文章目录
- First Program
- 指令系统
- 伪指令
- 数值表达式
- 程序框架解释
- int 21 中断
通过一个基本框架解释各个指令和用处,方便复习。所以我认为最好的学习顺序就是先看一段完整的汇编代码程序,然后给你逐个逐个的解释每一个代码是干嘛用的。然后剩下的还有很多指令或者伪指令会在以后用到的时候再根据具体上下文使用,我认为汇编就是实战出来的,很多指令根本不用记忆,需求出来了,你用了后就知道是怎个事了。
First Program
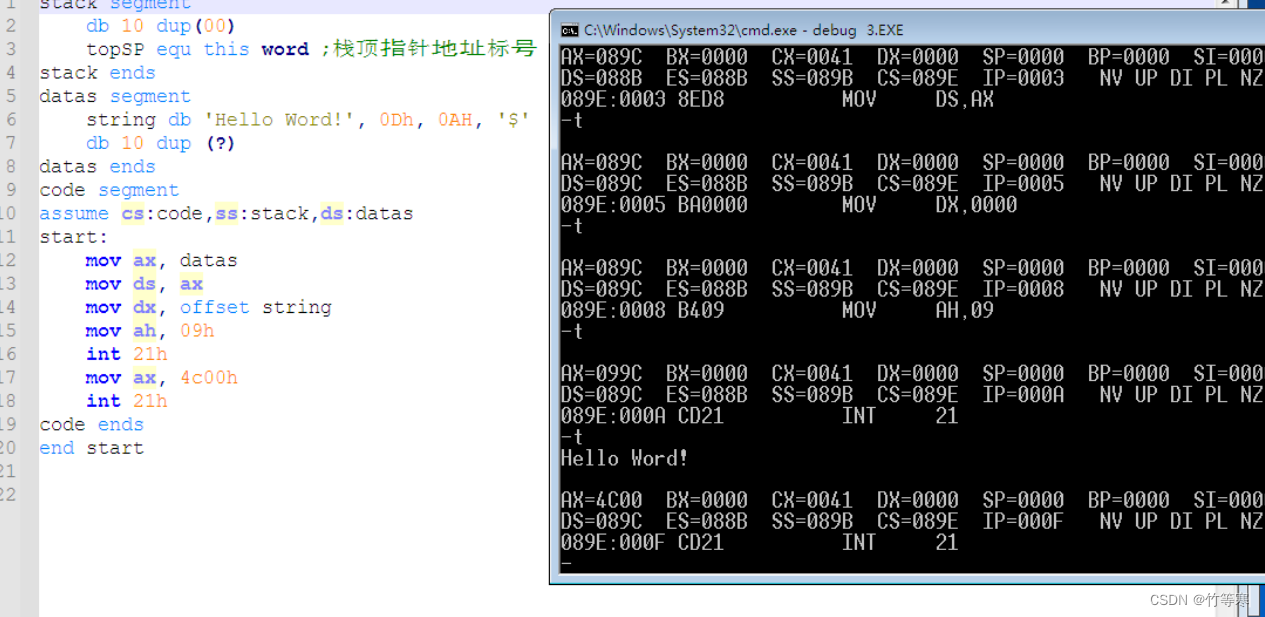
经典Hello Word!
代码如下:
stack segmentdb 10 dup(00)topSP equ this word ;栈顶指针地址标号
stack ends
datas segmentstring db 'Hello Word!', 0Dh, 0AH, '$'db 10 dup (?)
