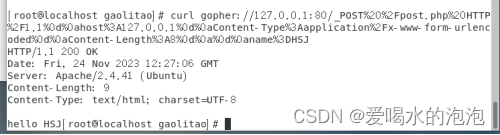
云原生容器编排问题盘点,总结分享年度使用Kubernetes的坑和陷阱
- Kubernetes与云原生
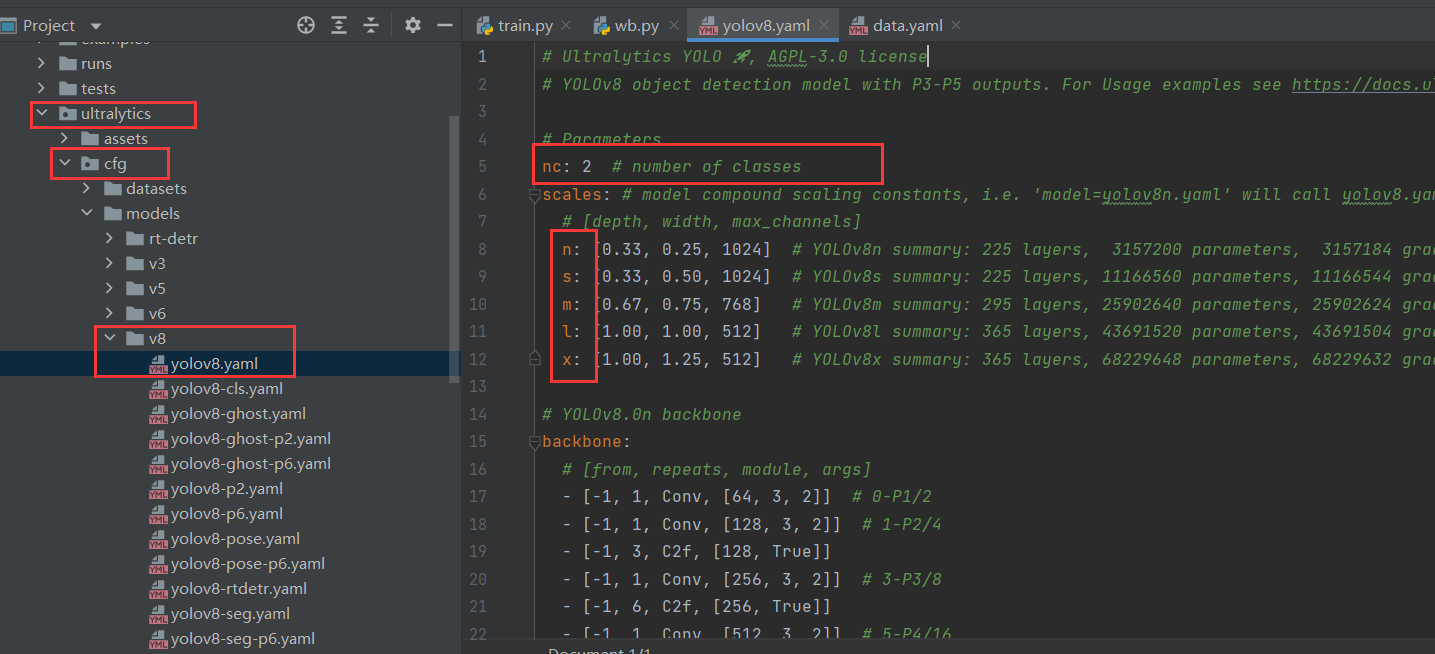
- 性能问题:忽略节点选择器导致调度效率低下
- 问题排查和分析
- 解决方案
- 案例介绍
- 配置问题:应用服务端口与Service(KubectlProxy)控制的端口不一致
- 隔离问题:容器组件部署到K8S集群错误的命名空间或者默认空间(建议)
- 资源问题:不进行设置资源请求和限制的Pod(命名空间也没有控制)
- 解决方案
- 设置资源限制
- 参数解释:
- 状态问题:优化和使用Liveness和Readiness探针
- Liveness探针
- Readiness探针
- 最后总结
Kubernetes与云原生
随着云原生的兴起,越来越多的应用选择基于Kubernetes进行部署,可以说Kubernetes 是最流行的容器编排和部署平台。它的强大功能特性,可以保障在生产中可靠地运行容器化应用程序,相关的DevOps等工具也应运而生,下面就是小编简单化了一个Kubernetes的逻辑架构图。
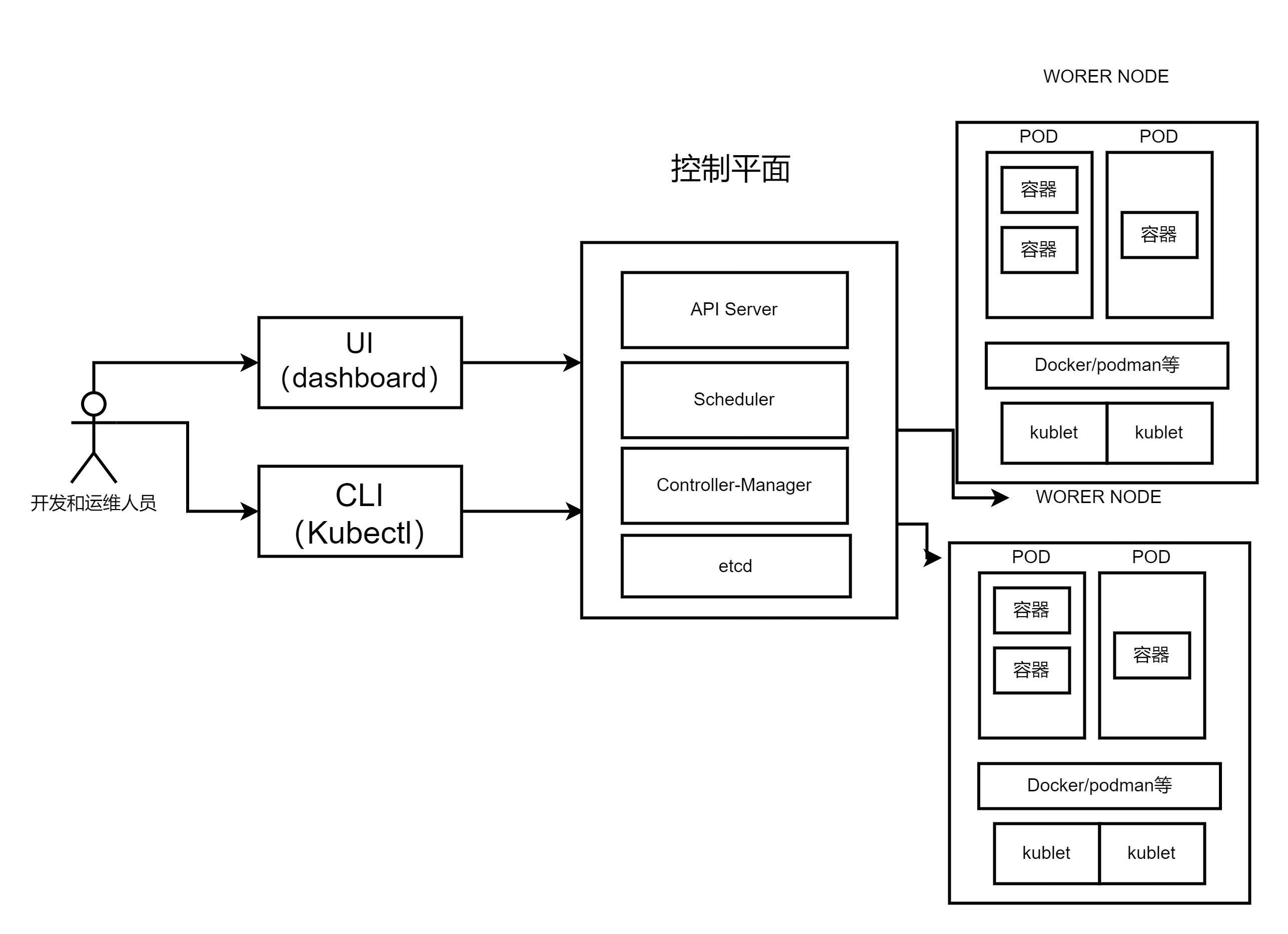
如何开发面向Kubernetes部署和运维的微服务应用是很多开发者与架构师要解决的问题。通过本文的阅读,作者介绍了在Kubernetes体系下构建高效、可靠的微服务应用所遇到的种种问题。希望这篇文章能够对您有所帮助。
