目录
- 一、简介
- 二、实现单词统计
- 数据准备
- 编程
- Map
- Reduce
- Job
- 三、运行
- 四、结果
一、简介
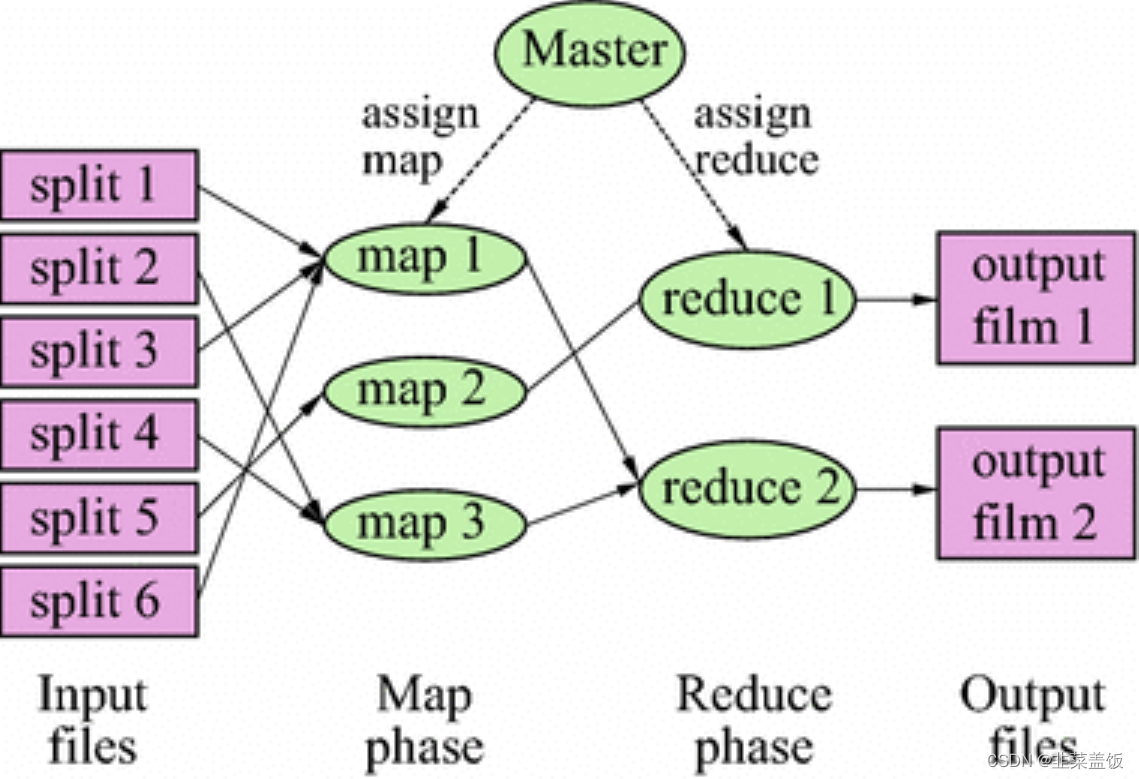
Hadoop MapReduce 是一个编程框架,它可以轻松地编写应用程序,以可靠的、容错的方式处理大量的数据(数千个节点)。
正如其名,MapReduce 的工作模式主要分为 Map 阶段和 Reduce 阶段。
一个 MapReduce 任务(Job)通常将输入的数据集分割成独立的块,这些块被 map 任务以完全并行的方式处理。框架对映射(map)的输出进行排序,然后将其输入到 reduce 任务中。通常,作业的输入和输出都存储在文件系统中。框架负责调度任务、监视任务并重新执行失败的任务。
在 Hadoop 集群中,计算节点一般和存储节点相同,即 MapReduce 框架和 Hadoop 分布式文件系统均运行在同一组节点上。这种配置允许框架有效地调度已经存在数据的节点上的作业,使得跨集群的带宽具有较高的聚合度,能够有效利用资源。
详细介绍参考:MapReduce理论与实践
二、实现单词统计
数据准备
数据准备wordcount.txt文件
hello,word,nihao
csust,hello
hello,csust,nihao
nihao,hello,word
上传数据
创建文件夹
hdfs dfs -mkdir /wordcount
如果出现以下问题:

可以通过以下命令解决
./bin/hdfs dfsadmin -safemode leave
将我们的数据上传至刚才创建的目录中
hdfs dfs -put -p wordcount.txt /wordcount
编程
Map
package com.csust.code;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*四个泛型解释:KEYIN :K1的类型VALUEIN: V1的类型KEYOUT: K2的类型VALUEOUT: V2的类型*/
public class WordCountMapper extends Mapper<LongWritable,Text, Text , LongWritable> {//map方法就是将K1和V1 转为 K2和V2/*参数:key : K1 行偏移量value : V1 每一行的文本数据context :表示上下文对象*//*如何将K1和V1 转为 K2和V2K1 V10 hello,world,hadoop15 hdfs,hive,hello---------------------------K2 V2hello 1world 1hdfs 1hadoop 1hello 1*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {Text text = new Text();LongWritable longWritable = new LongWritable();//1:将一行的文本数据进行拆分String[] split = value.toString().split(",");//2:遍历数组,组装 K2 和 V2for (String word : split) {//3:将K2和V2写入上下文text.set(word);longWritable.set(1);context.write(text, longWritable);}}
}Reduce
package com.csust.code;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
/*四个泛型解释:KEYIN: K2类型VALULEIN: V2类型KEYOUT: K3类型VALUEOUT:V3类型*/public class WordCountReducer extends Reducer<Text,LongWritable,Text,LongWritable> {//reduce方法作用: 将新的K2和V2转为 K3和V3 ,将K3和V3写入上下文中/*参数:key : 新K2values: 集合 新 V2context :表示上下文对象----------------------如何将新的K2和V2转为 K3和V3新 K2 V2hello <1,1,1>world <1,1>hadoop <1>------------------------K3 V3hello 3world 2hadoop 1*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {long count = 0;//1:遍历集合,将集合中的数字相加,得到 V3for (LongWritable value : values) {count += value.get();}//2:将K3和V3写入上下文中context.write(key, new LongWritable(count));}
