记一次关于架构设计从0到1的讨论
简介:
在一次面试中和面试官讨论起来架构设计这个话题,一聊就不知不觉一个小时了,感觉意犹未尽。现在回想起来感觉挺有意思的,古人说独学而无友则孤陋而寡闻,的确是这样的,这次的交流让我对架构设计方面的见解加深了,于是激动不已的想记录一下关于架构设计的思路。
一、什么是架构设计
要聊架构设计这一话题首先我们要知道什么是架构,百科中介绍:软件架构所指的就是说相应的系列性的抽象模式,可以为设计大型软件系统的各个方面提供相应的指导。从本质上来看,软件架构是属于一种系统草图。这段定义我感觉等于白说了,反正我是没理解。我觉得架构应该这么理解,就像搭房子,我们需要方案设计、人员安排、物料规划。这些结合在一起才算是完整的架构设计过程。而相对于软件项目,在方案设计方面我们需要有项目说明书、架构设计图,依据项目说明书我们来做方案。
其中最重要的一个环节就是制作架构设计图,分别有业务架构、应用架构、数据架构、技术架构、部署架构。这些设计出来之后整体项目总体方案基本就确定下来了,接下来就是项目执行的细节设计了。
二、架构设计要思考哪些方面
2.1、系统技术方案选型
2.1.1、云服务or自建机房
如果是公司系统完全从0开始,第一步还需要考虑公有云服务or自建机房搭建私有云。
首先来看一下云服务,市面上份额较大的云厂商:阿里云、腾讯云、华为云。根据个人以往都是使用的阿里云,这里以阿里云为例来进行说明,各厂家服务都大同小异。如下是阿里云上热门产品的展示:

由列表可以看到云服务商提供的云产品品类是非常丰富的,架构设计中需要使用的组件都提供了。根据以往经验使用云服务方案具备维护成本低、服务稳定性高。有一点就是费用较高。
这里也说一下自建机房,首先自建机房需要大量的初始成本,包括购买服务器、网络设备、空调系统等,其次就是维护成本高:自建机房需要处理大量的维护问题,包括服务器维护、网络维护、安全维护等,这不仅需要人力成本,还需要时间和精力,尤其是在面对多个地点的机房时,复杂性将会更高; 然后就是需要独立的技术支持:自建机房需要有专业的技术人员进行管理和维护。自建机房有一个好处就是成本相对会低一些。
一般来说云服务和自建机房会结合来使用,云服务稳定性高一些我们就会规划用来部署线上业务系统,相对次要的一些服务比如研发环境、测试环境我们选择放到机房,另外研发日常中一些新技术测试和研究的资源也建议使用本地机房。
2.1.2、系统架构设计
在系统架构设计这块我们要考虑如下方面:负载均衡方案、中间件、数据存储方案、安全方案、运维方案。下面会简单介绍一下各方面的思考,因为每一个方面都需要大量篇幅才能讲清楚,所以这里不做详细描述,只是阐述一下架构设计思考的过程。
负载均衡(Load Balance)
