- 一、前置安装准备
- 1、机器
- 2、java
- 3、创建hadoop用户
- 二、安装Hadoop
- 三、环境配置
- 1、workers
- 2、hadoop-env.sh
- 3、core-site.xml
- 4、hdfs-site.xml
- 5、linux中Hadoop环境变量
- 四、启动hadoop
- 五、验证
一、前置安装准备
1、机器
| 主机名 | ip | 服务 |
|---|---|---|
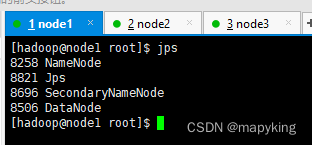
| node1 | 192.168.233.100 | NameNode、DataNode、SecondaryNameNode |
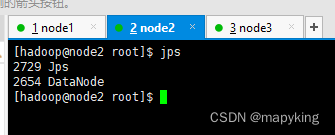
| node2 | 192.168.233.111 | DataNode |
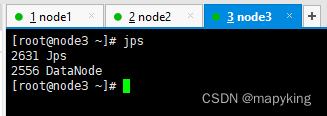
| node3 | 192.168.233.222 | DataNode |
配置host
hostnamectl set-hostname node1vim /etc/hosts192.168.233.100 node1
192.168.233.111 node2
192.168.233.222 node3
关闭防火墙,关闭selinux
systemctl stop firewalld
systemctl disable firewalldvim /etc/sysconfig/selinux
SELINUX=disabled
setenforce 0
2、java
需要安装java
rz
tar -zxvf jdk-8u381-linux-x64.tar.gz -C /
ln -s /jdk1.8.0_381/ /jdk
# rm jdk-8u381-linux-x64.tar.gzvim /etc/profile
export JAVA_HOME=/jdk
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile
ln -s /jdk/bin/java /usr/bin/java
3、创建hadoop用户
后续hadoop程序用hadoop用户启动
uesradd hadoop
passwd hadoop # 123456su hadoop
ssh-keygen -t rsa -b 4096
ssh-copy-id 192.168.233.100
ssh-copy-id 192.168.233.111
ssh-copy-id 192.168.233.222
二、安装Hadoop
Hadoop可以选择清华源或者官网下载官网
rz # 上传hadoop包到机器
tar -zxvf hadoop-3.3.6.tar.gz -C / # 解压到对应目录
ln -s /hadoop-3.3.6/ /hadoop # 创建软连接
# rm -rf hadoop-3.3.6.tar.gz 删除包
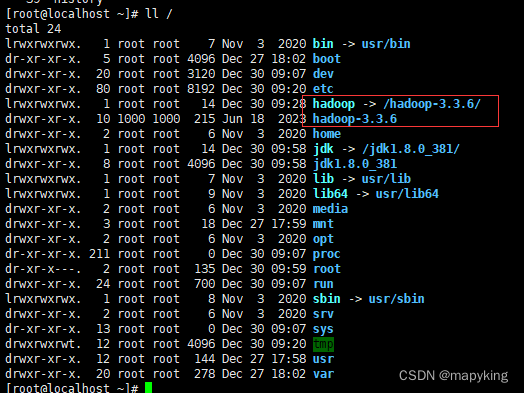
[root@localhost hadoop]# ll /hadoop
total 92
drwxr-xr-x. 2 1000 1000 203 Jun 18 2023 bin # 存放hadoop命令
drwxr-xr-x. 3 1000 1000 20 Jun 18 2023 etc # 存放配置文件
drwxr-xr-x. 2 1000 1000 106 Jun 18 2023 include
drwxr-xr-x. 3 1000 1000 20 Jun 18 2023 lib
drwxr-xr-x. 4 1000 1000 4096 Jun 18 2023 libexec
-rw-rw-r--. 1 1000 1000 24276 Jun 13 2023 LICENSE-binary
drwxr-xr-x. 2 1000 1000 4096 Jun 18 2023 licenses-binary
-rw-rw-r--. 1 1000 1000 15217 Jun 9 2023 LICENSE.txt
-rw-rw-r--. 1 1000 1000 29473 Jun 9 2023 NOTICE-binary
-rw-rw-r--. 1 1000 1000 1541 Jun 9 2023 NOTICE.txt
-rw-rw-r--. 1 1000 1000 175 Jun 9 2023 README.txt
drwxr-xr-x. 3 1000 1000 4096 Jun 18 2023 sbin # 管理员程序