datas ends
code segment
assume cs:code,ss:stack,ds:datas
start:mov ax, datasmov ds, axmov dx, offset stringmov ah, 09hint 21h mov ax, 4c00hint 21h
code ends
end start编译->链接->运行,经过三个步骤就能够使用debug对生成的exe文件调试了
编译命令:masm 名.asm;
链接命令:link 名.obj; (obj文件是在masm后自动生成的)
运行命令:名.exe(exe文件是在link后自动生成的)
debug调试exe命令:debug 名.exe
指令系统
点击复习指令系统
伪指令
伪指令都不占程序空间,因为在编译过程中,你的伪指令全部帮你翻译好了,然后变成机器指令后就只能按照机器指令, 机器指令没有伪指令,伪指令是方便人类阅读代码的,可以通过汇编编译器翻译对应的计算机能够执行的机器指令,比如:fun我把他作为一个函数入口地址,我们编译器翻译的时候不会再fun这一处存fun的地址空间,而是假设你有用到fun这个函数入口地址的话,在你使用该标号的位置处将该标号翻译成fun的入口地址就是fun的下一条指令。
-
标号(他不是伪指令,是一个不占空间但又不是伪指令的东西)
可以理解为变量名,变量的名字可以随便起,这个和下面介绍的名字指令差不多。
标号后一定要接了一个冒号:,表示这个标号可以作为一个地址,地址和下一个指令地址一样。(虽然不是伪指令,但是他也不占程序空间,用来标记程序中某些位置的)随便名标号: mov ax ,bx loop 随便名标号 ... -
名字(就是程序中Stack 或者 datas这些,可以随便命名)
可以理解为变量名,用来记录当前位置的下一条指令或者数据的地址,所以利用这个特点我们就可以用它来定位是一件十分轻松的事情,因为他不占空间地址,写一条指令上去后就可以直接用这个指令的名字来表示地址了,很方便。(这里我程序里面也用到了我给栈顶指针起了个名字topSP ,最显著的特点就是用来当栈顶指针,妈妈再也不用担心我计算指针位置错误了!又因为他不占空间,有了这个标志就直接用就可以找到栈顶指针,不会影响后面的代码位置关系)随便名字段 segment 随便名字段 ends 随便名字段 db 'hello' ... -
ASSUME
翻译就是:假设、设想
在汇编中是指明段寄存器的段名,格式为:assume 段寄存器:随便名字段
随便名字段是段地址,是段地址,是段地址!!
assume可以放在开头也行,不一样放在数据段定义的后面,因为assume是伪指令,汇编编译过程中会帮你翻译好。
很明显这个是给自己编写的段一个归属,比如我datas段就是专门给ds段的,所以在assume中就是ds:datas,这就将我们的datas段数据连接到了数据段了,说到连接,那其实assume的本质就是为了汇编在link的时候将自己写的段设置到正确的段位置。
注意事项:assume是 给自己定义的数据块指明回家的路,回到自己的段内,意思是DS冒号后面你的数据段属于DS段,那你要是用你他的时候就需要在DS里面访问(这里是一个坑,下面我接着说很重要的一点)
还有一点很重要:我们assume定义完成后希望在code代码里面使用这段数据的话,其实代码里面还需要自己将DS段设置为随便名字段对应的段地址,我们的随便名字段就是段地址。
