Jmeter基础功能
了解Jmeter的常用组件
元件:多个类似功能组件的容器(类似于类)
一:Test Plan(测试计划)
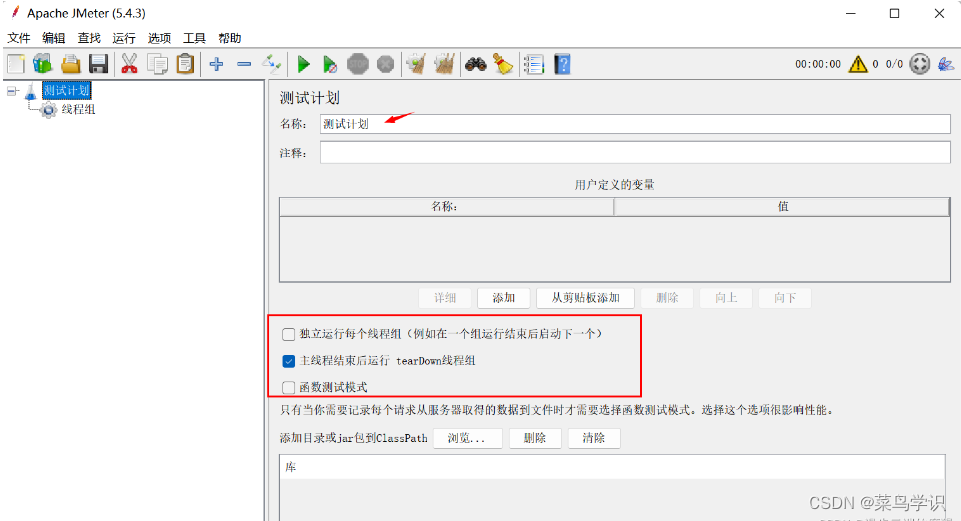
测试计划通常用来给测试的项目重命名,使用多线程脚本运行时还可以配置线程组运行方式
用户定义的变量:
在测试计划上可以添加用户定义的变量,相当于是全局变量。
一般添加一些系统常用的配置。如果测试过程中想切换环境,切换配置,一般不建议在测试计划上添加变量,因为不方便启用和禁用,一般是直接添加用户自定义变量组件。独立运行每个线程组:
用于控制测试计划中的多个线程组的执行顺序。
不勾选时,默认各线程组并行、随机执行。
如果勾选了独立运行每个线程组,可以保证按照顺序执行各线程组。
补充说明:
线程组中的取样器的执行顺序:默认是从上到下执行。交替控制器、随机控制器、随机顺序控制器和循环控制器等可以改变取样器的执行顺序。Run tearDown Thread Groups after shutdown of main threads:
当线程组停止运行时仍继续运行 tearDown 线程组,该选项结合线程组的执行配置使用,一般很少用到,了解即可。函数测试模式(Functional Testing):
如果选中了此选项,同时监听组件如“查看结果树”配置了保存到一个文件中,那么jmeter会将每次的请求结果保存到文件中。一般不建议勾选。Add directory or jar to classpath:
添加文件或jar包,此功能最常用于调用外部jar包。
当脚本需要调用外部的java文件或jar包时,可以把jar包路径添加到这里,然后在beanshell中直接import进来,并调用jar包中的方法。二、线程组
用于设置发送请求的线程数,线程的时间间隔以及循环次数

三、配置元件
CSV Data Set Config
1)用户配置常用的参数等,常用的有:CSV Data Set Config,HTTP信息头管理器,HTTP请求默认值,用户自定义的变量等。CSV Data Set Config用于数据参数化

例如:
test.csv 文件内容如下
name,age,sex,class,address
李白,8,男,2班,中国
杜甫,7,男,3班,中国
苏轼,9,男,1班,中国设置CSV配置元件

HTTP信息头管理器
2)HTTP信息头管理器用户配置请求头参数,token变量值取自登录接口返回,其余参数均参照浏览器F12查看接口的请求头数据

常用请求头:

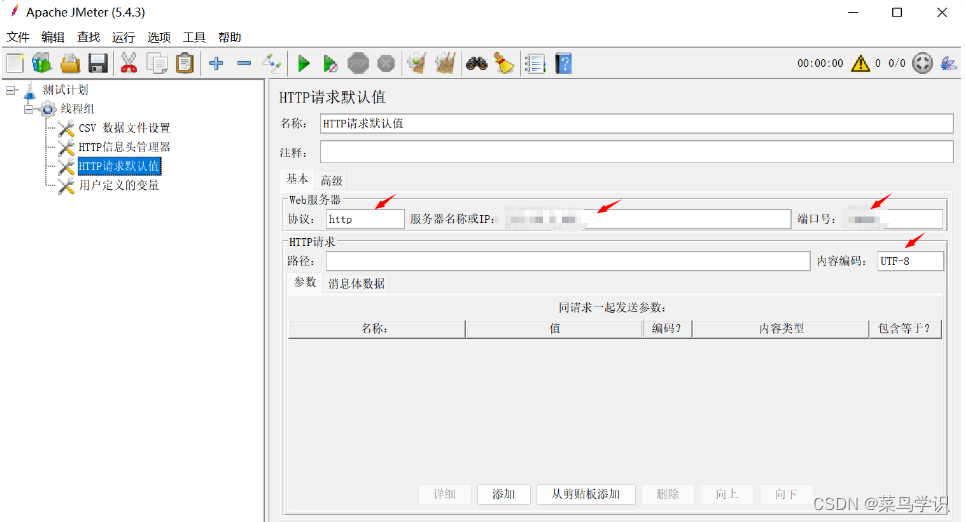
HTTP请求默认值
3)HTTP请求默认值用于配置接口默认请求参数,配置协议,IP,端口号,编码等,线程组内的全部请求参数均取自该处
用户自定义的变量
4)用户自定义的变量用于设置变量值
用户自定义变量,通过表达式 ${变量名} 引用变量的值。
放在测试计划下,可实现跨线程组共享数据。

请求时的引用:
JDBC Connection Configuration
5)JDBC Connection Configuration(数据库链接配置)
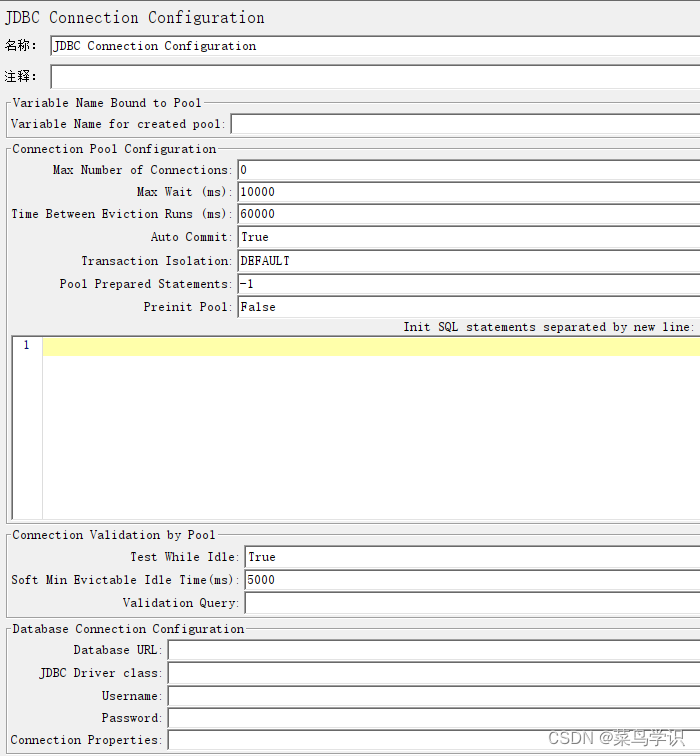
主要参数:
Variable Name(绑定到池的变量名称):
该名称自定义,在JDBC Request会用到,名称必须保证唯一性,不可重复;JDBC Sampler 使用它来标识要使用的配置。Database URL(数据库URL):
jdbc:mysql://数据库IP地址:数据库端口/数据库名称。JDBC Driver Class(JDBC驱动程序类):
com.mysql.jdbc.Driver。 Username(用户名):
数据库连接的用户名。 Password(密码):
数据库连接的密码。其他参数:
Max Number of Connections:最大连接数。
Max Wait:最大延迟时间,单位毫秒。
Time Between Eviction Runs:线程可空闲时间,单位毫秒。
Auto Commit:自动提交sql语句。
Transacion Isolation:事务隔离级别。
Pool Prepared Statements:????
Preinit Pool:立即初始化连接池,如果为 False,则第一个 JDBC 请求的响应时间会较长,因为包含了连接池建立的时间。
Test While Idle:当连接空闲时是否断开。
Soft Min Evictable Idle Time(ms):连接在池中处于空闲状态的最短时间。
Validation Query:一个简单的查询,用于确定数据库是否仍在响应 ;默认为jdbc驱动程序的 isValid() 方法,适用于许多数据库使用时JDBC Connection Configuration 需要和 JDBC Request 配合使用
1)新建 JDBC Connection Configuration

