文本数字表示
统计文档中的字符,并且统计字符个数。这里是为了将文字转换为数字表示。
import numpy as np
import re
import torch
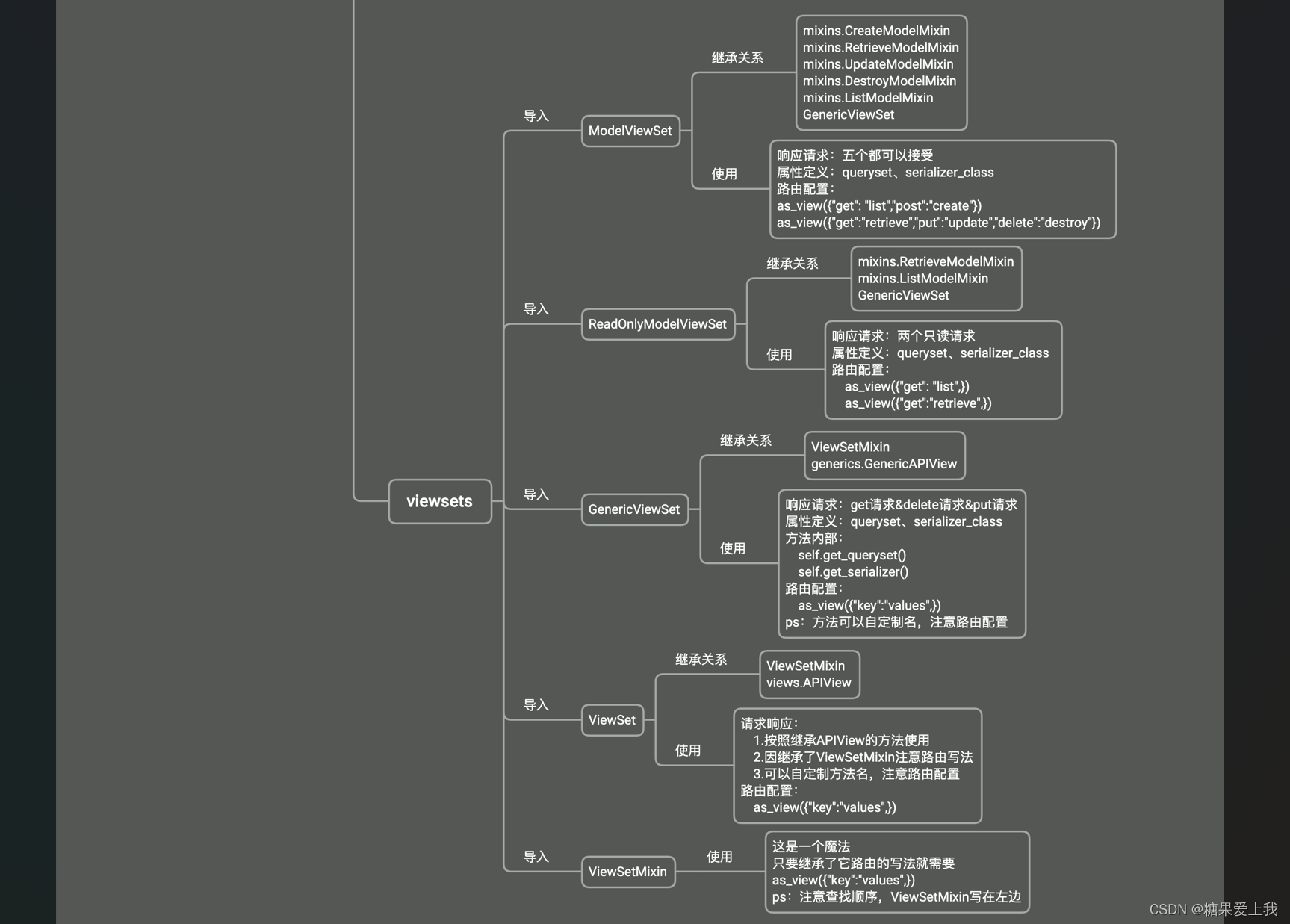
class TextConverter(object):def __init__(self,text_path,max_vocab=5000):"""建立一个字符索引转换,主要还是为了生成一个词汇表:param text_path: 文本位置:param max_vocab: 最大的单词数量"""with open(text_path,'r',encoding='utf-8') as f:text_file=f.readlines()# print('查看部分数据', text_file[:100])# 去掉一些特殊字符text_file = [re.sub(r'\n', '', _) for _ in text_file]text_file = [re.sub(r' ', '', _) for _ in text_file]text_file = [re.sub(r'\u3000', '', _) for _ in text_file]text_file = [_.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ') for _ in text_file]# print('查看部分数据', text_file[:100])# 只匹配中文字符pattern = re.compile(r'[\u4e00-\u9fa5]+')test_file = [pattern.findall(_) for _ in text_file]# print(test_file)word_list = [v for s in text_file for v in s]# print(word_list)# print('一共{}字符'.format(len(word_list)))# 词汇表vocab = set(word_list)# print('一共有{}字'.format(len(vocab)))# 统计每个字出现的频率,如果字超过最长限制,则按字出现的频率去掉最小的部分vocab_count = {}for word in vocab:vocab_count[word] = 0for word in word_list:vocab_count[word] += 1# 打印每个字出现的个数# for key,value in vocab_count.items():# print('key:{},value:{}'.format(key,value))# #将字典转换为列表,并且排序vocab_list = [[key, value] for key, value in vocab_count.items()]# print(vocab_list)vocab_list.sort(key=lambda x: x[1], reverse=True)# vocab_list=sorted(vocab_list,key=(lambda x:x[1]),reverse=True)# print(vocab_list)# 如果大于最大字符数,则进行截取if len(vocab_list) > max_vocab:vocab_list = vocab_list[:max_vocab]self.word_to_int_table = {c[0]: i for i, c in enumerate(vocab_list)}self.int_to_word_table = {i: c[0] for i, c in enumerate(vocab_list)}self.vocab=vocab_list# @propertydef vocab_size(self):# 词汇表的字符数量return len(self.vocab)def int_to_word(self,index):#根据索引找到对应的字符if index==len(self.vocab):return '<unk>'elif index<len(self.vocab):return self.int_to_word_table[index]else:return Exception('输入索引超过范围')def word_to_int(self,word):#根据字符生成对应的索引if word in self.word_to_int_table:return self.word_to_int_table[word]else:return len(self.vocab)def text_to_arr(self,text):#将文本生成对应的数组arr=[]for word in text:arr.append(self.word_to_int(word))return np.array(arr)def arr_to_text(self,arr):words=[]for index in arr:words.append(self.int_to_word(index))return ''.join(words)if __name__=='__main__':#定义一个字符转换器convert=TextConverter('./poetry.txt',max_vocab=1000)# print('词汇表',convert.vocab)print('词汇表的大小',convert.vocab_size())with open('./poetry.txt','r',encoding='utf-8') as f:txt=f.read()txt=txt.