Tungsten 内存管理机制
催生 Tungsten 内存管理优化的原因主要来自两个方面 。
• Java对象占用内存空间大。 相对于 C/C++等更加底层的程序语言, Java对象的存储密度相对偏低。 例如,即使最简单的 “abed” 字符串,用Java的UTF-16编码的情况下也需要8 字节进行存储, 加上Java内存布局的其他信息(如header等),共需要48字节的空间来 存储“abed”字符串 。
• JVM垃圾回收(GarbageCollection)的开销大。 在海量数据场景下,数据分析通常会涉及转换、 清洗、处理等步骤,这个过程伴随着海量的 Java对象创建与回收, JVM垃圾回收的执行效率对应用性能有着很大影响。 JVM 调优能够在一定程度上提升性能,但是过程非常烦琐,且需要用户对应用、分布式计算框架和 JVM 都有深入的了解 。
Tungsten 优化中堆外内存的引入有效解决了上述问题 。
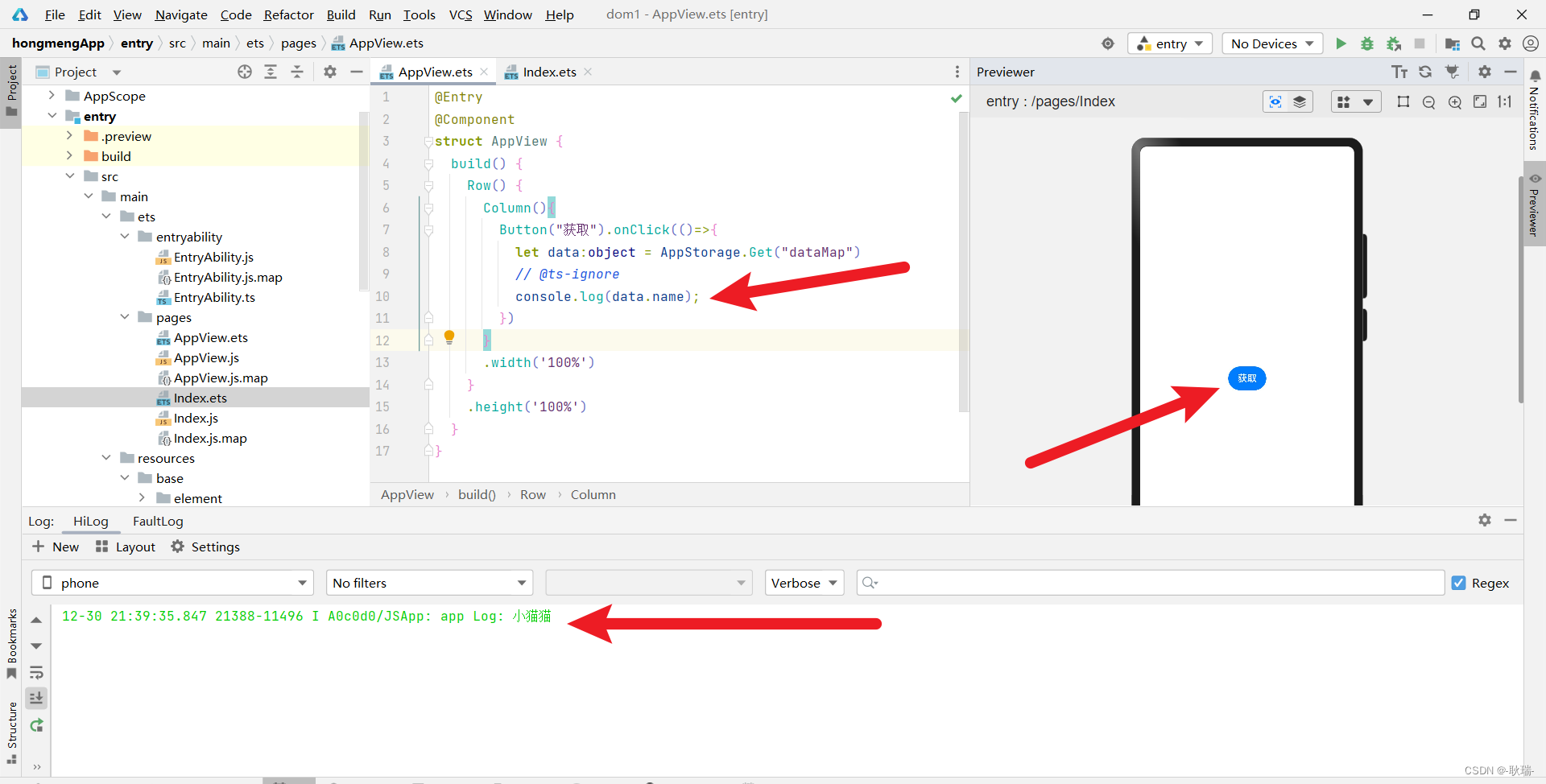
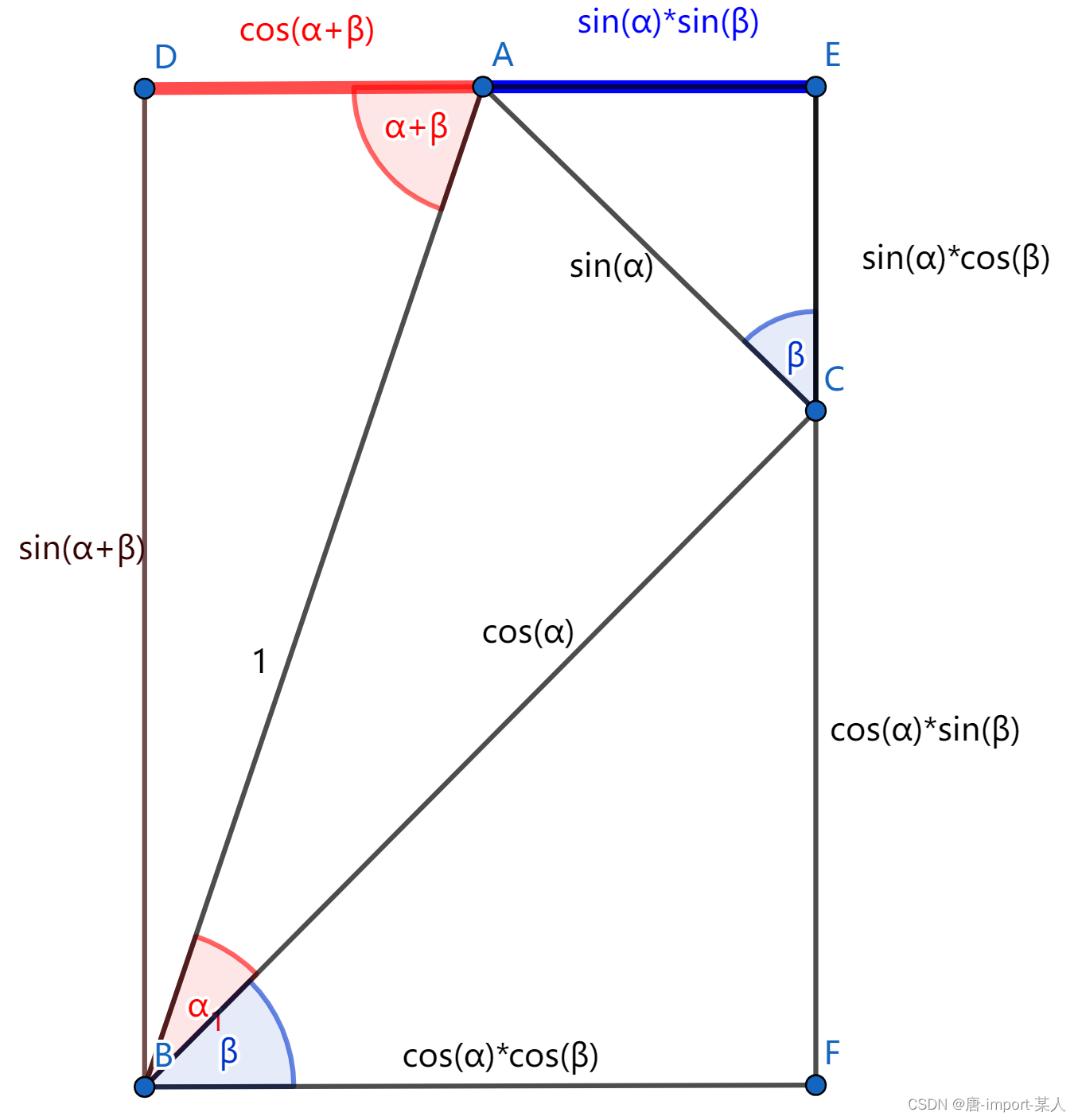
Tungsten 内存管理机制较核心部分的实现在 TaskMemoryManager类中, 如下图所示。 可 以看到, Tungsten 按照内存页表 (pageTable)的方式来管理 内存,pageTable 本质上是一个 MemoryBlock 的数组 ,这些内存会被 Task 内部的内存消费者( MemoryConsumer)使用 。

每个Task的内存空间被划分为多个内存页(page) ,每个内存页本质上都是一个内存块 (MemoryBlock) 。 为统一堆内和堆外的内存访问方式, TaskMemoryManager 引入了类似操作系统中虚拟内存逻辑地址的概念,并将逻辑地址映射到实际的物理地址。 逻辑地址由一个 64bits 的长整型表示,其中处于高位的 13bits用来表示页编号(pageNumber),处于低位的 5lbits用来表示在该内存页内部的偏移( offsetlnPage)。 这样内存映射的过程,实际上就是先根据内存页编号查询页表(pageTable),得到对应的内存页 ,然后得到该页的物理地址,最后在物理地址上加上偏移,得到实际内存物理地址。因此,所有内存地址都可由 pageNumber和 offsetinPage决定。
