前言
我看了一下,网上关于 LinkBomb 的题解不是很多,LinkBomb 不是 CSAPP 目前大纲的内容,大多数都是写的 LinkLab。如果你做的作业内容是要求每关输出学号,那么你就是跟我一样的 LinkBomb 的实验(需要注意的是,不同文件题号顺序可能和我的不一样,但是题型是类似的)。
LinkBomb 的解法还是有很多的,写的过程中我也参考了一些已有的资源。此时,你应该已经学习了 ELF 文件的重定位和链接的知识,下面将向大家分享一下我自己做题时一些粗鄙、笨拙的技巧吧。
在这里我还是要感谢所有帮助过我学习的朋友们。

一、实验目的
通过对一组可重定位目标文件的分析和修改,将其链接成为可正确运行的程序,加深对理论课程中关于目标文件(ELF)的基本结构组成、程序链接过程(符号解析与重定位)等基本概念的理解。
二、实验原理
1.ELF 目标文件的组成结构:节、段、符号表、重定位记录等。
2.程序的链接过程:符号解析,重定位。
三、实验步骤
1.在实验的每一阶段 n(n=1,2,3,4,5…),修改相应可重定位二进制目标模块 phase[n].o 后,使用如下命令链接生成可执行程序 linkbomb:$ gcc -no-pie -o linkbomb main.o phase[n].o(有些阶段还要求输入额外的 .o 模块)。
2.运行链接生成的可执行程序 linkbomb ,应输出符合各阶段要求的字符串:
$ ./linkbomb
$ 123456789 (具体应输出的字符串需要查看 outputs.txt 说明文档,前几关都是学号)
3.提交修改之后的可重定位目标文件,撰写实验报告。
四、基础准备
4.1 实验阶段
实验包含 6 个阶段,各阶段考察程序链接与 ELF 文件的不同方面知识:
- 阶段1:静态数据与 ELF 数据节
- 阶段2:指令与 ELF 代码节
- 阶段3:符号解析
- 阶段4:switch 语句与重定位
- 阶段5:可重定位目标文件
- 阶段6:位置无关代码
4.2 readelf 工具
readelf 工具可以读取 ELF 格式二进制目标文件中的各方面信息并打印输出,如节(节名、偏移量及其中数据等)、符号表、字符串表、重定位记录等。
常用命令行格式:readelf<options> elf-file(s)
Options(部分):
- -a –all 等同于同时使用:-h -l -S -s -r -d -V -A -I
- -h --file-header 显示ELF文件头
- -l --program-headers 显示程序头
- -S --section-headers 显示节头
- -t --section-details 显示节详细信息
- -s --syms 显示符号表
- -r --relocs 显示重定位信息
- -x --hex-dump=<number|name> 字节形式显示输出<number|name>指定节的内容
- -p --string-dump=<number|name> 以字符串形式显示输出<number|name>指定节的内容
- -R --relocated-dump=<number|name> 以重定位后的字节形式显示输出<number|name>指定节内容
4.3 objdump 工具
objdump 工具可以用于反汇编二进制目标文件中包含的机器指令,获得对应的汇编指令供分析。
主要用到的指令:
- objdump -dr prog > asm.txt
- -- 对 prog 程序的代码段和重定位节进行反汇编,把反汇编结果保存于文本文件 asm.txt 中。
- objdump -t prog
- -- 打印 prog 程序的符号表,其中包含 prog 中所有函数、全局变量的名称和存储地址。
4.4 十六进制编辑器
十六进制编辑器可以用 HxD(这个是教学时推荐的),我个人推荐 WinHex(功能强大)。
十六进制编辑器是方便于我们修改二进制文件的,注意:这个两款软件都是 Windows 系统环境下运行的。
五、题解和心得
在第一关进行前,我们首先浏览一下我们拿到的文件:
一共有 8 个文件,其中 .o 文件有 7 个,有一个名为 outputs.txt 的输出格式说明文档。
打开说明文档,可以看到前几关都是要求输出自己的学号(11 位,我看到目前教程中的学号都是 9 位,我们的学号多出来的几位会导致对求解时一些方法的差异,为了避免一些问题,我将学号部分打码了,大家看教程时候可能看到学号改成其他数字,见谅,当作 11 位学号来看就行):

