IO多路复用
在以前,传统的网络编程是多线程模型,一个线程单独处理一个请求。
然而,线程是很昂贵的资源:
- 线程的创建和销毁成本很高,linux的线程实际上是特殊的进程;因此通常会使用线程池来减少线程创建和销毁的开销
- 线程本身占用较大的内存,如果并发比较高,那么光是线程本身占用的内存就很大了
- 线程上下文切换的成本也比较高,如果频繁切换,可能cpu用于处理线程切换的时间会大于业务执行时间
- 容易导致系统负载升高
因此,当面对海量连接的时候,传统的多线程模式就无能为力了。
而且:
- 处理请求的很大比重时间,线程都是在等待网络io,线程很多时候都是在等待io
- 在推送服务场景下,有海量连接,但是大多数时候只有少数连接是活跃的
这时候,我们就想,能不能有一种机制,可不可以让多个连接复用一个线程?就像cpu的分时复用一样。
答案肯定是可以的,这就是IO多路复用。要能够实现IO多路复用,需要:
- 非阻塞IO。传统的阻塞IO,当需要等待IO时,会阻塞线程,这还复用个屁?
- 需要有一个poller,能够轮询连接的io事件。比如当需要往一个连接写入内容,这个连接当前缓冲区是满的,无法写入,我们希望当它的缓存区空闲的时候能够收到通知,从而完成写入
对于非阻塞io,我们可以在accept连接的时候指定SOCK_NONBLOCK标志,或者在一些低版本的linux内核上,通过fcntl系统调用来设置。
而poller,linux提供了select、poll和epoll三种系统接口。本篇文章的主角是epoll。
首先来看select接口:
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);
An fd_set is a fixed size buffer. The Linux kernel allows fd_set of arbitrary size, determining the length of the sets to be checked from the value of nfds. However, the glibc implementation make the fd_set a fixed-size type is fixed in size, with size defined as 1024.
Three independent sets of file descriptors are watched. The file descriptors listed in readfds will be watched to see if characters become available for reading (more precisely, to see if a read will not block; in particular, a file descriptor is also ready on end-of-file). The file descriptors in writefds will be watched to see if space is available for write (though a large write may still block). The file descriptors in exceptfds will be watched for exceptional conditions.
The timeout argument specifies the interval that select() should block waiting for a file descriptor to become ready. If both fields of the timeval structure are zero, then select() returns immediately. (This is useful for polling.) If timeout is NULL (no timeout), select() can block indefinitely.
select具有如下几个缺陷:
- 如果一个fd需要同时监听readab和writable事件,那么需要同时加入到readfds和writefds列表中;
- 每次调用select,都需要将要监听的fd列表从用户空间传到内核空间,内核每次都需要COPY FROM USER,而往往fd列表是固定的内容;
- glibc的实现中,限制了fd_set的大小固定为1024,因此当需要监听的fd列表超过了这个大小,就无能为力了;
poll接口相对select接口有所改进:
struct pollfd {int fd; /* file descriptor */short events; /* requested events */short revents; /* returned events */
};// fds is a pollfd array
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
首先,poll使用结构体pollfd来描述需要监听的文件,并且可以通过设置pollfd#events来描述感兴趣的事件,同时当返回时,可以通过pollfd#revents来获取就绪的事件类型。这样就不需要像select接口分别指定三种类型的文件描述符集合了,而且事件类型也更加丰富。而且poll接口对于fds数组的大小也没有限制。
但是,每次调用poll,依然需要传入感兴趣的fd列表。
也正是因为poll的不足,才有了后来epoll的出现。
接下来简单看一下epoll的接口:
// 创建一个epoll实例
int epoll_create(int size);// 往一个epoll实例中添加/移除/修改对fd的事件监听
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);// 等待就绪事件
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
光从接口就可以看到epoll的强大。select和poll才只有一个接口,而epoll自己就足足有3个啊!
epoll本身也是一个file,我们需要先调用epoll_create创建它,才能使用,该方法会在内核空间创建一个epoll实例,然后返回对应的fd。
既然epoll是一个file,那么当不再使用的时候,需要被close掉,就像我们close一个打开的文件一样。
当我们通过epoll_create创建一个epoll实例,然后通过epoll_ctl来添加,移除或者修改对文件的就绪事件的监听。比如,当一个连接到达时,我们将其加入epoll,并监听其EPOLLIN/EPOLLOUT/EPOLLRDHUP事件。然后可以多次调用epoll_wait方法来轮询是否有就绪事件,而不用重新加入;当接收到EPOLLRDHUP事件时,移除对该文件的监听,并将其关闭。
epoll也可以被别的epoll轮询!!!