因此正确使用我们定义的数据段因该是:assume cs:随便名字段,ds:datas, ss:随便名字段3 mov ax, datas mov ds, ax将datas段地址给到我们的ds段,由于前面设置了ds:datas,所以编译器看得懂你这段datas数据,否则定义在其他段了你又在ds使用的话就会出问题。datas可以随便起名字
-
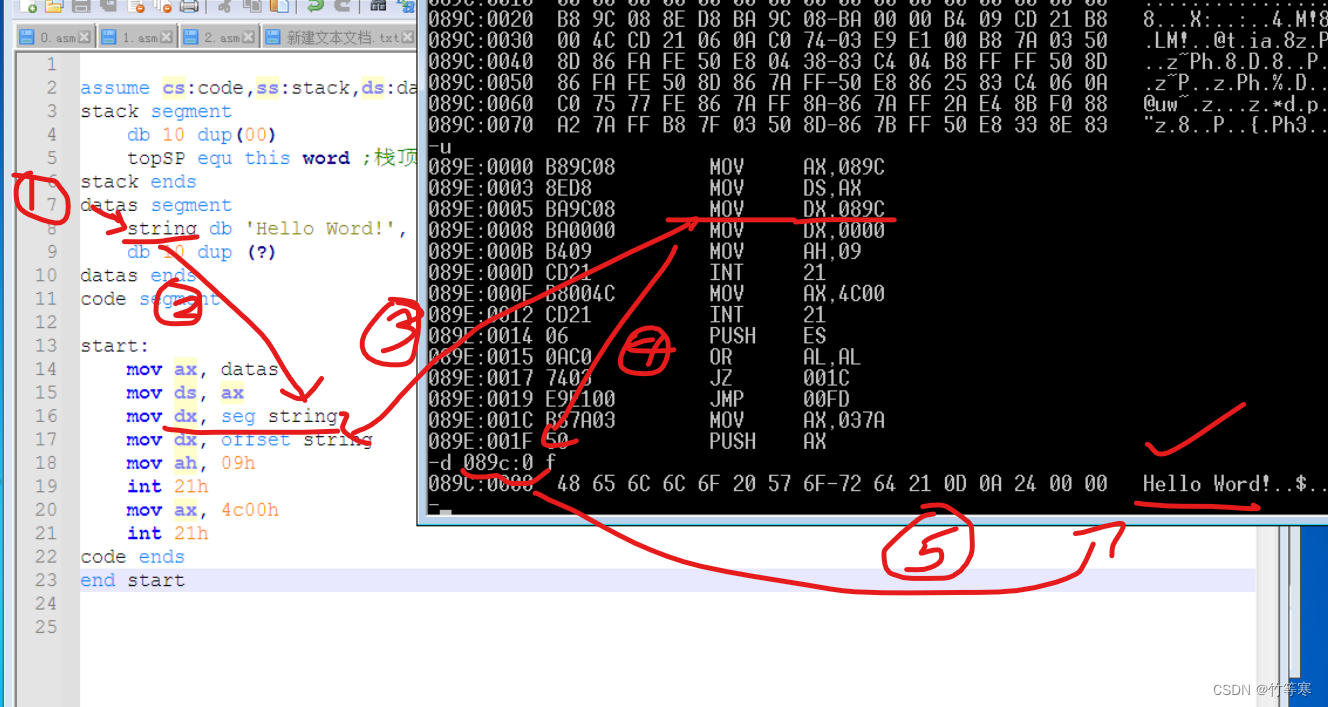
OFFSET 标号或者名字 / SEG 标号或者名字
offset是返回标号在他自己的段的偏移地址
seg是返回标号所在的段地址
一般用法:mov ax, offset string mov ax, seg string;这里返回的是string所在的段地址通过验证也可以知道seg是真的返回了string的段地址,所以有时候不知道string的段地址的名字叫啥比如忘记了datas的话,我们就可以通过这种方式获取段地址,如下图所示
-
DUP
格式:重复次数 DUP (要重复的东西)
DUP一般是用来赋初值的
要重复的东西:这里可以是问号,可以是数值,也可以是字符串等等,字符串也给你重复好多次。
?问号表示不确定是什么,如下图,通过验证后,8086debug中显示是0的状态。
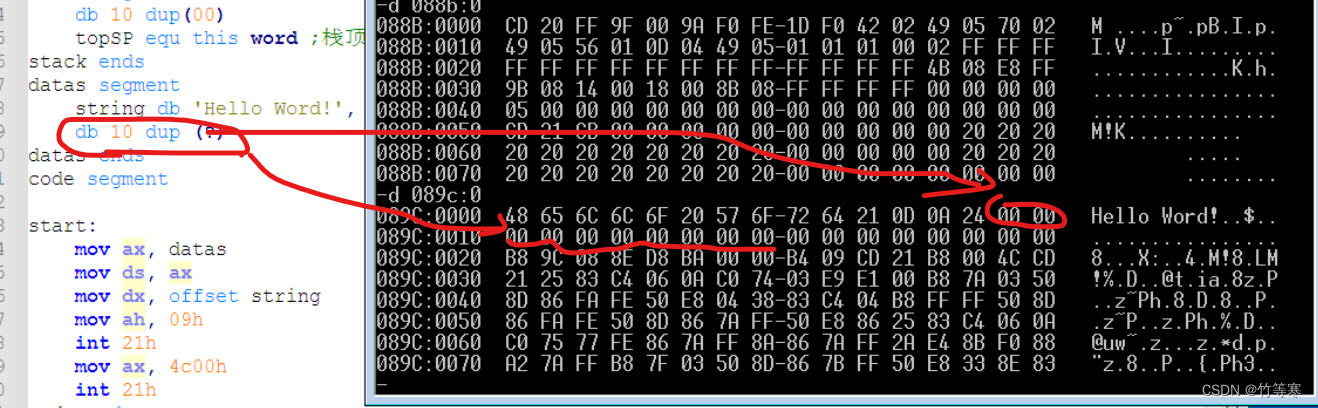
db 10 dup(00) db 10 dup (?) -
DB/DD/DW
DB字节 8字节
DD单字 16字节
DW双字 32字节
用处就是当你定义一个数据段的时候可以指明一个元素占多少字节
好比上一个DUP中用到的就是DB,表示他每一个重复的元素都是占8个字节大小db 10 dup(00) -
$
有时候表示当前地址
比如:使用 $ 和相对偏移计算mov bx, $ - 标号
有时候表示字符串结束符,当我们int 21中 09h的功能就是当遇到$字符的时候停止输出字符。
比如:前面我们定义了string db 'Hello Word!', 0Dh, 0AH, '$' 所以int 21的09号中断程序会在打印字符中遇到$的时候停止 mov ah, 09h nt 21h -
EQU / =
equal相等,=也是相等
格式:随便 equ 12 随便2 = 13那以后代码中出现 了随便,就会在汇编编译过程汇总将随便这个名字换成12同理随便2换成13
-
PTR
在指令系统讲过了,就是指明类型的意思
下面介绍几个用法即可

-
THIS
用法:THIS 类型名
这种用法搭配equ和等号简直无敌,因为是伪指令所有使用他的时候不占程序空间内存,单单用作给编译器翻译,让编译器去做而已,翻译机器码后是没有这个语句的
让我感到优雅的一个语句就是:topSP equ this word ;栈顶指针地址标号
基本一看就懂了,最牛逼的是opSP equ this word伪指令他不占内存。翻译的时候他名字对应的地址是等于下一个指令的地址,并且不会影响你该语句后面的数据段或者代码段位置。我们以后想用栈的时候直接使用topSP这个名字就行,真的是一箭双雕,太优雅了!stack segmentdb 10 dup(00)topSP equ this word ;栈顶指针地址标号 stack ends下图也可以看出确实topSP没有他的内存空间
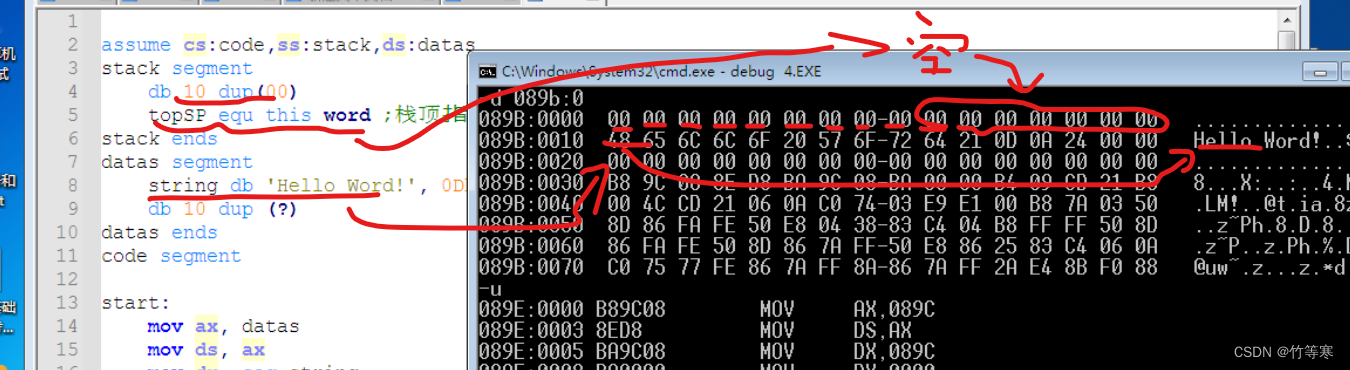
