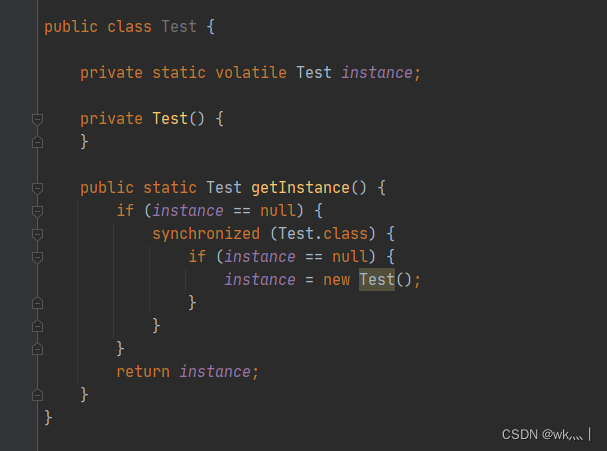
RTMPose
- 1. 人体姿态估计简介
- 2. RTMPose
- 2.1 网络结构
- 2.2 基于SimCC的优化路线
- 2.2.1 SimCC:
- 2.2.2 RTMPose
1. 人体姿态估计简介
- 多人姿态估计框架包括5个方面:
- paradigm:范式
- top-down:
- 用于人数不多于6人的场景
- 使用现成的检测器提供边界框,然后将人体裁剪为统一的尺度进行姿势估计
- 人体检测器和位姿估计器可输入较小的分辨率
- bottom-up:
- 自下而上的范式被认为适合人群场景,因为随着人数的增加,计算成本保持稳定;
- 通常需要较大的输入分辨率来处理不同的人的尺度,这使得协调准确性和推理速度变得具有挑战性
- top-down:
- backbone network:骨干网络
- localization method:定位算法
- 坐标回归(coordinate regression)
- 热图回归(heatmap regression)
- 坐标分类(coordinate classification)
- 子像素箱分类(将关键点预测看作为分别针对水平和垂直坐标的子像素箱的分类)
- 代表算法:SimCC
- 摆脱了对高分辨率热图的依赖,因此可以实现非常紧凑的架构,既不需要高分辨率中间表示,也不需要昂贵的上采样层
- 展平最终的特征图进行分类,不需要全局池化,从而避免了空间信息的丢失
- 通过亚像素尺度的坐标分类可以有效缓解量化误差,无需额外的优化后处理
- training strategy:训练策略
- deployment:部署推理
- paradigm:范式
2. RTMPose
2.1 网络结构
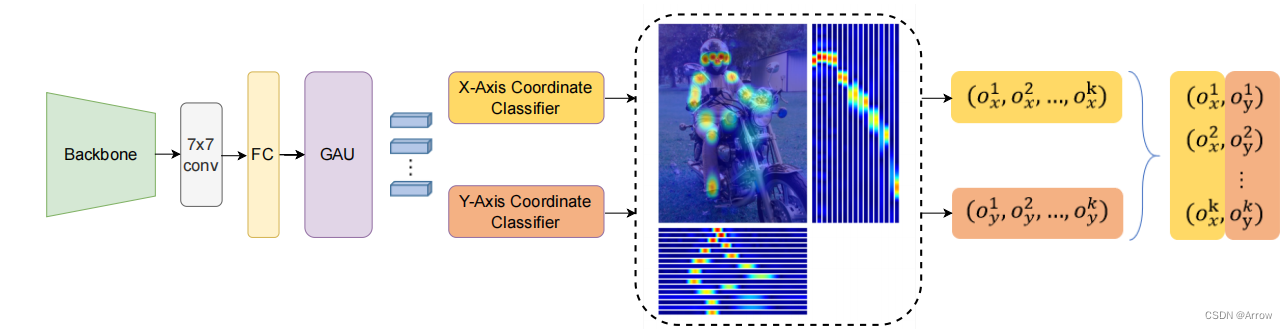
- GAU:Gated Attention Unit (门控注意力单元)
- RTMPose的整体架构包含:
- 骨干网络
- 一个卷积层
- 一个全连接层
- 一个用于细化K个关键点表示的门控注意力单元
- 将二维姿态估计视为x轴和y轴坐标的两个分类任务,以预测关键点的水平和垂直位置
2.2 基于SimCC的优化路线
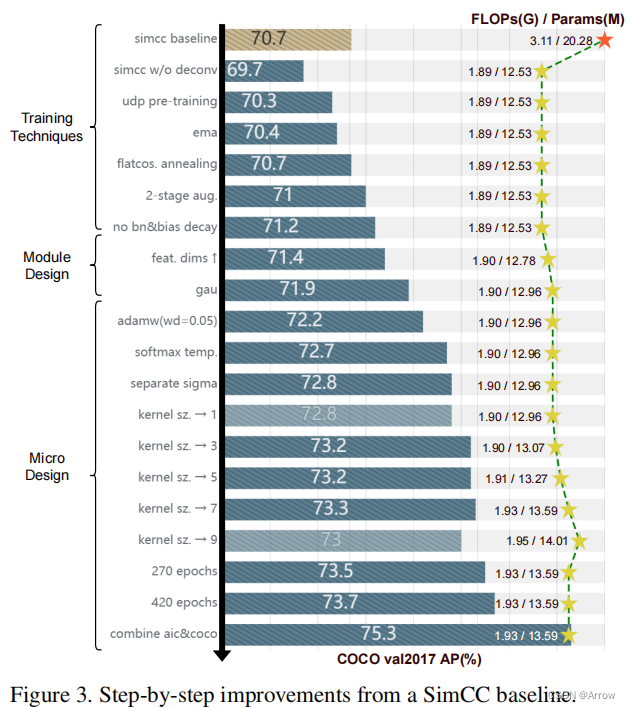
2.2.1 SimCC:
- 核心思想:将水平轴和垂直轴划分为等宽编号的 bin,并将连续坐标离散化为整数 bin 标签。 然后训练模型来预测关键点所在的 bin。 通过使用大量的 bin,可以将量化误差降低到子像素级别。
- 结构简单:由于这种新颖的公式,SimCC 具有非常简单的结构,使用 1 × 1 卷积层将主干提取的特征转换为矢量化关键点表示,并使用两个全连接层分别执行分类
- 平滑策略:受传统分类任务中标签平滑的启发[53],SimCC提出了一种高斯标签平滑策略,用以ground-truth bin为中心的高斯分布式软标签代替one-hot标签,该策略在模型训练中融合了归纳偏差,带来了 关于显着的性能改进。
2.2.2 RTMPose
- 基于SimCC,做了以下改进 (SimCC*)
- 删除了上采样层
- 使用CSPNext-m 替换 ResNet-50