作者:vivo 互联网数据库团队 - Han Chaobing
介绍 vivo 数据库备份恢复功能的演化,以及对备份文件的功能扩展。
一、概述
vivo互联网领域拥有的数据库组件分别为 MySQL、MongoDB、TiDB 等,其中MySQL集群占比绝大部分, MongoDB 集群占比小部分, TiDB 集群占比更小。为了介绍方便,本文把改造前的数据库备份恢复系统称为旧备份恢复系统,改造后的数据库备份恢复系统称为新备份恢复系统。我们将从旧的架构系统开始,发现其不足,慢慢的优化形成新的系统架构。
二、旧备份恢复系统
旧备份恢复系统架构图
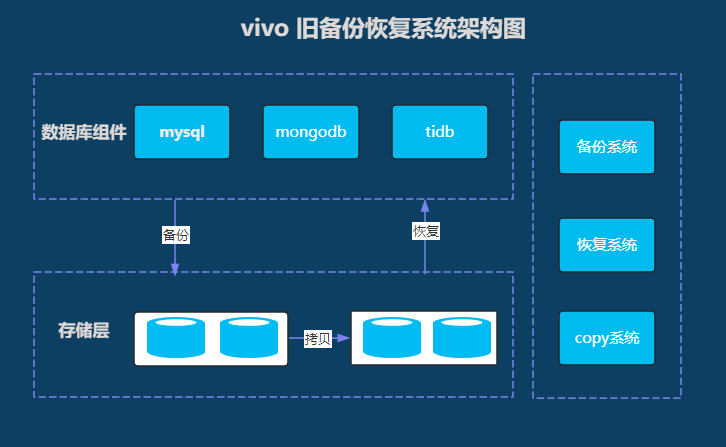
旧备份恢复系统是基于Python 语言开发的,使用分布式文件系统GlusterFS,Python作为开发语言,使用任务调度模块Celery下发备份和恢复任务。或许由于之前开发时间紧迫,在服务可用性和Redis组件高可用性上,并未做过多的工作。若出现物理机宕机或网络等问题,将直接影响备份系统的稳定性。
2.1 备份模块
备份模块是旧备份恢复系统的一个主要功能服务,主要用于MySQL、TiDB、MongoDB 组件的备份调度、备份等任务,来完成每日的数据库备份。旧备份恢复系统主要使用的是逻辑备份,在仅有5台物理机上负责备份任务的发起和执行,由于互联网的体量大,数据库全备一次需要2天的时间,因此备份的成功率是按照2天统计。由于文件系统的高负载,以及备份中锁等原因也会出现备份调度失败的情况,导致整个物理机上的实例不能再次发起备份,需要手工维护才能继续备份,系统维护上也非常麻烦。
2.2 组件备份介绍
MySQL和TiDB的备份
【备份工具】:Mydumper + Xtrabackup(MySQL)
【备份方式】:逻辑备份 + 物理机备份
-
逻辑备份 Mydumper 工具
Mydumper 是一款社区开源的逻辑备份工具。该工具主要由 C 语言编写,目前由 MySQL 、Facebook 等公司人员开发维护。
参考官方介绍,Mydumper 主要有以下几点特性:
-
支持多线程导出数据,速度更快。
-
支持一致性备份。
-
支持将导出文件压缩,节约空间。
-
支持多线程恢复。
-
支持以守护进程模式工作,定时快照和连续二进制日志。
-
支持按照指定大小将备份文件切割。
-
数据与建表语句分离。
Mydumper的主要工作步骤:
-
主线程 flush tables with read lock, 施加全局只读锁,以阻止dml语句写入,保证数据的一致性。
-
读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供恢复使用。
-
start transaction with consistent snapshot; 开启读一致事务。
-
启用n个(线程数可以指定,默认是4)dump线程导出表和表结构。
-
备份非事务类型的表。
-
主线程 unlock tables,备份完成非事务类型的表之后,释放全局只读锁。
-
基于事务dump innodb tables。
-
事务结束。
基于Mydumper 以上的特性,PingCAP公司针对 TiDB 的特性进行了优化,Mydumper 包含在 tidb-enterprise-tools 安装包中。对于 TiDB 可以设置 tidb_snapshot 的值指定备份数据的时间点,从而保证备份的一致性,而不是通过 FLUSH TABLES WITH READ LOCK 来保证备份一致性。使用 TiDB 的隐藏列 _tidb_rowid 优化了单表内数据的并发导出性能。TiDB 官方早起提供了Mydumper备份工具,后期提供了BR 物理机备份工具,然而物理机备份受限制于文件系统,在GlusterFS 文件系统下,只能使用Mydumper 做逻辑备份。
