欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流
本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle

分析函数的点点滴滴
- 1.什么是分析函数:
- 1.1统计分析函数略解
- 1.2.排序分析函数
- 1.3 开窗函数 ROW 与 RANGE
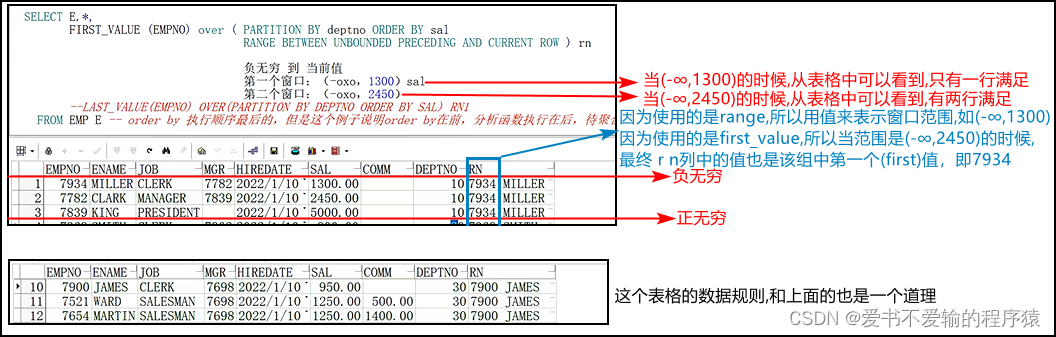
- 1.3.1`range`的窗口范围是`负无穷 ~ 当前值(range逻辑行,当前行与行中的值有关,所以到当前值)`,负无穷是每个组的最上面,正无穷在每个组的下面
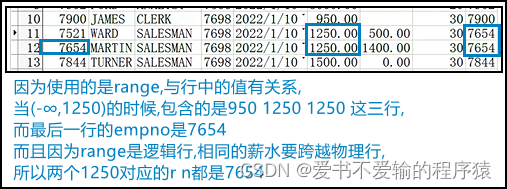
- 1.3.2`rows`看的是物理行,与行中的值是没有关系的
- 1.3.3 将`first_value`换成 `last_value`,观察 `range`和 `rows`
- 1.3.4 自定义`rows between ... preceding and ...`
- 1.3.5 自定义`range between ... preceding and ...`
- 1.4 统计分析函数详解
- 1.4.1 分析函数使用sum()进行累计
- 1.4.2 使用count()进行累计
- 1.4.3 使用max()进行求最大值
- 1.5 不使用order by时
1.什么是分析函数:
👉:传送门💖分析函数💖
1.1统计分析函数略解
👉:传送门💖统计分析函数💖
1.2.排序分析函数
👉:传送门💖排序分析函数💖
1.3 开窗函数 ROW 与 RANGE
-
row 物理行 与行中的值是没有关系的
-
range 逻辑行 与行中的值是有关系的
select e.*,first_value(empno) over (partition by deptno order by sal) rn
from emp e;select e.*,first_value(empno) over (partition by deptno order by sal range between unbounded preceding and current row -- 忽略的Windows子句,与上面没有加Windows子句的sql命令的作用是一样的
) rn
from emp e;
range between unbounded preceding and current row指定了要统计的窗口范围,这个窗口范围也是面向行的,只是比partiton更细,先partiton分组,再按组里面看窗口范围
1.3.1range的窗口范围是负无穷 ~ 当前值(range逻辑行,当前行与行中的值有关,所以到当前值),负无穷是每个组的最上面,正无穷在每个组的下面
- 所以用
first_value的时候,不加range between unbounded preceding and current row这个子句是没有问题的,因为总能统计到第一行
1.3.2rows看的是物理行,与行中的值是没有关系的
select e.*,first_value(empno) over (partition by deptno order by sal rows between unbounded preceding and current row
) rn
from emp e;

1.3.3 将first_value换成 last_value,观察 range和 rows
select e.*,last_value(empno) over (partition by deptno order by salrange between unbounded preceding and current row) rn
from emp e;

select e.*,last_value(empno) over (partition by deptno order by salrows between unbounded preceding and current row) rn
from emp e;
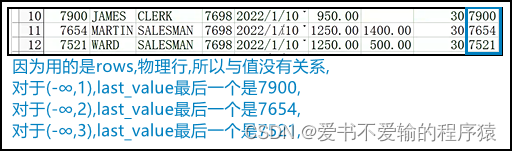
1.3.4 自定义rows between ... preceding and ...