指将负载相对均匀地分摊到多个操作单元上执行。负载均衡方面一般分为硬件负载F5和软件负载nginx,阿里云也有推出相应的负载均衡产品。
消息中间件
中间件是介于应用系统和系统软件之间的一类软件,它使用系统软件所提供的基础服务(功能),衔接网络上应用系统的各个部分或不同的应用,能够达到资源共享、功能共享的目的。平时我们研发过程中会涉及各方面的中间件,如下简单列举了几类。
常用消息中间件:RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ等。如下是常用的四种消息中间件的特性对比:

数据库中间件
处于底层数据库和用户应用系统之间,主要用于屏蔽异构数据库的底层细节的中间件。是客户端与后台的数据库之间进行通信的桥梁。
数据库中间件有以下几种:
- 分布式数据库分表分库
- 数据增量订阅与消费
- 数据库同步(全量、增量、跨机房、复制)
- 跨数据库(数据源)迁移
整个产品族图如下:
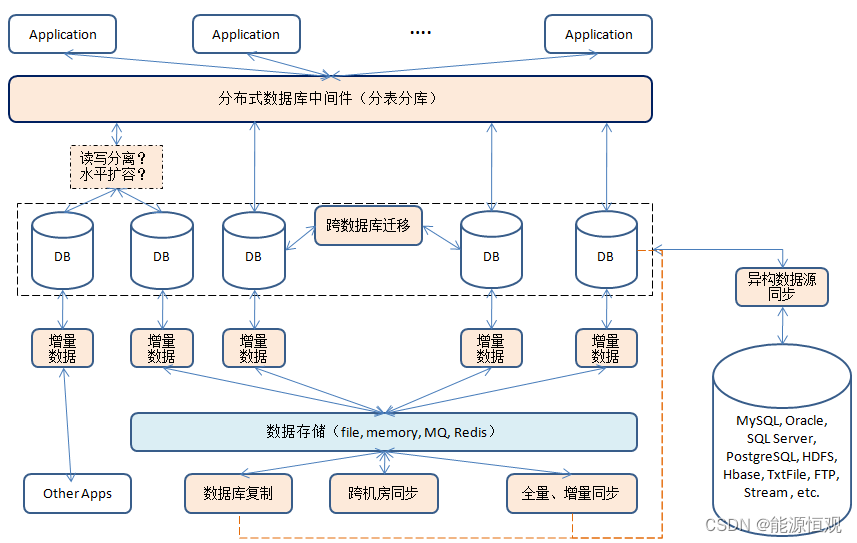
- 最上层的是分布式数据库分表分库中间件,负责和上层应用打交道,对应用可表现为一个独立的数据库,而屏蔽底层复杂的系统细节。分布式数据库中间件除了基本的分表分库功能,还具备读写分离、水平扩容等功能。常见的产品:Apache ShardingSphere,Cobar, MyCAT, TDDL, DRDS, DDB等
- 增量数据订阅和消费,用户对数据库操作,比如DML, DCL, DDL等,这些操作会产生增量数据,下层应用可以通过监测这些增量数据进行相应的处理。典型代表Canal,根据MySQL的binlog实现。也有针对Oracle(redolog)的增量数据订阅与消费的中间件。常见的产品:Canal, Erosa
- 数据库同步中间件涉及数据库之间的同步操作,可以实现跨(同)机房同步以及异地容灾备份、分流等功能。可以涉及多种数据库,处理之后的数据也可以以多种形式存储。常见的产品:Otter, JingoBus, DRC
- 数据库与数据库之间会有数据迁移(同步)的动作,同款数据同步原理比较简单,比如MySQL主备同步,只要在数据库层进行相应的配置既可,但是跨数据库同步就比较复杂了,比如Oracle->MySQL. 数据迁移一般包括三个步骤:全量复制,将原数据库的数据全量迁移到新数据库,在这迁移的过程中也会有新的数据产生;增量同步,对新产生的数据进行同步,并持续一段时间以保证数据同步;原库停写,切换新库。将“跨数据库”这个含义扩大一下——“跨数据源”,比如HDFS, HBase, FTP等都可以相互同步。常见的产品:yugong, DataX
数据存储方案
