1、redis的持久化
"Redis 如何将数据写入磁盘",首先要明白的时候,我们使用的redis的数据保存在内存上的,也就是说,只要我们的电脑关机或者重启服务器,那么在内存中的数据就会消失,所以要想持久化的存储,就必须将我们的数据写入内存。redis的持久化的技术大致可以分为两类,一个是RDB,一个是AOF。
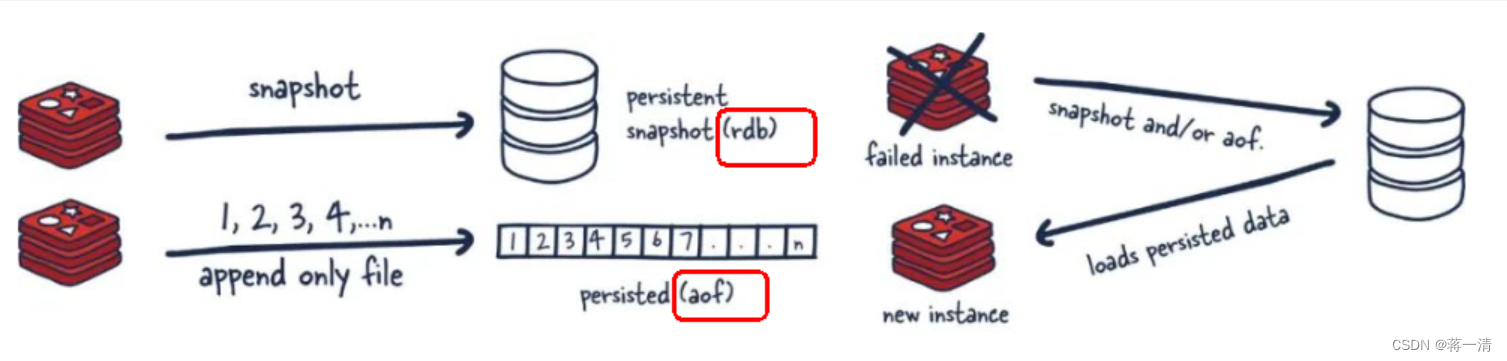
1.1、RDB (Redis Database)
RDB 持久性以指定的时间间隔执行数据集的时间点快照。在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot内存快照,它恢复时再将硬盘快照文件直接读回到内存里。
实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。在备份的时候它执行的是全量快照,就是把内存中的所有数据都记录到磁盘中。这样一来即使故障宕机,快照文件也不会丢失,数据的可靠性也就得到了保证。这个快照文件就称为RDB文(dump.rdb),其中,RDB就是Redis DataBase的缩写。
RDB配置文件,首先大概了解啦,RDB是基于快照的方式,隔一段时间然后执行快照然后保存数据,那么问题是时间间隔是多久,有没有什么附加条件。随着redis的版本的更新,关于RDB的配置文件也在不断的更新。
在6.2以前呐,是自动触发,大概的意思就是在规定的时间间隔中,如果多少有数据发生修改,达到这个设定的阈值就触发快照。
#每隔900秒 如果有1个key发生变化的化就备份文件
save 900 1
#每隔300秒 如果有10个key发生变化的化就备份文件
save 300 10
#每隔60秒 如果有10000个key发生变化的化就备份文件
save 60 10000在redis6.2开始,默认的时间频率发生了变化,但是大概的思路还是在指定的时间间隔中有多少key发生变化就触发快照,大概就是快照的频率降低了,没有之前那种更新的很频繁。
1.1.1、自动触发
自动触发就是修改配置文件,然后设定快照的触发条件,然后当条件触发的时候自动的执行。
修改配置文件
使用vim编辑器编辑redis.conf的配置文件,这里我就不做什么修改
440 # save 3600 1 300 100 60 10000441 save 3600 1 300 100 60 10000修改dump文件的保存路径
512 # Note that you must specify a directory here, not a file name.513 dir /software/redis/redis-7.2.3/redisconf/dumpfiles修改dump文件名称
#这里没有做修改
489 dbfilename dump.rdb修改完毕后可以重启一下redi,然后在客户端中查看数据配置的,文件保存的路径是不是配置的。
> CONFIG GET dir
dir
/software/redis/redis-7.2.3/redisconf/dumpfiles
> CONFIG GET port
port
6379
> CONFIG GET save
save
3600 1 300 100 60 10000然后当我们的数据发生变化到某一阈值就会触发快照,然后保存数据。

好了,现在有啦备份的文件,问题是怎么把它里面的数据恢复出来,将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。另外执行flushall/flushdb命令也会产生dump.rdb文件,但里面是空的,无意义。
重启redis的话,然后回到指定的备份文件中读取数据。既然使用清空数据库的和showdown命令都会将dump.rdb文件文件清空然后覆盖之前的备份文件,其实清空我还理解,这个关闭我有点不太理解,为什么关闭还要备份,而且是空的数据,就很离谱!