接下来我们基于linux kernel 5 的代码看一下epoll的实现。
epoll实现
epoll的结构以及创建
我们首先来看一下epoll的创建过程。
在fs/eventpoll.c文件下,可以看到epoll_create系统调用的定义,
SYSCALL_DEFINE1(epoll_create, int, size)
{if (size <= 0)return -EINVAL;return do_epoll_create(0);
}
SYSCALL_DEFINEN是一系列用于定义系统调用的宏,N表示系统调用的参数个数。因为epoll_create只有一个参数,因此使用的是SYSCALL_DEFINE1。
我们可以看到,如果传入的size小于或者等于0,则会返回EINVAL,表示参数错误。在早期的版本中,epoll是使用哈希表来管理注册的文件列表,需要传入一个size参数;但是现在的版本已经换做红黑树了,该参数已经没有具体的意义了,但是为了兼容性还是保留了下来,使用时传入一个任意大于0的数就好了。
接下来,我们看一下do_epoll_create的实现,该方法才是真正干活的主:
static int do_epoll_create(int flags)
{int error, fd;struct eventpoll *ep = NULL; // eventpoll是epoll实例struct file *file; // 前面说过epoll实例本身也是一个file// flags只支持设置EPOLL_CLEXECif (flags & ~EPOLL_CLOEXEC)return -EINVAL;// 分配一个epoll实例error = ep_alloc(&ep);if (error < 0)return error;// 分配一个未使用的文件描述符fdfd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));if (fd < 0) {error = fd;goto out_free_ep;}// 获取一个具有匿名inode的file,并设置file->f_op为eventpoll_fops// 同时设置file->private_date为epfile = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,O_RDWR | (flags & O_CLOEXEC));if (IS_ERR(file)) {error = PTR_ERR(file);goto out_free_fd;}// 管理epoll实例和fileep->file = file;// 设置fd对应的filefd_install(fd, file);return fd;out_free_fd:// 创建失败,释放fdput_unused_fd(fd);
out_free_ep:// 创建失败,释放内存ep_free(ep);return error;
}
do_epoll_create接收一个flags参数,如果我们使用epoll_create来创建,默认是没有设置任何flags的。但是内核后面又添加了epoll_create1系统调用,使用该系统调用是可以设置flags的,具体可以查看man手册。
上面代码已经加了具体的注释了。在linux中正所谓一切皆文件,可以看到当我们创建epoll实例的时候,同时会创建一个file。其实linux的文件系统正是面向对象的思想,我们可以把file看成是一个统一的接口,具体的实现只需要把对应的方法实现注册到file->f_op中就好了,而且file->private_data保存了实际实现的指针。那些支持接口的语言,背后的实现无外乎也就是这样。
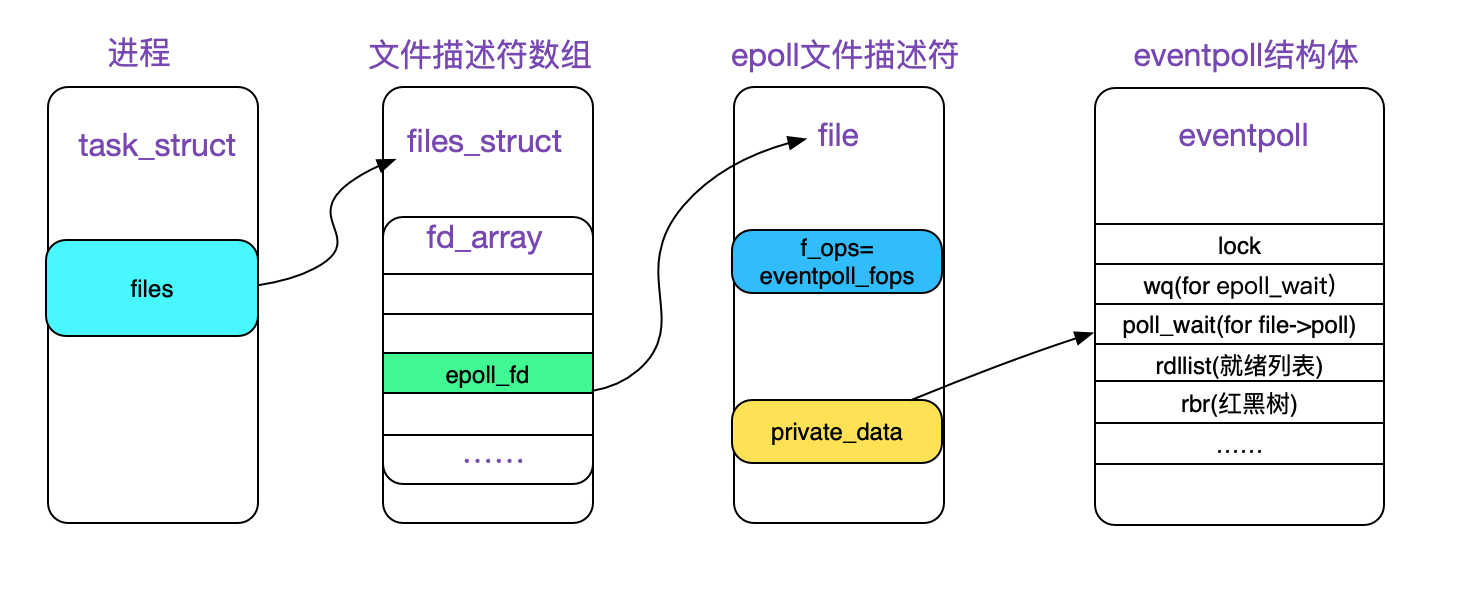
epoll实例
既然是创建epoll实例,那我们是不是应该看一下这个epoll实例到底是什么?