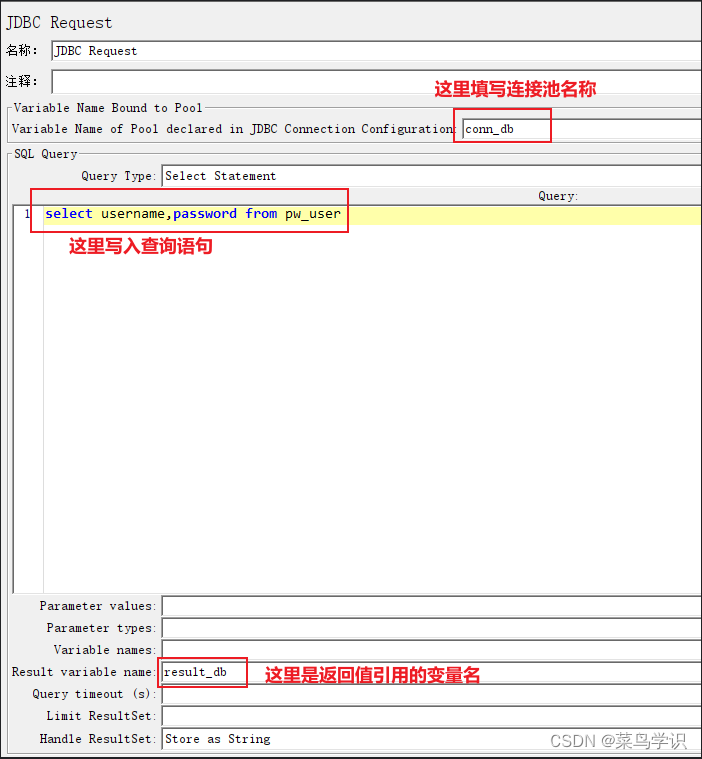
2)新建 JDBC Request
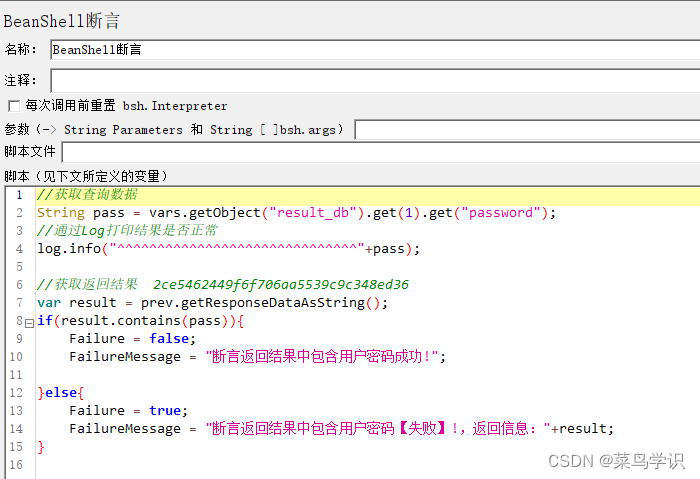
3)新建 BeanShell 断言
四、取样器
向服务器发送请求,常见的如:HTTP Request Sampler、FTP Request Sample、TCP Request Sample、JDBC Request Sampler等,每一种不同类型的请求可以根据设置的参数向服务器发出不同类型的请求,最常见的为HTTP Request Sampler
1)HTTP请求