还有一种老师的用法,就是通过地址相同,因为不占空间,但是地址是下一条指令地址,我们直接将f_jump 相等equ与far,因为不指明跳转范围的标号都是段内转移,但是由于f_jump等于下一个指令的地址,但是他的属性类型是far,所以只要用他的名字就可以实现段间转移(确实有点反人类指令)

-
TYPE
这个就是typeofC语言中的函数一样,
type 标号或者名字,能够返回该标号或者名字的类型大小,以字节作为单位,
比如一个标号s是段内转移,那他就是一个byte,返回的就是1,假设像我们f_jump的话,我们type一下他就返回2,因为far是段间
mov ax, type f_jump ;这里等于 mov ax, 2
mov ax, type n_jump ;这里等于 mov ax, 1
-
SIZEOF
这个指令就是量整个变量所占的空间,可以理解为量我们的数据段首地址,然后就会返回你这个数据段的占的字节大小。 -
LENGTHOF
这个就是量你元素个数,数据段中我们可能有多个相同大小的多个元素,那么这个指令就是用来量长度的,量个数的。 -
SIZEOF = TYPE × LENGTHOF
数值表达式
这个就有点推翻以前说的格式了,我们以前的指令格式都是:
操作指令 目的操作数,源操作数
但当你使用数值表达式的话就不一样了,就跟我们平常的写式子的顺序是一样的。
mov ax,3*4+5 ;等价于 mov ax,17
目前看起来很正常,因为我们的乘除法这样使用的在高级语言中也是可以。
or al,03h AND 45h ;等价于 or al,01h
这种就有点迷惑了,首先我们学的and指令都是:and 操作数1,操作数2
但是这种就是跟你写数学式子一样
也是数值表达式的一种特色吧,直接用and没给你改成其他的指令,直接拿硬指令,所以通过这个式子例子就可以猜到后面的用法了,
也就是说当我们需要一种计算的式子的话,可以放到源操作数中进行,不用手动计算,工作交给编译器,编译完成后会直接形成结果,所以不会影响执行速度。
mov al,0101b SHL (2*2);等价于 mov al,01010000b
这个指令就真的是推翻了我在指令系统里面的解释,指令系统中提到过shl如果要移位超过1位的话就要将移位个数存进cl中,然后shl ax, cl才可以多次移位,但是在数值表达式中就直接推翻了,但是 前提是你需要按照数值表达式的格式来写才可以,所以我们可以0101b SHL (2*2),但是这种形式是一个结果,所以我们一般都是需要放在源操作数,然然后送进目的操作数中。
程序框架解释
最后会在int中断号给出相关示例代码,这里只给出模版。
-
assume设置自己定义的数据段时属于哪一个段寄存器的,一般都会有assume,因为我们一般情况下是会定义一个代码段,assume一般是放在开头第一段或者code segment下一行。
-
codes segment …
codes ends
代码段,段都是用segment,
开头段都需要 [段名 segment]
结束段都需要 [段名 ends] -
start:…
end start
start是程序入口,需要在程序最后结尾添上end start,
start是可以随便起名字 -
代码段和入口程序标号通常是交织在一起的,我们就按照正常的格式写。如下:
codes segmentstart:..................