struct eventpoll {// 资源保护锁struct mutex mtx;// 阻塞在epoll_wait的等待队列wait_queue_head_t wq; // epoll实例本身实现了file->f_op->poll方法,对应的poll等待队列// 比如epoll实例本身也可以被添加到其他epoll实例中wait_queue_head_t poll_wait;// 就绪队列,保存已经就绪的事件struct list_head rdllist;// 用于保护rdllist和ovflist的锁rwlock_t lock;// 用于存储添加到epoll实例的fd的红黑树struct rb_root_cached rbr; // 当正在转移就绪队列中的事件到用户空间时,这段时期就绪的事件会被暂时加入该队列,等待转移结束再添加到rdllist。struct epitem *ovflist; struct wakeup_source *ws;// 创建epoll实例的用户struct user_struct *user;// epoll本身也是一个文件struct file *file;/* used to optimize loop detection check */int visited;struct list_head visited_list_link;#ifdef CONFIG_NET_RX_BUSY_POLL/* used to track busy poll napi_id */unsigned int napi_id;
#endif
};
epoll实例使用红黑树来管理注册的需要监听的fd,关于红黑树的介绍可以参考该篇,这里就不介绍了。
每个被添加到epoll实例的fd对应一个epitem:
struct epitem {union {// 红黑树节点,linux内核中红黑树被广泛使用,因此有必要实现成通用结构,通过rb_node连接到rb-tree// 当需要访问具体结构体时,通过简单的指针运算以及类型转换就可以了struct rb_node rbn;/* Used to free the struct epitem */struct rcu_head rcu;};// 用于添加到epoll实例的就绪队列的链表节点struct list_head rdllink; // 在将就绪列表中的事件转移到用户空间期间,新的就绪事件会先加入到epoll的ovflist;为什么不复用rdllink字段呢?因为同一个fd,可能还在就绪队列中,但是又有了新的就绪事件了,这时候它既在就绪队列中,也在ovflist中struct epitem *next; // 该epitem关联的fd和file信息,用于红黑树中的比较;我们知道,红黑树是二叉搜索树,在查找的时候,是需要比较大小的struct epoll_filefd ffd; // Number of active wait queue attached to poll operations int nwait;// List containing poll wait queuesstruct list_head pwqlist;// 该epitem注册的epoll实例struct eventpoll *ep; // used to link this item to the "struct file" items liststruct list_head fllink;// wakeup_source used when EPOLLWAKEUP is set struct wakeup_source __rcu *ws;// 该结构体保存epitem对应的fd和感兴趣的事件列表struct epoll_event event;
};
当一个fd被添加到epoll实例时,epoll实例会调用对应file的poll方法,poll方法有两个作用:
- 设置callback,当文件有新的就绪事件产生时,调用该callback;
- 返回文件当前的就绪事件;
而当我们从epoll实例移除一个fd时,需要从file中移除注册的callback。
注册callback,实际上是添加一个eppoll_entry到file的等待队列:
// Wait structure used by the poll hooks
struct eppoll_entry {// 用于链接到epitem的pwdliststruct list_head llink; // 对应的epitemstruct epitem *base;// 保存回调函数wait_queue_entry_t wait; // The wait queue head that linked the "wait" wait queue itemwait_queue_head_t *whead;
};
eppoll_entry使用wait链接到目标文件的等待队列,这样当目标文件有就绪事件到来时,就可以调用wait中的回调函数了;而whead保存等待队列的head,使用llink链接到epitem的pwdlist队列,这样当从epoll删除目标文件时,可以遍历epitem的pwdlist队列,然后通过whead删除添加到file中的回调。
接下来看一下 epoll_filefd以及在搜索红黑树时,是如果通过该结构体比较大小的:
struct epoll_filefd {struct file *file; // 对应fileint fd; // 对应的fd
} __packed; // _packed设置内存对齐为1/* Compare RB tree keys */
static inline int ep_cmp_ffd(struct epoll_filefd *p1,struct epoll_filefd *p2)
{return (p1->file > p2->file ? +1:(p1->file < p2->file ? -1 : p1->fd - p2->fd));
}
可以看到,比较的逻辑是:
- 首先比较file的地址
- 如果属于同一个file,则比较fd;比如使用dup系统调用,就可以产生两个fd指向同一个file
epoll_ctl的实现
我们要添加,修改或者移除对目标文件的监听,都是通过epoll_ctl系统调用实现的,接下来看一下该方法的实现。
首先,我们看一下syscall的定义:
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,struct epoll_event __user *, event)
{int error;int full_check = 0;struct fd f, tf;struct eventpoll *ep;struct epitem *epi;struct epoll_event epds;struct eventpoll *tep = NULL;error = -EFAULT;// ep_op_has_event:对应操作是否需要从用户空间拷贝eventif (ep_op_has_event(op) &&// 拷贝用户空间的event到epds中copy_from_user(&epds, event, sizeof(struct epoll_event))) goto error_return;error = -EBADF;// 获取对应的epoll实例f = fdget(epfd); if (!f.file) goto error_return;// 获取目标文件tf = fdget(fd); if (!tf.file)goto error_fput;error = -EPERM;// 方法定义在`linux/poll.h`中,检查目标文件是否实现了poll方法,只有实现了poll方法才可以添加到epoll中监听if (!file_can_poll(tf.file))goto error_tgt_fput;/* Check if EPOLLWAKEUP is allowed */if (ep_op_has_event(op))ep_take_care_of_epollwakeup(&epds);error = -EINVAL;// 检查是否是epoll实例,并且epoll不能监听自己if (f.file == tf.file || !is_file_epoll(f.file))goto error_tgt_fput;// 只有当op=EPOLL_CTL_ADD,才会加入到唤醒队列if (ep_op_has_event(op) && (epds.events & EPOLLEXCLUSIVE)) {// 如果目标文件是epoll,不允许设置EPOLLEXCLUSIVEif (op == EPOLL_CTL_MOD)goto error_tgt_fput;// 监听其他epoll时,也不允许设置EPOLLEXCLUSIVEif (op == EPOLL_CTL_ADD && (is_file_epoll(tf.file) ||// 