接下来,我们正式开始我们每一关的求解。
5.1 phase 1
关卡内容:修改二进制可重定位目标文件“phase1.o”的数据节内容(不允许修改其他节),使其与main.o链接后运行时输出自己的学号。以下是完成题解后,用于测试的样例指令:
$ gcc -no-pie –o linkbomb main.ophase1.o
$ ./linkbomb
学号
相关课程知识:ELF目标文件组成、静态数据的存储与访问。
实验要点:
(1)在 main 函数中调用 do_phase 函数;
(2)在 do_phase 函数中,将 puts 函数的参数所指向的字符串内容替换为学号的 ASCII 码;
(3)最后链接 mian.o 和 phase1.o ,并实现打印学号。
实验过程:
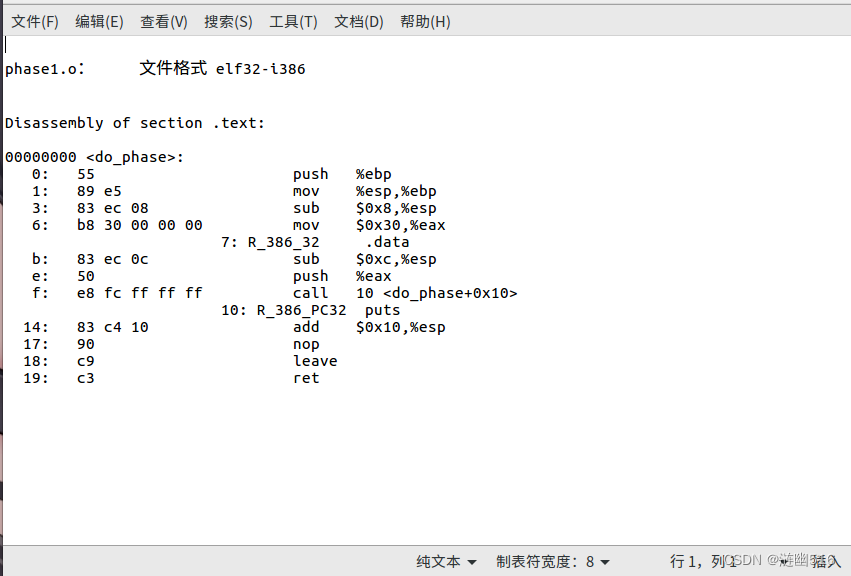
1. 首先,我们对 phase1. o 进行反汇编。使用下面的指令:
objdump -dr phase1.o > asm-phase1.txt这条指令会将 phase1.o 的反汇编指令(-dr 表示包含重定位信息)保存到 asm-phase1.txt 文本文档中。
下面,我们打开该文档即可看到 phase1.o 的汇编代码:
接下来,我们分析指令中重要的部分(部分插图可能采用我当初报告中重新截出来的图片,所以清晰度可能受到影响):
这处的指令只有两处重定位,这也是我们需要分析的部分。首先是 call 它调用了 puts 函数,这是被反汇编工具 objdump 分析出来的,当然我们知道自己也可以手动分析出来。puts 前面的 push %eax 就是要将它需要的参数压栈,而我们就要找最近的 %eax 值了对吧?也就是所谓的“找出是谁修改了 %eax 寄存器”。显然,最近的是第六个字节处的 mov 指令,该指令将 .data 节偏移 0x30 计算得到的地址作为立即数传递给了 %eax,也就是说,链接后,这里 b8 后面的 4 字节(32位)为地址。
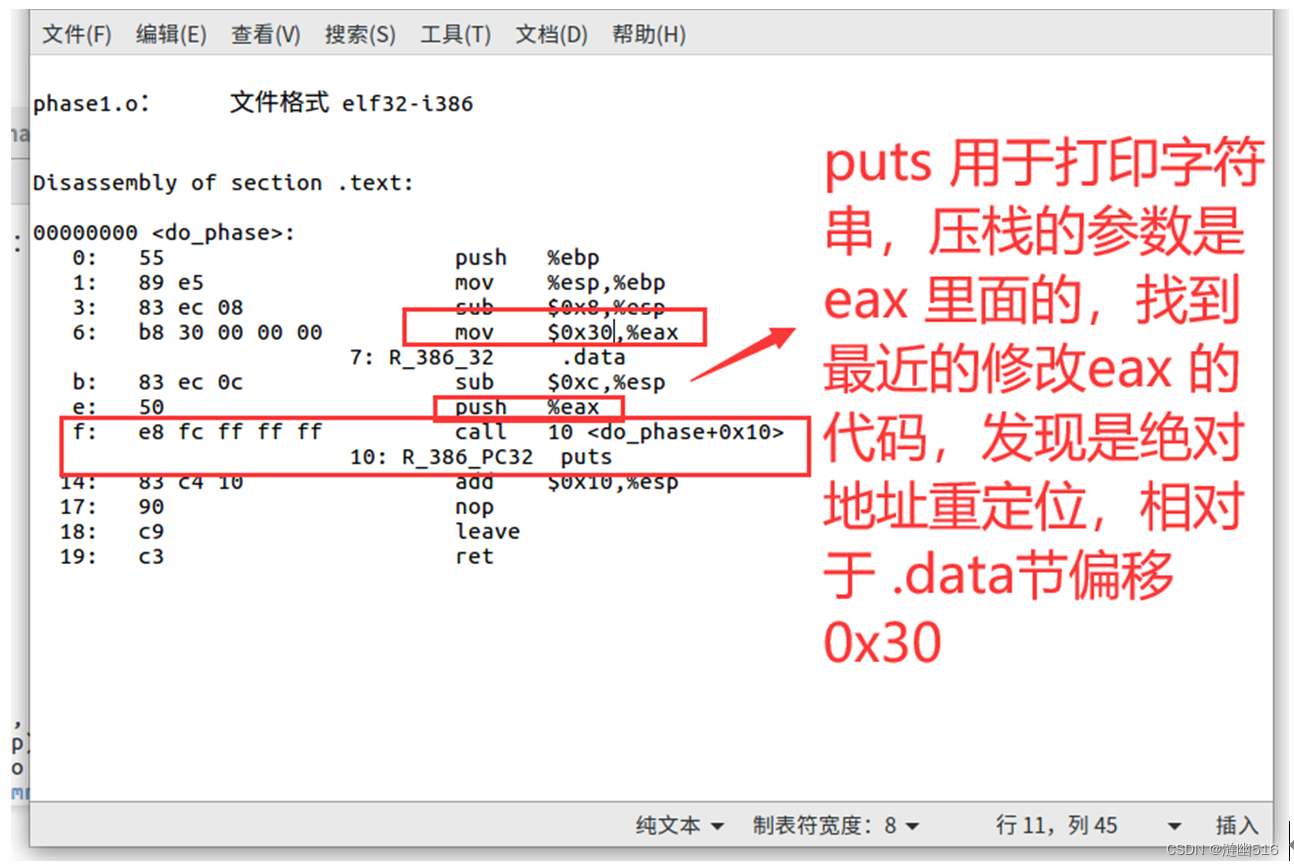
mov 处的重定位属于 R_386_32 重定位,下面是关于该重定位的解释:
R_386_32 直接地址重定位
重定位修正方法为: S + A
具体含义:
A: 保存在修正位置的值
S: 符号的实际地址
也就是说,我们需要确定 .data 节的起始偏移(S),用这个偏移加上原来需要重定位的地方存在的值(A),就得到了需要重定位的符号所在的地址了。
这里我们的 A = 0x30 所以我们的最终重写的地址应该是 0x30 + .data 节起始地址。
利用 readelf 查看 phase1.o 的节头表,查找 .data 节在文件中的偏移量:
readelf -S phase1.o得到的结果如下:
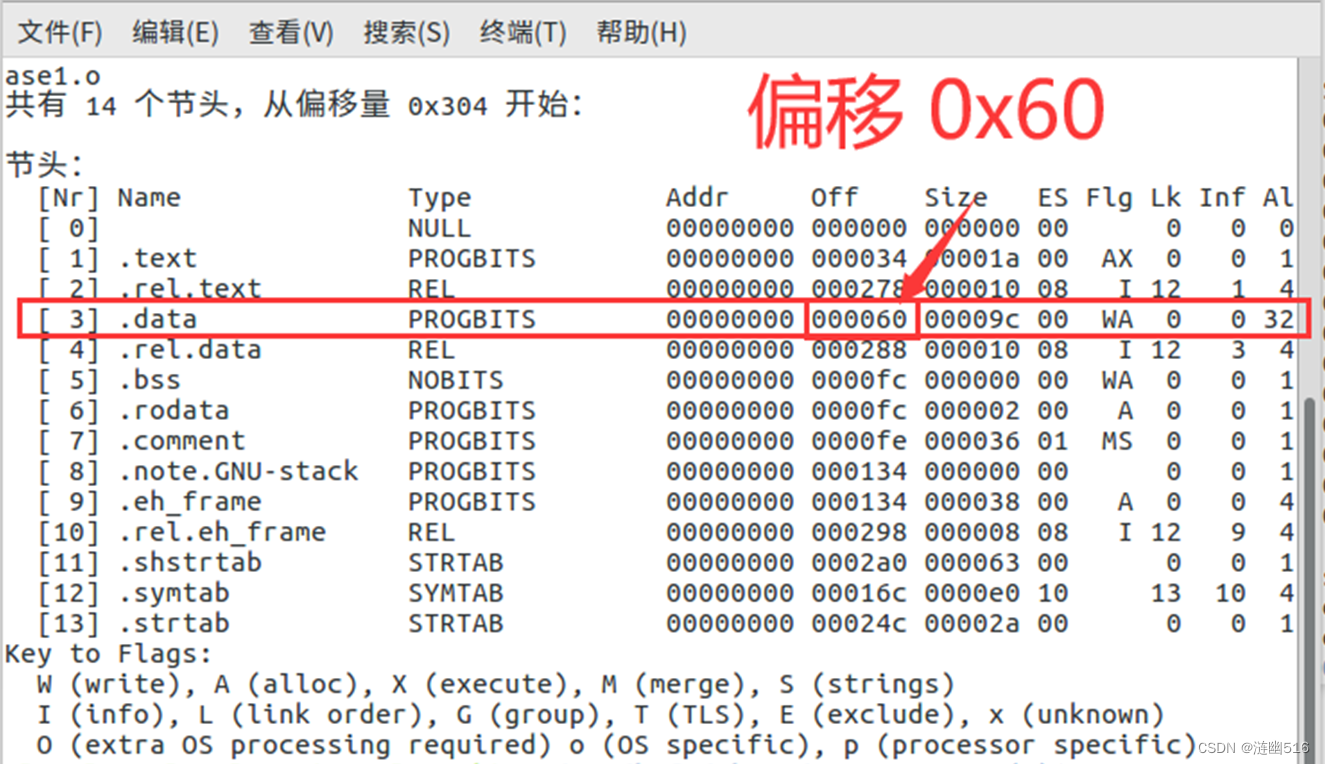
可见 .data 节的偏移为 0x60。
所以 pAddr = 0x60 + 0x30 = 0x90 ,我们需要在进制文本编辑器 HxD 里面打开可重定位文件 phase1.o ,并修改从偏移 0x90 开始之后的12位字符串为学号(包含一个字节的00字符串终止符)就行。
用 HxD 打开 phase1.o,如下图所示,点击菜单栏中的“搜索”,点击下拉栏中的“跳转”选项:
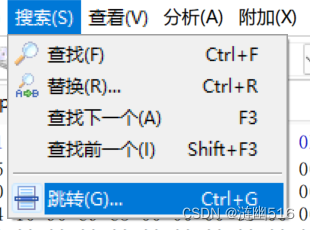
在打开的窗口选择十六进制地址相对开始地址的搜索方式,并输入 90:

可以看到窗口中已经定位到指定的位置(定位的方框很不明显,一不小心就改错位置了,还没有保存后的撤销功能。这是一个槽点,还是建议用 WinHex):

直接修改该位置,但需要注意的是,学号作为字符串有 11+1 位,最后一位为 00 表示字符串结尾的 \0 符号(否则 puts 会一直向后输出直到第一个 00 出现,结果不对,其次不安全)。确保无误后按 Ctrl + S 保存修改即可:(警告:这里一定细心找和填写,但用 WinHex 的无需顾虑)

然后,回到虚拟机,链接文件并运行,所用指令如下:
$ gcc -no-pie –o linkbomb1 main.ophase1.o
$ ./linkbomb1
可以看到返回值正确:

至此,第一关成功通关!
附1:phase1.o 反汇编结果:
00000000 <do_phase>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 83 ec 08 sub $0x8,%esp
6: b8 30 00 00 00 mov $0x30,%eax
7: R_386_32 .data
b: 83 ec 0c sub $0xc,%esp
e: 50 push %eax
f: e8 fc ff ff ff call 10 <do_phase+0x10>
10: R_386_PC32 puts
14: 83 c4 10 add $0x10,%esp
17: 90 nop
18: c9 leave
19: c3 ret
5.2 phase 2
首先,对 phase2.o 进行反汇编,用这个指令:objdump -dr phase2.o > asm-phase2.txt 。
在 asm-phase2.txt 中,我们会得到三个函数:
00000000 <lWsUtgeKct>
00000072 <hmHxHHjZ>
000000a2 <do_phase >
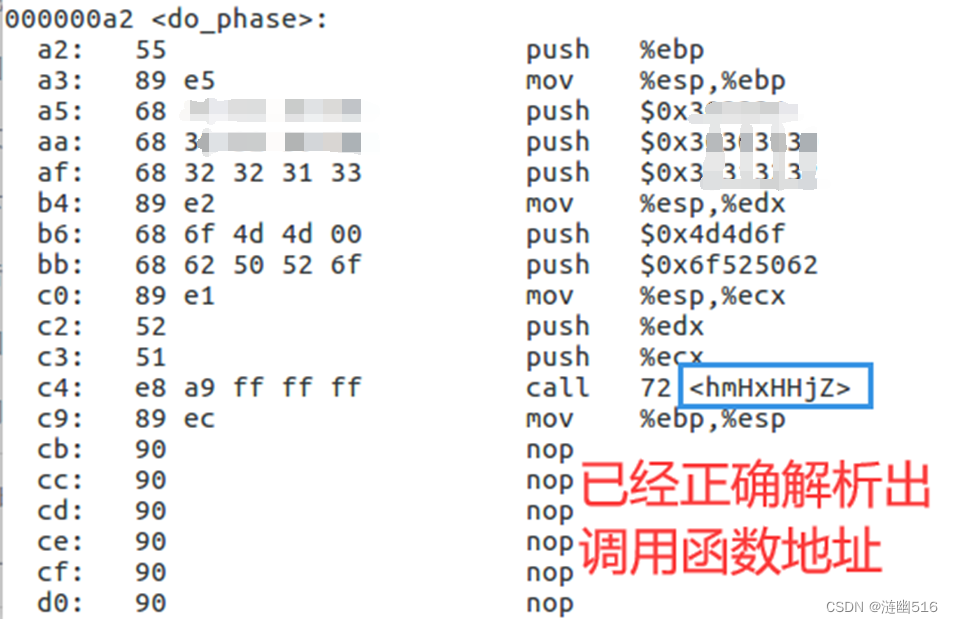
我们发现 do_phase 函数里面除了初始化保存栈指针和返回前弹栈,中间部分有很多 nop(不执行操作的占位指令),那么很显然,这个阶段是要我们填充 do_phase 函数中的指令(修改 phase3.o 的代码节),从而打印出学号。
然后就是两个函数名非常奇怪的函数,要想最后打印处学号,我们可以找到调用 puts 的一个函数,显然 “hmHxHHjZ” 符合要求。
我们来看一下这个函数的汇编:
00000072 <hmHxHHjZ>:
72: push %ebp
73: mov %esp,%ebp
75: sub $0x8,%esp
78: sub $0x8,%esp
7b: 68 02 00 00 00 push $0x2
7c: R_386_32 .rodata(显然这是一个字符串的地址)
80: pushl 0x8(%ebp)
83: e8 fc ff ff ff call 84 <hmHxHHjZ+0x12>
84: R_386_PC32 strcmp(和第一个实参比较)
88: 83 c4 10 add $0x10,%esp
8b: test %eax,%eax (如果不相等,则跳转到返回处,注意偏移 2d 就是 nop 处)
8d: jne 9f <hmHxHHjZ+0x2d>
8f: sub $0xc,%esp
92: pushl 0xc(%ebp) (第二个实参的表示的指针值入栈,用 puts 输出)
95: e8 fc ff ff ff call 96 <hmHxHHjZ+0x24>
96: R_386_PC32 puts (这个函数可以构造用于输出学号字符串)
9a: 83 c4 10 add $0x10,%esp
9d: jmp a0 <hmHxHHjZ+0x2e>
9f: nop
a0: leave
a1: ret
显然这个函数有两个参数,函数内做了两件事:第一,比较第一个实参指向的字符串是否等于 .rodata 上偏移 0x02 处起始的 TOKEN 字符串(后文把该特殊字符串称为调用该函数的一个令牌,即 token,有正确的令牌才会执行正常功能),相等才能进行第二件工作;第二,调用 puts 将第二个参数指向的字符串打印出来。
我们只需要精心构造 do_phase 的汇编指令序列,首先准备好校验码字符串(后文称为:TOKEN)和学号字符串 (后文称为:MYID) 的指针地址,然后 call <hmHxHHjZ> 即可。下面分析如何构造这个函数。
(一)分析 TOKEN 字符串
首先是要知道 TOKEN 字符串的内容,这里是一个和第一关一样的直接地址重定位(R_386_32),所以不是很难。
第一步,利用 readelf 查看 phase2.o 的节头表,查找.rodata节在文件中的偏移量
readelf -S phase2.o结果如下图:

于是,在 phase2.o 中,TOKEN 字符串地址为 0x124 + 0x02 = 0x126。
用 HxD 查看偏移 0x126 ,由于字符串以第一个 0x00 作为结尾,该字符串编码如下图圈出的部分所示:

按照字符顺序为:62 50 52 6F 6F 4D 4D 00。
但是,按照 x86 数据传输指令字长限制,我们一次 mov 或者 push 只能准备4个字符,这里有 8 个字符(有效字符有 7 个字符),所以我们需要使用两次数据传递指令,并且需要使用小端序编写立即数,这里推荐只用 push 指令(经过计算 mov 占用更多字节,学号和验证码加上去,超过了 do_phase 的 nop 区域长度,会比较麻烦):
push $0x004d4d6f
push $0x6f525062
其次,我们需要将学号的 ASCII 也同样 push 进去,这个查表即可(高位都是 3,低位和十进制数字相对应):

我的学号通过三条指令(11+1=12字节,需要三次 push)来完成入栈操作:
push $0x003x3x3x
push $0x303x3x30
push $0x3x3x3x32
注释:上面带有 x 的地方原本是数字,被我改了。
(二)分析 call <hmHxHHjZ>
我们知道 call 指令的重定位的类型为:R_386_PC32 ,即相对地址重定位。它的计算公式如下:
call 的函数地址 = ADDR(PC) + Offest
= call 指令偏移一位的地址 + 4 + 重定位前 call 指令(E8)后面填写的初始值。
=ADDR(hmHxHHjZ) – ((ADDR(.text) + r_offest) - init)
其中,对于 call 指令,r_offest = -4。
call 指令的机器码后面一个字节填写的初始值 init 是重定位要用到的偏移量。
于是,我们只要找到两个量,一个是 call 函数的地址( hmHxHHjZ 的虚拟地址),另一个是 call 指令下一条指令的第一个字节的地址,做差就可以得到偏移量。
但这个“call 指令的下一条指令的地址( PC 对应的值)”我们暂时确定不了,所以我们给 call 指令的操作数先随便写个值(只要保证 call 操作数的机器码大小为 4 字节即可),把指令序列写完之后再用 HxD 调整这个值。
在写汇编代码前,一个关键点是我们需要仔细地维护 do_phase 函数的栈帧。我们注意到 do_phase 函数在 return 之前用 pop %ebp 代替了 leave 指令,这成立的条件是 %esp 和 %ebp 的值相同。但是这次我们会改动 %esp,所以我们需要在汇编指令的最后多加一条指令 mov %ebp,%esp(不这么做就会引起“段错误”)。
初步测试用的汇编序列如下:
push $0x303x3x
push $0x303x3x30
push $0x3x3x3x32 (前三句指令将学号压栈)
mov %esp,%edx (edx 指向学号的首地址)
push $0x4d4d6f
push $0x6f525062 (后两句把验证码字符串压栈)
mov %esp,%ecx (ecx 指向验证码字符串首地址)
push %edx (准备调用参数)
push %ecx
call 0xfffffffd (这里是测试值为-3,属于有符号数)
mov %ebp,%esp (连同后面的pop指令,实现恢复调用者寄存器的值)
需要注意编译器和汇编编程指令对 call 的不同解释,这可能导致我们的代码出错。
我们编写的汇编代码的 call 指令后面的值是相对于 E8 之后一个字符所在地址的偏移量,并不是编译器编译得到的机器码。编译后得到的汇编指令后地址的值首先要求必须是小端序(程序是小端序的),其次编译后得到的汇编指令中机器码 e8 后面的四字节填充相对于下一条指令的偏移量,是有符号数。我们知道这里的机器码需要对地址多减去 4 ,这条指令的机器码也就是 E8 F9 FF FF FF,初始值变成 0xfffffff9 了。
首先,用 Linux 的文本编辑器 Vim 将汇编代码写入到后缀名为 .s 的文档中,然后用 gcc 把do_phase2.s 文件转换为 do_phase2.o:
gcc -c do_phase2.s -o do_phase2.o通过 objdump -dr 反编译的结果和我们的想法一样, fd 变成 f9 了:
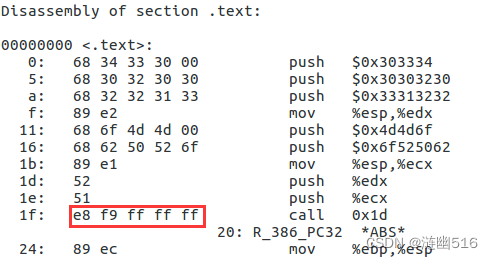
这就告诉我们,之后在填写 call 后面的数字时候就需要注意了。
接下来就是如何将机器码写入 do_phase 对应位置上去了。
通过 readelf -s phase2.o 指令来查看符号表(注意是小写的 s 不是大写):