总体问题大纲分布如下说是:

在接下来的内容中,我们将探讨今年个人遇到的5个常见的Kubernetes问题和错误。通过识别并避免这些挑战,您将能够提高应用程序的可扩展性、可靠性和安全性,同时更好地控制集群及其部署。
性能问题:忽略节点选择器导致调度效率低下
整个集群效能的表现关键在于Pod是否能被精准地部署至适宜的节点上。在众多的集群配置中,常常包含多样化的节点类型,比如那些专为常规应用程序设计的小型内存和低配CPU节点,以及针对高密度后台服务所配置的大型内存和高配CPU节点。
问题排查和分析
- 首先,我们一定要侧重分析当前节点池的利用率和资源分配情况,确定是否存在未充分利用的较小节点。
- 如果存在未充分利用的较小节点,使用自动化工具进行节点重分配。将该节点上运行的负载迁移到其他节点上,以实现节点资源的最优使用。
- 最后,在节点迁移之前,需再三确保目标节点有足够的资源来承载额外的负载。
注意:考虑负载迁移对运行中应用的影响,并确保其在迁移过程中不会中断。
解决方案
为了避免出现这个问题,我们可以使用一种有效的方法来管理Pod的调度,即通过在节点上设置标签,并使用节点选择器将Pod分配给兼容的节点。这种方法可以确保Pod被正确地调度到具备所需资源和能力的节点上。
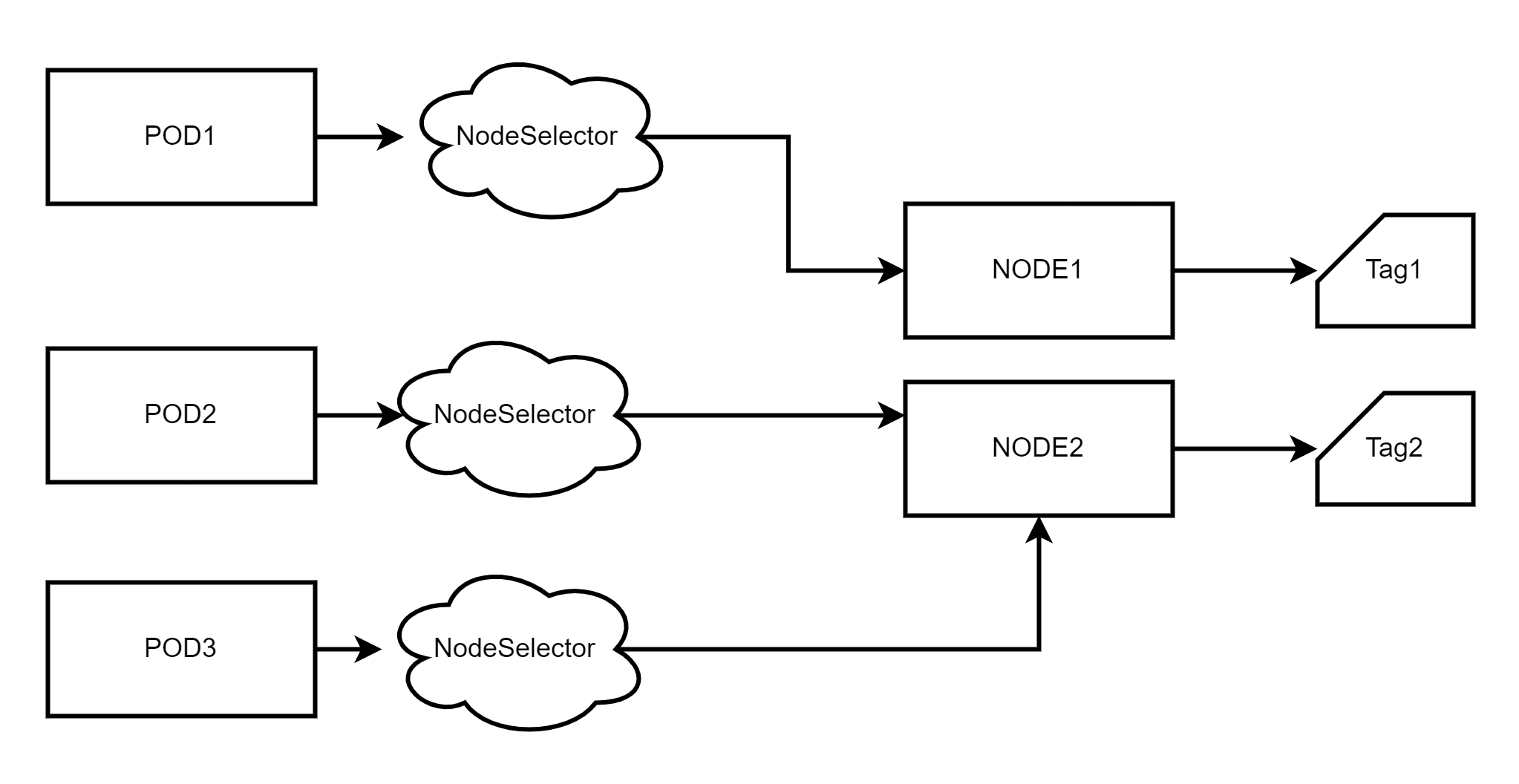
案例介绍
首先,我们为节点设置适当的标签。标签可以根据节点的特性、硬件配置或其他自定义需求进行定义。
例如,可以为具备高性能GPU的节点设置一个标签,或者为具备特定版本的软件组件的节点设置一个标签。