Mydumper 备份属于逻辑备份,需要读全表,因此备份效率会低很多。同一个数据库,在文件系统不变的情况下,逻辑备份和物理备份的对比。
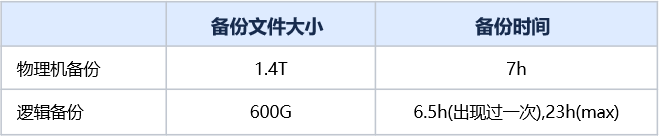
从该统计可以看出,逻辑备份时间很不稳定,Mydumper 备份最短一次是6.5个小时,最长在23小时,而物理机备份时间基本维持在7个小时左右。
-
物理机备份Xtrabackup工具
Xtrabackup是Percona团队开发的用于MySQL数据库物理热备份的开源备份工具,具有备份速度快、支持备份数据压缩、自动校验备份数据、支持流式输出、备份过程中几乎不影响业务等特点,是目前各个云厂商普遍使用的MySQL备份工具。
由于物理机备份未使用压缩和打包,备份的文件受限于表的大小,在备份特别大的表时,总会出现文件系统分布不均匀的情况,大部分磁盘在80%的时候,某些磁盘的使用容量却超过95%,需要经常登录文件系统删除备份文件来消除告警。另外物理备份配置比例较小,备份占比不高。后续虽然经过一些了优化(增加打包和文件分拆功能),解决了磁盘分布不均的问题。但备份成功率提升不明显。
MongoDB 备份
【备份工具】:mongodbdump
【备份方式】:逻辑备份
【备份时间】:全天时间段
mongodbdump 是MongoDB 官方提供的备份程序,对于小于100G以内的备份还能轻松应付,但对于大于100G的实例虽然也能备份,不过备份时间会比较长。vivo目前有几十个大于1T的实例,备份难度可想而知,备份成功率很低。有些MongoDB 实例因为太大,导致从未成功过。2天的备份成功率基本在20%左右,哪怕统计一周的成功率也无法达到40%,大于1T的MongoDB 实例,因为文件系统过慢,总是出现备份一半就出现失败,虽经过多次优化,哪怕是把备份盘放置本地盘,再拷贝至文件系统,虽然备份成功率有所提高,但成功率依旧很差,而且还需要经常手工维护。
2.3 恢复模块
恢复模块也是基于Python开发,由Celery 模块调度恢复策略,根据已配置的数据库备份方式,选择相应的逻辑和物理机恢复。
逻辑恢复是直接使用备份文件对目标库进行恢复,不过逻辑恢复很慢,之前做过一次上T的数据库恢复,竟然恢复了1天左右的时间。不过逻辑备份也是有好处的,在恢复单个表时,可以直接把该表的文件系统拷贝出来,直接使用myloader程序直接恢复,可以非常快速的恢复单表,这比物理机恢复单个表要快很多。不过这里的恢复需要手工操作,代码并未实现该项功能。。
物理机恢复是直接使用文件系统挂载的方式,直接把文件系统挂载至目标机器,把备份的文件拷贝纸目标机器来恢复数据,功能相对简单一些,由于是直接拷贝文件,恢复速度相对会快一些。
恢复模块仅用于增加从库实例和延迟从库,未做到任一时间点的恢复,功能相对单一。
2.4 文件系统
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上。
vivo的备份模块使用的GlusterFS 文件系统,分别在两个区域的机房中。其中A机房是用于数据库备份和恢复,B机房主要用于异地灾备,增加备份文件的安全性。
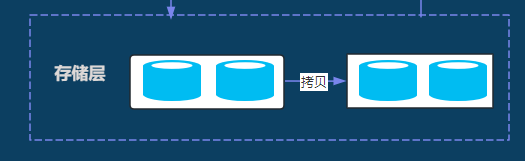
A机房的文件系统主要挂载至备份恢复的主控机上,并且A机房文件系统也会挂载到需要物理备份的物理机上。数据库的物理机任何DBA人员均可登录,只要登录该机器上,便可以操作任一备份文件,这对于备份文件是十分危险的;由于A机房是单机房,存在单机房故障的可能,基于以上两点,B机房就应运而生了。
B机房的文件系统只挂载至备份恢复机器的主控机上,并且把A机房的备份文件拷贝至B机房,同时管控备份恢复的主控机权限,便可以确保备份文件系统的安全性。基于此,备份恢复主控机及B机房物理机权限只有2个人有权限访问,从而确保备份文件的安全性。
2.5 Copy 模块