codes ends
end start
整合一下整个框架就是:
(记住,要用数据段的时候千万不要漏掉将ds或者其他段用对应的标号修改,比如:mov ax, datas mov ds, ax,修改ds段地址)
assume cs:codes, ss:stacks, ds:datas
stacks segment
... ... ...
stacks ends
datas segment
... ... ...
datas ends
codes segmentstart:... ...... ...... ...... ...
codes ends
end start int 21 中断
这里是最后一个知识点,因为想要入门一个简单的程序需要用到,但是不会讲的很详细,int中断本来就是一个很大的章节需要慢慢学习,很多功能都能解决很多问题。这里就简单介绍几个常用的功能号
我们在程序中经常会看到这么一段
mov ah, 09h
int 21h
mov ax, 4c00h
int 21h
int 21h是一个DOS系统中断,21h里面包含很多功能,但是需要用寄存器来空间。
怎么控制?
最简单的一个控制,就是当ax等于09h的时候就是打印一个ds段里面的dx偏移地址的字符串,遇到$符号就停止,所以这里终于解释明白了我们First程序的字符串是怎么打印出来的了。
因此可以想象一下,我们int 21h中断有很多功能,那我们不仅仅是一个打印功能,还有很多,有可能是al来控制,也有可能是ah来控制,也有可能是其他寄存器,当然我不知有没有其他寄存器i,只是告诉使用int 21h功能的时候,记得设置功能调用号和参数。
09功能号,参数是ds:dx作为字符串入口
所以就是打印出来一个Hello Word!
4c00h就是意味着代码段程序正常退出
但是不是整个程序结束,整个程序结束时end start,当然 start是随便名,在你代码段开始的start:自己定义名字的。
下面介绍的比如09h数字是ax或者al/ah对应的数字所对应21h中断的功能程序是什么。当然09h上面说过了是打印ds:dx首地址的字符串,遇到$停止
注意:下面需要将中断号传到ah而不是ax,除了4c00需要传到ax,因为他是16位。
-
09h
功能:在显示器输出指定的字符串
DS:DX=欲显示字符串在主存中的首地址
字符串应以$(24H)结束