接下来,在Pod的定义中添加一个节点选择器。节点选择器是一组标签键值对,用于指定Pod所需的节点属性或条件。
例如,可以指定Pod需要运行在具备某个特定标签的节点上。
当调度程序接收到新的Pod创建请求时,它将根据Pod的节点选择器进行匹配,并将Pod分配给满足条件的节点。这样,Pod就能够被正确、高效地调度到合适的节点上,避免了资源浪费和性能问题。
apiVersion: v1
kind: Pod
metadata:name: pod-node-selector-sample
spec:containers:- name: tomcatimage: tomcat:latestnodeSelector:node-class: middleLevel
为了确保Pod只会调度到设置了标签的节点(例如node-class: middleLevel),我们可以使用kubectl命令在匹配的节点上设置标签。
首先我们先使用kubectl命令列出当前可用的节点
kubectl get nodes
之后,找到您想要为其添加标签的特定节点。使用kubectl命令在该节点上设置标签。你可以使用以下命令格式:
kubectl label nodes <节点名称> <标签键>=<标签值>
此外,如果节点的名称是node-1,要将标签node-class设置为middleLevel,您可以运行以下命令:
kubectl label nodes node-1 node-class=middleLevel
这将在节点node-1上设置了一个标签node-class,其值为middleLevel。