Note: 对于堆外内存,当给定内存地址时,可以使用与 CIC++ 语言中操作指针 一样的方法,在 一 个数据结构中指向另一个数据结构来访问内存空间中的数据。然而,在 JVM 堆内内存模式下, GC 会导致堆内结构重 新组织 , Java 对 象 的内存地扯不 是固定 不变的,无法直 接使 用对象指针(地址〉来访问 。
Shuffle实现
Unsafe Shuffle 的实现在 一定程度上可以算是 Tungsten 内存管理优化最主要的应用场景。 在前面的内容中已经介绍过, Tungsten 方式的 Shuffle 过程中, ShuffleMapTask 的输出数据能够先序列化为二进制数据存储在内存中,再执行相关的操作 。 Tungsten Shuffle 的写操作由 UnsafeShuffleWriter 完成,与常规的 SortShuffleWriter 的不同之处在于 UnsafeShuffleWriter 中不涉及数据的反序列化操作 。
UnsafeShuffleWriter里面维护着一个 ShuffleExternalSorter,用来进行外部排序,与 SortShuffleWriter中的ExternalSorter功能类似。 当UnsafeShuffleWriter在逐条写入RDD的(K,V)记录时, 首先会由 Partitioner根据 K得到 partitionld,并依次将 K和 V序列化写入临时的 serOutputStream 中,然后写入 ShuffleExternalSorter。 因此, ShuffleExternalSorter 是 Tungsten Shuffle 写实现的核 心所在 。
缓存敏感计算( Cache-aware computation)
缓存敏感计算(Cache-awarecomputation)是 Tungsten 中一个比较重要的优化,主要对比的是普通的内存计算 。 在硬件层面,访问 CPU 的 Ll/L2/L3 级缓存比访 问内存速度快,大数据处理系统可以利用这个特性优化性能 。 而要将数据存储在 Ll/L2/L3 中,数据大小需要满足特定条件 。
基于该目标, Tungsten 缓存敏感计算机制通过设计缓存友好的数据结构来提高缓存命中率 (Cache hit)和本地化( Cache locality)的特性 。 到目前为止, Spark 中缓存敏感的计算优化针对 的主要是排序(Sort)操作,相应的实现是 UnsafeExterna!Sorter和 UnsafeinMemorySorter类(参 见 org叩ache叩ark.ut且unsafe.sort包)。 实际上, cache-aware排序方式在 Spark1.5版本中已经实现,其主要思想受微软 AlphaSort 研究工作的启发 。
