1.有哪些方法能提升CNN模型的泛化能力
-
采集更多数据:数据决定算法的上限。
-
优化数据分布:数据类别均衡。
-
选用合适的目标函数。
-
设计合适的网络结构。
-
数据增强。
-
权值正则化。
-
使用合适的优化器等。
2.BN层面试高频问题大汇总
BN层解决了什么问题?
统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。对于神经网络的各层输出,由于它们经过了层内卷积操作,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,但是它们所能代表的label仍然是不变的,这便符合了covariate shift的定义。
因为神经网络在做非线性变换前的激活输入值随着网络深度加深,其分布逐渐发生偏移或者变动(即上述的covariate shift)。之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(比如sigmoid),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。而BN就是通过一定的正则化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,避免因为激活函数导致的梯度弥散问题。所以与其说BN的作用是缓解covariate shift,也可以说BN可缓解梯度弥散问题。
BN的公式

其中scale和shift是两个可学的参数,因为减去均值除方差未必是最好的分布。比如数据本身就很不对称,或者激活函数未必是对方差为1的数据有最好的效果。所以要加入缩放及平移变量来完善数据分布以达到比较好的效果。
BN层训练和测试的不同
在训练阶段,BN层是对每个batch的训练数据进行标准化,即用每一批数据的均值和方差。(每一批数据的方差和标准差不同)
而在测试阶段,我们一般只输入一个测试样本,并没有batch的概念。因此这个时候用的均值和方差是整个数据集训练后的均值和方差,可以通过滑动平均法求得:
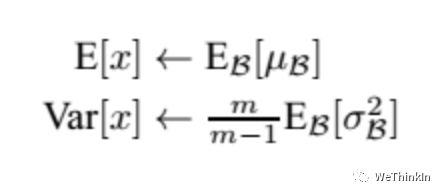
上面式子简单理解就是:对于均值来说直接计算所有batch u u u 值的平均值;然后对于标准偏差采用每个batch σ B σ_B σB 的无偏估计。
在测试时,BN使用的公式是:

BN训练时为什么不用整个训练集的均值和方差?
因为用整个训练集的均值和方差容易过拟合,对于BN,其实就是对每一batch数据标准化到一个相同的分布,而不同batch数据的均值和方差会有一定的差别,而不是固定的值,这个差别能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
BN层用在哪里?
在CNN中,BN层应该用在非线性激活函数前面。由于神经网络隐藏层的输入是上一层非线性激活函数的输出,在训练初期其分布还在剧烈改变,此时约束其一阶矩和二阶矩无法很好地缓解 Covariate Shift;而BN的分布更接近正态分布,限制其一阶矩和二阶矩能使输入到激活函数的值分布更加稳定。
BN层的参数量
我们知道 γ γ γ 和 β β β 是需要学习的参数,而BN的本质就是利用优化学习改变方差和均值的大小。在CNN中,因为网络的特征是对应到一整张特征图上的,所以做BN的时候也是以特征图为单位而不是按照各个维度。比如在某一层,特征图数量为 c c c ,那么做BN的参数量为 c ∗ 2 c * 2 c∗2 。
BN的优缺点
优点:
-
可以选择较大的初始学习率。因为这个算法收敛很快。
-
可以不用dropout,L2正则化。
-
不需要使用局部响应归一化。
-
可以把数据集彻底打乱。
-
模型更加健壮。
缺点:
-
Batch Normalization非常依赖Batch的大小,当Batch值很小时,计算的均值和方差不稳定。
-
所以BN不适用于以下几个场景:小Batch,RNN等。
3.Instance Normalization的作用
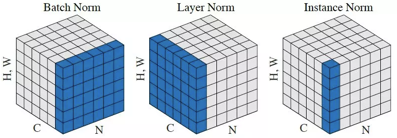
Instance Normalization(IN)和Batch Normalization(BN)一样,也是Normalization的一种方法,只是IN是作用于单张图片,而BN作用于一个Batch。
BN对Batch中的每一张图片的同一个通道一起进行Normalization操作,而IN是指单张图片的单个通道单独进行Normalization操作。如下图所示,其中C代表通道数,N代表图片数量(Batch)。
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个Batch进行Normalization操作并不适合图像风格化的任务,在风格迁移中使用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。
下面是IN的公式:
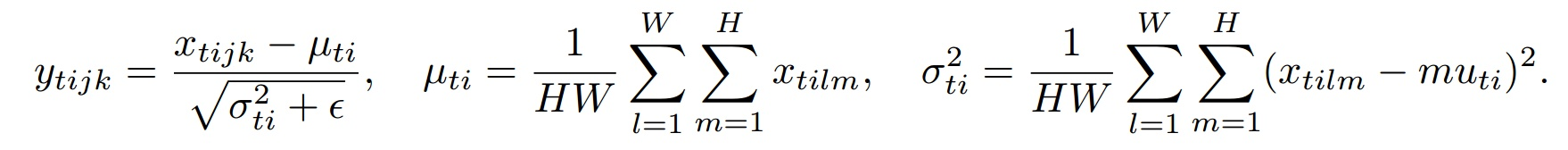
其中t代表图片的index,i代表的是feature map的index。
4.有哪些提高GAN训练稳定性的Tricks
1.输入Normalize
- 将输入图片Normalize到 [ − 1 , 1 ] [-1,1] [−1,1] 之间。
- 生成器最后一层的输出使用Tanh激活函数。
Normalize非常重要,没有处理过的图片是没办法收敛的。图片Normalize一种简单的方法是(images-127.5)/127.5,然后送到判别器去训练。同理生成的图片也要经过判别器,即生成器的输出也是-1到1之间,所以使用Tanh激活函数更加合适。
2.替换原始的GAN损失函数和标签反转
-
原始GAN损失函数会出现训练早期梯度消失和Mode collapse(模型崩溃)问题。可以使用Earth Mover distance(推土机距离)来优化。
-
实际工程中用反转标签来训练生成器更加方便,即把生成的图片当成real的标签来训练,把真实的图片当成fake来训练。
3.使用具有球形结构的随机噪声 $Z$ 作为输入
- 不要使用均匀分布进行采样