配置问题:应用服务端口与Service(KubectlProxy)控制的端口不一致
在我们的运行环境中,确保Service将流量路由到对应的Pod上的正确端口非常重要。为了解决这个问题,您需要确保Service的端口定义与Pod容器的端口一致。
以下是一个错误的配置Service和Pod的配置文件:
apiVersion: v1
kind: Pod
metadata:name: test-podlabels:app: test-app
spec:image: tomcat:latestports:- containerPort: 8081---apiVersion: v1
kind: Service
metadata:name: test-service
spec:selector:app: test-appports:- protocol: TCPport: 9000targetPort: 8082
在上述示例中,Service的目标端口(targetPort)设置为8081,与Pod容器的实际端口(containerPort:8081)不一致。通过调整Service的配置,确保正确路由流量到Pod的适当端口,将有助于保证应用程序的正常运行和可靠性。
正确的配置如下所示:
apiVersion: v1
kind: Pod
metadata:name: test-podlabels:app: test-app
spec:image: tomcat:latestports:- containerPort: 8081---apiVersion: v1
kind: Service
metadata:name: test-service
spec:selector:app: test-appports:- protocol: TCPport: 9000targetPort: 8081
隔离问题:容器组件部署到K8S集群错误的命名空间或者默认空间(建议)
Kubernetes命名空间在集群中提供了一定程度的隔离,将一组服务逻辑分组在一起。在使用命名空间时,请记住为每个服务和kubectl命令指定目标命名空间。如果没有指定目标命名空间,将默认使用default命名空间。
如果服务没有部署在合适的命名空间下,就会导致相关的服务器请求无法到达,在这里给大家看一个逻辑结构图就可以了解到:
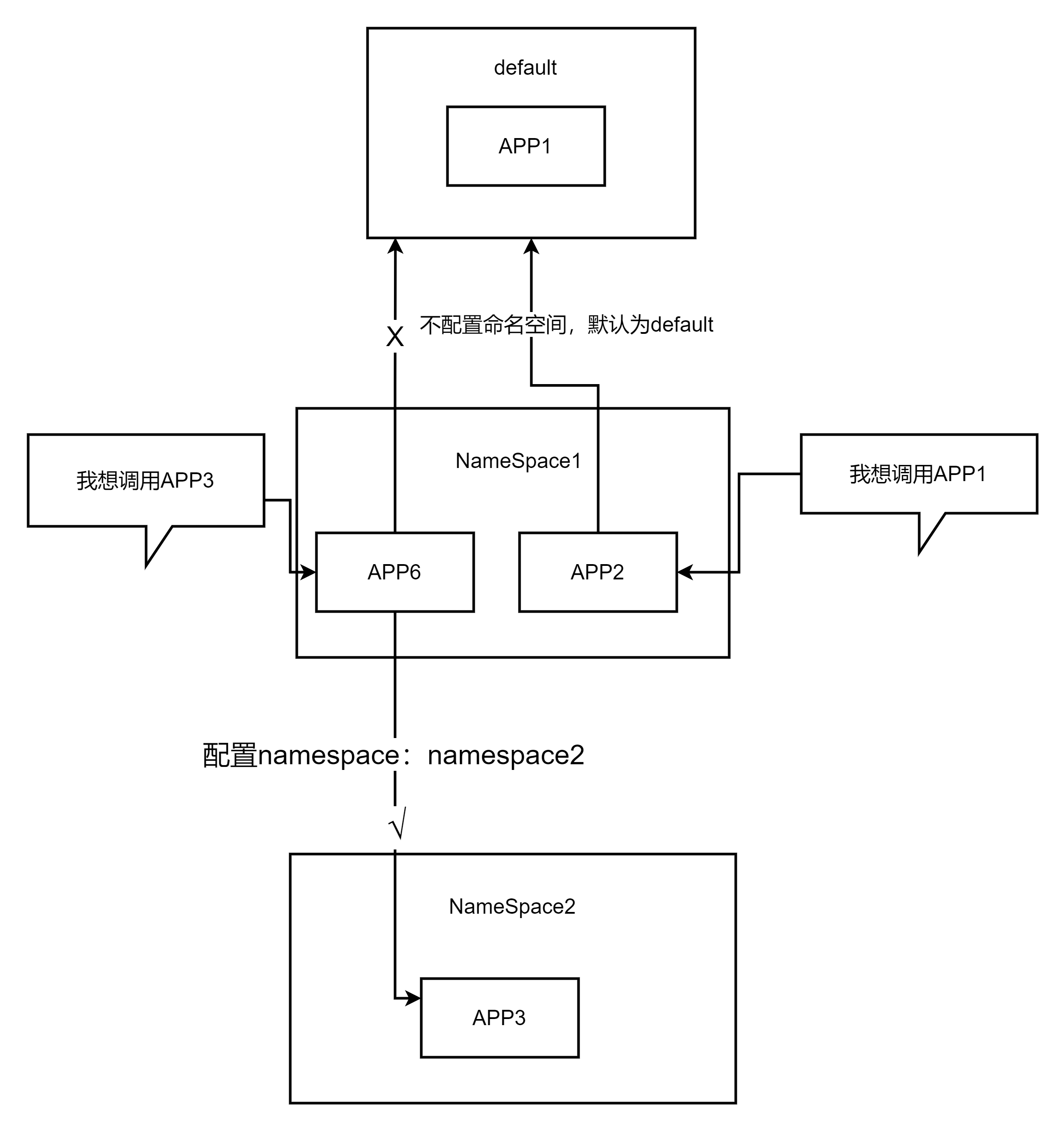
为了避免这个问题,请确保在部署和管理服务时,建议大家始终使用正确的命名空间。在执行kubectl命令时,可以使用--namespace参数来指定目标命名空间。例如:
kubectl get pods --namespace=test-namespace
这将列出位于test-namespace命名空间下的Pods。此外,在创建和管理服务时,也要确保正确指定目标命名空间。例如,在创建Deployment时,可以在yaml文件中使用namespace字段指定目标命名空间:
apiVersion: apps/v1
kind: Deployment
metadata:name: test-appnamespace: test-namespace
...