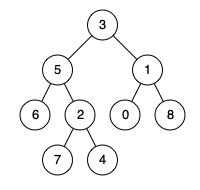
Tungsten 中 cache-aware 排序原理如下图所示。 常规的做法是每个 record (<key, value>) 中有一个指针指向该 record,对两个 record排序先根据指针定位到实际数据,然后对实际数据 进行比较,这个操作涉及的都是内存的随机访问(Random access),缓存本地化(Cachelocality)会变得很低。 针对该缺陷,缓存友好的存储方式会将 key和 record指针放在一起,以 key为前 缀,排序操作是按照线性方式查询 key-pointer 对,避免内存的随机访问 。

动态代码生成( Code generation)
Spark引入代码生成主要用于 SQL和 DataFrames中的表达式求值(Expression evaluation) 。表达式求值的过程是在特定的记录上计算一个表达式的值。 当然,这里指的是运行时,而不是在一个缓慢的解释器中逐行做单步调试。 对比解释器,代码生成去掉了原始数据类型的封装,更重要的是,避免了昂贵的多态函数调度。
当今绝大多数数据库系统处理 SQL查询的方式都是将其翻译成一系列的关系代数算子或表达式,然后依赖这些关系代数算子逐条处理输入数据并产生结果。 从本质上看,这是一种迭代的模式,某些时候也被称为 Volcano形式的处理方式,由 Graefe在 1993年提出 。
该模式可以概括为.每个物理关系代数算子反复不断地调用 next 函数来读入数据元组 (Tuple)作为算子的输入,经过表达式处理后输出一个数据元组的流( Tuple stream)。 这种模式简单而强大,能够通过任意组合算子来表达复杂的查询 。
这种迭代处理模式提出的背景是减轻查询处理的 IO瓶颈,对 CPU 的消耗则考虑较少。 首先,每次处理一个数据元组时, next 函数都会被调用,在数据量非常大时,调用的次数会非常多。 最重要的是,next函数通常实现为虚函数或函数指针,这样每次调用都会引起CPU中断并使得 CPU 分支预测( Branch Prediction)下降,因此相比常规函数的调用代价更大。 此外,迭代处理模式通常会导致很差的代码本地化能力,并且需要保存复杂的处理信息。例如,表扫描算子在处理一个压缩的数据表时,在迭代模式下,需要每次产生一个数据元组,因此表扫描算子中需要记录当前数据元组在压缩数据流中的位置,以便根据压缩方式跳转到下一条数据元组的位置 。