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')# txt_char=txt[:11]# print('原始字符串: ',txt_char)## # 转换成数字的形式# arr=convert.text_to_arr(txt_char)# print('转换成数字: ',arr)# txt_char=convert.arr_to_text(arr)# print('将数字转换成文字: ',txt_char)# 构造时序样本数据n_step=20 #每个序列的长度,这里是指每个序列拥有20个字符#总的序列个数num_sep=int(len(txt)/n_step)# 去掉最后不足序列长度的部分txt=txt[:num_sep*n_step]print('共有{}个序列,每个序列含有{}个汉字'.format(num_sep,n_step))print('第一个序列: ',txt[:20])print('转换为数字: ',convert.text_to_arr(txt[:20]))#将所有的文本转换为数字表示,且重新排列成(num_sep,n_step)的矩阵arr=convert.text_to_arr(txt)arr=arr.reshape((num_sep,-1))arr=torch.from_numpy(arr)print('arr shape',arr.shape)print('第一个序列',arr[0,:])# 转换为汉字arr_text=convert.arr_to_text(np.array(arr[0,:]))print('第一个序列转换为汉字',arr_text)
构造样本数据
import numpy as np
import re
import torch
class TextConverter(object):def __init__(self,text_path,max_vocab=5000):"""建立一个字符索引转换,主要还是为了生成一个词汇表:param text_path: 文本位置:param max_vocab: 最大的单词数量"""with open(text_path,'r',encoding='utf-8') as f:text_file=f.readlines()# print('查看部分数据', text_file[:100])# 去掉一些特殊字符text_file = [re.sub(r'\n', '', _) for _ in text_file]text_file = [re.sub(r' ', '', _) for _ in text_file]text_file = [re.sub(r'\u3000', '', _) for _ in text_file]text_file = [_.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ') for _ in text_file]# print('查看部分数据', text_file[:100])# 只匹配中文字符pattern = re.compile(r'[\u4e00-\u9fa5]+')test_file = [pattern.findall(_) for _ in text_file]# print(test_file)word_list = [v for s in text_file for v in s]# print(word_list)# print('一共{}字符'.format(len(word_list)))# 词汇表vocab = set(word_list)# print('一共有{}字'.format(len(vocab)))# 统计每个字出现的频率,如果字超过最长限制,则按字出现的频率去掉最小的部分vocab_count = {}for word in vocab:vocab_count[word] = 0for word in word_list:vocab_count[word] += 1# 打印每个字出现的个数# for key,value in vocab_count.items():# print('key:{},value:{}'.format(key,value))# #将字典转换为列表,并且排序vocab_list = [[key, value] for key, value in vocab_count.items()]# print(vocab_list)vocab_list.sort(key=lambda x: x[1], reverse=True)# vocab_list=sorted(vocab_list,key=(lambda x:x[1]),reverse=True)# print(vocab_list)# 如果大于最大字符数,则进行截取if len(vocab_list) > max_vocab:vocab_list = vocab_list[:max_vocab]self.word_to_int_table = {c[0]: i for i, c in enumerate(vocab_list)}self.int_to_word_table = {i: c[0] for i, c in enumerate(vocab_list)}self.vocab=vocab_list# @propertydef vocab_size(self):# 词汇表的字符数量return len(self.vocab)def int_to_word(self,index):#根据索引找到对应的字符if index==len(self.vocab):return '<unk>'elif index<len(self.vocab):return self.int_to_word_table[index]else:return Exception('输入索引超过范围')def