确保Deployment部署在test-namespace命名空间下。通过正确使用命名空间,可以保证每个服务被正确隔离,并且相关的服务器请求可以顺利到达。
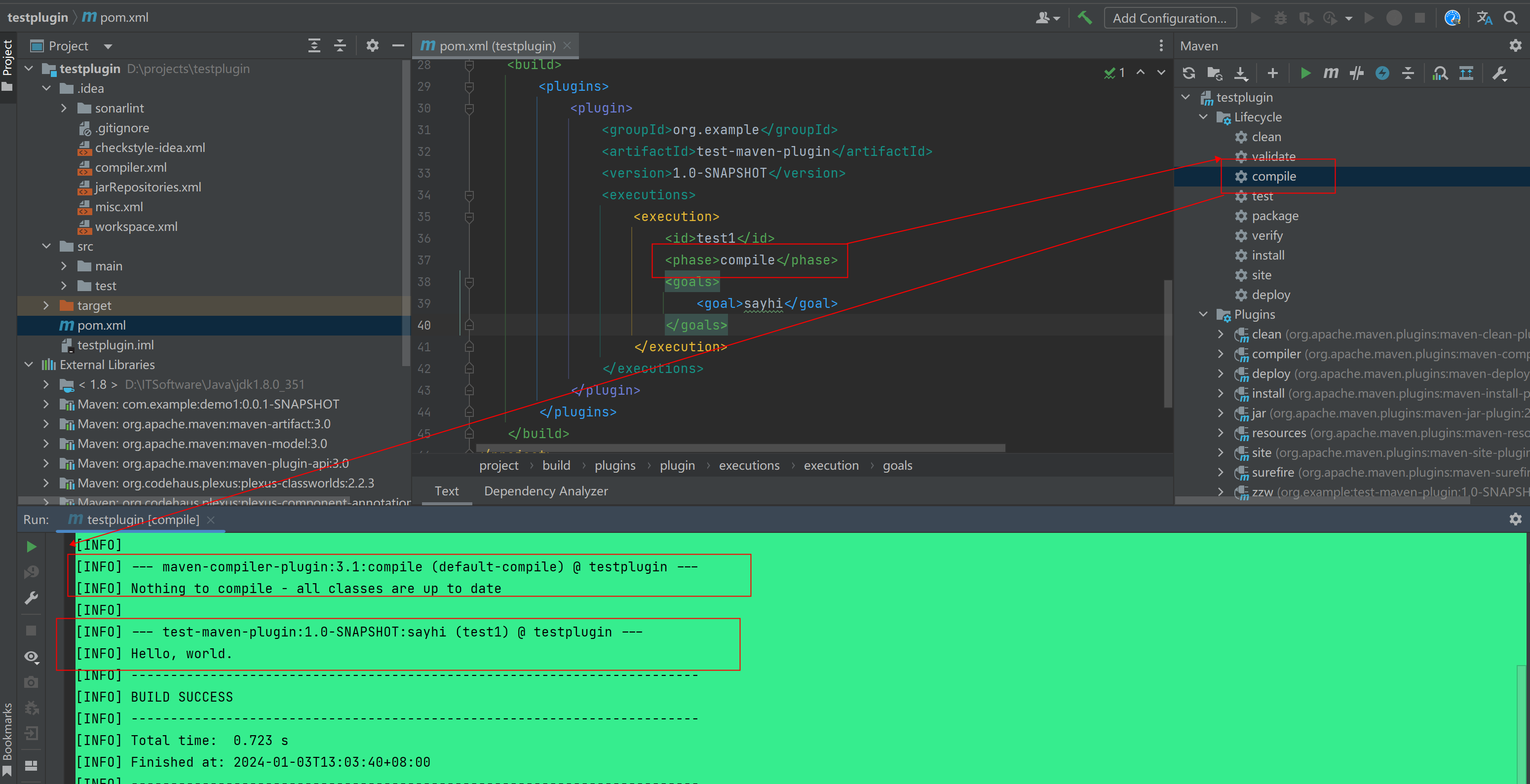
资源问题:不进行设置资源请求和限制的Pod(命名空间也没有控制)
在Kubernetes集群中,正确地管理资源对于保持整个集群的稳定性非常重要。默认情况下,Pod并没有任何资源限制,除非我们显式地对其进行适当的配置,否则可能会导致Node节点的CPU和内存资源耗尽。
解决方案
在所有的Pod上设置适当的资源请求和限制,以减少资源竞争的问题。通过指定资源请求,Kubernetes可以为我们的Pod预留特定数量的资源,从而避免将其调度到无法提供足够容量的节点上。
设置资源限制
限制Pod使用的最大资源量,当Pod超过CPU或内存限制时,Kubernetes会对其进行限制,例如,限制超过CPU限制的Pod的处理能力,或者当达到内存限制时触发内存不足 (OOM) 来终止Pod的运行。下面是一个示例,展示如何在Pod的配置中设置资源请求和限制的参数:
apiVersion: v1
kind: Pod
metadata:name: test-pod
spec:containers:- name: test-serverimage: test-imageresources:requests:cpu: "0.5"memory: "1Gi"limits:cpu: "1"memory: "2Gi"
参数解释:
- limits:Pod对CPU和内存的最大限制。
- requests:Pod对CPU和内存的最小需求
- cpu: 0.5 或 500m:表示0.5个CPU核心或500毫核(mCPU)的CPU资源请求/限制。
- 1:表示1个整数CPU核心的CPU资源请求/限制。
注意:请根据具体需求和应用程序的资源消耗情况,来设置适当的资源请求和限制,以确保集群的稳定性和有效的资源利用。
状态问题:优化和使用Liveness和Readiness探针
Kubernetes探针是一种能够增加应用程序弹性的重要工具。它们可以向Kubernetes Pod报告应用程序的健康状况。
Liveness探针