drwxr-xr-x. 4 1000 1000 31 Jun 18 2023 share三、环境配置
均在 /hadoop/etc/hadoop 目录下
1、workers
配置DataNode 从节点,以此告诉集群有多少个节点
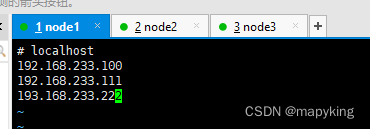
vim etc/hadoop/workers# localhost
192.168.233.100
192.168.233.111
192.168.233.222
2、hadoop-env.sh
配置Hadoop相关环境变量
vim etc/hadoop/hadoop-env.shexport JAVA_HOME=/jdk
export HADOOP_HOME=/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
3、core-site.xml
Hadoop 核心配置文件
vim /hadoop/etc/hadoop/core-site.xml<configuration><property><name>fs.defaultFS</name> # HDFS文件系统的网络通讯路径<value>hdfs://192.168.233.100:8020</value> # 表明datanode将和192.168.233:8020通讯,该配置固定了192.168.233:8020是NameNode进程</property><property><name>io.file.buffer.size</name> # io操作文件缓冲区大小,单位是bit<value>131072</value></property>
</configuration>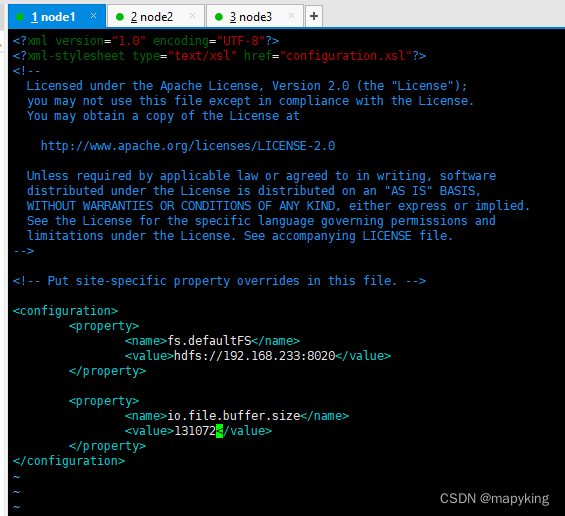
4、hdfs-site.xml
HDFS 核心配置文件
vim /hadoop/etc/hadoop/hdfs-site.xml<configuration><property><name>dfs.datanode.data.dir.perm</name> # 定义hdfs文件系统默认创建文件的权限,700<value>700</value></property><property><name>dfs.namenode.name.dir</name> # NameNode元数据存储位置,在192.168.233.100/data/nm下<value>/data/nn</value></property><property><name>dfs.namenode.hosts</name> # namenode允许哪几个datanode连接,定义允许加入集群<value>192.168.233.100,192.168.233.111,192.168.233.222</value></property><property><name>dfs.blocksize</name> # 定义block块大小,256MB<value>268435456</value></property><property><name>dfs.namenode.handler.count</name> # 定义namenode处理的并发线程数<value>100</value></property><property><name>dfs.datanode.data.dir</name> # data数据存储目录<value>/data/dn</value></property></configuration># node1
mkdir -p /data/nn
mkdir -p /data/dn# node2、node3
mkdir -p /data/dn
5、linux中Hadoop环境变量
vim /etc/profileexport HADOOP_HOME=/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin# source /etc/profile
chown -R hadoop:hadoop /jdk1.8.0_381
chown -R hadoop:hadoop /jdk
chown -R hadoop:hadoop /hadoop-3.3.6
chown -R hadoop:hadoop /hadoop
chown -R hadoop:hadoop /data
四、启动hadoop
su hadoop
hadoop namenode -format # 格式化namenode
start-dfs.sh
# stop-dfs.sh 停止
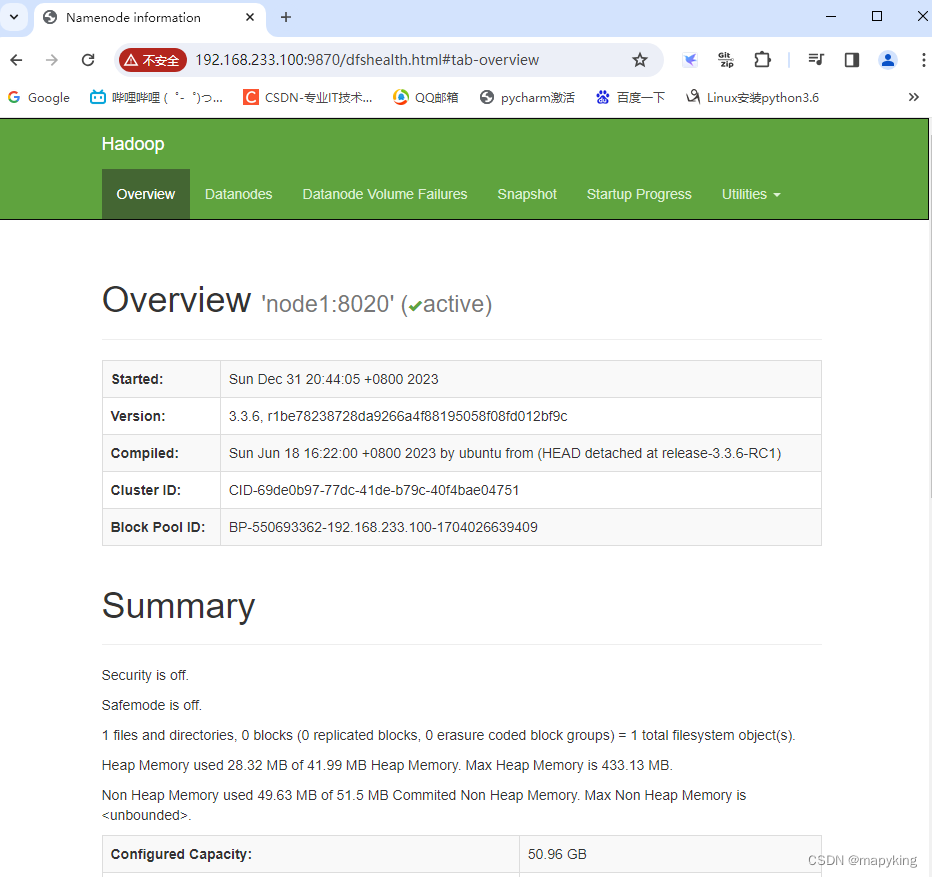
五、验证