可以输出回车(0DH)和换行(0AH)字符产生回车和换行的作用

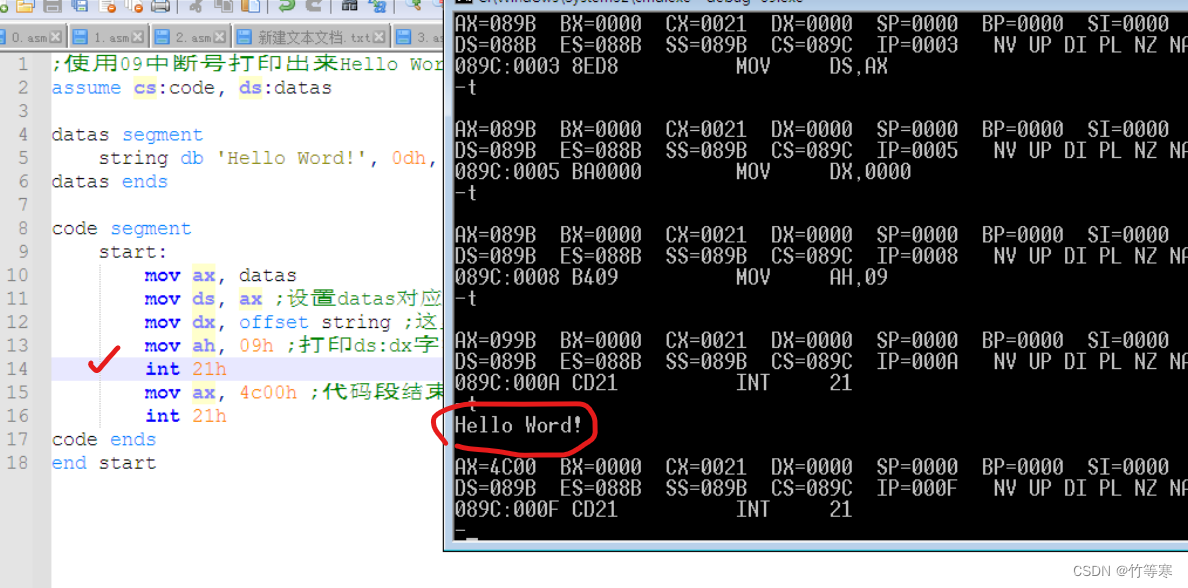
示例代码如下:;使用09中断号打印出来Hello Word! assume cs:code, ds:datasdatas segment string db 'Hello Word!', 0dh, 0ah, '$' datas endscode segmentstart:mov ax, datas mov ds, ax ;设置datas对应的数据段mov dx, offset string ;这里一定要用offset,mov ah, 09h ;打印ds:dx字符串,遇到$停止int 21hmov ax, 4c00h ;代码段结束int 21h code ends end start -
01h
功能:获得按键的ASCII代码值
功能号:AH=01H
出口参数:AL=字符的ASCII码
调用此功能时,若无键按下,则会一直等待,直到按键后才读取该键值
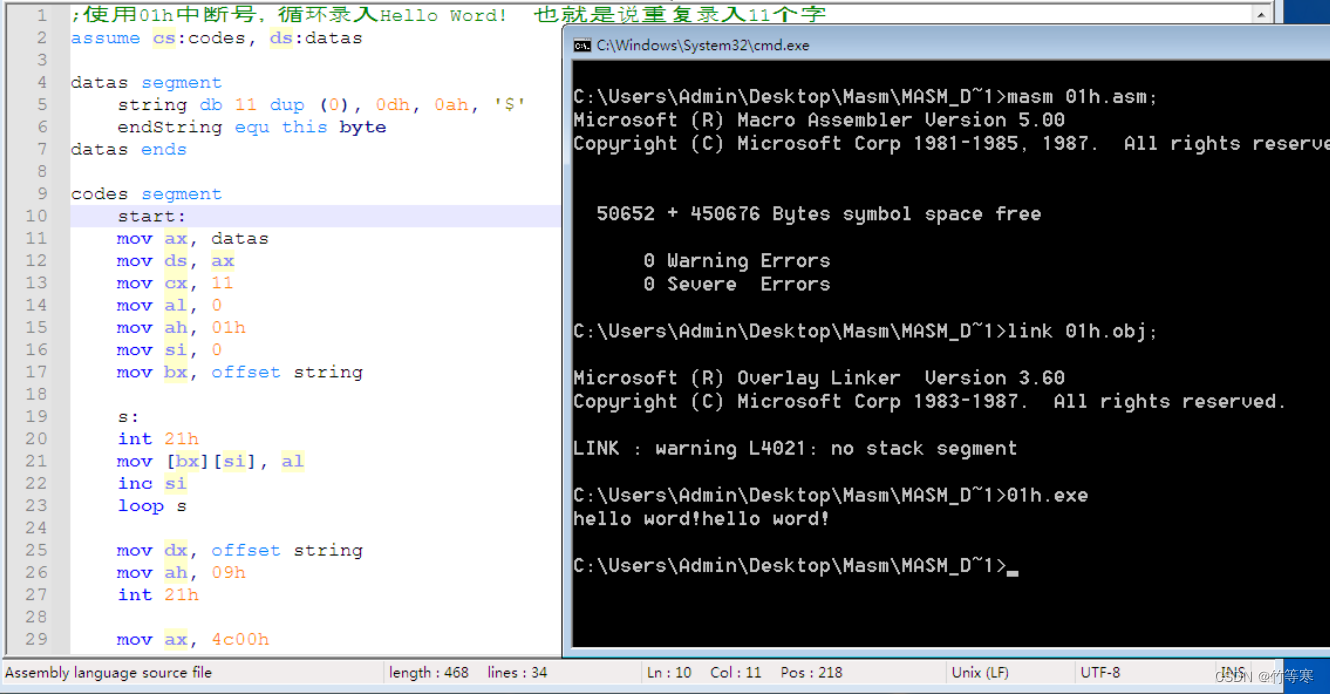
示例代码如下:;使用01h中断号,循环录入Hello Word! 也就是说重复录入11个字符 assume cs:codes, ds:datasdatas segmentstring db 11 dup (0), 0dh, 0ah, '$'endString equ this byte datas endscodes segmentstart:mov ax, datasmov ds, axmov cx, 11mov al, 0mov ah, 01hmov si, 0mov bx, offset string s:int 21hmov [bx][si], al inc siloop smov dx, offset string mov ah, 09hint 21hmov ax, 4c00hint 21hcodes ends end start -
02h
功能:在显示器当前光标位置显示给定的字符,光标右移一个字符位置。如按Ctrl-Break或Ctrl-C则退出
功能号:AH=02H
入口参数:DL=字符的ASCII码
既然他是显示一个字符就右移一个字符,那就是说我们可以利用循环每调用一次显示一个字符也不会覆盖住我们先前显示的字符了。理论存在,开始实现!