当容器出现问题时(例如内存溢出)或Liveness探针的请求超时,Liveness探针会通知Kubernetes重新启动容器,以确保应用程序的可用性。
Readiness探针
Kubernetes提供了Readiness探针来发现并处理这些情况。容器所在的Pod会报告其未就绪状态的信息,并且将不接收来自Kubernetes Service的流量。
例如:应用程序在启动时可能需要加载大量数据或配置文件,或者在启动后需要等待外部服务。在这种情况下,我们既不希望停止应用程序的运行,也不希望将请求发送到它。
通过合理配置 Liveness 和 Readiness 探针,我们能够更好地监测和管理应用程序的状态,提高应用程序的可用性,并确保容器在适当的时候进行重新启动,从而提高整体系统的稳定性。
以下是一个示例,展示了如何在 Pod 的配置中设置 Liveness 和 Readiness 探针:
apiVersion: v1
kind: Pod
metadata:name: test-pod
spec:containers:- name: test-serverimage: test-imagelivenessProbe:httpGet:path: /healthport: 80initialDelaySeconds: 3periodSeconds: 5readinessProbe:httpGet:path: /readinessport: 80initialDelaySeconds: 5periodSeconds: 10
所以首先探针一定要配置,此外要应对IO密集型以及CPU密集型等场景进行设置对应的参数值,切勿一套配置Cover主全场,那是不可能的。
对此我深有体会,总是出现服务负荷过高的时候,总是被探针Kill掉。
我的建议是:对于敏感度不高,且不是核心数据服务(无状态化的),可以酌量调大一些。肺腑之言。
最后总结
以上是作者根据个人经验和使用中出现的一些问题和错误的总结。希望其他开发者能够从中受益,避免犯类似的错误。我们选择使用Kubernetes的原因之一就是它具备弹性扩容的能力。正确的配置可以使Kubernetes在需求高峰期自动添加新的Pod和节点,实现动态的水平扩容和垂直扩容。然而,不幸的是,许多团队在自动扩容方面存在一些不可预测性的问题。