目前数据库可分为3大类:关系型数据库、NoSQL数据库和NewSQL数据库。
关系型数据库是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。关系型数据库应该是我们使用的最普遍的,常用的有Oracle、SQL Server、MySQL、PostgreSQL、DB2等
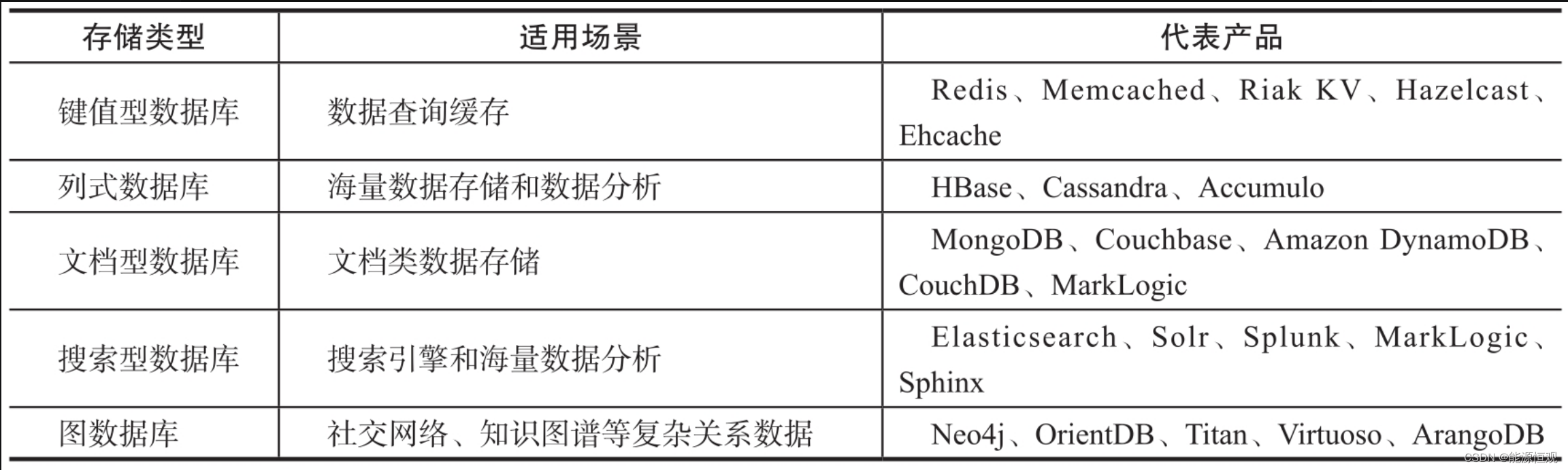
NoSQL的全称是Not Only SQL,泛指非关系型数据库,是对关系型数据库的一种补充。根据特性和适用场景,NoSQL数据库可以进一步细分为键值型数据库、列式数据库、文档型数据库、搜索型数据库、图数据库等类型,常见的NoSQL数据库如下表所示:
NewSQL是对各种新的可扩展、高性能数据库的简称。
一般来讲我这边选用存储方案思路有两个:一是依托于项目说明书进行选型;二是基于自身和团队的技术栈选型。这两个思路是贯穿我整个项目架构设计过程的。阅读项目说明书我们根据项目情况来进行技术栈初定,之后经过团队讨论得出最终方案。
安全方案
这里关注的是系统落地之后如何确保系统安全运行和快速问题定位和恢复,这里我们要设计服务器、应用系统、数据库等账号和密码安全;备份和恢复(日志,应用程序,数据)、服务器重新开机自启方案。
运维方案
这一块也是很重要的,项目方案设计初期就需要考虑,比如监控告警,链路追踪,业务补偿、CI/CD方案。如果项目是从0到1的设计,那么这些也是需要前期准备好,方便项目研发和今后上线运营维护,从而确保项目稳定性和故障及时修复。这里还需要提一个预案设计,所谓预案是指根据评估分析或经验,针对潜在的突发事件的类别和影响程度而事先制定的应急处置方案。在运维方案这一步也需要设计好应急处理方案,好在故障出现之后能够及时修复服务减小服务宕机的影响。
总结:
编写这篇文章是为了记录自己在架构设计过程中的思考路线,文章个别图片或者描述应用了其他人的资源,主要还是为了描述清楚文章内容。文章首先介绍了什么是架构设计以及我个人的理解,之后开始描述架构设计过程中各方面的思考,从服务器的方案到架构技术选型方案都有讲到。另外还有系统设计方面没有提及,系统设计过程中还需要考虑微服务拆分方案,各微服务之间系统的限流、降级、熔断、链路追踪、幂等以及安全认证等方面,然后就是存储方案定下来之后要考虑数据库设计,还有关于缓存方面的设计本文没有提及,后续文章在做补充。总归一句话项目整体架构设计完成之后,还需要进行系统架构设计!




![[Linux] MySQL数据库之索引](https://img-blog.csdnimg.cn/direct/4bca566b31bd4c2c9b3ae5bea00cceab.png)