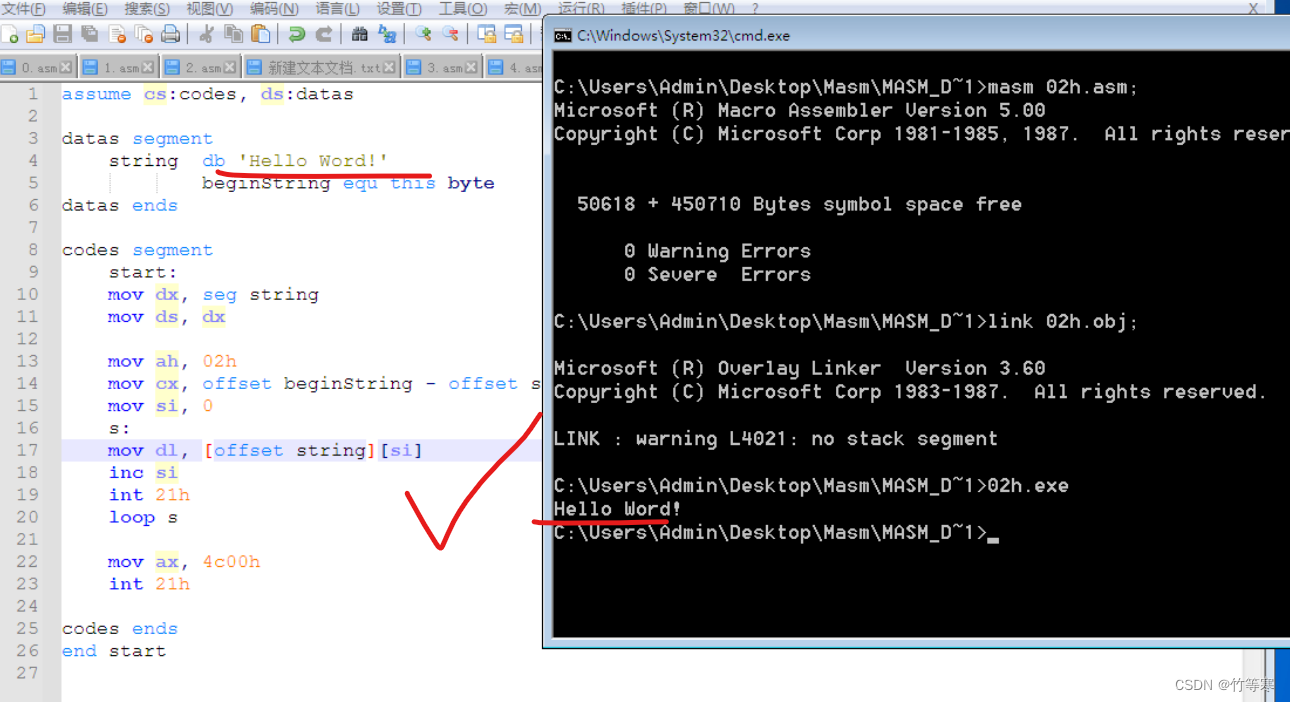
示例代码如下:
assume cs:codes, ds:datasdatas segmentstring db 'Hello Word!'beginString equ this byte
datas endscodes segmentstart:mov dx, seg stringmov ds, dxmov ah, 02hmov cx, offset beginString - offset stringmov si, 0s:mov dl, [offset string][si]inc siint 21hloop smov ax, 4c00hint 21hcodes ends
end start -
0ah
功能:执行该功能调用时,用户按键,最后用回车确认
功能号:AH=0AH
入口参数:DS:DX=缓冲区首地址
本调用可执行全部标准键盘编辑命令;用户按回车键结束输入,如按Ctrl+Break或Ctrl+C则中止细节:首先这个其实是有三个参数,
就拿datas段来举例子datas segment string db 12 ;这个是用来表示你最大可以输;入多少个字符,这里是包含回车的,不要忘记db 0 ;这里是表示你的输入字符个数,;会在你输入的时候自动计算,然后一般是0db 12 dup(0) ;这里是存你输入的字符串,;所以你要输出的话就要记得将string 地址偏移地址;偏移到该为止,这里由于是db大小所以偏移两个byte。下图证明了无论你第二个参数设置什么,都是默认帮你计算好最终你输入多少个字符的,我这里是输入了10个字符,但是我设置的是11,最后结果是a=10那就代表是强制性计数器。

