1.主要结构
transformer 是一种深度学习模型,主要用于处理序列数据,如自然语言处理任务。它在 2017 年由 Vaswani 等人在论文 “Attention is All You Need” 中提出。
Transformer 的主要特点是它完全放弃了传统的循环神经网络(RNN)和卷积神经网络(CNN),而是完全依赖于注意力机制(Attention Mechanism)来捕捉输入序列中的模式。
Transformer 的主要组成部分包括:
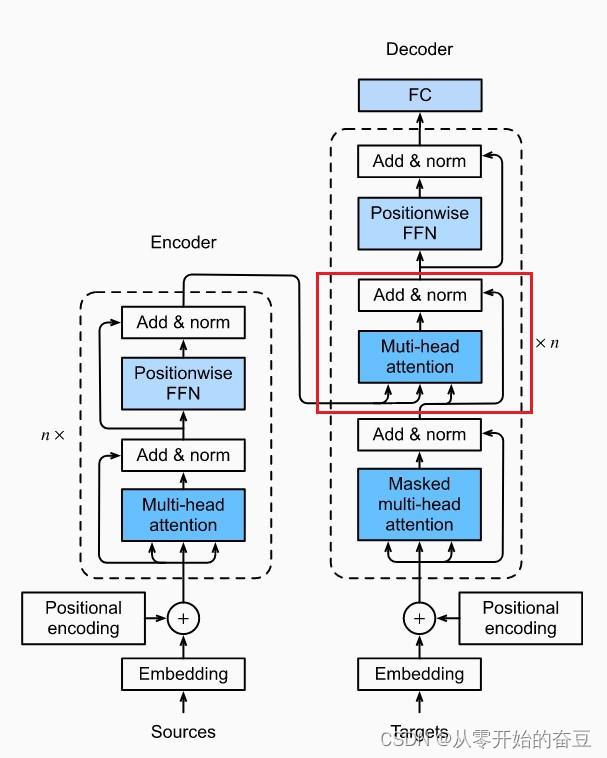
1.自注意力机制(Self-Attention):自注意力机制能够处理序列数据,并且能够关注到序列中的任何位置,从而捕捉到长距离的依赖关系。
2.位置编码(Positional Encoding):由于 Transformer 没有循环和卷积操作,所以需要额外的位置编码来捕捉序列中的顺序信息。
3.编码器和解码器(Encoder and Decoder):Transformer 模型由编码器和解码器组成。编码器用于处理输入序列,解码器用于生成输出序列。编码器和解码器都是由多层自注意力层和全连接层堆叠而成。
2.自注意力机制
个人理解就是把字符编码后通过公式相乘变为另一个向量。
通过关注X中的词嵌入,我们在Y中生成了复合嵌入(加权平均值)。例如,Y中的dog嵌入是X中的the、dog和ran嵌入的组合,权重分别为0.2、0.7 和0.1。
构建词嵌入如何帮助模型实现理解语言的最终目标?要完全理解语言,仅仅理解组成句子的各个单词是不够的;还需要理解组成句子的各个单词。模型必须理解单词在句子上下文中如何相互关联。注意力机制通过形成模型可以推理的复合表示,使模型能够做到这一点。例如,当语言模型尝试预测句子“the runningdog was ___”中的下一个单词时,除了单独的“running ”或“dog”概念之外,模型还应该理解“runningdog”的复合概念;例如,走狗经常喘气,所以喘气是句子中合理的下一个词。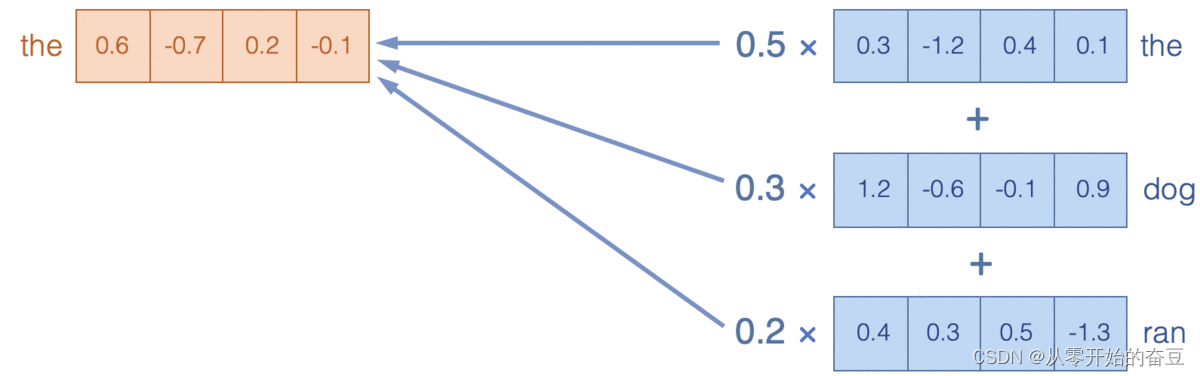
2.1注意力可视化
通过bertviz可视化,bert模型记得替换
from bertviz import head_view, model_view
from transformers import BertTokenizer, BertModel
import imageio
model_version = 'D:\PycharmProjects\Multimodal emotion\model\\bert-base-chinese'
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version)
sentence_a = "好不好?燕子,你要开心,你要幸福,好不好?"