- 使用高斯分布进行采样
4.使用BatchNorm
- 一个mini-batch中必须只有real数据或者fake数据,不要把他们混在一起训练。
- 如果能用BatchNorm就用BatchNorm,如果不能用则用instance normalization。

5.避免使用ReLU,MaxPool等操作引入稀疏梯度
- GAN的稳定性会因为引入稀疏梯度受到很大影响。
- 最好使用类LeakyReLU的激活函数。(D和G中都使用)
- 对于下采样,最好使用:Average Pooling或者卷积+stride。
- 对于上采样,最好使用:PixelShuffle或者转置卷积+stride。
最好去掉整个Pooling逻辑,因为使用Pooling会损失信息,这对于GAN训练没有益处。
6.使用Soft和Noisy的标签
- Soft Label,即使用 [ 0.7 − 1.2 ] [0.7-1.2] [0.7−1.2] 和 [ 0 − 0.3 ] [0-0.3] [0−0.3] 两个区间的随机值来代替正样本和负样本的Hard Label。
- 可以在训练时对标签加一些噪声,比如随机翻转部分样本的标签。
7.使用Adam优化器
- Adam优化器对于GAN来说非常有用。
- 在生成器中使用Adam,在判别器中使用SGD。
8.追踪训练失败的信号
- 判别器的损失=0说明模型训练失败。
- 如果生成器的损失稳步下降,说明判别器没有起作用。
9.在输入端适当添加噪声
- 在判别器的输入中加入一些人工噪声。
- 在生成器的每层中都加入高斯噪声。
10.生成器和判别器差异化训练
- 多训练判别器,尤其是加了噪声的时候。
11.Two Timescale Update Rule (TTUR)
对判别器和生成器使用不同的学习速度。使用较低的学习率更新生成器,判别器使用较高的学习率进行更新。
12.Gradient Penalty (梯度惩罚)
使用梯度惩罚机制可以极大增强 GAN 的稳定性,尽可能减少mode collapse问题的产生。
13.Spectral Normalization(谱归一化)
Spectral normalization可以用在判别器的weight normalization技术,可以确保判别器是K-Lipschitz连续的。
14.使用多个GAN结构
可以使用多个GAN/多生成器/多判别器结构来让GAN训练更稳定,提升整体效果,解决更难的问题。
5.深度学习炼丹可以调节的一些超参数
- 预处理(数据尺寸,数据Normalization)
- Batch-Size
- 学习率
- 优化器
- 损失函数
- 激活函数
- Epoch
- 权重初始化
- NAS网络架构搜索
6.Spectral Normalization的相关知识
Spectral Normalization是一种wegiht Normalization技术,和weight-clipping以及gradient penalty一样,也是让模型满足1-Lipschitz条件的方式之一。
Lipschitz(利普希茨)条件限制了函数变化的剧烈程度,即函数的梯度,来确保统计的有界性。因此函数更加平滑,在神经网络的优化过程中,参数变化也会更稳定,不容易出现梯度爆炸。
Lipschitz条件的约束如下所示:

其中 K K K 代表一个常数,即利普希茨常数。若 K = 1 K=1 K=1 ,则是1-Lipschitz。
在GAN领域,Spectral Normalization有很多应用。在WGAN中,只有满足1-Lipschitz约束时,W距离才能转换成较好求解的对偶问题,使得WGAN更加从容的训练。
如果想让矩阵A映射: R n → R m R^{n}\to R^{m} Rn→Rm 满足K-Lipschitz连续,K的最小值为 λ 1 \sqrt{\lambda_{1}} λ1 ( λ 1 \lambda_{1} λ1 是 A T A A_TA ATA 的最大特征值),那么要想让矩阵A满足1-Lipschitz连续,只需要在A的所有元素上同时除以 λ 1 \sqrt{\lambda_{1}} λ1 (Spectral norm)。
Spectral Normalization实际上在做的事,是将每层的参数矩阵除以自身的最大奇异值,本质上是一个逐层SVD的过程,但是真的去做SVD就太耗时了,所以采用幂迭代的方法求解。过程如下图所示:

得到谱范数 σ l ( W ) \sigma_l(W) σl(W) 后,每个参数矩阵上的参数皆除以它,以达到Normalization的目的。