分机隔离可以解决上面的问题嘛,我试了一下,使用linux版本的提供服务,然后window版本的当作客户端,执行了shutdown后,对数据没有影响,备份数据可以正常恢复。使用linux下的也没有影响!!!
1.1.2、手动触发
手动触发就是使用redis的命令来完成生成RDB文件,分别是save和bgsave。save命令执行会阻塞当前的redis服务器,直到持久化的工作完成,而且子啊save命令执行期间,redis不能处理其他的命令,(线上禁止使用)。
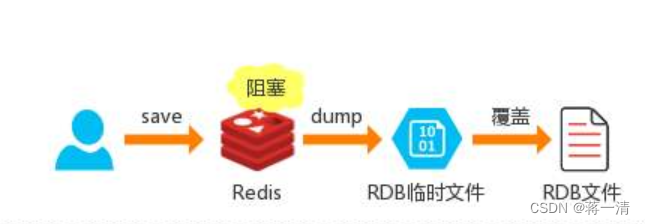
bgsave命令的执行期间,redis会在后台异步进行快照的操作,采用的不是阻塞的方式,在备份的同时还可以响应客户端的请求,触发方式会fork一个子进程由子进程来完成备份持久化的过程。

此外使用lastsave可以获取最近一次的成功执行备份的时间戳!
> LASTSAVE
17041806661.1.3、总结
1.1.3.1、优点
RDB的优点,是对数据的整体的备份所以使用RDB可以进行大规模的数据备份和恢复,可以按照业务定时的备份,默认使用的是bgsave,不影响主进程。和AOF相比RDB文件在内存中的加载的速度更快。对数据完整性和一致性不高。
1.1.3.2、缺点
在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失从当前至最近一次快照期间的数据,快照之间的数据会丢失。内存数据的全量同步,如果数据量太大会导致I/0严重影响服务器性能。RDB依赖于主进程的fork,在更大的数据集中,这可能会导致服务请求的瞬间延迟。fork的时候内存中的数据被克隆了一份,大致2倍的膨胀性,需要考虑。
1.1.3.3、修复dump文件
使用redis-check-rdb可以检查和修复dump文件。
[root@localhost redisconf]# redis-check-rdb /software/redis/redis-7.2.3/redisconf/dumpfiles/dump.rdb
[offset 0] Checking RDB file /software/redis/redis-7.2.3/redisconf/dumpfiles/dump.rdb
[offset 26] AUX FIELD redis-ver = '7.2.3'
[offset 40] AUX FIELD redis-bits = '64'
[offset 52] AUX FIELD ctime = '1704180537'
[offset 67] AUX FIELD used-mem = '988016'
[offset 79] AUX FIELD aof-base = '0'
[offset 81] Selecting DB ID 1
[offset 114] Checksum OK
[offset 114] \o/ RDB looks OK! \o/
[info] 3 keys read
[info] 0 expires
[info] 0 already expired1.1.3.4、触发RDB的条件
-
根据配置文件中的配置触发
-
手动的save/bgsave命令
-
执行flushdb/flushall命令会产生备份文件,但是没有数据
-
执行shutdown并且没有开启AOF持久化
-
主从复制,主节点自动触发
关于如何禁用配置中的触发条件。可以临时配置使用
redis-cli config set save ""想要永久的修改,在配置文件中修改为 save ""
1.1.3.5、RDB的优化配置
配置文件SNAPSHOTTING模块,前面已经修改过dump的存储目录、dump文件名以及save的参数。当然还有一些其他的配置参数可以调优。
stop-writes-on-bgsave-error yes默认yes,如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制这种不一致,那么在快照写入失败时,也能确保redis继续接受新的写请求。
rdbcompression yes默认yes,对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。 如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能 。
rdbchecksum yes默认yes ,在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdb-del-sync-files no在没有持久性的情况下删除复制中使用的RDB文件启用。默认情况下no,此选项是禁用的。
1.2、AOF (Append Only File)
以日志的形式来记录每个写操作,将redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
开启aof,修改redis.conf的配置文件
1390 appendonly yes默认情况下,redis是没有开启AOF(append only file)的。开启后就可以执行AOF备份。然后将数据保存在appendonly.aof。