有些flag不允许和EPOLLEXCLUSIVE同时使用(epds.events & ~EPOLLEXCLUSIVE_OK_BITS)))goto error_tgt_fput;}// 获取epoll实例,我们会将其保存到file的private_data中ep = f.file->private_data; mutex_lock_nested(&ep->mtx, 0);// 如果是添加新文件if (op == EPOLL_CTL_ADD) {// 如果目标文件也是一个epoll实例,那么有可能导致循环监听,需要执行循环检测if (!list_empty(&f.file->f_ep_links) || is_file_epoll(tf.file)) { full_check = 1;mutex_unlock(&ep->mtx);mutex_lock(&epmutex);if (is_file_epoll(tf.file)) {error = -ELOOP;if (ep_loop_check(ep, tf.file) != 0) {clear_tfile_check_list();goto error_tgt_fput;}} elselist_add(&tf.file->f_tfile_llink,&tfile_check_list);mutex_lock_nested(&ep->mtx, 0);if (is_file_epoll(tf.file)) {tep = tf.file->private_data;mutex_lock_nested(&tep->mtx, 1);}}}// 首先先到rb-tree查找,是否已经添加过该目标文件epi = ep_find(ep, tf.file, fd);error = -EINVAL;switch (op) {case EPOLL_CTL_ADD:// 添加目标文件// 如果没有添加过if (!epi) {// 默认接收EPOLLERR和EPOLLHUB事件epds.events |= EPOLLERR | EPOLLHUP; // 执行插入逻辑,包括插入rb-tree,设置callback等error = ep_insert(ep, &epds, tf.file, fd, full_check); } elseerror = -EEXIST;if (full_check)clear_tfile_check_list();break;case EPOLL_CTL_DEL:// 删除目标文件if (epi)// 目标文件存在,执行删除逻辑error = ep_remove(ep, epi); // 执行删除逻辑elseerror = -ENOENT;break;case EPOLL_CTL_MOD:if (epi) {// 如果添加的时候设置了EPOLLEXCLUSIVE,则不允许修改if (!(epi->event.events & EPOLLEXCLUSIVE)) {// 默认监听EPOLLERR和EPOLLHUP epds.events |= EPOLLERR | EPOLLHUP;// 执行更新error = ep_modify(ep, epi, &epds); }} elseerror = -ENOENT; break;}if (tep != NULL)mutex_unlock(&tep->mtx);mutex_unlock(&ep->mtx);// linux典型的错误处理,挺巧妙的
error_tgt_fput:if (full_check)mutex_unlock(&epmutex);fdput(tf);
error_fput:fdput(f);
error_return:return error;
}
具体逻辑在代码中已经注释了,我们可以看到,只有实现了poll方法才可以被添加到epoll中
添加监听文件
接下来看一下ep_insert的实现
// 在linux/poll.h中定义
typedef struct poll_table_struct {// 在poll方法中被调用,用于添加eppoll_entry到file的等待队列poll_queue_proc _qproc;// 监听的事件列表__poll_t _key;
} poll_table;struct ep_pqueue {poll_table pt;struct epitem *epi;
};static int ep_insert(struct eventpoll *ep, const struct epoll_event *event,struct file *tfile, int fd, int full_check)
{int error, pwake = 0;__poll_t revents;long user_watches;struct epitem *epi;struct ep_pqueue epq;lockdep_assert_irqs_enabled();// 首先检查一下,是否达到用户最大允许监听的文件数量user_watches = atomic_long_read(&ep->user->epoll_watches);if (unlikely(user_watches >= max_user_watches))return -ENOSPC;// 从slab cache分配一个epitemif (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))return -ENOMEM;// 初始化为空指针INIT_LIST_HEAD(&epi->rdllink);INIT_LIST_HEAD(&epi->fllink);INIT_LIST_HEAD(&epi->pwqlist);// 设置epepi->ep = ep; // 设置ffd字段ep_set_ffd(&epi->ffd, tfile, fd);// 设置监听的事件epi->event = *event;epi->nwait = 0;// next指针用于加入就绪列表epi->next = EP_UNACTIVE_PTR;if (epi->event.events & EPOLLWAKEUP) { error = ep_create_wakeup_source(epi);if (error)goto error_create_wakeup_source;} else {RCU_INIT_POINTER(epi->ws, NULL);}// 初始化ep_pqueueepq.epi = epi;// 设置pt._qproc=ep_ptable_queue_proc,pt._key=~0init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);// 调用file对应的poll方法,该方法会返回当前正在监听的已经就绪的事件列表revents = ep_item_poll(epi, &epq.pt, 1);error = -ENOMEM;if (epi->nwait < 0)goto error_unregister;spin_lock(&tfile->f_lock);// 添加epitem到file的f_ep_links尾部list_add_tail_rcu(&epi->fllink, &tfile->f_ep_links);spin_unlock(&tfile->f_lock);// 插入红黑树ep_rbtree_insert(ep, epi);/* now check if we've created too many backpaths */error = -EINVAL;if (full_check && reverse_path_check())goto error_remove_epi;/* We have to drop the new item inside our item list to keep track of it */write_lock_irq(&ep->lock);/* record NAPI ID of new item if present */ep_set_busy_poll_napi_id(epi);// 有就绪事件并且还没有添加到就绪列表if (revents && !ep_is_linked(epi)) {// 添加到就绪列表表尾list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);// 唤醒等待epoll_wait的线程if (waitqueue_active(&ep->wq))wake_up(&ep->wq);// 如果当前epoll实例被添加到别的epoll中,需要通知if (waitqueue_active(&ep->poll_wait))// 这里不能直接通知,会产生死锁pwake++;}write_unlock_irq(&ep->lock);atomic_long_inc(&ep->user->epoll_watches);// 在这里通知当前epoll的监听者if (pwake)ep_poll_safewake(&ep->poll_wait);// 添加成功,正常返回return 0;// 错误处理
