什么是 CAP?
C 代表 Consistency,一致性,是指所有节点在同一时刻的数据是相同的,即更新操作执行结束并响应用户完成后,所有节点存储的数据会保持相同。
A 代表 Availability,可用性,是指系统提供的服务一直处于可用状态,对于用户的请求可即时响应。
P 代表 Partition Tolerance,分区容错性,是指在分布式系统遇到网络分区的情况下,仍然可以响应用户的请求。网络分区是指因为网络故障导致网络不连通,不同节点分布在不同的子网络中,各个子网络内网络正常。
CAP 理论又是什么呢?
CAP 理论指的就是,在分布式系统中 C、A、P 这三个特征不能同时满足,只能满足其中两个,如下图所示。
什么是 CAP 以及 CAP 为什么不能同时满足?
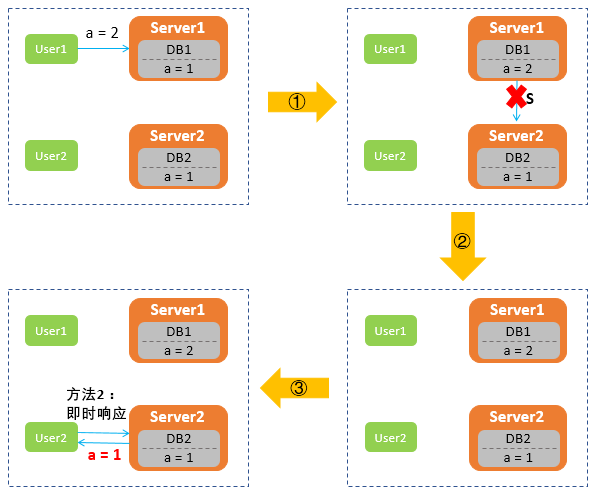
网络中有两台服务器 Server1 和 Server2,分别部署了数据库 DB1 和 DB2,这两台机器组成一个服务集群,DB1 和 DB2 两个数据库中的数据要保持一致,共同为用户提供服务。用户 User1 可以向 Server1 发起查询数据的请求,用户 User2 可以向服务器 Server2 发起查询数据的请求,它们共同组成了一个分布式系统。
对这个系统来说,分别满足 C、A 和 P 指的是:
- 在满足一致性 C 的情况下,Server1 和 Server2 中的数据库始终保持一致,即 DB1 和 DB2 内容要始终保持相同;
- 在满足可用性 A 的情况下,用户无论访问 Server1 还是 Server2,都会得到即时响应;
- 在满足分区容错性 P 的情况下,Server1 和 Server2 之间即使出现网络故障也不会影响 Server1 和 Server2 分别处理用户的请求。
用户 User1 向服务器 Server1 发起请求,将数据库 DB1 中的数据 a 由 1 改为 2;
系统会进行数据同步,即图中的 S 操作,将 Server1 中 DB1 的修改同步到服务器 Server2 中,使得 DB2 中的数据 a 也被修改为 2;
当 User2 向 Server2 发起读取数据 a 的请求时,会得到 a 最新的数据值 2。

这其实是在网络环境稳定、系统无故障的情况下的工作流程。但在实际场景中,网络环境不可能百分之百不出故障,比如网络拥塞、网卡故障等,会导致网络故障或不通,从而导致节点之间无法通信,或者集群中节点被划分为多个分区,分区中的节点之间可通信,分区间不可通信。
这种由网络故障导致的集群分区情况,通常被称为“网络分区”。在分布式系统中,网络分区不可避免,因此分区容错性 P 必须满足。接下来,我们就来讨论一下在满足分区容错性 P 的情况下,一致性 C 和可用性 A 是否可以同时满足。
假设,Server1 和 Server2 之间网络出现故障,User1 向 Server1 发送请求,将数据库 DB1 中的数据 a 由 1 修改为 2,而 Server2 由于与 Server1 无法连接导致数据无法同步,所以 DB2 中 a 依旧是 1。这时,User2 向 Server2 发送读取数据 a 的请求时,Server2 无法给用户返回最新数据,那么该如何处理呢?