2)Debug Sampler (调试取样器)
定位后置处理器提取结果,定位到的样本通过查看结果树查看
将调试取样器放置在样本的下方,可以提取到对应的样本数据。


五、后置处理器
请求之后的操作,通常用来提取接口返回数据,常用的有JSON提取器,正则表达式提取器等
json 提取器
JSON 提取器可以使用JSON-PATH语法从JSON格式的响应中提取数据
JsonPath语法
(1) “$” 根节点,“@” 当前节点,“*” 所有节点;(2) “.” 或 “[]” 去子节点;(3)如果是数组(llist),则通过下标取值;(4)相对路径用法:$..name 这里的 name 一般需要唯一;(5)列表切片:$.tags[0:3];(6)“?()” 过滤操作;(7)“()” 表达式计算;请求的返回结果为json格式,通过查看结果树里的 JSON PATH TESTER 模式检索匹配结果


设置JSON提取器: 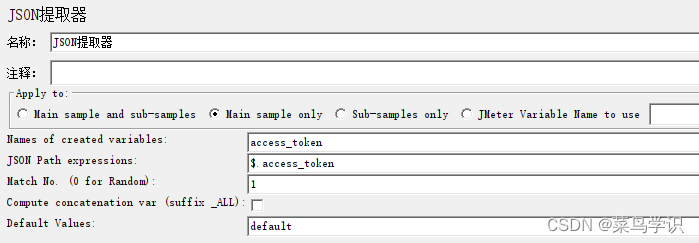
设置json断言:

正则表达式提取器
正则表达式提取器:左边界和右边界不能缺失,如果有特殊字符必须用\转义符
设置提取的access_token值名称为token

设置响应断言:

六、监听器
负责收集测试结果,同时确定结果的显示方式,常用的有查看结果树、聚合报告等
察看结果树
察看结果树,显示取样器请求和响应的细节以及请求结果,包括消息头,请求的数据,响应的数据。
(1)察看结果树,放的位置不同,查看的结果也不同。在线程组下添加察看结果树,查看线程组下所有请求的结果;放在具体某个请求下,只查看此请求的结果;若放在某个控制器节点下,则查看此控制器下节点执行的结果;
(2)该监听器推荐做调试用,在实际运行压测时,应该禁用,因为大量请求时,启用该监听器时打印的日志比较多,会造成大IO消耗,影响压力机性能。
结果说明:
1)查看请求结果,请求成功的测试通常为绿色;红色则代表失败。
注:在没有对请求断言的情况下,显示绿色并不一定是成功,只代表响应码是200或300系列,显示红色说明响应码是400或500系列。所以要想确定请求返回的是正确的,必须要加上断言,只有断言成功才会显示绿色。
2)查看对应Sampler的测试结果的请求、响应数据。
取样器结果:显示的是取样器相关参数(客户端参数与响应参数)
请求:发送请求的具体内容
响应数据:服务器返回的相应参数
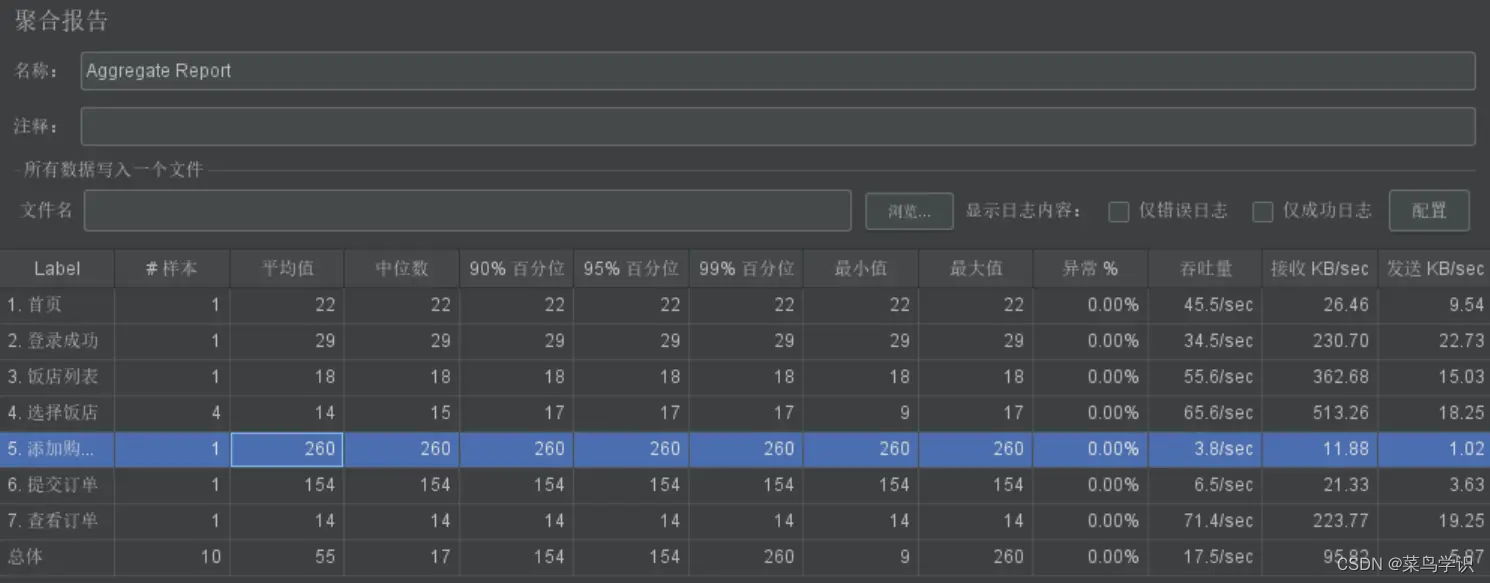
聚合报告
聚合报告,记录这次性能测试的总请求数、错误率、用户响应时间(中间值、90%、最少、最大)、吞吐量等,用以帮助分析被测试系统的性能。在聚合报告中,各个响应时间不能超过客户的要求,就是合格,例如不能超过响应时间2s,大于2s就是不合格的。
该监听器对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,中位数、90%、95%、错误率,吞吐量(以请求数/秒为单位)和以kb/秒为单位的吞吐量。