正是基于这些考虑及实际性能上的观察,一些现代的数据库系统开始尝试摆脱单纯的迭代模式,考虑面向数据块( Block)的方式(一次读取一批数据)来获得数据向量化的处理优势。 具体包含两方面,一方面是每次解压一批数据元组,然后每次迭代读取数据时只在这批数据中读取;另一方面是直接在 next 函数读取数据时就读取多个数据元组,甚至一次性读取所有的数据元组。上述面向数据块的处理方式在一定程度上确实能够消除在大数据量情况下的调用代价, 然而在另一方面却丢掉了迭代模式一个重要的优点,即所谓的能够按照管道方式传输数据 (Pipelining data) 。 管道方式意味着数据从一个算子传输到另一个算子不需要进行额外复制或序列化处理。 例如,select就是一个具有管道方式的算子,能够在不修改数据的前提下传输数据元组到下一个算子。然而,在面向数据块的处理方式中,一次产生多条数据元组往往需要序列化保存,虽然能够带来向量化处理的优势,但是破坏了管道方式的优点,并且在通常情况下会消耗更多的内存与网络带宽。
因此,当内存与IO不再成为瓶颈后,CPU成为现代数据库系统的主要瓶颈。MonetDB系列的数据库处理系统采用的是面向数据块的思路。 另一个思路则是将查询编译成中间可执行的格式,即动态代码生成( Code generation),来取代解释性的结构。在实际数据处理中,比较有意思的一个发现是开发人员手写的程序明显比向量化的数据库系统性能高。
总的来讲,动态代码生成能够有效地解决 3 个方面的问题 。
- 大量虚函数调用,生成的实际代码不再需要执行表达式系统中统一定义的虚函数(如Eva!、 Evaluate 等) 。
- 判断数据类型和操作算子等内容的大型分支选择语句 。
- 常数传播( Constants propagation)限制,生成的代码中能够确定性地折叠常量。
近年来,在代码生成方面, 学术界与企业界也做了大量的工作。例如,将查询逻辑转换为 Java字节码、HIQUE 系统将查询翻译为C代码。 代码生成技术在大数据系统中的应用也非常广泛,例如, Impala中采用 LLVM (Low-LevelVirtualMachine)作为中间代码加速数据处理、 SparkSQL生成 Java中间代码来提升效率。