word_to_int(self,word):#根据字符生成对应的索引if word in self.word_to_int_table:return self.word_to_int_table[word]else:return len(self.vocab)def text_to_arr(self,text):#将文本生成对应的数组arr=[]for word in text:arr.append(self.word_to_int(word))return np.array(arr)def arr_to_text(self,arr):words=[]for index in arr:words.append(self.int_to_word(index))return ''.join(words)class TextDataset(object):"""arr:arr表示的是所有文本的数字表示"""def __init__(self,arr):self.arr=arrdef __getitem__(self, item):x=self.arr[item,:]#构造labely=torch.zeros(x.shape)#将输入的第一个字符作为最后一个输入的labely[:-1],y[-1]=x[1:],x[0]return x,ydef __len__(self):return self.arr.shape[0]if __name__=='__main__':#定义一个字符转换器convert=TextConverter('./poetry.txt',max_vocab=1000)# print('词汇表',convert.vocab)print('词汇表的大小',convert.vocab_size())with open('./poetry.txt','r',encoding='utf-8') as f:txt=f.read()txt=txt.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')# 构造时序样本数据n_step=10 #每个序列的长度,这里是指每个序列拥有10个字符#总的序列个数num_sep=int(len(txt)/n_step)# 去掉最后不足序列长度的部分txt=txt[:num_sep*n_step]print('共有{}个序列,每个序列含有{}个汉字'.format(num_sep,n_step))# print('第一个序列: ',txt[:20])# print('转换为数字: ',convert.text_to_arr(txt[:20]))#将所有的文本转换为数字表示,且重新排列成(num_sep,n_step)的矩阵arr=convert.text_to_arr(txt)arr=arr.reshape((num_sep,-1))arr=torch.from_numpy(arr)#定义数据集train_set=TextDataset(arr)x,y=train_set[0]print(x.numpy(),convert.arr_to_text(x.numpy()))print(y.numpy(),convert.arr_to_text(y.numpy()))
搭建模型
import torch
from torch import nn
from torch.autograd import Variableclass CharRNN(nn.Module):"""num_classes:表示预测多少个类别,文本生成,num_classes=词汇表的大小,也就是说模型输出每个单词的概率embed_dim:这里用nn.Embedding将字符映射为 embed_dim维的向量hidden_size:表示隐藏层的大小num_layers:表示隐藏层的个数"""def __init__(self,num_classes,embed_dim,hidden_size,num_layers,dropout):super().__init__()self.num_layers=num_layersself.hidden_size=hidden_sizeself.word_to_ver=nn.Embedding(num_classes,embed_dim)self.rnn=nn.RNN(embed_dim,hidden_size,num_layers,batch_first=True)self.project=nn.Linear(hidden_size,num_classes)def forward(self,x,hs=None):batch=x.shape[0]if hs is None:hs=Variable(torch.zeros(self.num_layers,batch,self.hidden_size))word_embed=self.word_to_ver(x) #(batch,seq_len,embed_dim)# word_embed=word_embed.permute(1,0,2) #(seq_len,batch,embed_dim)out,h0=self.rnn(word_embed,hs) #(seq_len,batch,hidden)batch,seq_len,hd_dim=out.shapeout=out.contiguous().view(batch*seq_len,hd_dim)out=self.project(out)out=out.view(batch,seq_len,-1)# out=out.permute(1,0,2).contiguous()return out.view(-1,out.shape[2]),h0