| 序号 | 描述 |
|---|---|
| 1 | Client作为命令的来源,会有多个源头以及源源不断的请求命令。 |
| 2 | 在这些命令到达Redis Server 以后并不是直接写入AOF文件,会将其这些命令先放入AOF缓存中进行保存。这里的AOF缓冲区实际上是内存中的一片区域,存在的目的是当这些命令达到一定量以后再写入磁盘,避免频繁的磁盘IO操作。 |
| 3 | AOF缓冲会根据AOF缓冲区*同步文件的三种写回策略*将命令写入磁盘上的AOF文件。 |
| 4 | 随着写入AOF内容的增加为避免文件膨胀,会根据规则进行命令的合并(又称*AOF重写)*,从而起到AOF文件压缩的目的。 |
| 5 | 当Redis Server 服务器重启的时候会从AOF文件载入数据。 |
1.2.1、写回策略
redis中的AOF有三种写回策略,always,同步写回,每个写命令执行完立刻同步地将日志写回磁盘。everysec,每秒写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔1秒把缓冲区中的内容写入磁盘。no,操作系统控制的写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。

配置文件的位置:
1448 # appendfsync always
1449 appendfsync everysec
1450 # appendfsync no
1451 1.2.2、文件保存
在redis6以前的AOF文件的保存路径和RDB保存文件的位置一样,都是通过redis.conf配置文件的 dir 配置,就是生成的文件存放在一起,不便于维护,因为AOF的备份文件存放在dir下的appendnoly目录下。接下来修改配置文件啦。
# Note that you must specify a directory here, not a file name.
dir /software/redis/redis-7.2.3/redisconf/backupfiles
#文件名
appendfilename "appendonly.aof"
#文件目录
appenddirname "appendonlydir"
关于文件的设置,在redis6之前的redis的AOF的备份文件有且只有一个,也就是上面的appendonly.aof,但是在redis7以后,AOF的备份文件不止一个。Redis7.0 Multi Part AOF的设计是指将AOF的备份文件拆分成三种类型,
-
BASE:表示基础的AOF,它一般由子进程通过重写产生,该文件最多只有一个
-
INCR:表示增量AOF,它一般会在AOFRW开始执行时候被创建,该文件可以存在多个
-
HISTORY:表示历史AOF,它是由BASE和INCR AOF变化而来,每一次的AOFRW完成的时候,本次AOFRW之前对应的BASE和INCR AOF都将变成HISTORY,HISTORY类型的AOF会被redis自动删除。
为了管理这些AOF文件,redis引入了一个manifest(清单)文件来跟踪,管理这些AOF文件,同时为了便于备份AOF备份和拷贝,redis将所有的AOF文件和manifest文件放入一个单独的文件目录中,目录名由appenddirname配置。
# - appendonly.aof.1.base.rdb as a base file.
# - appendonly.aof.1.incr.aof, appendonly.aof.2.incr.aof as incremental files.
# - appendonly.aof.manifest as a manifest file.然后配置之后可以看到生成的文件在我指定的文件夹中

1.2.3、shutdown命令
使用shutdown命令,之前也正常使用,但是不知道怎么回事,开启了RDB和AOF后就提示报错,然后一直关闭不掉redis,提示信息如下:
(error) ERR Errors trying to SHUTDOWN. Check logs.然后大概是因为没有配置log日志文件的位置,然后还有权限,所以我们接下来就是要处理这个问题,然后来配置filelog
#使用命令查看
config get filelog
#默认是空串
#然后使用vim编辑redis.conf
logfile /software/redis/redislog/redis-log.log
#修改一下创建的文件夹的权限
chmod 777 redislog这里说一下,要提前创建号目录,对于日志文件的话,不需要手动去创建,但是你要指定名字比如redis-log.log,然后重启一下,如果关闭不掉话可以先使用kill pid,来杀死进程,然后重启服务端,客户端,最后在客户端测试shurdown命令是否可以正常的关闭。
1.2.4、备份文件的恢复
1.2.4.1、正常恢复
修改后的配置文件就已经生效了,然后再指定的目录下也有啦备份文件,想要测试的话,首先清空数据库,然后执行shutdown,然后为了去除RDB的备份文件的影响,可以把dump文件删除掉,最后再重新启动redis服务。
另外也可以执行读写操作,然后观察三个类型的文件哪一个会发生改变!