error_remove_epi:spin_lock(&tfile->f_lock);list_del_rcu(&epi->fllink);spin_unlock(&tfile->f_lock);rb_erase_cached(&epi->rbn, &ep->rbr);error_unregister:ep_unregister_pollwait(ep, epi);write_lock_irq(&ep->lock);if (ep_is_linked(epi))list_del_init(&epi->rdllink);write_unlock_irq(&ep->lock);wakeup_source_unregister(ep_wakeup_source(epi));error_create_wakeup_source:kmem_cache_free(epi_cache, epi);return error;
}
接下来看一下ep_item_poll方法,该方法会调用file对应的poll方法:
// 该方法返回正在监听的已经就绪的事件列表
static __poll_t ep_item_poll(const struct epitem *epi, poll_table *pt,int depth)
{struct eventpoll *ep;bool locked;// 设置poll_table的_keypt->_key = epi->event.events;// 如果目标文件不是epoll实例,走这个分支if (!is_file_epoll(epi->ffd.file))// vfs_poll方法,该方法会调用file的poll方法,并返回file当前所有的就绪事件列表// 我们只需要获取关心的事件列表,因此 & event.eventsreturn vfs_poll(epi->ffd.file, pt) & epi->event.events;// 目标文件是epoll实例ep = epi->ffd.file->private_data;// 添加到epoll实例的poll_wait链表poll_wait(epi->ffd.file, &ep->poll_wait, pt);locked = pt && (pt->_qproc == ep_ptable_queue_proc);return ep_scan_ready_list(epi->ffd.file->private_data,ep_read_events_proc, &depth, depth,locked) & epi->event.events;
}
可以看到,会调用vfs_poll方法,来设置callback,而不同的文件实现有不同的poll方法,这里我们看一下tcp的sock的poll实现:
// 定义在 linux/poll.h 中
static inline __poll_t vfs_poll(struct file *file, struct poll_table_struct *pt)
{if (unlikely(!file->f_op->poll))return DEFAULT_POLLMASK;// 调用file的poll方法return file->f_op->poll(file, pt);
}__poll_t tcp_poll(struct file *file, struct socket *sock, poll_table *wait)
{__poll_t mask;// 获取network sockstruct sock *sk = sock->sk;const struct tcp_sock *tp = tcp_sk(sk);int state;// 该方法回调wait._qproc,设置callbacksock_poll_wait(file, sock, wait);state = inet_sk_state_load(sk);if (state == TCP_LISTEN)return inet_csk_listen_poll(sk);mask = 0;// ... 获取当前所有就绪事件列表return mask;
}// 该方法定义在 linux/net/sock.h
static inline void sock_poll_wait(struct file *filp, struct socket *sock,poll_table *p)
{// p不为空且p._qproc不为空,具体实现在linux/poll.h中if (!poll_does_not_wait(p)) { // 调用p._qproc,具体实现在linux/poll.h中poll_wait(filp, &sock->wq.wait, p);smp_mb();}
}
可以看到,file的poll方法主要有两个作用:
- 如果
poll_table和poll_table._qproc不为空,则调用该方法,设置监听回调 - 返回file当前所有已经就绪的事件
根据前面的分析,我们知道poll_table._qproc实际上就是fs/eventpoll.c中的ep_ptable_queue_proc方法:
typedef struct wait_queue_entry wait_queue_entry_t;struct wait_queue_entry {unsigned int flags;void *private;wait_queue_func_t func; // 回调函数struct list_head entry; // 用于链接到file的等待队列
};static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,poll_table *pt)
{// poll_table保存在ep_pqueue,通过指针运算就可以获取到ep_pqueue中对应的epitemstruct epitem *epi = ep_item_from_epqueue(pt); struct eppoll_entry *pwq;// 从slab cache分配pwqif (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {// 设置回调函数到pwq->wait->wait_queue_func_tinit_waitqueue_func_entry(&pwq->wait, ep_poll_callback); pwq->whead = whead;pwq->base = epi;// 如果设置了EPOLLEXCLUSIVEif (epi->event.events & EPOLLEXCLUSIVE)// 方法声明在linux/wait.h中, 链接pwd->wait到whead,同时会设置EXCLUSIVE标志位add_wait_queue_exclusive(whead, &pwq->wait); elseadd_wait_queue(whead, &pwq->wait);// 将pwd添加到epi->pwdlist中list_add_tail(&pwq->llink, &epi->pwqlist); epi->nwait++;} else {/* We have to signal that an error occurred */epi->nwait = -1;}
}
可以看到添加的逻辑,主要就是调用file的poll方法,设置添加回调函数到file的等待队列,并且如果已经有正在监听的就绪事件,则唤醒正在等待队列中的线程。
修改监听文件
接下来看一下修改的逻辑:
static int ep_modify(struct eventpoll *ep, struct epitem *epi,const struct epoll_event *event)