if __name__=='__main__':num_classes=1000model=CharRNN(num_classes=num_classes,embed_dim=100,hidden_size=30,num_layers=1,dropout=0.5)print(model)x=torch.randint(0,100,(10,5))y,h=model(x)print(y.shape)print(h.shape)
训练
import numpy as np
import re
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
class TextConverter(object):def __init__(self,text_path,max_vocab=5000):"""建立一个字符索引转换,主要还是为了生成一个词汇表:param text_path: 文本位置:param max_vocab: 最大的单词数量"""with open(text_path,'r',encoding='utf-8') as f:text_file=f.readlines()# print('查看部分数据', text_file[:100])# 去掉一些特殊字符text_file = [re.sub(r'\n', '', _) for _ in text_file]text_file = [re.sub(r' ', '', _) for _ in text_file]text_file = [re.sub(r'\u3000', '', _) for _ in text_file]text_file = [_.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ') for _ in text_file]# print('查看部分数据', text_file[:100])# 只匹配中文字符pattern = re.compile(r'[\u4e00-\u9fa5]+')test_file = [pattern.findall(_) for _ in text_file]# print(test_file)word_list = [v for s in text_file for v in s]# print(word_list)# print('一共{}字符'.format(len(word_list)))# 词汇表vocab = set(word_list)# print('一共有{}字'.format(len(vocab)))# 统计每个字出现的频率,如果字超过最长限制,则按字出现的频率去掉最小的部分vocab_count = {}for word in vocab:vocab_count[word] = 0for word in word_list:vocab_count[word] += 1# 打印每个字出现的个数# for key,value in vocab_count.items():# print('key:{},value:{}'.format(key,value))# #将字典转换为列表,并且排序vocab_list = [[key, value] for key, value in vocab_count.items()]# print(vocab_list)vocab_list.sort(key=lambda x: x[1], reverse=True)# vocab_list=sorted(vocab_list,key=(lambda x:x[1]),reverse=True)# print(vocab_list)# 如果大于最大字符数,则进行截取if len(vocab_list) > max_vocab:vocab_list = vocab_list[:max_vocab]self.word_to_int_table = {c[0]: i for i, c in enumerate(vocab_list)}self.int_to_word_table = {i: c[0] for i, c in enumerate(vocab_list)}self.vocab=vocab_list# @propertydef vocab_size(self):# 词汇表的字符数量return len(self.vocab)+1def int_to_word(self,index):#根据索引找到对应的字符if index.ndim>=1:index=np.squeeze(index)index=index.item()else:index=indexif index==len(self.vocab):return '<unk>'elif index<len(self.vocab):return self.int_to_word_table[index]else:return Exception('输入索引超过范围')def word_to_int(self,word):#根据字符生成对应的索引if word in self.word_to_int_table:return self.word_to_int_table[word]else:return len(self.vocab)def text_to_arr(self,text):#将文本生成对应的数组arr=[]for word in text:arr.append(self.word_to_int(word))return np.array(arr)def arr_to_text(self,arr):words=[]for index in arr:words.append(self.int_to_word(index))return ''.join(words)class TextDataset(object):"""arr:arr表示的是所有文本的数字表示"""def __init__(self,arr):self.arr=arrdef __getitem__(self, item):x=self.arr[item,:]#构造labely=torch.zeros(x.shape,dtype=torch.float32)#将输入的第一个字符作为最后一个输入的labely[:-1],y[-1]=x[1:],x[0]return x,ydef __len__(self):return self.arr.shape[0]class CharRNN(nn.Module):def __init__(self,num_classes,embed_dim,hidden_size,num_layers):super().