序
在日常的数据库运维中,我们可能会遇到一些看似难以理解的现象。比如两个SQL查询语句,仅仅在ORDER BY子句上略有不同,却造成了性能的天壤之别——一个飞速完成,一个则让数据库崩溃。今天就让我们围绕这个问题,深入剖析MySQL的查询优化机制。
Q1 - 能否自我介绍下?
嗨,大家好,我是 小 明 (小明java问道之路),互联网大厂后端研发专家,2022博客之星TOP3/博客专家/CSDN后端内容合伙人、InfoQ(极客时间)签约作者、阿里云签约博主、全网5万粉丝博主。
一个8年开发经验的老兵,专注于面试/后端/源码/架构/算法,擅长面试高安全/可用/并发/性能的架构设计与演进、系统优化与稳定性建设。
Q2 - 出现 Using filesort 问题分析?
- 我们拿到两条SQL语句,第一条查询语句是:"WHERE time >= '2023-12-21 00:00:00' ORDER BY time ASC“
- 第二条查询语句是:"WHERE time >= '2023-12-21 00:00:00' ORDER BY id ASC“。
通过EXPLAIN命令对两条SQL进行分析后发现,在使用id作为排序字段时,MySQL使用了Using filesort 操作;但是在使用time作为排序字段时,却没有 Using filesort。而我们知道,Using filesort通常代表着磁盘排序,相较于内存排序,它的性能开销要大很多。
那么问题来了,既然id是主键,应该有更好的性能,为什么会导致 Using filesort 的出现呢?
Q3 - 问题原因是什么?
在我们的例子中,假设time字段的值是递增的,并且与id的增长趋势大致一致。那么在执行类似"WHERE time >='2023-12-21 00:00:00' ORDER BY time ASC"的查询时,MySQL可以通过time索引找到满足条件的第一个记录,然后顺序扫描后面的记录直到没有满足WHERE条件的记录为止。
在这个过程中,由于已经按照time字段的顺序读取记录,所以不需要额外的排序操作。
但当我们改为"WHERE time >='2023-12-21 00:00:00' ORDER BY id ASC"时,就不能保证按id的顺序读取记录了。
因为虽然两个字段都是递增的,但并不能确保每个time值对应的id也是按顺序排列的。此时,MySQL查询优化器可能会选择扫描所有满足条件的记录,并把它们加载进入一个临时表进行排序,这样就产生了 Using filesort。
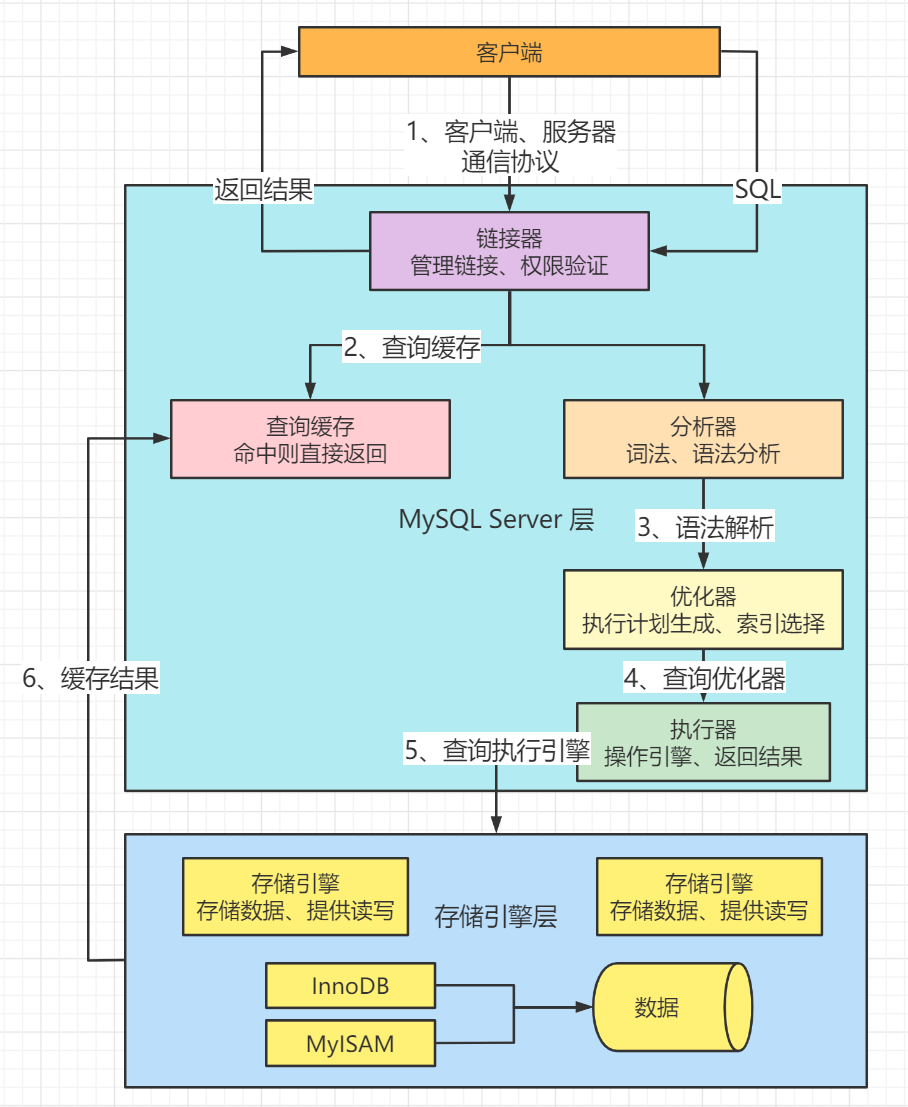
Q4 - MySQL索引与查询优化器?
MySQL的索引可以提高查询速度,因为它们使得MySQL可以找到记录而无需扫描整个表。然而,索引并非万能的,它也会带来存储和管理的开销。所以,当MySQL选择执行计划时,会基于众多因素来考虑是否使用索引、使用哪种索引,以及如何使用索引。
NULL值和数据分布及唯一性都可以影响MySQL索引的使用效果。除此之外,MySQL的查询优化器还会根据查询条件和排序规则,选择最佳的索引进行操作。这就可能出现我们现在这个情况,即使id是主键,但如果在使用id进行排序时,不能有效利用索引,也可能产生 Using filesort 操作。
Q5 - 解决方案是什么?
- 如果我们经常需要按照time和id排序的查询,一种解决方案是创建联合索引(time, id)。这样即使按照id排序,也能利用索引进行优化。因为对于联合索引来说,MySQL可以在满足time过滤条件的情况下,直接使用索引进行id的排序。
- 可以尝试调整MySQL的sort_buffer_size参数。如果排序的数据量小于这个参数,那么MySQL可能会选择内存排序而非 Using filesort。需要注意的是,这个参数是每个连接独享的,设置得过大可能会浪费内存资源。
总结
理解MySQL索引的使用规则和查询优化器的工作原理,可以帮助我们更好地优化数据库性能,解决实际问题。同时,要明白没有最好的索引,只有最合适的索引。我们需要根据业务需求和实际数据分布,来选择和优化索引。
在本次的问题中,我们通过理解索引、排序以及查询优化器的工作原理,找出了导致问题的根源,并提出了相应的解决方案。
充分体现了,深入理解和掌握相关知识,对于我们解决实际问题的重要性。


![[BUG]Datax写入数据到psql报不能序列化特殊字符](https://img-blog.csdnimg.cn/img_convert/726e4e4133dccbdd9d36282def7a5c45.jpeg)