sentence_b = "开心啊,幸福。你的世界以后没有我了,没关系,你要自己幸福。"
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt')
print(inputs)
input_ids = inputs['input_ids']
print(input_ids)
token_type_ids = inputs['token_type_ids']
print(token_type_ids)
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
print(attention)
sentence_b_start = token_type_ids[0].tolist().index(1)
print(sentence_b_start)
input_id_list = input_ids[0].tolist() # Batch index 0
print(input_id_list)
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
print(tokens)head_view(attention, tokens, sentence_b_start)下面的可视化(在此处以交互形式提供)显示了示例输入文本引起的注意力。该视图将注意力可视化为连接正在更新的单词(左)和正在关注的单词(右)的线,遵循上图的设计。颜色强度反映注意力权重;接近 1 的权重显示为非常暗的线条,而接近 0 的权重显示为微弱的线条或根本不可见。用户可以突出显示特定单词以仅看到来自该单词的注意力。

升级一下,来讲多头注意力
它扩展了模型关注不同位置的能力。原来的编码 包含一些其他编码,但它可能由实际单词本身主导。如果我们翻译一个句子,比如“The Animal did not cross the street because it was tooert”,那么知道“it”指的是哪个单词会很有用。
它为注意力层提供了多个“表示子空间”。正如我们接下来将看到的,通过多头注意力,我们不仅拥有一组查询/键/值权重矩阵,而且拥有多组查询/键/值权重矩阵(Transformer 使用八个注意力头,因此我们最终为每个编码器/解码器提供八组,但是bert用12或24) 。