__init__()self.num_layers=num_layers #有几层self.hidden_size=hidden_size #隐藏层维度self.word_to_vec=nn.Embedding(num_classes,embed_dim) #一共有num_classes个词汇,每个词汇用embed_dim维度表示self.rnn=nn.GRU(embed_dim,hidden_size,num_layers)self.project=nn.Linear(hidden_size,num_classes)def forward(self,x,hs=None):batch=x.shape[0]if hs is None:hs=torch.autograd.Variable(torch.zeros(self.num_layers,batch,self.hidden_size))word_embed=self.word_to_vec(x) #(batch,seq_len,embed)word_embed=word_embed.permute(1,0,2) #(seq_len,batch,embed)out,h0=self.rnn(word_embed,hs) #(seq_len,batch,embed)seq_len,batch,hid_dim=out.shapeout=out.view(seq_len*batch,hid_dim)out=self.project(out)out=out.view(seq_len,batch,-1)out=out.permute(1,0,2).contiguous()return out.view(-1,out.shape[2]),h0if __name__=='__main__':#定义一个字符转换器convert=TextConverter('./poetry.txt',max_vocab=1000)# print('词汇表',convert.vocab)print('词汇表的大小',convert.vocab_size())with open('./poetry.txt','r',encoding='utf-8') as f:txt=f.read()txt=txt.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')# 构造时序样本数据n_step=10 #每个序列的长度,这里是指每个序列拥有10个字符#总的序列个数num_sep=int(len(txt)/n_step)# 去掉最后不足序列长度的部分txt=txt[:num_sep*n_step]print('共有{}个序列,每个序列含有{}个汉字'.format(num_sep,n_step))# print('第一个序列: ',txt[:20])# print('转换为数字: ',convert.text_to_arr(txt[:20]))#将所有的文本转换为数字表示,且重新排列成(num_sep,n_step)的矩阵arr=convert.text_to_arr(txt)arr=arr.reshape((num_sep,-1))print('最大值',np.max(arr))arr=torch.from_numpy(arr)#定义数据集train_set=TextDataset(arr)x,y=train_set[0]print(x.numpy(),convert.arr_to_text(x.numpy()))print(y.numpy(),convert.arr_to_text(y.numpy()))##定义一个dataloaderbatchsize=128train_data=DataLoader(train_set,batchsize,shuffle=True,num_workers=4)# for batch in train_data:# x,y=batch# print(x.shape)# print(y.shape)# break##定义模型model=CharRNN(convert.vocab_size(),512,512,1)#定义优化器和损失函数criterion=nn.CrossEntropyLoss()optimizer=torch.optim.Adam(model.parameters(),lr=1e-3)#训练epochs=20for e in range(epochs):train_loss=0for data in train_data:x,y=datax,y=torch.autograd.Variable(x),torch.autograd.Variable(y)#前向传播score,_ =model(x)y=y.view(-1)score=torch.FloatTensor(score)y=y.to(torch.int64)loss=criterion(score,y)#反向传播optimizer.zero_grad()loss.backward()#梯度裁剪nn.utils.clip_grad_norm_(model.parameters(),5)optimizer.step()train_loss+=loss.item()print('epoch: {} 困惑度: {:.3f} '.format(e,np.exp(train_loss / len(train_data))))# 保存模型torch.save(model,'model{}.pth'.format(e))