{int pwake = 0;poll_table pt;lockdep_assert_irqs_enabled();// 这里将poll_table._qproc初始化为空指针,// 这样在调用file的poll方法时,只会返回就绪事件列表,而不会设置回调函数init_poll_funcptr(&pt, NULL);// 设置新的事件掩码epi->event.events = event->events; // 设置新的data,用户空间可以使用event.data来保存连接相关的上下文信息epi->event.data = event->data;if (epi->event.events & EPOLLWAKEUP) {if (!ep_has_wakeup_source(epi))ep_create_wakeup_source(epi);} else if (ep_has_wakeup_source(epi)) {ep_destroy_wakeup_source(epi);}smp_mb();// 因为pt._qproc==NULL,只会检查就绪事件列表if (ep_item_poll(epi, &pt, 1)) {write_lock_irq(&ep->lock);if (!ep_is_linked(epi)) { // 还不在就绪队列中list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);/* Notify waiting tasks that events are available */if (waitqueue_active(&ep->wq))wake_up(&ep->wq);if (waitqueue_active(&ep->poll_wait))pwake++;}write_unlock_irq(&ep->lock);}/* We have to call this outside the lock */if (pwake)ep_poll_safewake(&ep->poll_wait);return 0;
}
可以看到,修改的逻辑,就是更新epitem中evnet的相关信息,然后检查一下是否有就绪事件,因为有可能存在之前没有监听的就绪事件。
删除监听文件
接下来看一下删除的逻辑:
static int ep_remove(struct eventpoll *ep, struct epitem *epi)
{struct file *file = epi->ffd.file;lockdep_assert_irqs_enabled();// Removes poll wait queue hooks.ep_unregister_pollwait(ep, epi);// Remove the current item from the list of epoll hooksspin_lock(&file->f_lock);list_del_rcu(&epi->fllink);spin_unlock(&file->f_lock);// 从红黑树删除rb_erase_cached(&epi->rbn, &ep->rbr);write_lock_irq(&ep->lock);if (ep_is_linked(epi))// 从就绪列表删除list_del_init(&epi->rdllink);write_unlock_irq(&ep->lock);wakeup_source_unregister(ep_wakeup_source(epi));call_rcu(&epi->rcu, epi_rcu_free);// 用户监听数量减1atomic_long_dec(&ep->user->epoll_watches);return 0;
}static void ep_unregister_pollwait(struct eventpoll *ep, struct epitem *epi)
{struct list_head *lsthead = &epi->pwqlist;struct eppoll_entry *pwq;// 遍历epi->pwdlistwhile (!list_empty(lsthead)) {// list_first_entry是一个宏pwq = list_first_entry(lsthead, struct eppoll_entry, llink);list_del(&pwq->llink);// 从等待回来移除hookep_remove_wait_queue(pwq);// 回收内存kmem_cache_free(pwq_cache, pwq);}
}
删除操作主要是做一些清除工作。
等待就绪事件
接下来看一下epoll_wait的实现:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,int, maxevents, int, timeout)
{// 调用do_epoll_waitreturn do_epoll_wait(epfd, events, maxevents, timeout);
}static int do_epoll_wait(int epfd, struct epoll_event __user *events,int maxevents, int timeout)
{int error;struct fd f;struct eventpoll *ep;if (maxevents <= 0 || maxevents > EP_MAX_EVENTS)return -EINVAL;// epoll_wait,需要将就绪事件列表拷贝到用户空间// 验证用户空间传过来的内存空间是否可写if (!access_ok(events, maxevents * sizeof(struct epoll_event)))return -EFAULT;// 根据epfd获取对应的filef = fdget(epfd);if (!f.file)return -EBADF;error = -EINVAL;// epll_wait的fd参数必须是epoll fileif (!is_file_epoll(f.file)) goto error_fput;ep = f.file->private_data; // 获取对应的epoll实例// 调用ep_pollerror = ep_poll(ep, events, maxevents, timeout); error_fput:fdput(f);return error;
}
可以看到,最后调用了ep_poll方法,接下来看一下该方法实现:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,int maxevents, long timeout)
{int res = 0, eavail, timed_out = 0;u64 slack = 0;bool waiter = false;wait_queue_entry_t wait;ktime_t expires, *to = NULL;lockdep_assert_irqs_enabled();if (timeout > 0) {// 设置过期时间struct timespec64 end_time = ep_set_mstimeout(timeout);slack = select_estimate_accuracy(&end_time);to = &expires;*to = timespec64_to_ktime(end_time);} else if (timeout == 0) {// 如果timeout为0,则epoll_wait不会阻塞,设置time_out为truetimed_out = 1;write_lock_irq(&ep->lock);// 获取就绪队列事件长度eavail = ep_events_available(ep); write_unlock_irq(&ep->lock);// 拷贝已经就绪的事件到用户空间,如果有的话goto send_events;}// 如果timeout小于0,则会阻塞直到有就绪事件到来fetch_events:// 如果没有就绪事件可以获取if (!ep_events_available(ep))// 如果没有定义CONFIG_NET_RX_BUSY_POLL宏,则该方法为空实现ep_busy_loop(ep, timed_out);eavail = ep_events_available(ep); if (eavail)// 如果已经有就绪事件了goto send_events;ep_reset_busy_poll_napi_id(ep);if (!waiter) { // 当前任务还没有加入epoll的等待队列// 加入ep的等待队列,如果有新的就绪事件到达,则会在ep_poll_callback唤醒当前任务waiter = true;init_waitqueue_entry(&wait, current);spin_lock_irq(&ep->wq.lock);__add_wait_queue_exclusive(&ep->wq, &wait);spin_unlock_irq(&ep->wq.lock);}// 等待就绪事件到达for (;;) {/*** PROCESS STATE CODES* R running or runnable (on run queue)* D uninterruptible sleep (usually IO)* S interruptible sleep (waiting for an event to complete)* Z defunct/zombie, terminated but not reaped by its parent* T stopped, either by a job control signal or because it is being