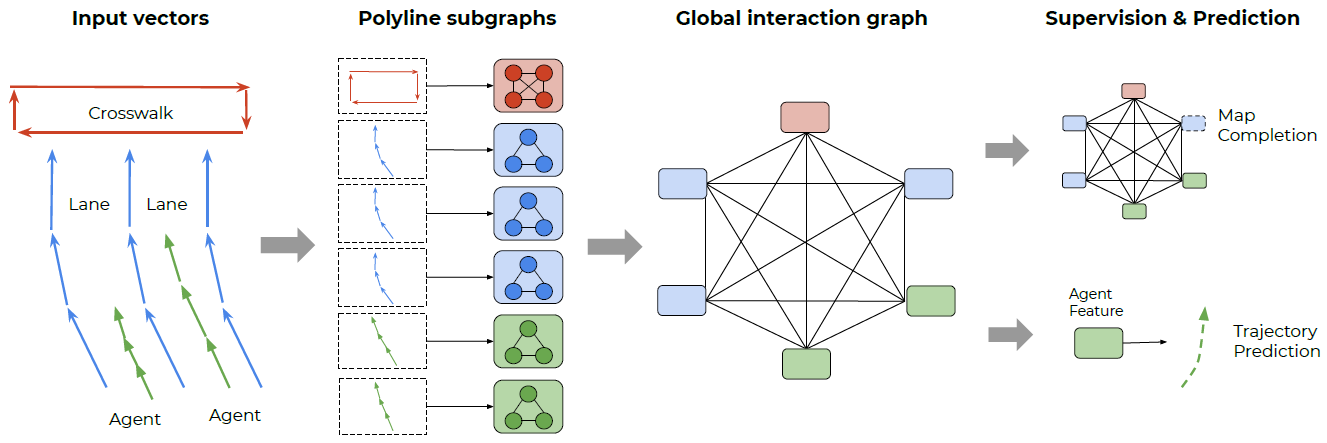
决策书就是一种树状的模型,可以用来做分类和回归。这种分类方式很好理解,相当于分岔路一样,满足某一个条件就走对应的道路,然后抵达不同的终点。决策树有很多类型,基本的有ID3决策树,C4.5决策树,CART决策树,他们主要经过三个步骤,特征选择,生成决策树,决策树剪枝。
1.特征选择
如果情况很复杂,条件有许多,成千上万,我们要是不加甄别,那么每一个条件都生成一个支路,那么我们的模型将会十分复杂。在生成一个分支的时候,依据什么呢?
(1).信息增益
先引入熵值的概念,也就是复杂度的描述,它是每一种事件发生的可能性决定的。假设有K个事件,每一个事件发生的可能性分别对应于pi,熵值如下
(2).联合熵
(3).条件熵
(4).信息增益
随机变量Y的熵H(Y)与Y的条件熵H(Y/X)的差就是信息增益。
g(Y,X)=H(Y)-H(Y/X)
当我们做的选择题的时候,如果四个选择都不确定,则表示复杂度最高,所蕴含的信息最多。而排除两个选项之后,复杂度就减少了,所蕴含的信息就较少了,那么熵值就会增加。当所选择的特征具有更大的信息增益时候,就表示这个特征所具有更多的判断能力。ID3就是用这个方法。
但是ID3算法无法处理连续数值,要对数值进行量化,后面的4.5和CART对其做了优化。
2.信息增益比
用信息增益来作为选择标准,它会有一个倾向,那就是他会选择类别取值更多的特征,很显然,特征选择越多,熵值越大。因此人们提取信息增益比。
也就是结果Y对于条件X的信息增益与X的信息熵的比值。
这么就相当于进行了量化处理,虽然某个特征的信息增益很大,但是如果它的信息增益相对于熵下降的不多,就表示这个特征不是那么重要。
3.Gini系数
它是用来度量不平衡分别的,且介于0-1之间,这个值越小说明越平衡。
计算出数据集某个特征所有取值的基尼指数后,就能计算基尼指数增加值GiniGain,根据GinGain的最小值来划分节点。
在分类问题中,假设有k个类别c1,c2,c3,...,ck,样本点属于第k类的概率为pk,则该概率分布的Gini系数定义为
给定样本集合D,其基尼系数为
ck代表第k类的集合
如果根据特征A的取值a可以把集合D分为两个部分D1和D2,则在A的条件下,D的基尼系数表达式为
4.决策树的生成
生成决策树的流程如下
(1).如果集合D所有的M个样本都属于同一个类别,则直接返回单节点树T,并将该唯一类Ck作为该树节点的类别。
(2).如果训练样本集合D的M个样本都不属于同一个类,但是特征集合只含有单个特征,则返回单节点树T,且该样本集合D中实例数最大的类作为该树节点的类别。
(3).如果以上情况都不存在,则计算训练样本D中F个特征的信息增益,找到最大增大增益Fn对于的特征,如果信息增益大于阈值(这个值可以自己设定),则选择这个特征作为节点,将D划分为Di,灭个子类都生成一个子节点。如果信息增益小于阈值,则返回单节点树T,且将该样本集合D中实例树最大的类作为该树的类别。