select e.*,last_value(empno) over (partition deptno order by salrows between 1 preceding and 1 following) rn
from emp e;
1 preceding代表的是当前行的前一行,1 FOLLOWING则代表的是当前行的后一行

- 如果写成
unbounded followingUNBOUNDED FOLLOWING表示在窗口函数中不限制窗口范围的结束位置,也就是说窗口的结束位置一直延伸至最后一行
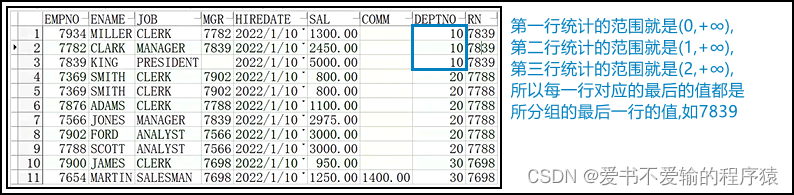
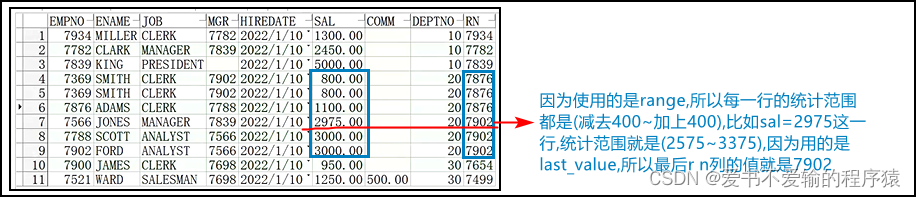
1.3.5 自定义range between ... preceding and ...
- 因为
range是逻辑行,与值有关,所以在...中填写的内容应该根据表格中的值来决定
select e.*,last_value(empno) over (partition by deptno order by salrange between 400 preceding and 400 following) rn
from emp e;
1.4 统计分析函数详解
1.4.1 分析函数使用sum()进行累计
select t.*,sum(sal) over(partition by deptno order by sal) cum_sum from emp t; -- 分析函数可以写group by,但是不需要
-
在
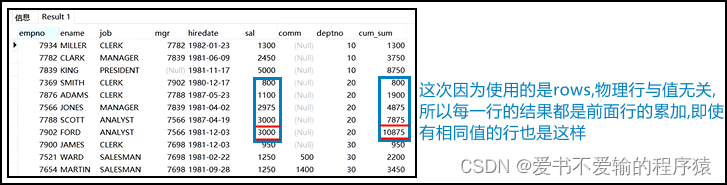
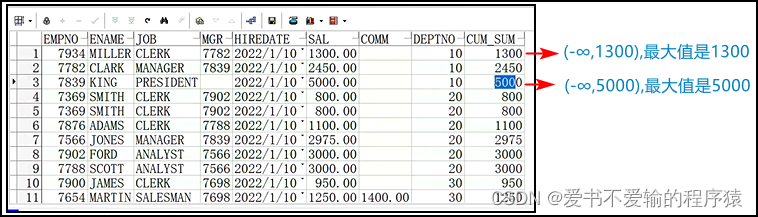
order by后面默认忽略了一个子句range between unbounded preceding and current row,即默认忽略了一个逻辑行的(-∞~当前值)的子句- 但是从下图中可以看出,当有两行的值一样的时候,其实并没有达到我们想要的累计效果
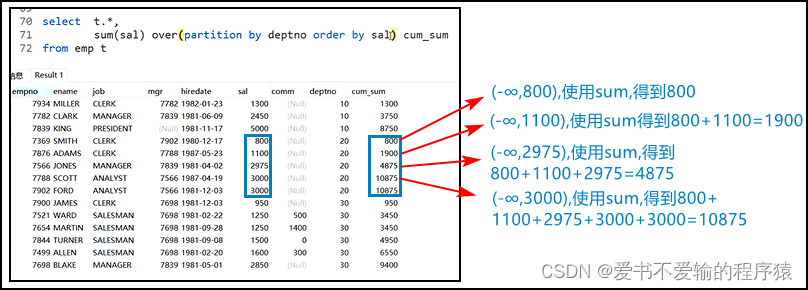
- 但是从下图中可以看出,当有两行的值一样的时候,其实并没有达到我们想要的累计效果
-
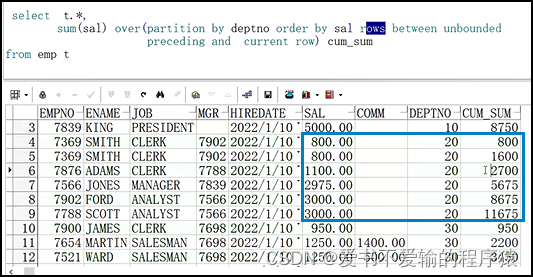
使用
rows进行改进,以达到想要的累计效果
select t.*,sum(sal) over(partition by deptno order by sal rows between unbounded preceding and current row) cum_sum
from emp t;
