操作
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',max_depth=None, max_features='auto', max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, n_estimators=100,n_jobs=None, oob_score=False, random_state=0, verbose=0,warm_start=False)
# 预测测试集上的结果
y_pred = clf.predict(X_test)
特征重要性
- 基于集成的决策树模型(例如Extra Trees和Random Forest)可以用来对不同特征的重要性进行排序。了解模型赋予最重要的特征可以对理解模型如何进行预测(从而使其更具解释性)非常重要。同时,我们可以去除对模型没有任何益处的特征。
# 创建一个图形窗口,设置窗口的大小和分辨率
plt.figure(num=None, figsize=(10,8), dpi=80, facecolor='w', edgecolor='k')# 创建一个Series对象,用于存储特征重要性值,并设置索引为特征名
feat_importances = pd.Series(clf.feature_importances_, index= X.columns)# 获取重要性值最大的前7个特征,并绘制水平条形图
feat_importances.nlargest(7).plot(kind='barh')
<matplotlib.axes._subplots.AxesSubplot at 0x7fddb81850f0>
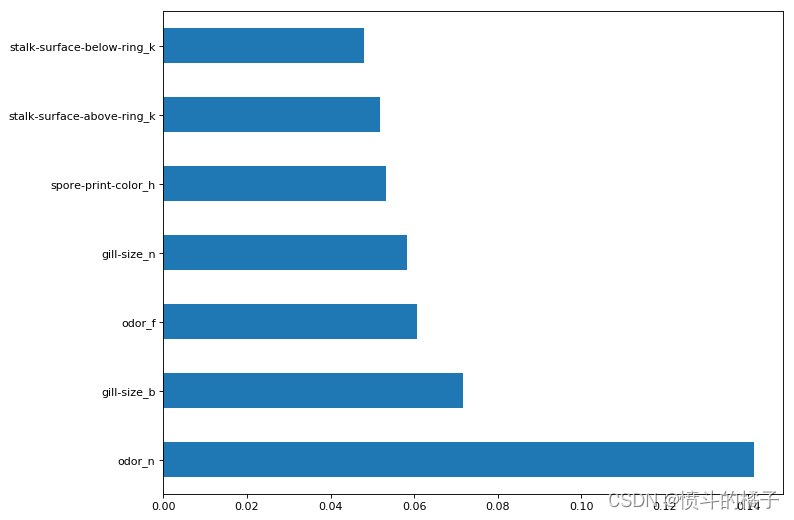
- 现在我们知道了随机森林模型中最重要的特征,我们可以只使用这些特征来训练我们的模型。
5. 如何选择合适的特征选择方法
目录
-
我们可以看到有很多特征选择技术可供选择。
-
下面的图表将作为选择特征选择方法的指南:
数值输入,数值输出
-
这是一个具有数值输入变量的回归预测建模问题。
-
最常见的技术是使用相关系数,如皮尔逊相关系数用于线性相关,或者使用基于排名的方法用于非线性相关。
-
所使用的测试如下:
- 皮尔逊相关系数(线性)。
- 斯皮尔曼秩相关系数(非线性)。
数值输入,分类输出
-
这是一个具有数值输入变量的分类预测建模问题。
-
这可能是分类问题中最常见的例子。
-
同样,最常见的技术是基于相关性的,尽管在这种情况下,它们必须考虑分类目标。
-
我们可以采用以下测试方法:
- 方差分析相关系数(线性)。
- 肯德尔秩相关系数(非线性)。
-
肯德尔秩相关系数假设分类变量是有序的。
分类输入,数值输出
-
这是一个具有分类输入变量的回归预测建模问题。
-
这是一个奇怪的回归问题的例子(例如,我们不经常遇到这种情况)。
-
我们可以使用相同的“数值输入,分类输出”方法(如上所述),但是反过来使用。
分类输入,分类输出
-
这是一个具有分类输入变量的分类预测建模问题。
-
对于分类数据,最常见的相关性测量是卡方检验。我们还可以使用信息论领域的互信息(信息增益)。
-
在这种情况下,可以采用以下测试方法 -
- 卡方检验(列联表)。
- 互信息。
事实上,互信息是一种强大的方法,可以对分类和数值数据都有用,例如,它对数据类型是不可知的。
6. 特征选择的技巧和提示
目录
- 在本节中,我们提供了一些在使用基于过滤的特征选择时需要考虑的额外因素。
相关统计
-
scikit-learn库提供了大多数有用统计量的实现。
-
例如:
- 皮尔逊相关系数:f_regression()
- 方差分析(ANOVA):f_classif()
- 卡方检验:chi2()
- 互信息:mutual_info_classif() 和 mutual_info_regression()。
-
此外,SciPy库还提供了许多其他统计量的实现,例如肯德尔tau(kendalltau)和斯皮尔曼等级相关(spearmanr)。
选择方法
-
scikit-learn库还提供了许多不同的过滤方法,一旦对每个输入变量与目标变量进行了统计计算。
-
其中两种较流行的方法包括:
- 选择前k个变量:SelectKBest
- 选择前百分位数的变量:SelectPercentile
变量转换
-
我们可以考虑对变量进行转换,以便使用不同的统计方法。例如,我们可以将一个分类变量转换为有序变量,即使它本身不是有序的,并查看是否有任何有趣的结果。
-
我们还可以将数值变量离散化(例如分箱);尝试基于分类的度量。
-
一些统计量假设变量具有特定的属性,例如皮尔逊相关系数假设观测值具有高斯概率分布和线性关系。您可以转换数据以满足测试的期望,并尝试测试而不考虑期望,并比较结果。
哪种方法最好?
-
没有最佳的特征选择方法,就像没有最佳的输入变量集或最佳的机器学习算法一样。
-
相反,我们必须通过仔细的系统实验来发现对于您的特定问题最有效的方法。
-
我们应该尝试使用不同的统计方法选择不同特征子集上拟合的不同模型,并发现对于您的特定问题最有效的方法。
特征选择的4种最佳方法
-
特征选择的4种实用方法,可以获得最佳结果,如下所示:
- SelectKBest
- 递归特征消除(Recursive Feature Elimination)
- 带有热力图的相关矩阵(Correlation-matrix with heatmap)
- 随机森林重要性(Random-Forest Importance)
返回顶部