下面是执行结果,输入字符串直到回车结束,但是我们这里设置了12个加上回车符号那就是只能够输入11个字符,所以刚好输入Hello Word!,然后再利用09h中断号再次找到字符串入口输出。
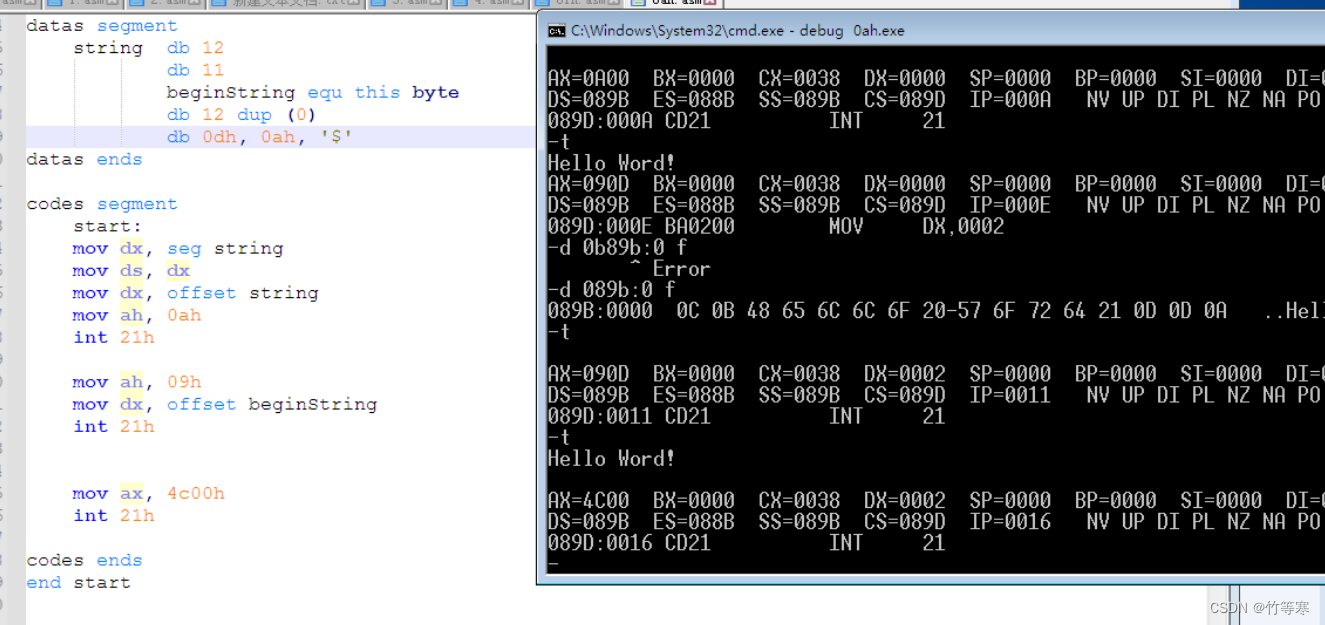
下面是示例代码:assume cs:codes, ds:datasdatas segmentstring db 12db 11beginString equ this bytedb 12 dup (0)db 0dh, 0ah, '$' datas endscodes segmentstart:mov dx, seg stringmov ds, dxmov dx, offset string mov ah, 0ahint 21hmov ah, 09hmov dx, offset beginStringint 21hmov ax, 4c00hint 21hcodes ends end start -
0bh
功能:仅判断当前是否有按下的键,设置AL后退出
功能号:AH=0BH
出口参数:AL=0,当前没有按键;
AL=FFH,当前已经按键。
注意的是这里讲的是出口参数,是用来判断你该是否按下按键了这个就不打算写示例了,因为就是用来测试有没有按键事件发生的一个中断号,可能在写游戏程序用到很多。