traced*/// 设置任务状态为Sset_current_state(TASK_INTERRUPTIBLE); // 检查是否有 fatal_signalif (fatal_signal_pending(current)) { res = -EINTR;break;}// 检查就绪事件列表eavail = ep_events_available(ep); if (eavail)break;// 检查是否有signalif (signal_pending(current)) { res = -EINTR;break;}// sleep util timeout// 返回0则表示timeout// 由于当前任务状态设置为TASK_INTERRUPTIBLE,因此可能由于signal到来而被唤醒,比如在ep_poll_callback被唤醒if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) {// 由于timeout而唤醒,设置超时timed_out = 1;break;}}// 设置为RUNNING__set_current_state(TASK_RUNNING); send_events:// 如果由于signal退出等待,res为trueif (!res && eavail &&// ep_send_events遍历就绪队列,拷贝就绪事件到用户空间!(res = ep_send_events(ep, events, maxevents))// 如果还未超时,继续等待就绪事件到来&& !timed_out) // 还没有就绪事件,并且还未超时,等待就绪事件到来goto fetch_events; if (waiter) {spin_lock_irq(&ep->wq.lock);// 从epoll的等待队列移除__remove_wait_queue(&ep->wq, &wait); spin_unlock_irq(&ep->wq.lock);}return res;
}
接下来,我们看一下ep_send_events方法的实现:
// maxevents表示最多获取多少个event
static int ep_send_events(struct eventpoll *ep,struct epoll_event __user *events, int maxevents)
{struct ep_send_events_data esed;esed.maxevents = maxevents;esed.events = events;// 在ep_scan_ready_list方法中调用ep_send_events_procep_scan_ready_list(ep, ep_send_events_proc, &esed, 0, false); return esed.res;
}static __poll_t ep_scan_ready_list(struct eventpoll *ep,__poll_t (*sproc)(struct eventpoll *,struct list_head *, void *),void *priv, int depth, bool ep_locked)
{__poll_t res;struct epitem *epi, *nepi;LIST_HEAD(txlist);lockdep_assert_irqs_enabled();if (!ep_locked)mutex_lock_nested(&ep->mtx, depth);write_lock_irq(&ep->lock);// 将rdllist链表拼接到txlist,同时重新初始化rdllistlist_splice_init(&ep->rdllist, &txlist); // 设置ep->ovflist为NULL,后续新的就绪事件都将暂时加入到该列表中WRITE_ONCE(ep->ovflist, NULL); write_unlock_irq(&ep->lock);// 回调ep_send_events_proc方法res = (*sproc)(ep, &txlist, priv); write_lock_irq(&ep->lock);// 将ep->ovflist中的事件移动到rdllistfor (nepi = READ_ONCE(ep->ovflist); (epi = nepi) != NULL;nepi = epi->next, epi->next = EP_UNACTIVE_PTR) {if (!ep_is_linked(epi)) {// 如果还没有加入rdllistlist_add(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}}// 设置ep->ovflist为EP_UNACTIVE_PTR,后续的就绪事件将加入到rdllistWRITE_ONCE(ep->ovflist, EP_UNACTIVE_PTR); // 将txlist剩余的就绪事件重新加入ep->rdllistlist_splice(&txlist, &ep->rdllist); __pm_relax(ep->ws);write_unlock_irq(&ep->lock);if (!ep_locked)mutex_unlock(&ep->mtx);return res;
}
接下来看一下ep_send_events_proc方法,该方法拷贝就绪事件到用户空间:
static __poll_t ep_send_events_proc(struct eventpoll *ep, struct list_head *head,void *priv)
{struct ep_send_events_data *esed = priv;__poll_t revents;struct epitem *epi, *tmp;struct epoll_event __user *uevent = esed->events;struct wakeup_source *ws;poll_table pt;init_poll_funcptr(&pt, NULL);esed->res = 0;lockdep_assert_held(&ep->mtx);// 这是一个宏,本质上还是for循环,从头遍历head链表中的就绪事件list_for_each_entry_safe(epi, tmp, head, rdllink) {// 如果已经超过maxeventsif (esed->res >= esed->maxevents) break;ws = ep_wakeup_source(epi);if (ws) {if (ws->active)__pm_stay_awake(ep->ws);__pm_relax(ws);}// 从就绪队列删除对应事件list_del_init(&epi->rdllink);// 获取就绪事件列表,因为ep._proc==NULL,这里只会检查是否有关心的就绪事件revents = ep_item_poll(epi, &pt, 1); // 如果已经没有感兴趣的就绪事件了,跳过if (!revents)continue;// 拷贝到用户空间if (__put_user(revents, &uevent->events) ||__put_user(epi->event.data, &uevent->data)) {// 拷贝失败,重新加入就绪队列list_add(&epi->rdllink, head);ep_pm_stay_awake(epi);if (!esed->res)esed->res = -EFAULT;return 0;}esed->res++;uevent++;// 如果设置了EPLLONESHOTif (epi->event.events & EPOLLONESHOT) // 将events mask设置为EP_PRIVATE_BITS,不会再触发通知,但是并没有从epoll中删除epi->event.events &= EP_PRIVATE_BITS; else if (!(epi->event.events & EPOLLET)) { // 如果是水平触发模式// 重新加入rdllist就绪队列,下次epoll_wait会重新扫描对应文件是否有就绪事件// 当前遍历的就绪队列已经不是ep->rdllist,因此不会被重新扫描到list_add_tail(&epi->rdllink, &ep->rdllist);ep_pm_stay_awake(epi);}}return 0;
}
可以看到,epoll_wait返回有三种情况:
- 由于timeout大于或者等于0而超时返回
- 有signal产生
- 有就绪事件到来
epoll_wait会将就绪事件拷贝到用户空间,并且在拷贝之前会重新检查是否还存在就绪事件
如果使用水平触发模式,就绪事件在被拷贝到用户空间之后,会被重新加入到就绪队列中,这样如果用户没有消费完对应事件,就会一直获得该事件的通知。