- **第一种处理方式是,**保证一致性 C,牺牲可用性 A:Server2 选择让 User2 的请求阻塞,一直等到网络恢复正常,Server1 被修改的数据同步更新到 Server2 之后,即 DB2 中数据 a 修改成最新值 2 后,再给用户 User2 响应。
- **第二种处理方式是,**保证可用性 A,牺牲一致性 C:Server2 选择将旧的数据 a=1 返回给用户,等到网络恢复,再进行数据同步。
保 CP 弃 A
如果一个分布式场景需要很强的数据一致性,或者该场景可以容忍系统长时间无响应的情况下,保 CP 弃 A 这个策略就比较适合。
保证 CP 的系统有很多,典型的有 Redis、HBase、ZooKeeper 等。接下来,我就以 ZooKeeper 为例,带你了解它是如何保证 CP 的。
首先,我们看一下 ZooKeeper 架构图。
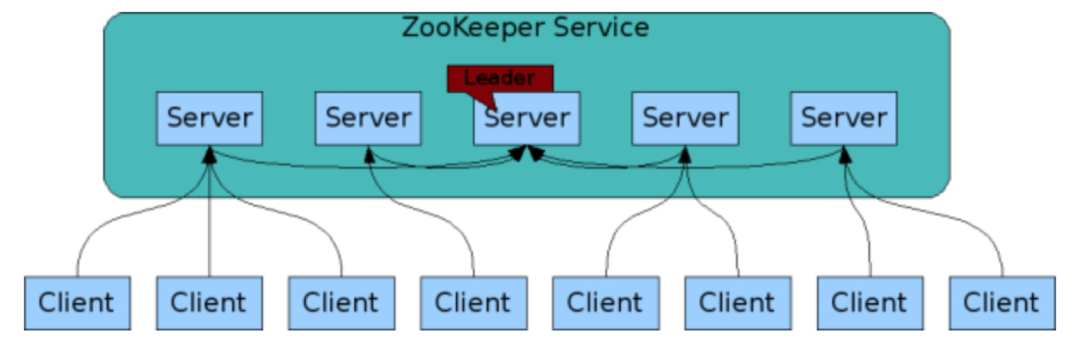
ZooKeeper 集群包含多个节点(Server),这些节点会通过分布式选举算法选出一个 Leader 节点。在 ZooKeeper 中选举 Leader 节点采用的是 ZAB 算法。在 ZooKeeper 集群中,Leader 节点之外的节点被称为 Follower 节点。
Leader 节点会专门负责处理用户的写请求:
当用户向节点发送写请求时,如果请求的节点刚好是 Leader,那就直接处理该请求;
如果请求的是 Follower 节点,那该节点会将请求转给 Leader,然后 Leader 会先向所有的 Follower 发出一个 Proposal,等超过一半的节点同意后,Leader 才会提交这次写操作,从而保证了数据的强一致性。
具体示意图如下所示:

当出现网络分区时,如果其中一个分区的节点数大于集群总节点数的一半,那么这个分区可以再选出一个 Leader,仍然对用户提供服务,但在选出 Leader 之前,不能正常为用户提供服务;如果形成的分区中,没有一个分区的节点数大于集群总节点数的一半,那么系统不能正常为用户提供服务,必须待网络恢复后,才能正常提供服务。
这种设计方式保证了分区容错性,但牺牲了一定的系统可用性。
保 AP 弃 C
**适合保证 AP 放弃 C 的场景有很多。**比如,很多查询网站、电商系统中的商品查询等,用户体验非常重要,所以大多会保证系统的可用性,而牺牲一定的数据一致性。
目前,采用保 AP 弃 C 的系统也有很多,比如 CoachDB、Eureka、Cassandra、DynamoDB 等。
知识扩展:CAP 和 ACID 的“C”“A”是一样的吗?
首先,我们看一下 CAP 中的 C 和 ACID 中的 C 是否一致。
- CAP 中的 C 强调的是数据的一致性,也就是集群中节点之间通过复制技术保证每个节点上的数据在同一时刻是相同的。
- ACID 中的 C 强调的是事务执行前后,数据的完整性保持一致或满足完整性约束。也就是不管在什么时候,不管并发事务有多少,事务在分布式系统中的状态始终保持一致。
其次,我们看一下 CAP 中的 A 和 ACID 中的 A。
CAP 中的 A 指的是可用性(Availability),也就是系统提供的服务一直处于可用状态,即对于用户的请求可即时响应。
ACID 中的 A 指的是原子性(Atomicity),强调的是事务要么执行成功,要么执行失败。
BASE理论
BASE理论是对CAP理论的一种实践指导原则,提出在分布式系统中更加灵活的一致性模型。具体来说:
- 基本可用性(Basically Available):系统保证在正常情况下的可用性,即系统能够及时响应用户请求。
- 软状态(Soft state):系统中的数据状态可以在一段时间内是不确定的,即允许存在中间状态。
- 最终一致性(Eventually consistent):系统的所有副本最终将达到一致的状态,尽管在某个时间点上可能存在不一致的情况。
BASE理论相对于严格的ACID(原子性、一致性、隔离性、持久性)事务模型,提倡在分布式系统中使用更灵活的一致性模型。它允许系统在一段时间内处于不一致的状态,以获得更高的可用性和性能。