1.2.4.2、异常恢复
就是假如某一时刻,redis正在执行写操作,但是此刻redis服务挂掉了,但是这个时候redis中的AOF的备份文件肯定是有错误的,只写了一半,然后重启 Redis 之后就会进行 AOF 文件的载入,发现启动都不行,o(╥﹏╥)o,异常修复命令:redis-check-aof --fix 进行修复,然后修复完毕后重新启动就可以啦!这里只用修复INCR文件就可以。
[root@localhost ~]# redis-check-aof --fix /software/redis/redis-7.2.3/redisconf/backupfiles/appendonlydir/appendonly.aof.1.incr.aof
1.2.5、总结
1.2.5.1、优点
可以更好的保护数据不丢失,性能比较高,有三种写回策略,即使丢失数据也只是很少的一部分,对于损坏的AOF文件,也可以使用工具去修复文件。有重写机制
可以紧急恢复文件,大概的意思是这样的如果不小心使用flushall命令导致数据清空,只要没有执行日志的重写,然后可以找到AOF文件,然后编辑备份文件,删除最新的错误命令,然后重启redis,就可以恢复之前的数据。
1.2.5.2、缺点
相同数据集的数据而言aof文件要远大于rdb文件,恢复速度慢于rdb,aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
1.2.5.3、重写机制
是这样的,随着我们进行写命令越来越多,那么自然我们的AOF备份文件也会也来越大,这样的话随着文件的变大,占用服务器内存也越来越大以及AOF的恢复时间也越来越长。为了解决这个问题,Redis新增了重写机制,当AOF文件的大小超过所设定的峰值时,Redis就会自动启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集或者可以手动使用命令 bgrewriteaof 来重新。
AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
AOF文件重写触发机制:通过 redis.conf配置文件中的 auto-aofrewrite-ercentage:认值为100.以及auto-aof-rewritemin-size: 64mb 配置,就是说默人Redis会记录上次重写时的AOF大小,默认配置是当A0F文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
重写机制:
-
1:在重写开始前,redis会创建一个“重写子进程”,这个子进程会读取现有的AOF文件,并将其包含的指令进行分析压缩并写入到一个临时文件中。
-
2:与此同时,主进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的AOF文件中,这样做是保证原有的AOF文件的可用性,避免在重写过程中出现意外。
-
3:当“重写子进程”完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新AOF文件中
-
4:当追加结束后,redis就会用新AOF文件来代替旧AOF文件,之后再有新的写指令,就都会追加到新的AOF文件中
-
5:重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似
1.2.5.3.1、自动触发
满足配置文件中的选项后,Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb1.2.5.3.2、手动触发
客户端向服务器发送bgrewriteaof命令。
1.2.5.4、优化配置

1.3、RDB-AOF混合持久化
首先关于备份的方式有RDB和AOF两种,之前的操作也证明了两个同时配置的话,其实是不冲突的,也就是支持两种方式共存,但是关于备份的数据的恢复,是从RDB还是AOF哪个备份恢复的,官方文档说,默认是RDB作为数据持久化的,但是当我们修改了配置文件开启了AOF后,文件的备份从AOF中来,AOF占主导地位。
AOF>RDB数据恢复顺序和加载流程,再同时开启了RDB和AOF持久化,重启进行数据加载的时候只加载AOF不加载RDB。
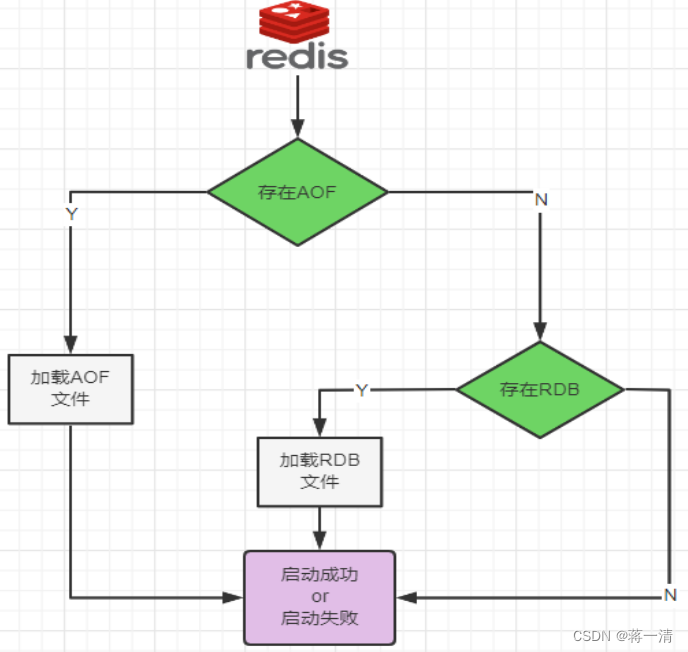
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储,AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾。
同时开启两种持久化方式,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?不建议只是使用AOF,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),留着rdb作为一个万一的手段。
开启混合模式设置aof-use-rdb-preamble的值为 yes yes表示开启,设置为no表示禁用