预测
import numpy as np
import re
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
class TextConverter(object):def __init__(self,text_path,max_vocab=5000):"""建立一个字符索引转换,主要还是为了生成一个词汇表:param text_path: 文本位置:param max_vocab: 最大的单词数量"""with open(text_path,'r',encoding='utf-8') as f:text_file=f.readlines()# print('查看部分数据', text_file[:100])# 去掉一些特殊字符text_file = [re.sub(r'\n', '', _) for _ in text_file]text_file = [re.sub(r' ', '', _) for _ in text_file]text_file = [re.sub(r'\u3000', '', _) for _ in text_file]text_file = [_.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ') for _ in text_file]# print('查看部分数据', text_file[:100])# 只匹配中文字符pattern = re.compile(r'[\u4e00-\u9fa5]+')test_file = [pattern.findall(_) for _ in text_file]# print(test_file)word_list = [v for s in text_file for v in s]# print(word_list)# print('一共{}字符'.format(len(word_list)))# 词汇表vocab = set(word_list)# print('一共有{}字'.format(len(vocab)))# 统计每个字出现的频率,如果字超过最长限制,则按字出现的频率去掉最小的部分vocab_count = {}for word in vocab:vocab_count[word] = 0for word in word_list:vocab_count[word] += 1# 打印每个字出现的个数# for key,value in vocab_count.items():# print('key:{},value:{}'.format(key,value))# #将字典转换为列表,并且排序vocab_list = [[key, value] for key, value in vocab_count.items()]# print(vocab_list)vocab_list.sort(key=lambda x: x[1], reverse=True)# vocab_list=sorted(vocab_list,key=(lambda x:x[1]),reverse=True)# print(vocab_list)# 如果大于最大字符数,则进行截取if len(vocab_list) > max_vocab:vocab_list = vocab_list[:max_vocab]self.word_to_int_table = {c[0]: i for i, c in enumerate(vocab_list)}self.int_to_word_table = {i: c[0] for i, c in enumerate(vocab_list)}self.vocab=vocab_list# @propertydef vocab_size(self):# 词汇表的字符数量return len(self.vocab)+1def int_to_word(self,index):#根据索引找到对应的字符# if index.ndim>=1:# index=np.squeeze(index)# index=index.item()# else:# index=indexif index==len(self.vocab):return '<unk>'elif index<len(self.vocab):return self.int_to_word_table[index]else:return Exception('输入索引超过范围')def word_to_int(self,word):#根据字符生成对应的索引if word in self.word_to_int_table:return self.word_to_int_table[word]else:return len(self.vocab)def text_to_arr(self,text):#将文本生成对应的数组arr=[]for word in text:arr.append(self.word_to_int(word))return np.array(arr)def arr_to_text(self,arr):words=[]for index in arr:words.append(self.int_to_word(index))return ''.join(words)class TextDataset(object):"""arr:arr表示的是所有文本的数字表示"""def __init__(self,arr):self.arr=arrdef __getitem__(self, item):x=self.arr[item,:]#构造labely=torch.zeros(x.shape,dtype=torch.float32)#将输入的第一个字符作为最后一个输入的labely[:-1],y[-1]=x[1:],x[0]return x,ydef __len__(self):return self.arr.shape[0]class CharRNN(nn.Module):def __init__(self,num_classes,embed_dim,hidden_size,num_layers):super().