}
Job
package com.csust.code;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;import java.net.URI;public class JobMain extends Configured implements Tool {//该方法用于指定一个job任务public int run(String[] args) throws Exception {//1:创建一个job任务对象Job job = Job.getInstance(super.getConf(), "wordcount");//如果打包运行出错,则需要加该配置job.setJarByClass(JobMain.class);//2:配置job任务对象(八个步骤)//第一步:指定文件的读取方式和读取路径job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job, new Path("hdfs://master:9000/wordcount"));//TextInputFormat.addInputPath(job, new Path("file:///D:\\mapreduce\\input"));//第二步:指定Map阶段的处理方式和数据类型job.setMapperClass(WordCountMapper.class);//设置Map阶段K2的类型job.setMapOutputKeyClass(Text.class);//设置Map阶段V2的类型job.setMapOutputValueClass(LongWritable.class);//第三,四,五,六 采用默认的方式//第七步:指定Reduce阶段的处理方式和数据类型job.setReducerClass(WordCountReducer.class);//设置K3的类型job.setOutputKeyClass(Text.class);//设置V3的类型job.setOutputValueClass(LongWritable.class);//第八步: 设置输出类型job.setOutputFormatClass(TextOutputFormat.class);//设置输出的路径Path path = new Path("hdfs://master:9000/wordcount_out");TextOutputFormat.setOutputPath(job, path);//TextOutputFormat.setOutputPath(job, new Path("file:///D:\\mapreduce\\output"));//获取FileSystemFileSystem fileSystem = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());//判断目录是否存在boolean bl2 = fileSystem.exists(path);if(bl2){//删除目标目录fileSystem.delete(path, true);}//等待任务结束boolean bl = job.waitForCompletion(true);return bl ? 0:1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();//启动job任务int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}
}三、运行
我们将项目打成jar包,上传至服务器

使用以下命令运行文件
hadoop jar mapreduce-1.0-SNAPSHOT.jar com.csust.code.JobMain
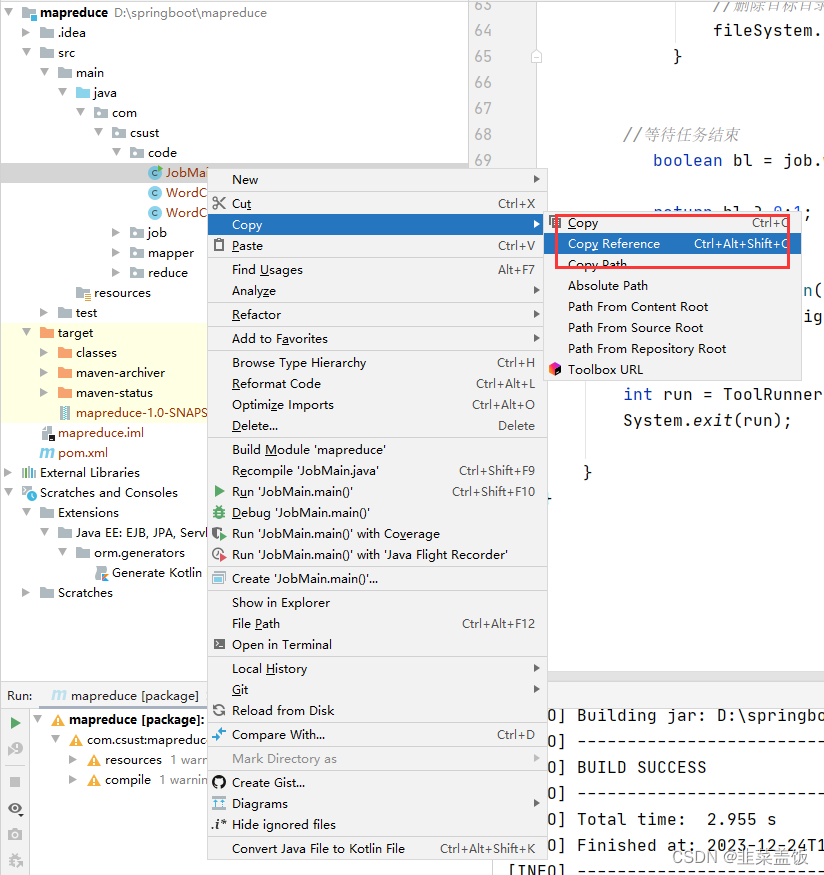
com.csust.code.JobMain获取方式如下:
四、结果