这些集合中的每一个都是随机初始化的。然后,在训练之后,每个集合用于将输入嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。
BERT 还堆叠了多个注意力层,每个注意力层都对前一层的输出进行操作。通过这种词嵌入的重复组合,BERT 能够在到达模型最深层时形成非常丰富的表示。我们接着写代码展示
model_view(attention, tokens, sentence_b_start)
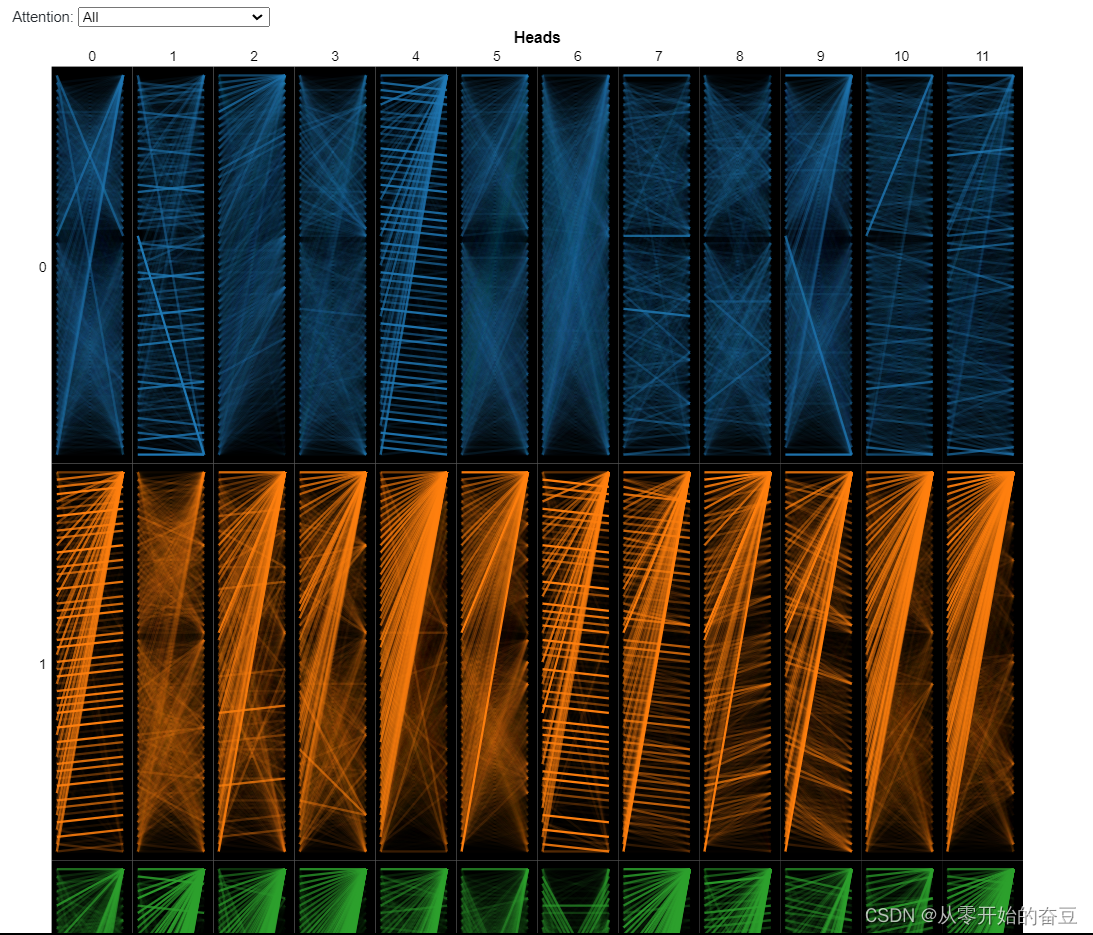
由于注意力头不共享参数,因此每个头都会学习独特的注意力模式。我们在这里考虑的 BERT 版本——BERT Base——有 12 层和 12 个头,总共有 12 x 12 = 144 个不同的注意力机制。我们可以使用模型视图(此处以交互形式提供)同时可视化所有头部的注意力:
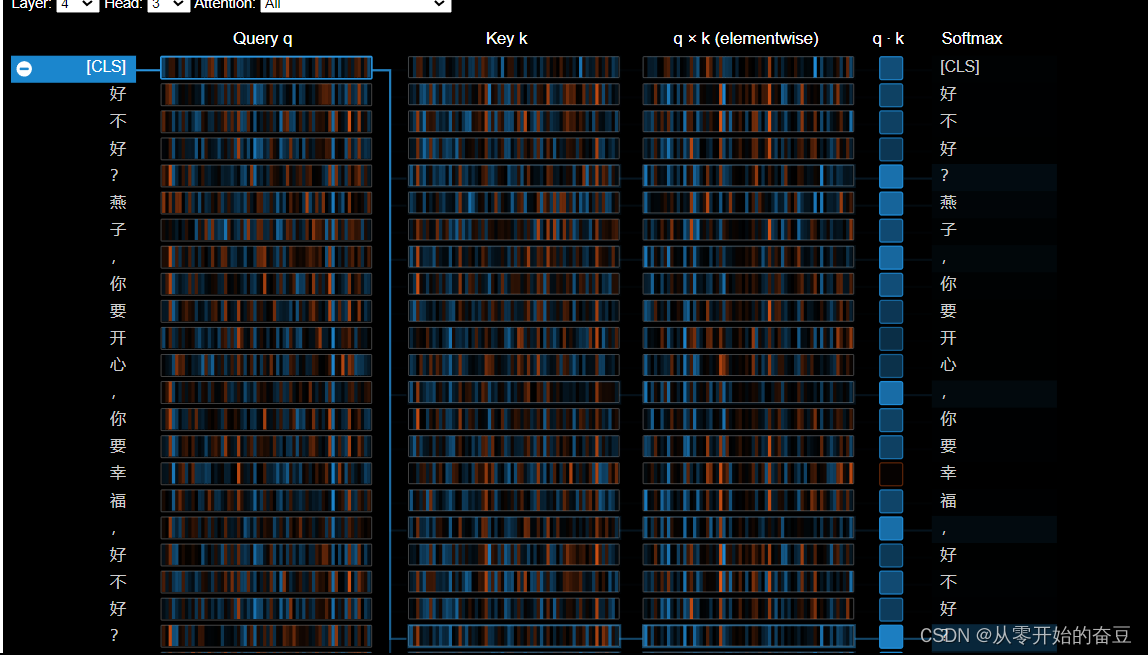
接着我们引入一些概念:
-
查询 q:查询 向量q编码左侧正在关注的单词,即“查询”其他单词的单词。在上面的示例中,“on”(所选单词)的查询向量被突出显示。
-
密钥k:密钥向量k对右侧所关注的单词进行编码。关键字向量和查询向量一起确定两个单词之间的兼容性分数。
-
q×k (elementwise):所选单词的查询向量与每个键向量之间的元素乘积。这是点积(元素乘积之和)的前身,包含在内是为了可视化目的,因为它显示了查询和键向量中的各个元素如何对点积做出贡献。
-
q·k:所选查询向量和每个关键 向量的缩放点积(见上文)。这是非标准化注意力分数。 Softmax:缩放点积的
-
Softmax。这会将注意力分数标准化为正值且总和为 1。
代码
from bertviz.transformers_neuron_view import BertModel, BertTokenizer
from bertviz.neuron_view import showmodel_type = 'bert'
model_version = 'D:\PycharmProjects\Multimodal emotion\model\\bert-base-chinese'
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version, do_lower_case=True)
show(model, model_type, tokenizer, sentence_a, sentence_b, layer=4, head=3)
该视图跟踪从左侧所选单词到右侧完整单词序列的注意力计算。正值显示为蓝色,负值显示为橙色,颜色强度代表大小。与前面介绍的注意力头视图一样,连接线表示相连单词之间的注意力强度。
2.2原理
回顾上面我所说的概念,运用如下公式

计算得分,多头是这样子的,就是增加了维度,把多头注意力拼接在一起
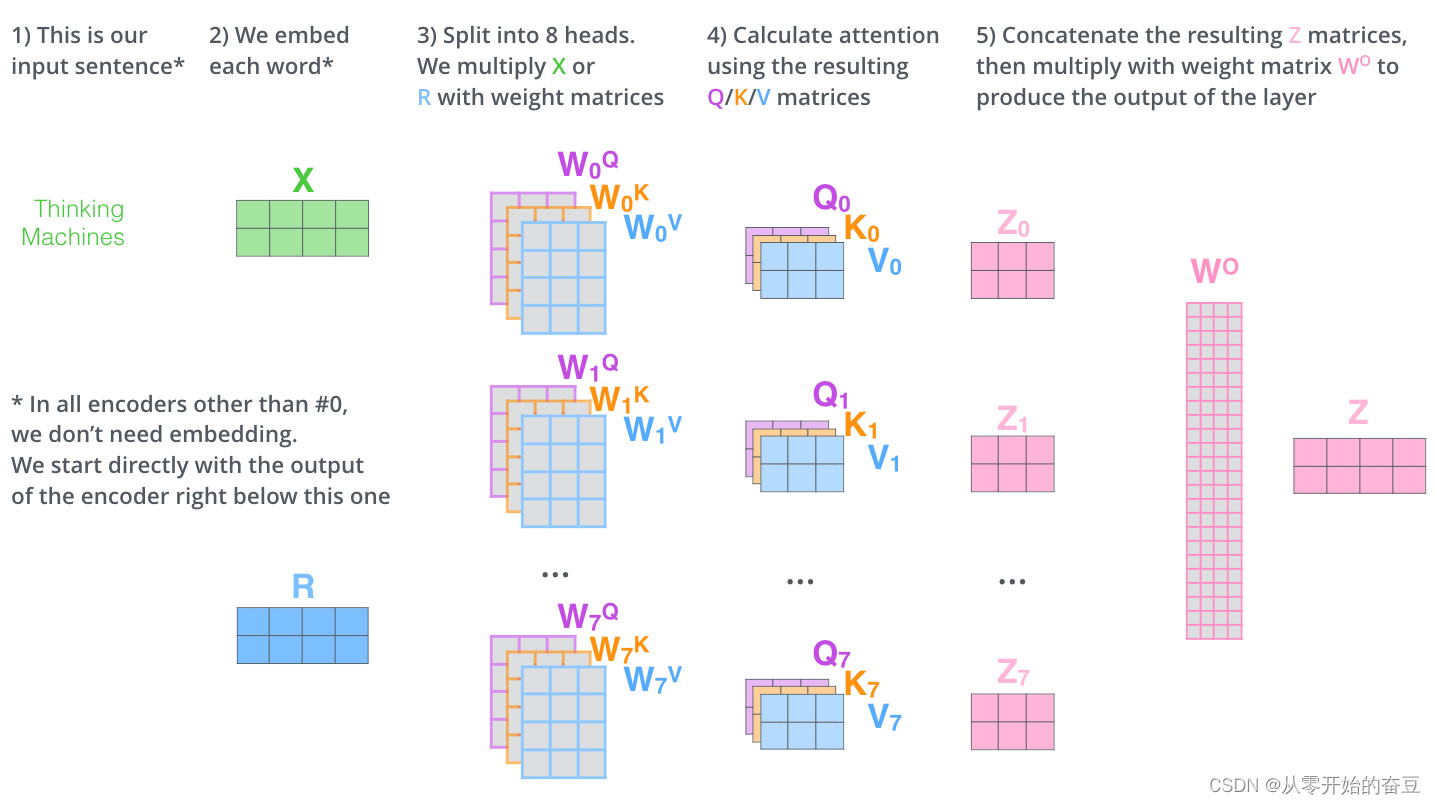
transformer的结构:
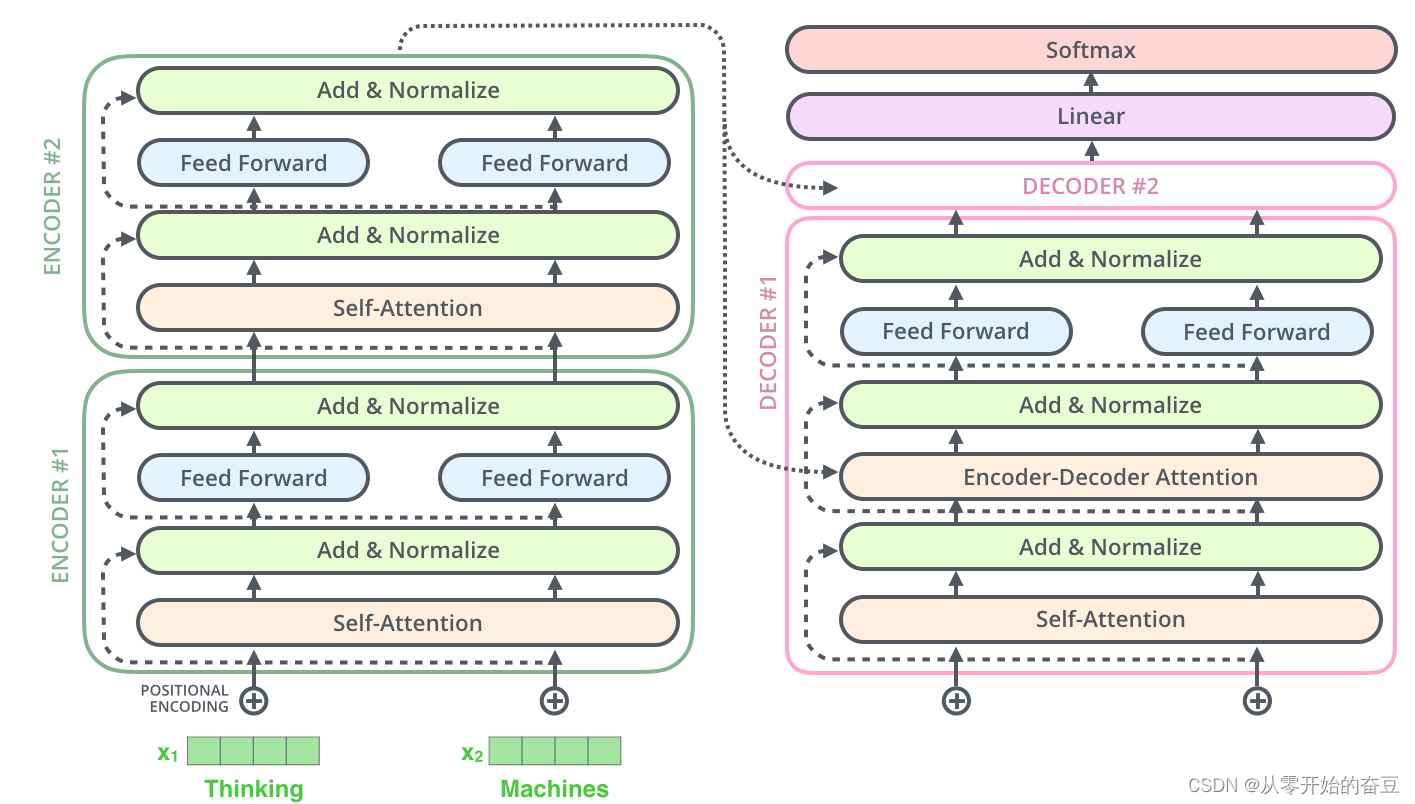
经历多头注意力再经过归一化层和前馈神经网络,每个head64维,因为有8个head,应该得到512维,但是bert有12个head,应该得到768维。