这里就需要我们会认读符号表了:
- Type 表示符号的类型:NOTYPE(未知类型),OBJECT(数据对象,变量),FUNC(函数),SECTION(段 必定是local的);
- Bind 表示符号的绑定信息:LOCAL(局部符号,外部不可见),GLOBAL(全局符号,外部可见),WEAK(弱符号);
- Ndx 表示符号所在段:如果符号定义在本 elf 中,表示该符号所在段在段表中下标,比如 do_phase 函数在 .text 中,下标为 1;
- ABS 表示一个绝对值,COM 表示一个 COMMON 块符号,未初始化的全局符号,UNDEF 表示该符号定义不在本 elf 文件中;
- Value,一般情况表示符号在所在段中的偏移,比如 do_phase 在 .text 中的偏移为 0xa2;
- 在可执行文件中,value 表示符号的虚拟地址,这个虚拟地址对动态链接器十分有用;
- Vis 暂未使用;
- Size 表示符号大小,如果是数据类型,表示类型占用字节数。如果是函数表示函数内容所占用字节。
从符号表里面可以看出 do_phase 函数位于 .text 节(段),节(段)内偏移量为 0xa2.
通过 readelf -S phase2.o 查看节(段)头表:

由此,可以知道 do_phase 函数的入口偏移地址为 0x34 + 0xa2 = 0xd6。(在 phase2.o 中的位置)
而当我们确定了位置之后,就可以试着将测试代码的机器码逐一写入到 do_phase 的对应位置上:
需要注意的是,我们需要保留开头三个字节的指令序列,这是用于恢复调用者寄存器用的。

首先在 HxD 中打开 phase2.o ,如下图所示,使用搜索功能定位函数入口点 0xD6 :

修改好的代码段如下所示:

然后,用 objdump -d 反汇编 phase2.o,我们根据反汇编的栈帧的实际情况确定 call 调用真正的偏移量。
首先,记住目标函数的偏移,这里是 0x72:

随后,看我们的 do_phase 函数:

可以发现,call 的下一条指令是 0xc9 用 0x72 – 0xc9 结果是 -87,转为浮点数表示就是 0xFFFFFFA9。
最后,我们总结汇编代码的编写方法:
精心构造 do_phase 的栈帧,准备两个实参,一个指向学号字符串,一个指向验证码字符串,然后采用 call 指令(PC 相对寻址)的方式完成对内部包含 puts 的函数的调用。打印出我们需要的学号字符串。
上文中,如果要编写汇编代码(do_phase2.s),应如下所示:
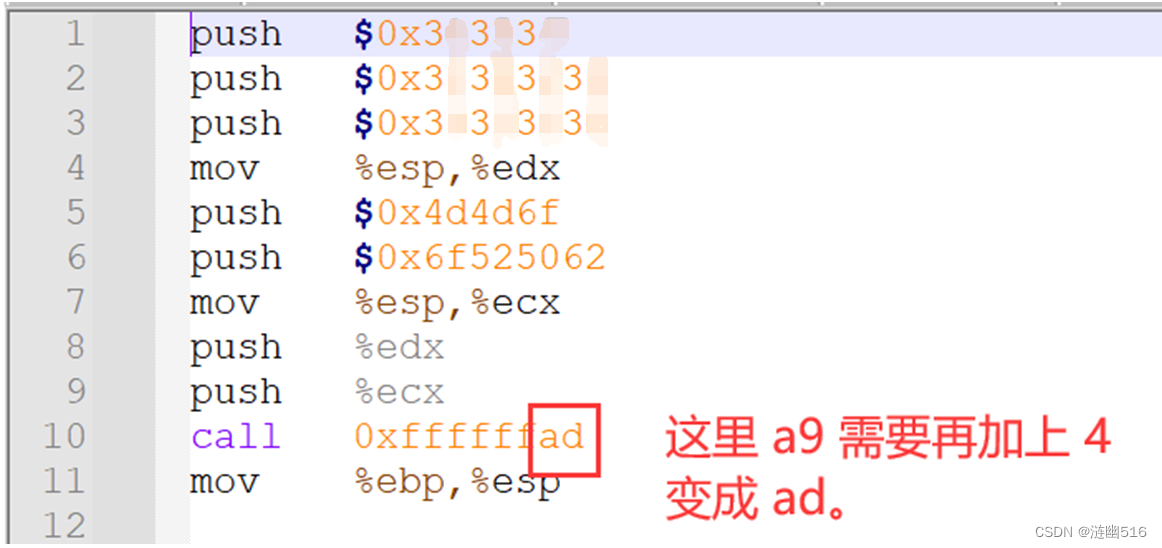
机器码如图(通过将 gcc -c do_phase2.s -o do_phase2.o 编译后的 .o 文件重新反汇编 objdump 得到):
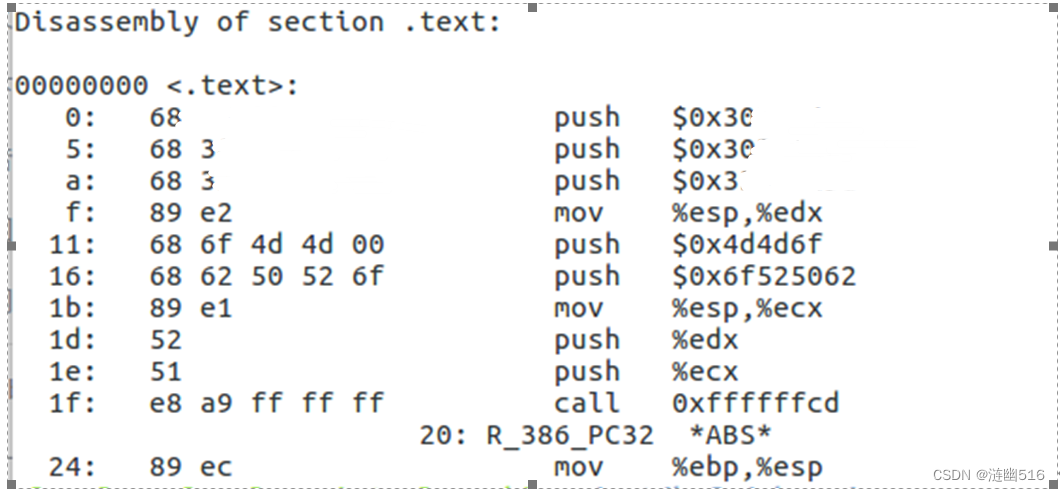
由于前面已经填入过指令(如果没有就全部填写),我们只要把之前的 E8 后面的值修改成算好的正确的值并保存即可:

重新 objdump -d phase2.o:
接下来就是链接和运行测试了:
gcc -no-pie -o linkbomb2 main.o phase2.o
./linkbomb2
运行效果如图:

可以看出已经通过了第二关。
但是根据 IA-32 的对齐规范,栈帧大小必须是16 的整数倍,上文汇编代码并没有满足指令字节对齐的要求,这会造成效率下降和潜在的程序错误,经过修改后的汇编代码如下:
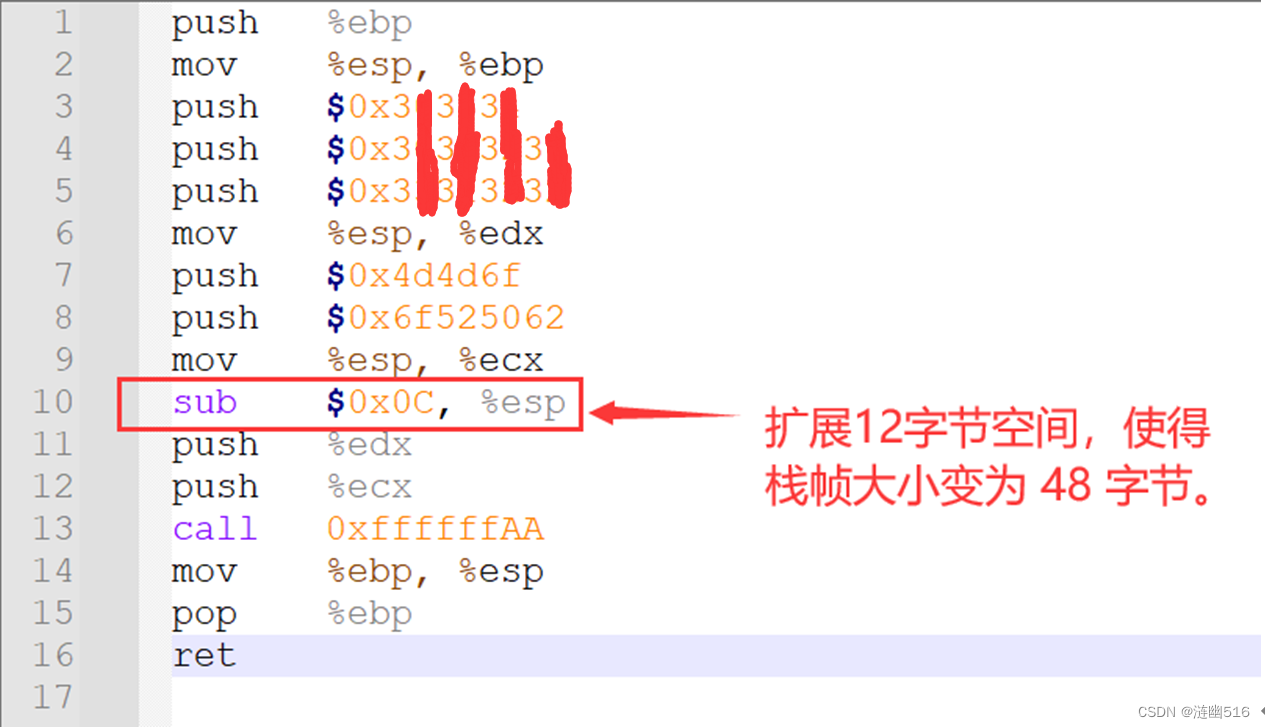
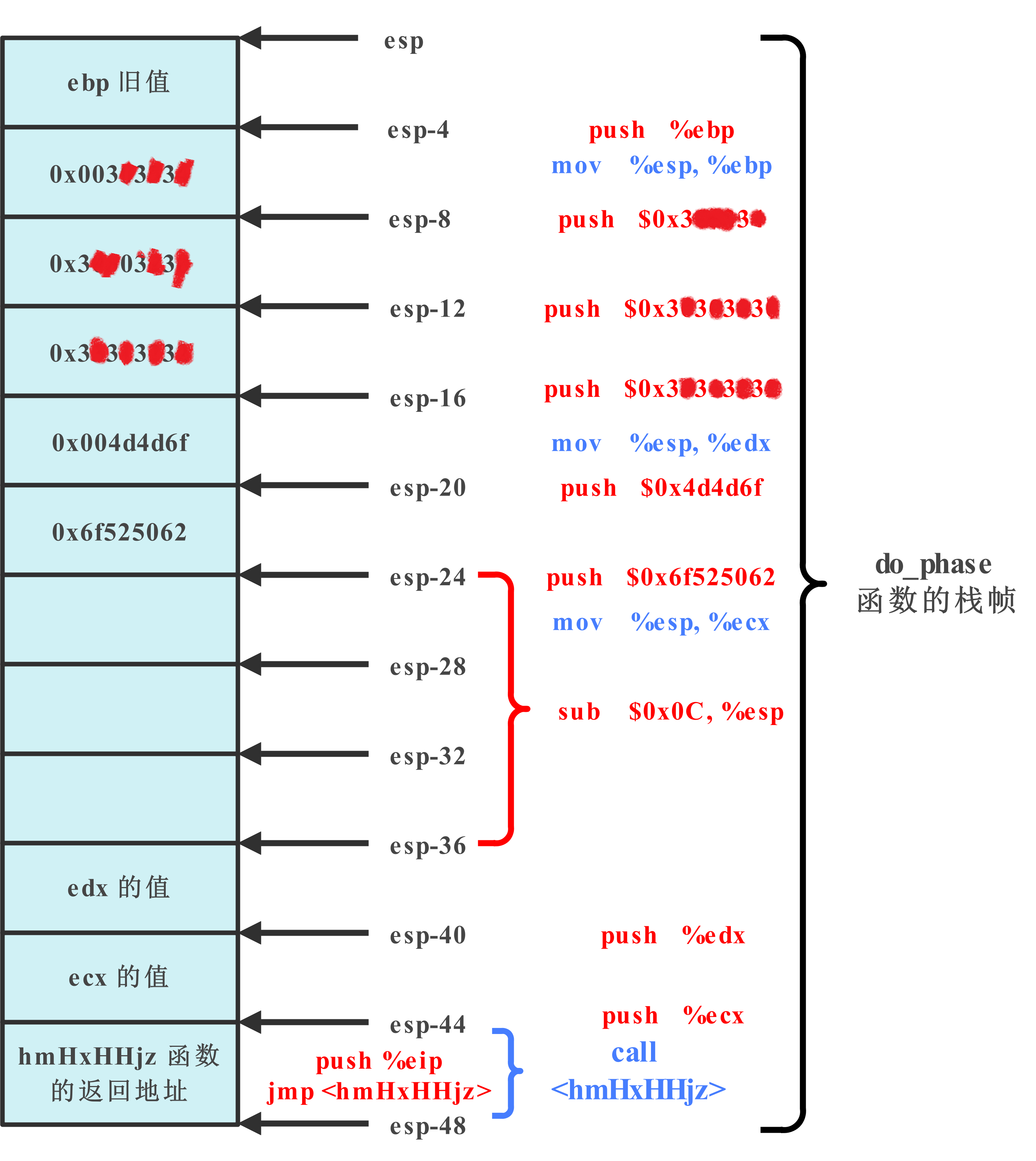
相比之前的代码,我们在 call 指令之前使用 sub 指令在栈上扩展了 12 个字节的空闲空间,然后再进行参数压栈和 call 调用,经计算,8次 push 花费了32个字节,sub 指令扩展了 12 个字节,call 指令压入4字节的返回地址, do_phase 函数的栈帧一共使用了 48 字节的栈空间,而48是16的3倍,符合IA - 32的规范要求。
绘制的栈帧结构如图:
反汇编之后的结果如下:
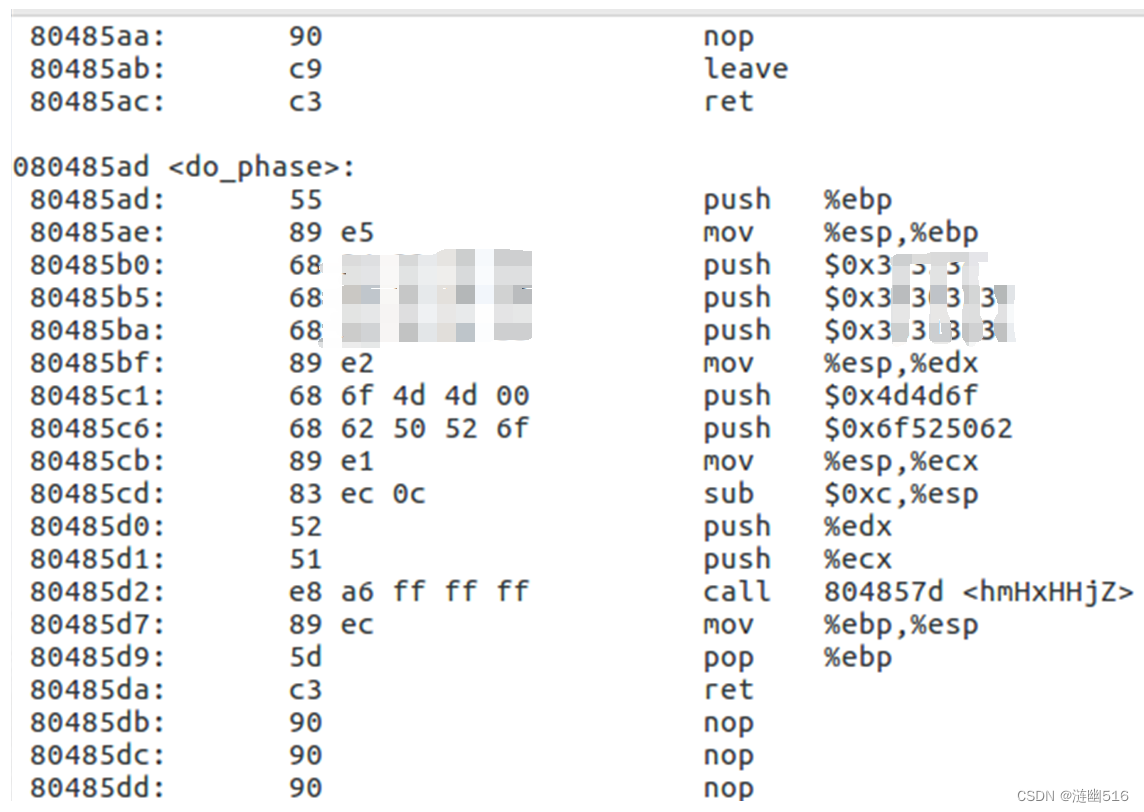
解析正确无误,第二关正式结束。
5.3 phase 3
汇编代码简析:do_phase 函数的汇编主要做了三件事情,第一个是创建栈帧用于存放字符串,第二是初始化一个计数器(放在栈上,没开编译优化,所以不是在寄存器上),第三是一个 for 循环计算地址,访问数据并更新之前分配的栈帧(最后还是又放到了寄存器上,总之没有优化就是浪费了在栈上的访存时间),循环采用条件跳转,每次读取栈上的计数器是否大于 10(0xa),每轮循环结束前其实会把这个值增加1(先读取后递增),也就是说读了11次。这恰好是学号长度。
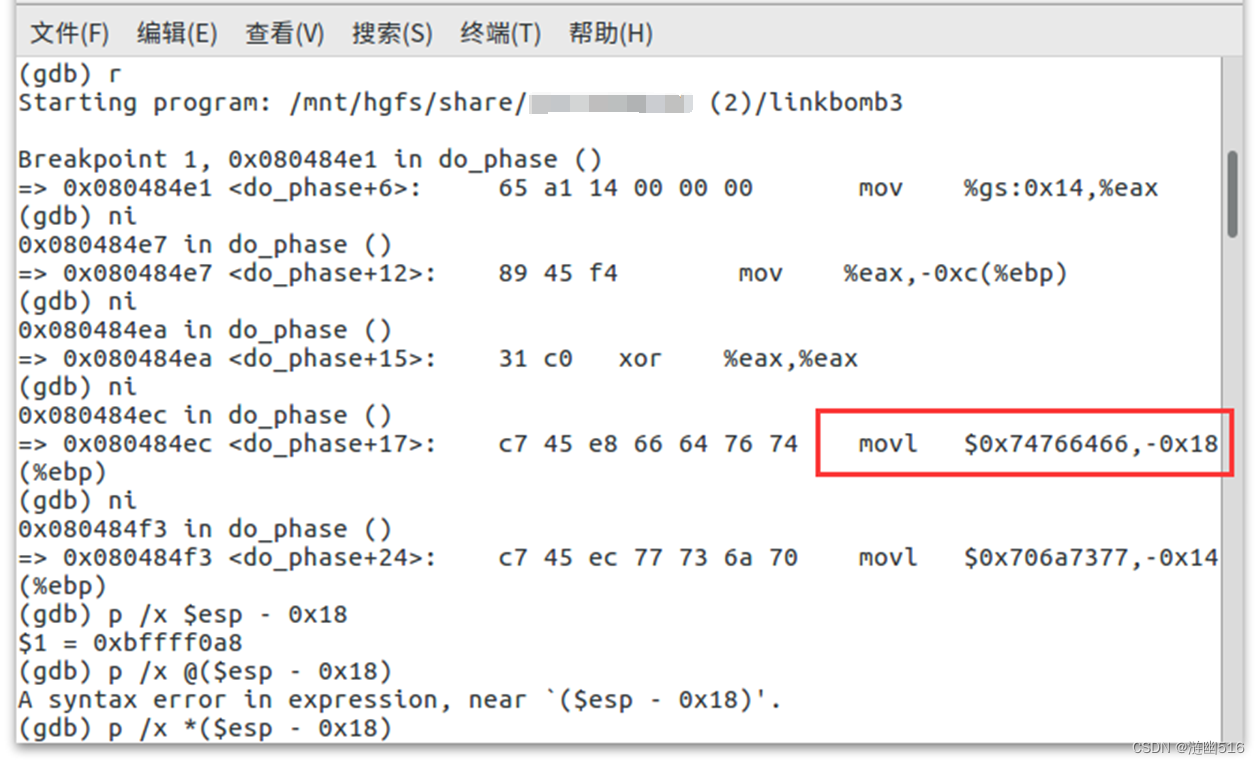
忽略前面预分配栈帧和堆栈溢出保护的代码,直接从 0x80484ec 处开始看:
movl $0x74766466,-0x18(%ebp)
movl $0x706a7377,-0x14(%ebp)
movl $0x006b676c,-0x10(%ebp)
movl $0x0,-0x1c(%ebp)
前三句是将数值 0x74766466 等分别存储在相对于栈底基址(bp)指针 -0x18、-0x14 和 -0x10 的位置。这里就是初始化了一个字符串,用于后面计算偏移逻辑,空间长度恰好为 12 ,结尾以高位 00 结束。(经查看 elf 信息知道程序是小端序,符合高位 00 是字符串结束符的定义)。