__init__()self.num_layers=num_layers #有几层self.hidden_size=hidden_size #隐藏层维度self.word_to_vec=nn.Embedding(num_classes,embed_dim) #一共有num_classes个词汇,每个词汇用embed_dim维度表示self.rnn=nn.GRU(embed_dim,hidden_size,num_layers)self.project=nn.Linear(hidden_size,num_classes)def forward(self,x,hs=None):batch=x.shape[0]if hs is None:hs=torch.autograd.Variable(torch.zeros(self.num_layers,batch,self.hidden_size))word_embed=self.word_to_vec(x) #(batch,seq_len,embed)word_embed=word_embed.permute(1,0,2) #(seq_len,batch,embed)out,h0=self.rnn(word_embed,hs) #(seq_len,batch,embed)seq_len,batch,hid_dim=out.shapeout=out.view(seq_len*batch,hid_dim)out=self.project(out)out=out.view(seq_len,batch,-1)out=out.permute(1,0,2).contiguous()return out.view(-1,out.shape[2]),h0def pick_top_n(preds, top_n=5):top_pred_prob, top_pred_label = torch.topk(preds, top_n, 1)top_pred_prob /= torch.sum(top_pred_prob)top_pred_prob = top_pred_prob.squeeze(0).cpu().numpy()top_pred_label = top_pred_label.squeeze(0).cpu().numpy()c = np.random.choice(top_pred_label, size=1, p=top_pred_prob)return cif __name__=='__main__':#定义一个字符转换器convert=TextConverter('./poetry.txt',max_vocab=1000)# print('词汇表',convert.vocab)print('词汇表的大小',convert.vocab_size())with open('./poetry.txt','r',encoding='utf-8') as f:txt=f.read()txt=txt.replace('\n', ' ').replace('\r', ' ').replace(',', ' ').replace('。', ' ')##定义模型#导入模型model=torch.load('model5.pth')print(model)begin = '天青色等烟雨'text_len = 30model = model.eval()samples = [convert.word_to_int(c) for c in begin]input_txt = torch.LongTensor(samples)[None]input_txt = torch.autograd.Variable(input_txt)_, init_state = model(input_txt)result = samplesmodel_input = input_txt[:, -1][:, None]for i in range(text_len):out, init_state = model(model_input, init_state)pred = pick_top_n(out.data)model_input = torch.autograd.Variable(torch.LongTensor(pred))[None]result.append(pred[0])text = convert.arr_to_text(result)print('Generate text is: {}'.format(text))参考:
Char-RNN-PyTorch
在 PyTorch 中使用 LSTM 生成文本-CSDN博客
基于pytorch的LSTM进行字符级文本生成实战_pytorch文本生成-CSDN博客
NLP-使用CNN进行文本分类_cnn用于文本分类-CSDN博客
利用RNN神经网络自动生成唐诗宋词_rnn生成唐诗-CSDN博客
NLP-中文文本预处理




![Linux操作系统极速入门[常用指令]](https://img-blog.csdnimg.cn/direct/c7b1dfc1c1714edd9682e3f289855e82.png)