举个简单的例子来理解一下
这是利用transformer进行翻译
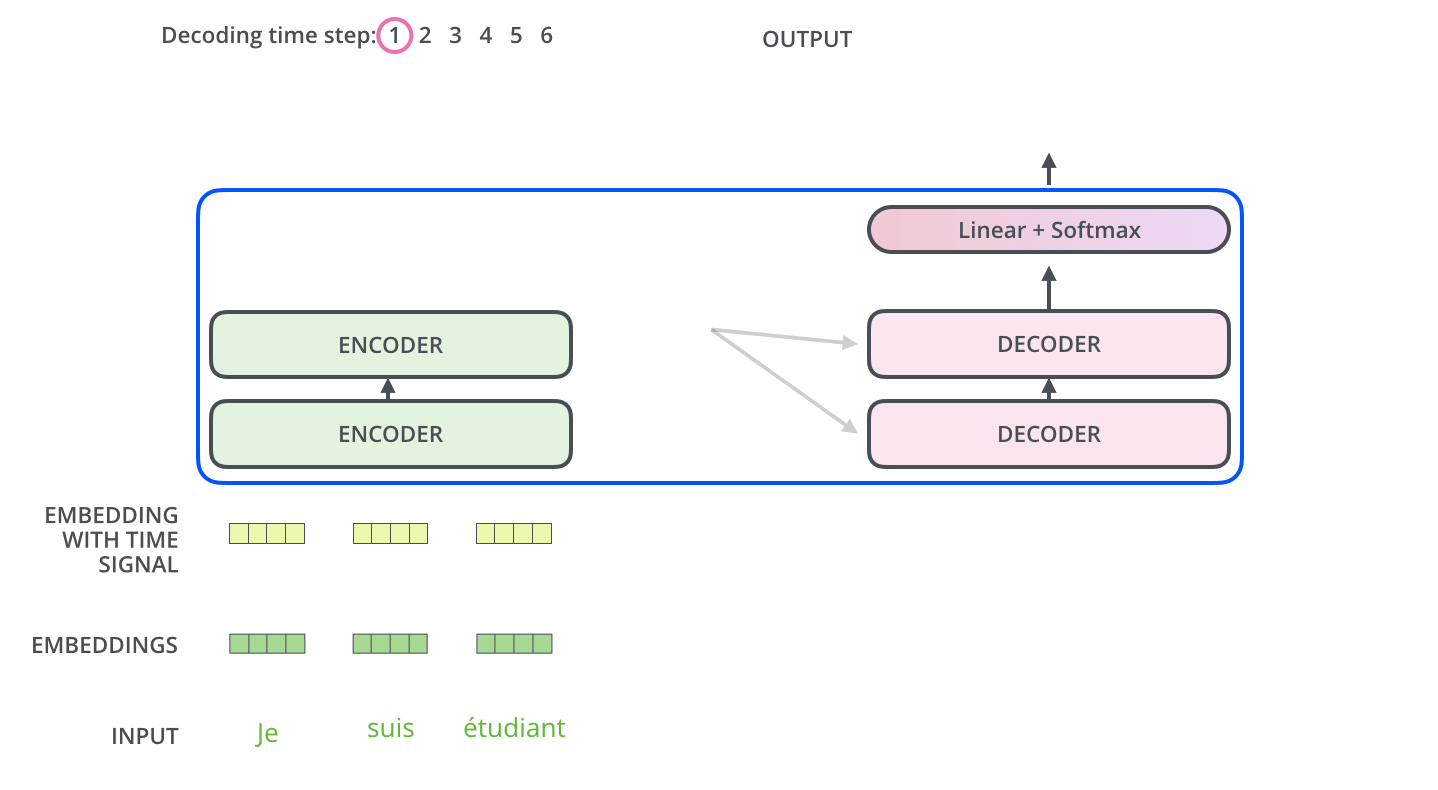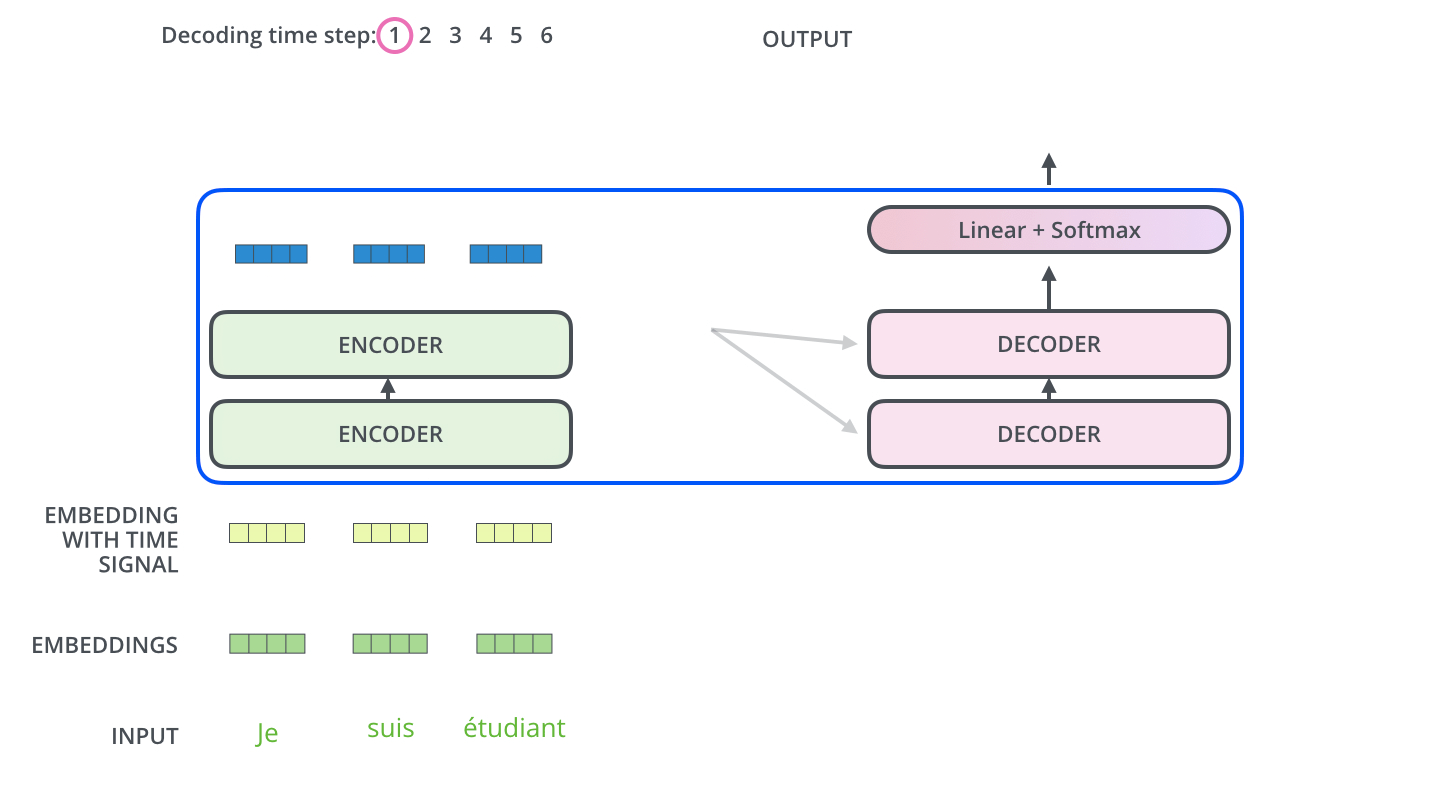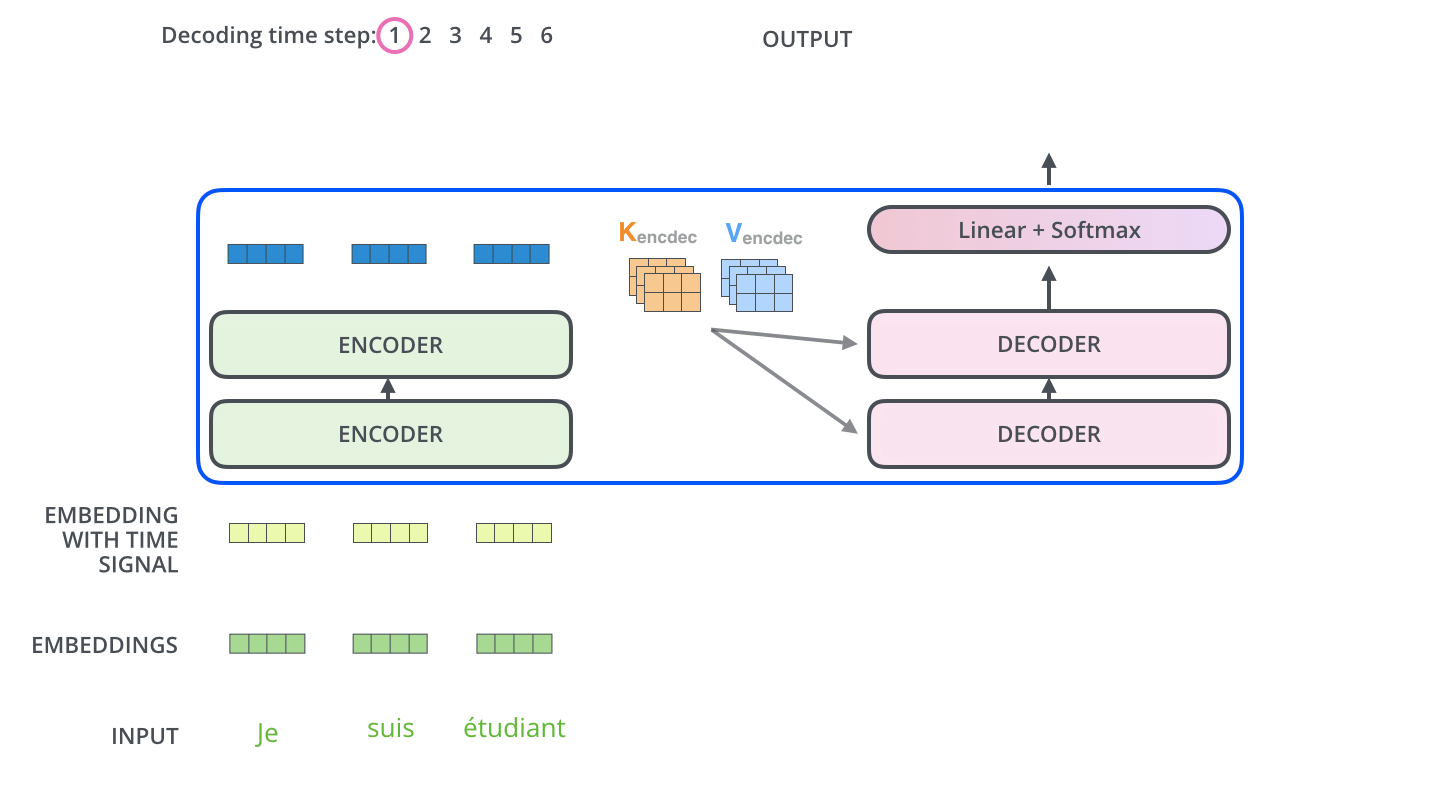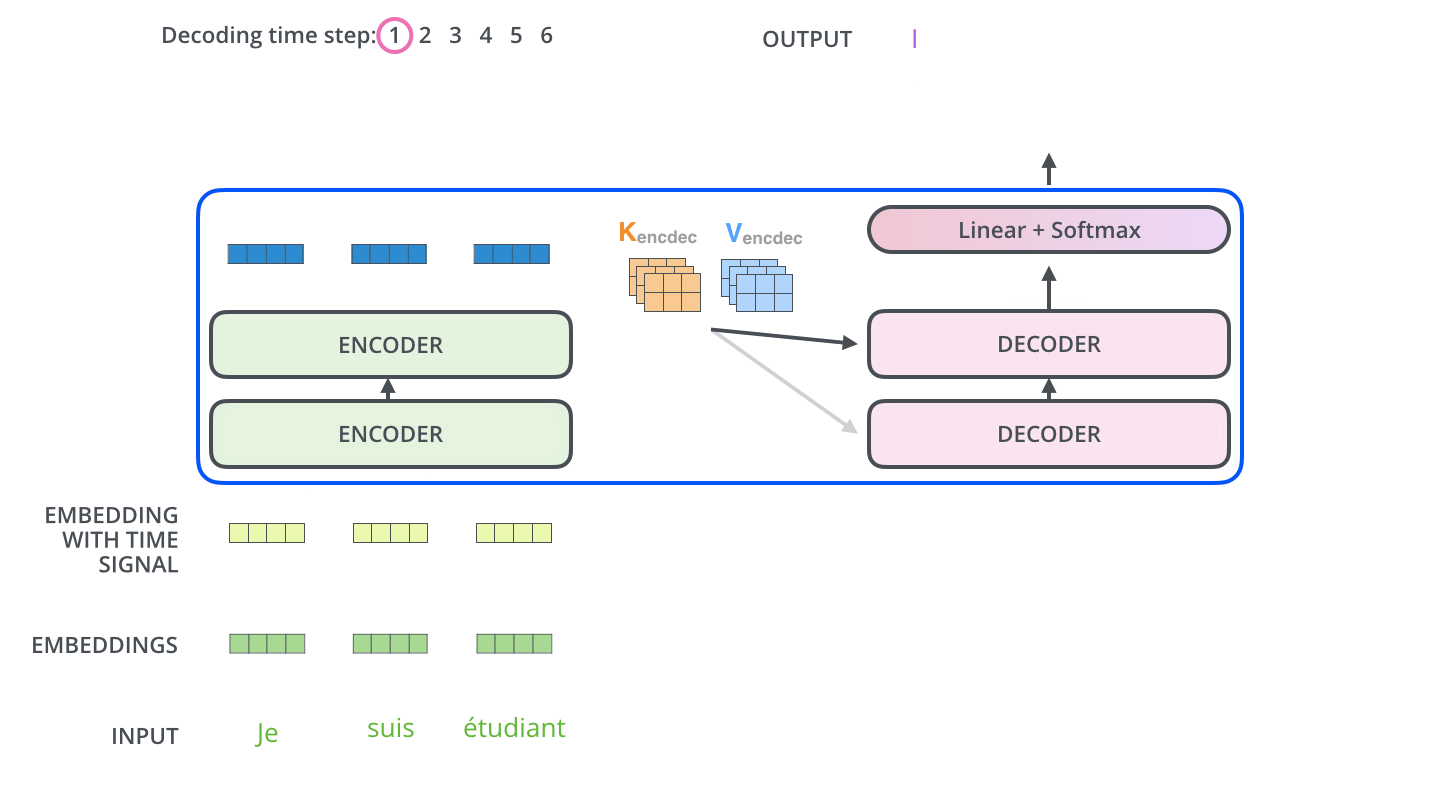

encoders是编码器,decoders是解码器。
3.Positional Encoding
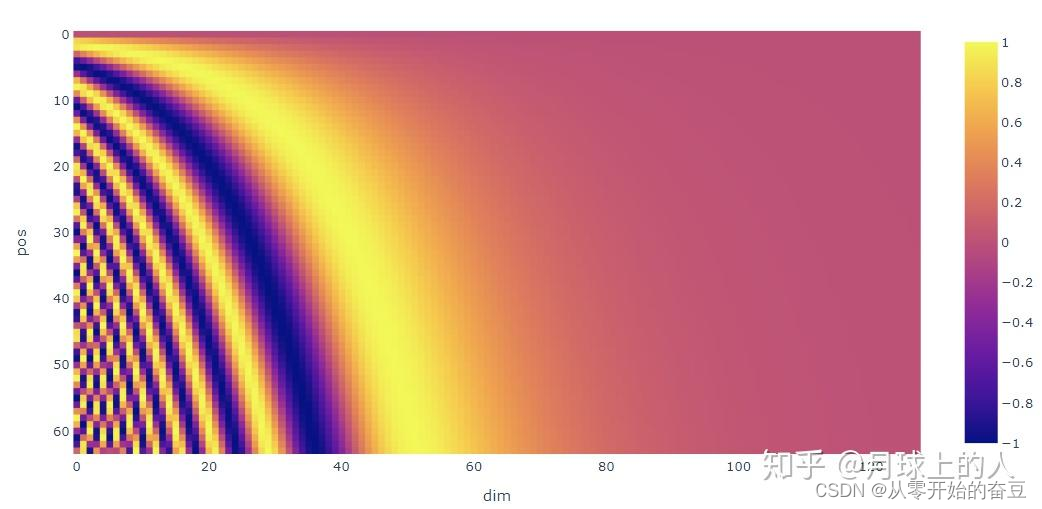
一句话概括,Positional Encoding就是句子中词语相对位置的编码,让Transformer保留词语的位置信息。
t t t表示当前词语在句子中的位置,
p t → \overrightarrow{p_t} pt表示的是该词语对应的位置编码,
d d d表示的是编码的维度。
公式如下
p t → = [ sin ( ω 1 . t ) cos ( ω 1 . t ) sin ( ω 2 . t ) cos ( ω 2 . t ) ⋮ sin ( ω d / 2 . t ) cos ( ω d / 2 . t ) ] d × 1 \left.\overrightarrow{p_t}=\left[\begin{array}{c}\sin(\omega_1.t)\\\cos(\omega_1.t)\\\\\sin(\omega_2.t)\\\cos(\omega_2.t)\\\\\vdots\\\\\sin(\omega_{d/2}.t)\\\cos(\omega_{d/2}.t)\end{array}\right.\right]_{d\times1} pt= sin(ω1.t)cos(ω1.t)sin(ω2.t)cos(ω2.t)⋮sin(ωd/2.t)cos(ωd/2.t) d×1
从公式可以看出,其实一个词语的位置编码是由不同频率的余弦函数函数组成的,从低位到高位。
不同频率的sines和cosines组合其实也是同样的道理,通过调整三角函数的频率,我们可以实现这种低位到高位的变化,这样的话,位置信息就表示出来了。