接口压测实战
一、实战应用简介
1、被压测应用:数据开放平台
2、常见业务场景:登录 ,随机查询、添加购物车等
3、目标:通过对该网站的压测,学习、体会实际业务场景中压测工具的使用方法
4、项目下载:https://github.com/princeqjzh/meican
二、压测脚本编写
压测业务规划
- 梳理常业务场景
- 尽量真实的模拟用户行为,让压测结果更贴近真实结果
- 正常与异常用例场景都需要被覆盖到
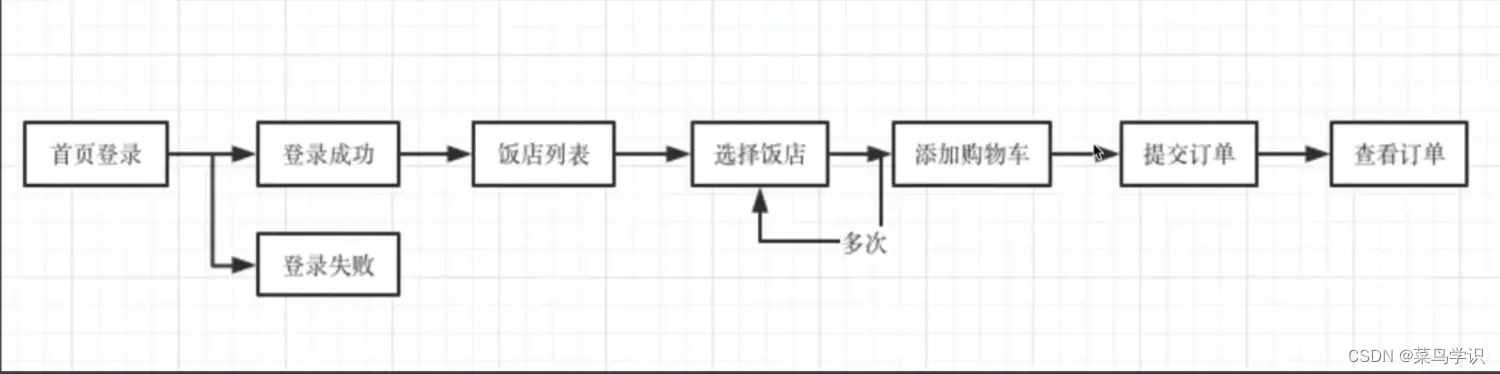
- 压力测试涉及的业务内容:
- 首页
- 登录
- 浏览饭店列表
- 选择饭店
- 添加购物车
- 提交订单
- 查看订单
- 业务场景规划(Demo)
-
正常:登录成功场景
-
异常:登录失败场景
-
编写前的准备
- 被压测页面URL获取方法
- 问研发(依赖别人)
- 抓包(依赖自己)
- 组织测试业务参数
- 新建用户(添加数据)
- 梳理测试商户数据
- 梳理测试商品数据
- 压测业务流程控制
- 预计接口访问次数
- 不同接口的分流比例
- 数据传递位置(参数? 响应payload? Header? Cookie? )
编写压测脚本
-
获取压测接口详情~Demo
压测流程图
开始压测
- 项目中的压测脚本路径
- 项目中的压测脚本
- 安装JMeter插件:Random CSV Data Set(也可百度下载下来放到jmeter的\lib\ext下)