最后一句,是将数值 0 存储在位于基址 -0x1c 的位置,结合下文看,这里就是用作循环计数器。
然后就是无条件跳转到地址 0x8048532 ,这是一个 for 循环开始的地方。
jmp 8048532 <do_phase+0x57>
下面这段就是循环判断语句了:
8048532: mov -0x1c(%ebp),%eax ; 将 ebp-0x1c 处的内容(也就是之前的计数器,初始化为 0 )加载到 eax 寄存器中.
cmp $0xa,%eax ; 将 eax 与 10 进行比较。
jbe 804850a <do_phase+0x2f> ; 当小于等于 10 时,跳转到地址 0x804850a ,继续循环。
下面就是步入循环:
1)804850a: lea -0x18(%ebp),%edx
lea指令将指向计算得到的 ebp-0x18 处的内存地址存放到 edx 寄存器中,现在 edx 是有效地址值。
2)mov -0x1c(%ebp),%eax
将位于基址 -0x1c 处的内容(循环计数器,也就是数组的索引)放到 eax 寄存器中。
3)add %edx,%eax
寄存器相加,现在 eax 里面是首地址加上索引偏移的地址。
4)movzbl (%eax),%eax
将eax指定地址处的字节(0 拓展到 32 位)加载到 eax 寄存器。
5)movzbl %al,%eax
将 eax 的低8位拓展为 32 位,存储在 eax 寄存器中,防止高位有垃圾值。
6)这是一个绝对地址重定位,也是本题的关键点,重定位前的地址现在是空 0x0,后面用于映射我们需要的字符串的地址。
0f b6 80 00 00 00 00 movzbl 0x0(%eax),%eax
40: R_386_32 jFohjcNmvs
指令的直接作用为:将指定偏移量加上 eax 的结果作为地址,在该地址获取一个字节(0 拓展为 32 位),并存储在 eax 寄存器中。
7)movsbl %al,%eax
将低 8 位拓展为 32 位,并带有符号扩展,已然是保护地址值,防止不足位数造成的地址的高位(小端序转换后)垃圾值污染,由于是偏移量,所以编译器把它写成有符号的。
看到这里就可暂时不继续往下看了,先去确定这个重定位的符号信息。
符号名称为“jFohjcNmvs”(每个人不同)。
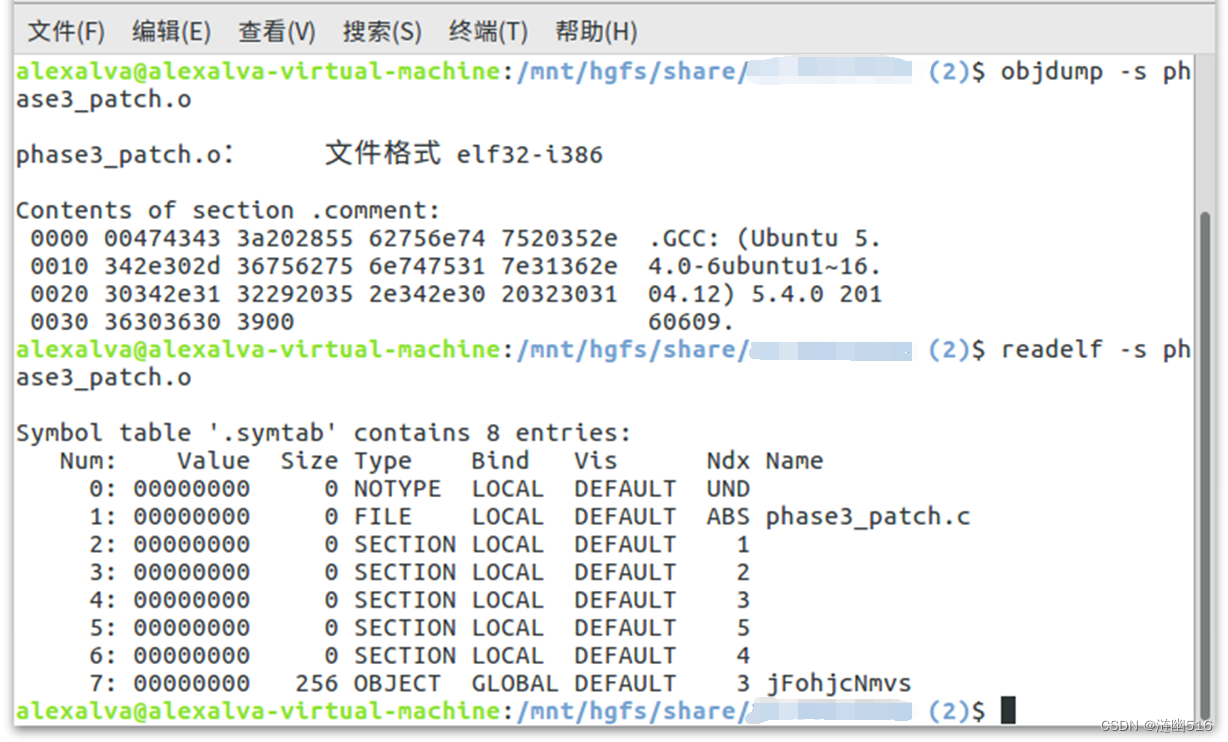
输入 readelf -s phase3.o 指令,得到符号表信息:

可以看到他是一个弱定义,所以可以采用补丁一个可重定位文件,里面有强定义,就可以链接时覆盖这里的定义。并且这里的数组大小为 256(十进制)。
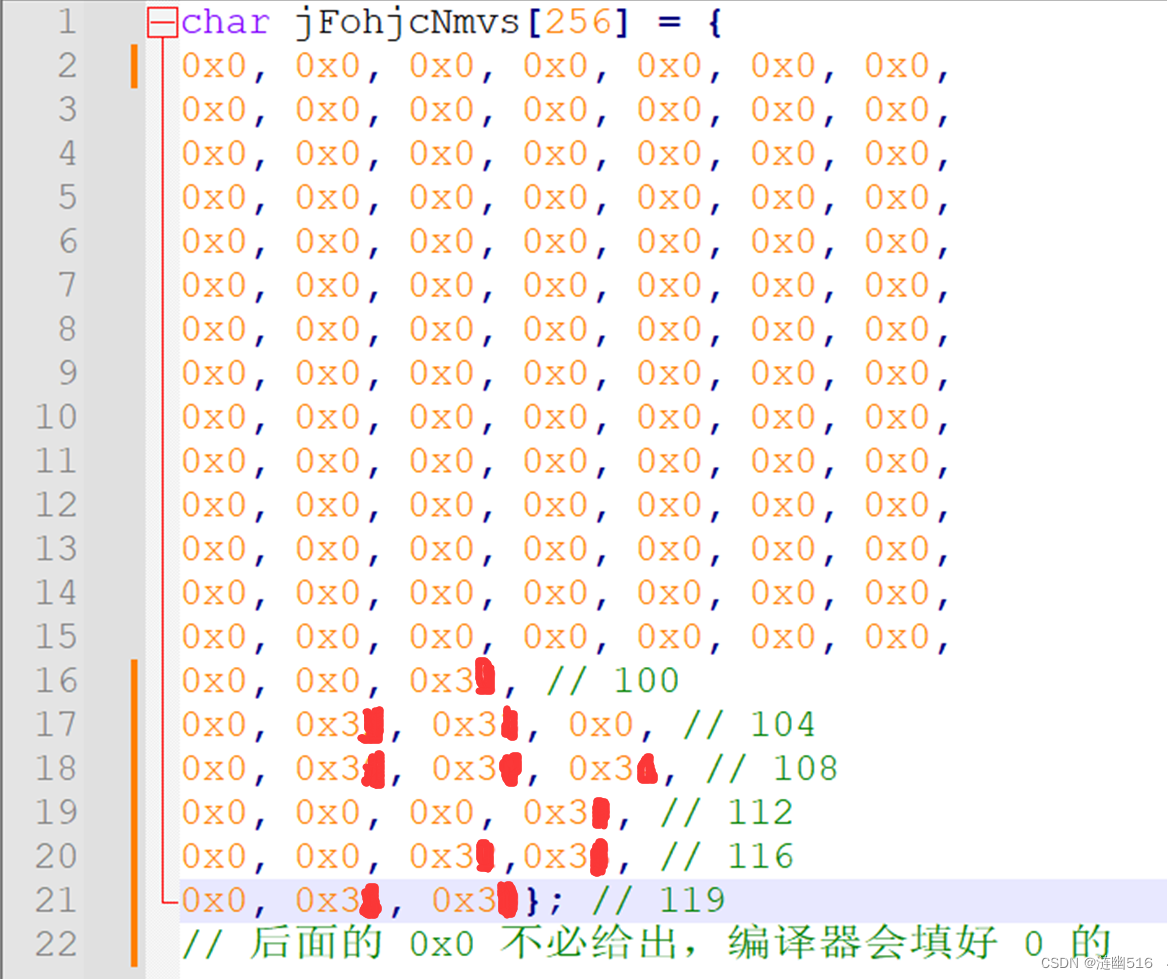
我们就创建定义一个 phase3_patch.c 的源文件,里面定义一个数组,并初始化。
因为看后面的汇编,调用了 putchar 打印字符串函数,所以这里的数组为字符串数组:

然后,gcc -c phase3_patch.c 只编译不链接。
随后,gcc -no-pie -o linkbomb main.o phase3.o phase3_patch.o 链接并生成可执行文件。
经检验,强定义存在:
然后,测试链接一下:

当然不会输出任何内容的,因为我们数组都是 0x0。
然后,我们反汇编(objdump -d linkbomb3 > asm-linkbomb3.txt)一下刚刚直接生成的linkbomb3,看看需要重定位的地方被链接器改写成了什么。
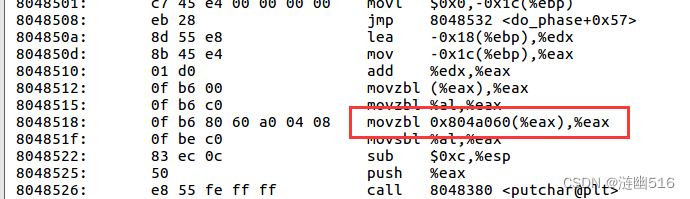
可以看出,需要重定位的地方已经填写了虚拟地址,通过 objdump -s命令查看字符串信息可以定位到该地址:
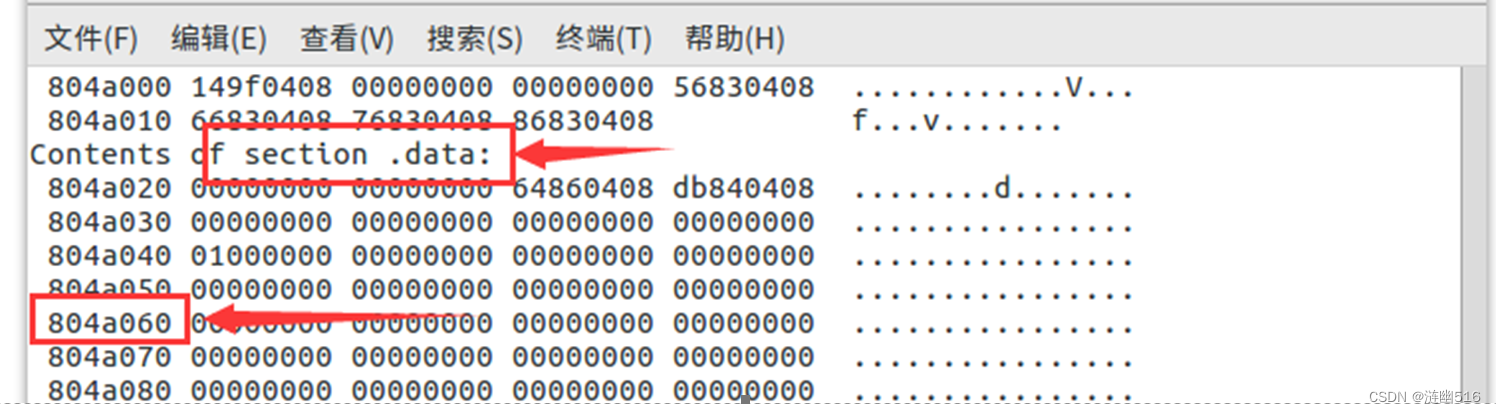
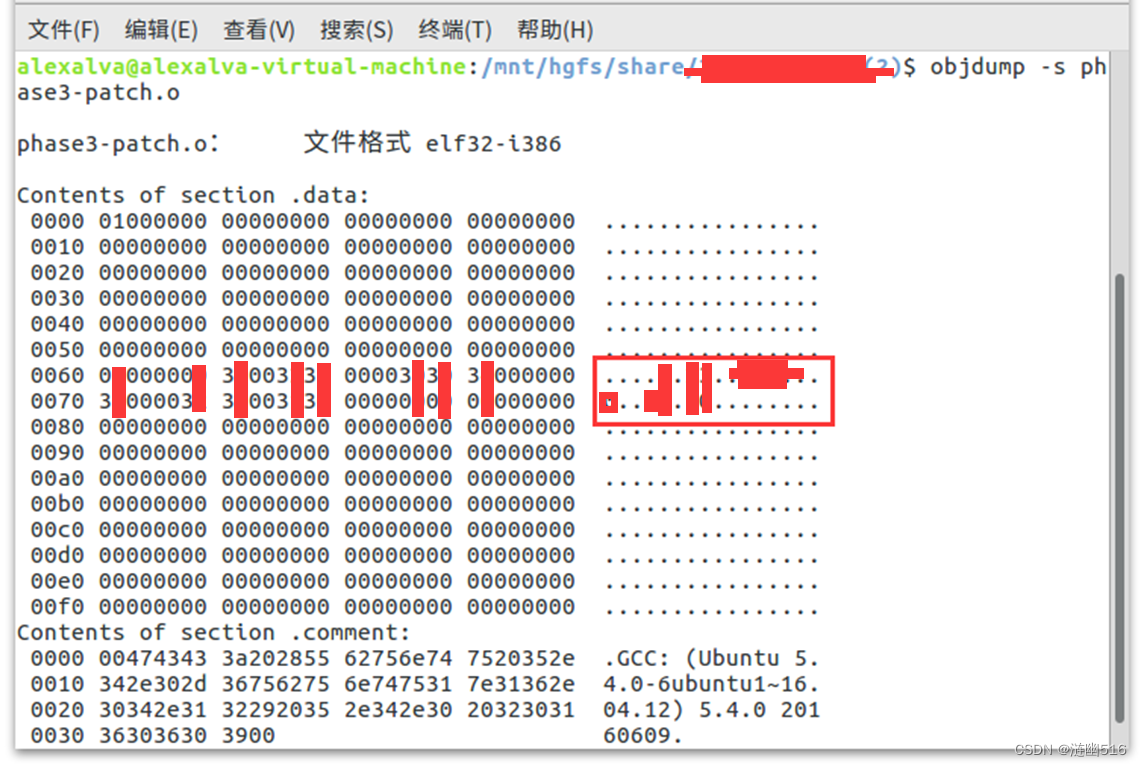
这是位于 .data 节的地址,是“jFohjcNmvs[256]”数组的首地址。
其实在验证过程中发现了一个问题,就是这里重定位的位置不对,如果数组的起始地址为0x804a040,截止到 .data 的结尾 0x804a140,我们只有 224 个字节,不足 256 字节。当我们正确填写数组内容后,链接并反汇编,会发现地址变成了 0x804a040 (如下图所示),此时大小就正确了(为256字节,0x140-0x40 = 0x100 = 256(Dec))。这是因为我猜测是没有填写数据时,编译器填写的重定位表和之后写好时填写的不一样导致的。
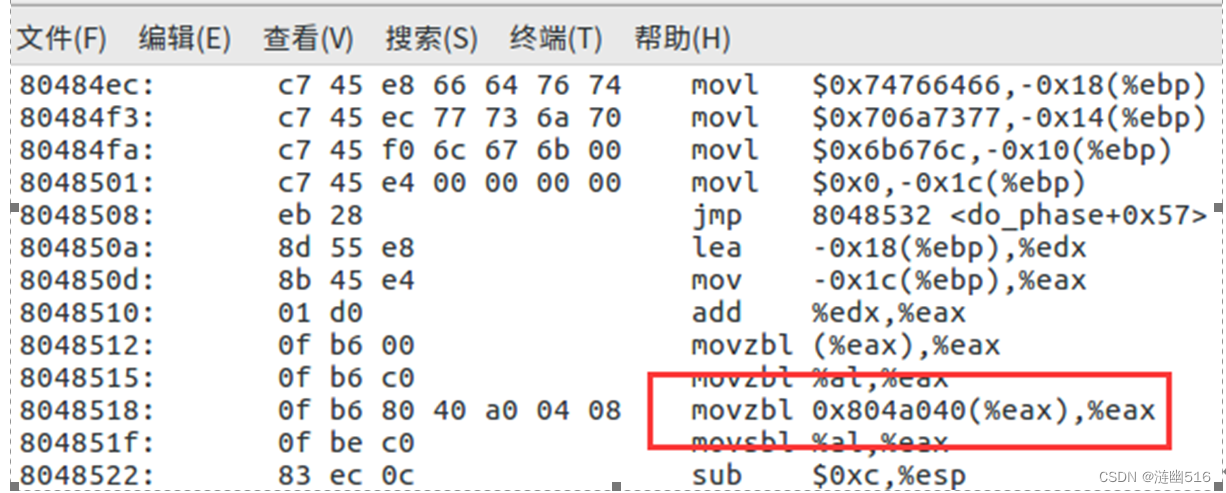
我们可以根据 do_phase 的逻辑精心编写 phase2_patch.c 文件。不用修改代码节。
所以,我们只需要研究好应该在该数组的哪些位置填写学号的 ASCII 码即可,而不必关心重定位过程。
然后,我们试着运行 gdb 实例并在 do_phase 下断点调试:
gdb linkbomb3
(gdb) b do_phase
(gdb) set disassemble-next-line on
(gdb) r
运行后,单步 ni ,并观察下一条指令的汇编,关注我们需要的地方:
比如这里的 movl 指令,前面说过它初始化了栈上的地址,作为数组的值,由于是采用小端序,所以 ebp – 0x18 位置上的值应该是 0x66(十进制的102,记住这个编号):

再继续往下看,就可以发现,是将索引 i 对应的 cookie 数组的值取出,并放到 eax 里面,第一轮循环 i = 0,就取出索引为 0x66(102) 的值。

然后,通过这个值加上我们“jFohjcNmvs”数组的首地址,作为新的源操作数,采用 movzbl 取该地址处的一个字节,作为 eax 最终的值。
我们回到之前没有分析的 do_phase 汇编代码部分:
1)804851f: movsbl %al,%eax
将低8位拓展为32位,并带有符号扩展。
2)8048522: sub $0xc,%esp
在栈上分配12字节的空间。
3)8048525: push %eax
将 eax 压入栈中,这里的eax 就是我们前面取出的“jFohjcNmvs”数组内的数值。
8048526: call 8048380 <putchar@plt>
4)调用 putchar 函数打印字符,将我们的数值作为 ASCII 打印对应的字符。
5)804852b: add $0x10,%esp
回收之前调用时压入栈中的参数。
其实,现在线索已经明朗了,最开始的时候 movl 很多次的就是准备用于计算“jFohjcNmvs”数组索引(读取学号数组具体每一个字符的位置)的 cookie 数组。
movl $0x74766466,-0x18(%ebp)
movl $0x706a7377,-0x14(%ebp)
movl $0x006b676c,-0x10(%ebp)
根据小端序整理出 cookie 数组的值为:
char cookie[12] = {0x66, 0x64, 0x76, 0x74, 0x77, 0x73, 0x6a, 0x70, 0x6c, 0x67, 0x6b, 0x00};
其中,0x00 就是末尾的字符串结束符。
那么 do_phase 的代码可以是下面的这样:
char jFohjcNmvs[256]; // 定义,但未初始化(弱符号)
void do_phase() {int i = 0;char cookie[12] = {0x66, 0x64, 0x76, 0x74, 0x77, 0x73, 0x6a, 0x70, 0x6c, 0x67, 0x6b, 0x00};for (; i <= 11; i++) putchar(jFohjcNmvs[cookie[i]]);putchar('\n');}第一轮索引是 0x66,也就是十进制的 102,所以我们应该将强符号定义的数组的第 103 个数(数组索引从 0 开始,102 对应第 103 个数,这是理解上的一个问题)初始化为我们学号的第一位 2,经过查表可知 (0x32) 是字符 2:

依次类推,最后修改好的 patch 代码如下:
再次编译,编译后的 .o 文件的 .data 节结构如下:
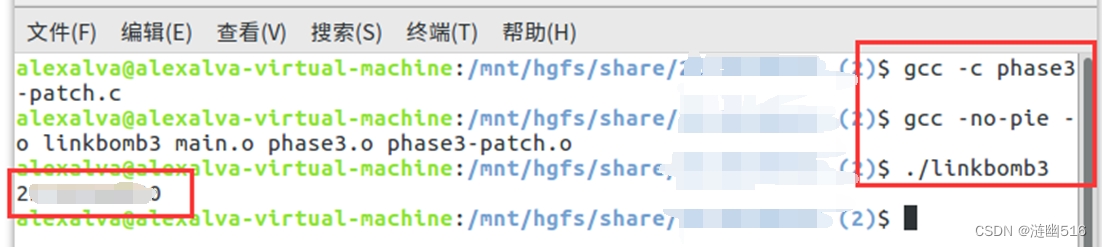
然后链接并运行,成功通关:
后记
一共有 6 个关卡,这是前 3 关,后面 3 关我会持续更新。
更新于:2023.12.31

![[BUG]Datax写入数据到psql报不能序列化特殊字符](https://img-blog.csdnimg.cn/img_convert/726e4e4133dccbdd9d36282def7a5c45.jpeg)