如果设置了EPLLONESHOT,那么在被拷贝到用户空间之后,events将被设置为EP_PRIVATE_BITS,将不会再监听任何事件,并且没有被从epoll中移除,如果需要重新监听,需要使用epoll_modify。
wait queue hook
接下来看一下回调函数,当file有新的就绪事件时就会回调该方法:
static int ep_poll_callback(wait_queue_entry_t *wait, unsigned mode, int sync, void *key)
{int pwake = 0;// 通过wait获取对应的epitemstruct epitem *epi = ep_item_from_wait(wait);// 获取对应的epoll实例 struct eventpoll *ep = epi->ep; // 事件列表 __poll_t pollflags = key_to_poll(key); unsigned long flags;// 是否唤醒int ewake = 0;// 获取epoll的锁,防止与其他fd的竞争read_lock_irqsave(&ep->lock, flags);ep_set_busy_poll_napi_id(epi);// 可能设置了EPOLLONESHOT,处于disable状态,直接解锁退出if (!(epi->event.events & ~EP_PRIVATE_BITS))goto out_unlock;// 检查就绪的事件类型是否有感兴趣的事件if (pollflags && !(pollflags & epi->event.events))goto out_unlock;// 如果ovflist!=EP_UNACTIVE_PTR,说明当前正在转移readyList中的事件到用户空间// 在此期间到达的事件暂时加入到ovflistif (READ_ONCE(ep->ovflist) != EP_UNACTIVE_PTR) {if (epi->next == EP_UNACTIVE_PTR &&// 将epi添加到ovflist链表尾部chain_epi_lockless(epi))ep_pm_stay_awake_rcu(epi);goto out_unlock;}// 还没有加入到就绪队列,将其加入if (!ep_is_linked(epi) &&list_add_tail_lockless(&epi->rdllink, &ep->rdllist)) { ep_pm_stay_awake_rcu(epi);}// 如果等待列表不为空if (waitqueue_active(&ep->wq)) {// 如果一个file同时使用EPOLLEXCLUSIVE添加到多个epoll实例中,那么在这些epoll实例中,每次只会唤醒一个有阻塞队列的epoll// 因此当设置了EPOLLEXCLUSIVE,只有真正唤醒了epoll的等待队列才会返回trueif ((epi->event.events & EPOLLEXCLUSIVE) &&// 如果存在POLLFREE,需执行一些清理操作,其他epoll也应该得到通知,因此需要返回false!(pollflags & POLLFREE)) {switch (pollflags & EPOLLINOUT_BITS) {case EPOLLIN:if (epi->event.events & EPOLLIN)ewake = 1;break;case EPOLLOUT:if (epi->event.events & EPOLLOUT)ewake = 1;break;case 0:ewake = 1;break;}}wake_up(&ep->wq); // 唤醒epoll对应的wq}if (waitqueue_active(&ep->poll_wait))pwake++; // 这里不能直接唤醒,存在锁竞争out_unlock:read_unlock_irqrestore(&ep->lock, flags);/* We have to call this outside the lock */// 唤醒等待epoll本身事件的等待队列if (pwake)ep_poll_safewake(&ep->poll_wait);// 没有设置EPOLLEXCLUSIVE,该方法会直接返回trueif (!(epi->event.events & EPOLLEXCLUSIVE))ewake = 1;// 存在POLLFREE,执行清理操作if (pollflags & POLLFREE) {list_del_init(&wait->entry);smp_store_release(&ep_pwq_from_wait(wait)->whead, NULL);}return ewake;
}
惊群效应
In computer science, the thundering herd problem occurs when a large number of processes or threads waiting for an event are awoken when that event occurs, but only one process is able to handle the event. After all the processes wake up, they will start to handle the event, but only one will win. All processes will compete for resources, possibly freezing the computer, until the herd is calmed down again.
多个进程/线程等待同一个epoll实例
如果多个进程或者线程通过epoll_wait阻塞在同一个epoll上,从上面的代码我们知道,当使用水平触发模式的时候,就绪的fd会被重新加入到就绪队列中,从而导致多个线程/进程被同一个就绪fd唤醒。我们可以使用边缘触发模式,或者设置EPOLLONESHOT来规避该问题。
同一个fd被加入到多个epoll实例
当一个file被同时添加到多个epoll中,并且监听了相同的事件。当该file对应事件就绪时,默认该file会被添加到每个epoll的就绪队列中。
可以在添加file到每个epoll的时候,设置EPOLLEXCLUSIVE这个flag来解决该问题:
Sets an exclusive wakeup mode for the epoll file descriptor that is being attached to the target file descriptor, fd. When a wakeup event occurs and multiple epoll file descriptors are attached to the same target file using EPOLLEXCLUSIVE, one or more of the epoll file descriptors will receive an event with epoll_wait(2). The default in this scenario (when EPOLLEXCLUSIVE is not set) is for all epoll file descriptors to receive an event. EPOLLEXCLUSIVE is thus useful for avoiding thundering herd problems in certain scenarios.
If the same file descriptor is in multiple epoll instances, some with the EPOLLEXCLUSIVE flag, and others without, then events will be provided to all epoll instances that did not specify EPOLLEXCLUSIVE, and at least one of the epoll instances that did specify EPOLLEXCLUSIVE.
注意:
EPOLLEXCLUSIVE只能在EPOLL_CTL_ADD操作中设置- 无法有效的和
EPOLLONESHOT共用,因为在ep_send_events_proc中,如果设置了EPOLLONESHOT,EPOLLEXCLUSIVE这个flag会被清除,但是该flag又不能在EPOLL_CTL_MOD调用时设置


![FileZilla的使用及主动模式与被动模式[FileZilla]](https://img-blog.csdnimg.cn/direct/add96a35b116442db7ce9c4dec83d6fc.png)