(4).对于每个子节点,令D=Di,F=F-Fn,递归调用1-3
对于ID3.5,是根据信息增益分支。它有两个缺点,一个是容易偏向选择取值更多的特征类型,第二个是不能处理连续值特征,第三个是容易过拟合。
对于C4.5决策树,它使用了如下几个方法改善效果
(1).使用的是信息增益,解决偏向取值更多的特征类型
(2).对连续取值进行离散化处理
(3).引入正则化系数进行初步的剪枝来缓解过拟合问题。
5.CATR
CATR叫做分类回归树,classification and regression Tree
虽然C4.5做出了修改,但是仍然出现了几个问题
(1).计算对数的次数太多,计算量太大
(2).使用过的特征会被丢弃,后续不会再使用
(3).对于连续值的处理很粗糙,把不同的范围映射到一个离散空间中,造成信息的损失。
(4).只能做分类,不能做回归。
因此CART决策树修正了这些缺点。
(1).使用基尼指数,而不是信息增益或者信息增益比,减少了对数的计算。采用平方误差最小化准则进行特征选择。
(2).使用二叉树而不是多叉树。这个需要解释一下。ID3和C3.5是根据某个特征划分的切分点,一旦使用,以后就不会用到这个特征。而CATR是使用某个特征的某个值作为切分点,因此这个特征不会被丢弃,在下一次选择时还会利用到。
(3).解决不能回归的问题。这个很简单,前两种算法都是根据特征来划分类别,选择对应类别较多的样本作为子节点,那么CATR每次划分的时候,使用均方误差作为评价指标,子节点是样本对应的标签的均值。
(4).对于容易过拟合的问题,CART使用了剪枝算法
6.CART回归和分类的区别
(1).特征选择的标准不同
分类的选择的是某个特征的某个取值在Gini系数值
回归选择的是均方差。
回归的具体过程如下:
数据集D有M个样本,N个特征。先遍历特征变量Fn,对每一个特征变量,扫描所有可能的K个样本切分点Sk,根据Sk把数据集划分为D1和D2两个子集。划分要求是让D1和D2各自集合的标准差最小,同时D1和D2的标准差之和也最小。
(2)决策树结果输出处理方式也不同
分类:计算子节点不同类别的样本数量,数量最多的那个类作为该节点的标签。
回归:计算子节点标签的均值(或者中位数);
7.剪枝算法
决策树的子节点如果过多,会导致过拟合,因此我们需要减少生成树,去掉多余的树。
剪枝算法有两种,一种是先剪枝,一种是后剪枝。
先剪枝比如C4.5,设置一个阈值,小于这个阈值就不再生成了。后剪枝指的是使用训练集种的大部分数据尽可能的生成一棵最大生成树,然后从决策树低端不断开始剪枝,直到只剩一个根节点的子树T0,得到一个剪枝后的子树序列{T0,T1,T2,......,Tk},最后进行交叉验证,选出其中最优子树。
8.决策树的优缺点
优点1.模型简单容易理解
优点2.可以同时处理数值数据和类型数据
优点3:可以进行多分类和非线性分类
优点4:训练好模型后,预测速度快
优点5:方便集成。比如随机森林,GBDT都是使用决策树模型集成
缺点1:对噪声很敏感
缺点2:处理特征关联性较强的数据时表现不太好