1520 aof-use-rdb-preamble yesRDB镜像做全量持久化,AOF做增量持久化、先使用RDB进行快照存储,然后使用AOF持久化记录所有的写操作,当重写策略满足或手动触发重写的时候,将最新的数据存储为新的RDB记录。这样的话,重启服务的时候会从RDB和AOF两部分恢复数据,既保证了数据完整性,又提高了恢复数据的性能。简单来说:混合持久化方式产生的文件一部分是RDB格式,一部分是AOF格式。----> AOF包括了RDB头部+AOF混写
2、redis的事务
可以一次执行多个命令,本质是一组命令的集合。一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞。一个队列中,一次性、顺序性、排他性的执行一系列命令。
| 概括 | 描述 |
|---|---|
| 1 单独的隔离操作 | Redis的事务仅仅是保证事务里的操作会被连续独占的执行,redis命令执行是单线程架构,在执行完事务内所有指令前是不可能再去同时执行其他客户端的请求的 |
| 2 没有隔离级别的概念 | 因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这种问题了 |
| 3不保证原子性 | Redis的事务不保证原子性,也就是不保证所有指令同时成功或同时失败,只有决定是否开始执行全部指令的能力,没有执行到一半进行回滚的能力 |
| 4 排它性 | Redis会保证一个事务内的命令依次执行,而不会被其它命令插入 |
2.1、事务命令
| 序号 | 命令及描述 |
|---|---|
| 1 | DISCARD 取消事务,放弃执行事务块内的所有命令。 |
| 2 | EXEC 执行所有事务块内的命令。 |
| 3 | MULTI 标记一个事务块的开始。 |
| 4 | UNWATCH 取消 WATCH 命令对所有 key 的监视。 |
| 5 | [WATCH key key ...] 监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。 |
Redis Multi 命令用于标记一个事务块的开始。事务块内的多条命令会按照先后顺序被放进一个队列当中,最后由 EXEC 命令原子性(atomic)地执行。
语法:Multi
Redis Exec 命令用于执行所有事务块内的命令。事务块内所有命令的返回值,按命令执行的先后顺序排列。 当操作被打断时,返回空值 nil 。
语法:EXEC
例子:
#正常执行
> MULTI
OK
> set k1 v1
QUEUED
> set k2 v2
QUEUED
> set k3 v3
QUEUED
> EXEC
OK
OK
OK
> get k1
v1Redis Discard 命令用于取消事务,放弃执行事务块内的所有命令。总是返回 OK 。
语法:DISCARD
例子:
> MULTI
OK
> set k1 v1
QUEUED
> set k2 v2
QUEUED
> INCR count
QUEUED
> DISCARD
OK
> get count
0
> get k1
nullRedis Watch 命令用于监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。redis使用watch来提供乐观锁,类似CAS(check-and-set)。
-
悲观锁: 悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。
-
乐观锁:乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。
大概的意思就是,监控这个key,如果再事务执行的过程中,监控的key被修改,那么这个事务就失败了。
语法:WATCH key [key ...]
例子:
> set count 0
OK
> watch count
OK
> MULTI
OK
> set k1 v1
QUEUED
> set k2 v2
QUEUED
> EXEC
OK
OK
> MULTI
OK
> set k3 v3
QUEUED
> incr count
QUEUED
> EXEC
OK
1
#模拟被修改的情况
> watch count
OK
> MULTI
OK
> incr count
QUEUED
> set k4 v4
QUEUED
#执行到这里的时候我又启动一个客户端,然后修改count
192.168.200.88:6379[1]> keys *
1) "k2"
2) "k3"
3) "k1"
4) "count"
192.168.200.88:6379[1]> incr count
(integer) 2
#然后执行事务
> EXEC
nullRedis Unwatch 命令用于取消 WATCH 命令对所有 key 的监视。总是返回 OK 。
语法: UNWATCH
例子:
> UNWATCH
OK此外想要取消监视的话还有,只要执行exec后之前所有监控锁都会被取消,客户端取消连接也会导致所有的监控锁取消。
此外事务的执行过程中,如果有错误redis进行语法检查出来的话,那么这个事务的所有命令都不生效,但是如果对于没有语法检查出来的命令,但是在执行的过程中报错,那么只有错误的命令不生效,其他的命令正常执行!

![[讲座] - 闲聊工业设计](https://img-blog.csdnimg.cn/direct/12be0a3b9cd44e37a19e227c75216cd9.png)