- Oracle:
select t.*,sum(sal) over(partition by deptno order by sal rows between unbounded preceding and current row) cum_sum
from emp t;
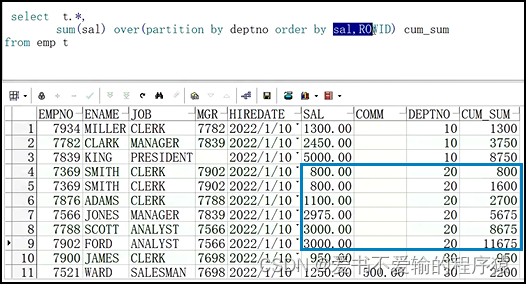
select t.*,sum(sal) over(partition by deptno order by sal,rowid) cum_sum -- 使用rowid,相当于实现了一个物理行的统计
from emp t;
# oracle 也可以使用rowid,因为rowid是指向内存的唯一的地址,是决定数据库如果找到记录的,这个行号是唯一的
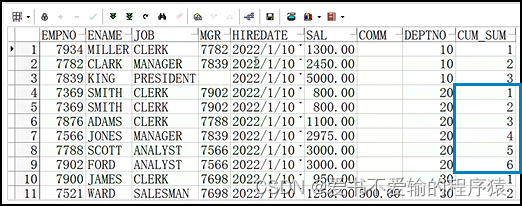
1.4.2 使用count()进行累计
select t.*,count(sal) over(partition by deptno order by sal,rowid) cum_sum
from emp t;
# 效果与row_number() over()有点像
1.4.3 使用max()进行求最大值
select t.*,max(sal) over(partition by deptno order by sal) cum_sum -- 求得是最大值,所以就不能用物理行了
from emp t;
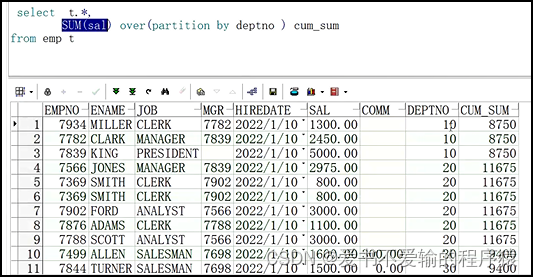
1.5 不使用order by时
# 按照部门编号进行分区,然后使用sum()得到每个组的薪水和
select t.*,sum(sal) over(partition by deptno) cum_sum
from emp t;
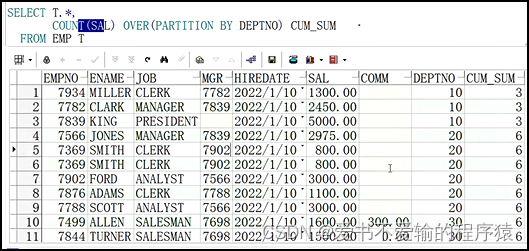
# 统计每组有薪水的人数,因为count()动态忽略null
select t.*,count(sal) over(partition by deptno) cum_sum
from emp t;
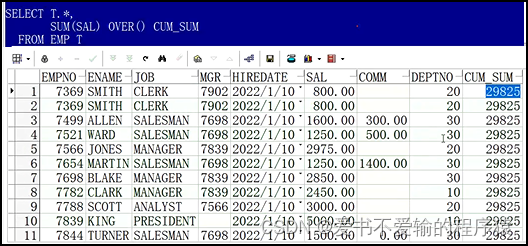
# 求出了所有人的薪水和
# 分析函数不会减少行数,数据有几行,求完和的结果就有几行
select t.*,sum(sal) over cum_sum
from emp t;
- 求占比
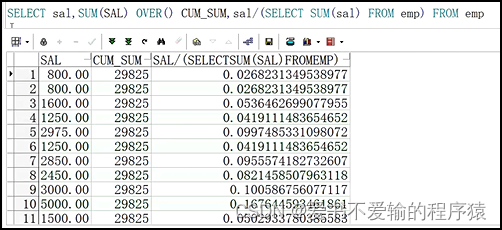
select sal,sal/sum(sal) over() cum_sum,sal/(select sum(sal) from emp) from emp;