- 开始压测

三、压测实施简介与后续安排
压测实施
- 制定压测策略不同的并发数10,15,20,25,30 ......
- 记录结果
- 测试期望结果
- 验证能够支撑多大并发数,峰值数
- 验证错误率,定义可接受范围,<= 0.1% or <= 0.5% or must = 0%
-
压测目的:寻找系统性能点
- 压测实施过程及生成测试报告和配合性能监控平台进行压测监控
- 部署InfluxDB
- 部署Grafana
- 配置JMeter
- JMeter性能测试实战-CSDN博客
JMeter性能监控平台准备
- 部署方法:Docker 部署
-
下载对应docker镜像,启动container实例

- 压测目标:美餐网
- 运行验证数据传递的正确性
- 验证监控环境运行正常
- 调试ok之后再开始实施压力测试
-
Demo:启动性能监控平台组件并验证系统的正确性
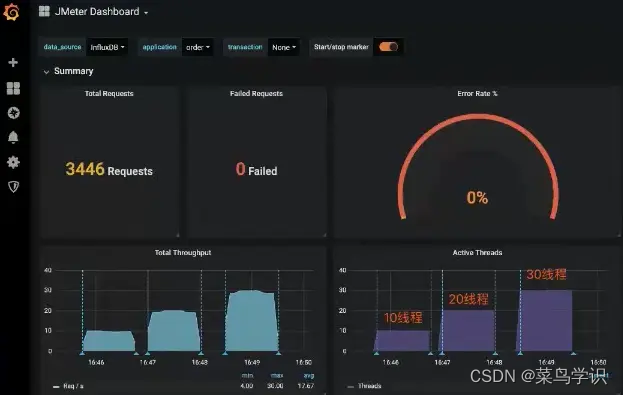
JMeter添加后端监听器

压测后数据监控

如果性能监控平台与JMeter报告结果有差异,要以JMeter的结果为准,因为性能监控平台本身也会消耗资源,而且不是实时刷新
压测实施计划
-
制定压测策略不同的并发数:10,20,50,100,200,400,.....
-
单个并发数压测时长:1分钟
-
参考压测报告,记录结果运行自动压测简化操作
-
测试期望结果
- 验证能够支撑多大并发数,峰值数
- 验证错误率,定义可接受范围,<=0.1% or <=0.5% or must = 0%
-
系统性能点
- Demo:运行压测,收集数据
- 并发数设定:10,20,30,40,50,
- 分析合理最大并发数,使用合理最大并发数,进行长时压测验证结论
- 注意事项:
- 如果高并发出错率偏高,可以尝试降低并发数,以获取更合理的结果
- 实际工作过程中,发压机与被压测应用需要运行在不同机器上
- 通过对比并发数与流量还有错误率的关系,找到一个最合理的系统可支撑最大并发数
- 可以先把并发数往大增加,压出问题之后,再逐步减少
- 找到系统可以支持的最合理最大并发数
- Demo-逐步增加并发数的压测过程,压测报告解读,记录数据分析结果
压测结果
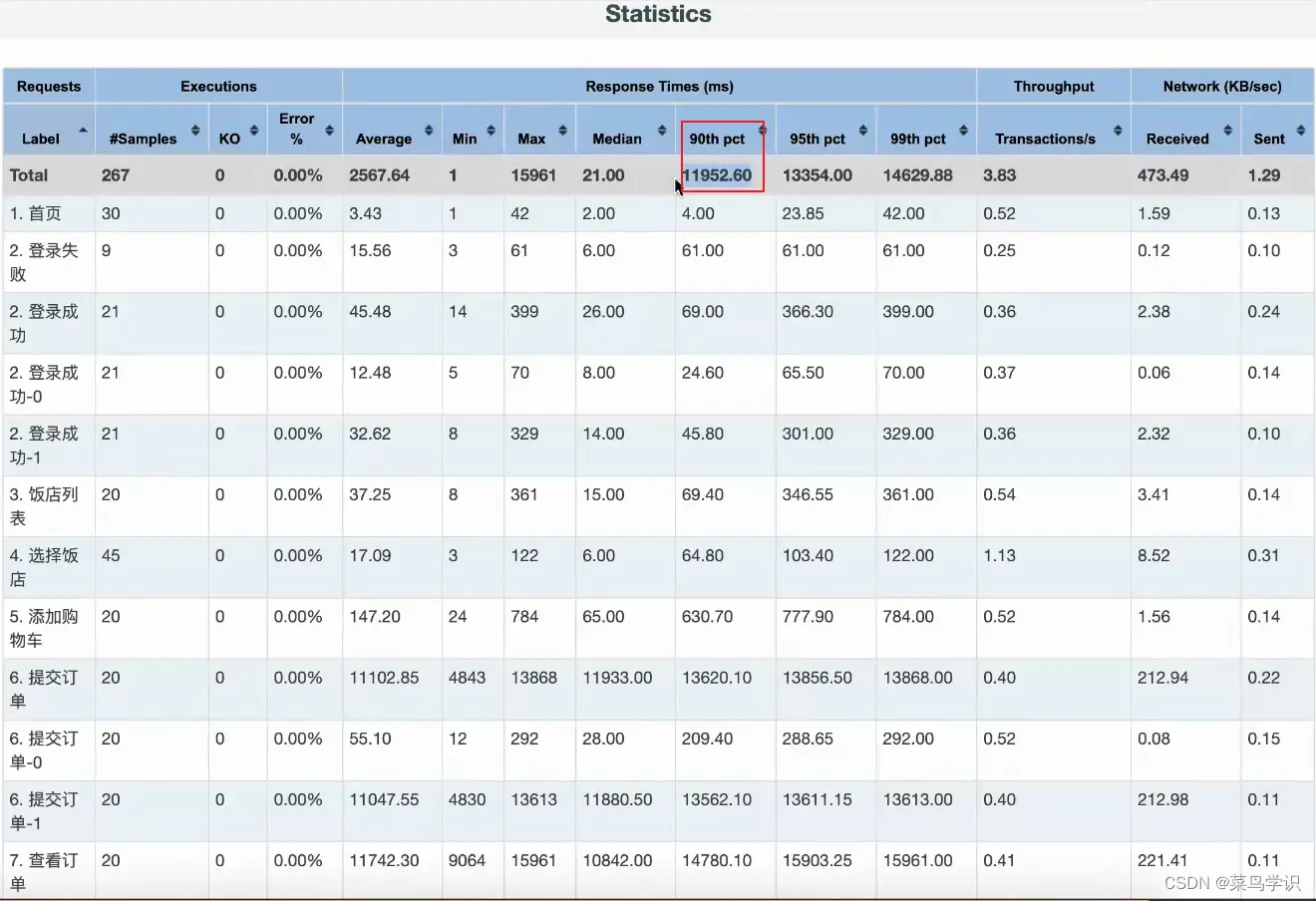
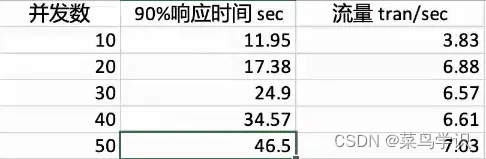
- 分析结果,最优并发数在10-20之间,然后再细化脚本中的并发数为(10 12 14 16 18)
小结
- 并发数设定原则:从小->大,先粗粒度,再细化
- 应用系统的流量与并发数的对应关系
- 错误率与并发数的关系
- 系统合理能力的判断与验证
- 性能监控压测运行状态