Copy 模块主要用于备份文件的拷贝,让备份文件保留2份副本,防止因A机房宕机,误删等情况下,导致备份文件的缺失。
A机房的文件系统用于数据库直接备份,B机房的文件系统中的数据,是由A机房通过Copy程序拷贝过来,在B机房保留一份副本。由于A机房承接备份和恢复两大功能,而且还要应用于拷贝文件至B机房,还要定时删除过期的备份文件,由此可知A机房的文件系统压力将有多大,这也是直接导致Copy程序效率将有多差,最终结果是B机房的文件要远远落后A机房,导致B机房异地备份名存实亡,Copy模块也变得形同虚设。
2.6 旧备份恢复系统存在问题
1. 效率不足
MySQL 两天才能完成一次全备份,而且恢复实例时间也比较长,不能满足日常恢复实例的时间要求。
MongoDB 大容量数据库比较多,而且逻辑备份已经无法应付现在的场景,超过50%以上的MongoDB集群已无法成功备份。
2. 旧功能不足
旧备份恢复系统目前只有 备份模块、恢复模块、Copy模块,功能单一,已经不能满足互联网领域的快速发展。
备份系统是Python代码完成的,最初开发未考虑高可用,逻辑复杂,维护困难。
3. 文件系统方面
① 文件系统权限控制较弱,不能达到安全要求
-
A机房文件系统会有多处挂载,导致备份文件安全无法得到保障
② 文件系统压力较大,文件系统已经不堪重负
③ 异地灾备形同虚设
-
受文件系统读写的限制,异地灾备的文件系统存储的都是几天之前的备份文件
三、新备份恢复系统
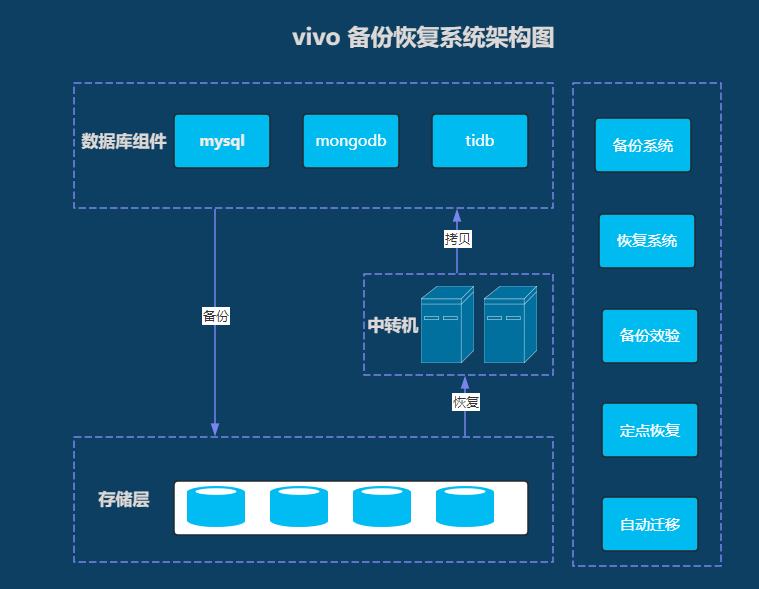
基于Python开发的旧备份恢复系统存在许多缺点,最后引入Java 开发人员和对象存储,对备份系统进行全方位的改造,经过一系列改进,互联网领域目前的备份系统架构图如下:
3.1 新备份恢复系统效率的提升
新备份恢复系统改善
Java 语言 + Redis cluster
Redis 系统终于从主从版本改成Redis cluster 集群版本,Redis可用性得到很大的提高。
1. MySQL备份效率提升
【备份工具】:Mydumper + Xtrabackup
【备份方式】:逻辑备份 + 物理机备份
【备份策略】:备份不再受限于文件系统的影响,为了快速备份、对于数据库data目录存储大于20G使用物理备份,小于20G的使用逻辑备份。
【备份时间】:00-10 之间就能完成当天的备份,大大的提高了备份效率。
在互联网领域数据库新的备份系统中,MySQL备份恢复采用的是逻辑备份与恢复、物理备份与恢复并存的模式,根据集群大小区分逻辑备份与物理备份。逻辑备份与恢复采用的工具是Mydumper 和 myloader,物理备份采用的是对Xtrabackup进行包装过的工具Xtrabackup_agent(主要是对备份文件上传至对象存储以及恢复从对象存储下载备份文件进行包装以及流式备份的包装)。
物理机备份在最后阶段会获取整个数据库的元数据锁,在日常的备份过程中经常会出现waiting_for的告警,经分析得知,大数据在对特定的表采集时,未释放元数据锁,而新的采集又要获取被备份系统已经持有的元数据锁,因此夜间的备份会告警出来,影响值班人员的休息,而且由于大数据采集SQL因为非常慢,经常与备份产生冲突,为了避免该冲突,备份增加 --ftwrl-wait-timeout参数,为了减少waiting_for的告警,目前的设置并不能避免waiting_for的告警,还需要优化慢SQL语句,才能做到治标治本。
--ftwrl-wait-timeout
指明执行flush tables with read lock前的等待时间,0表示不等待直接执行锁表命令,单位是s,若超过此参数设置的时间后还存在长时间执行的查询,则Xtrabackup终止运行。
--ftwrl-wait-threshold
show processlist 中的 SQL 执行时间,如果SQL 自行时间小于ftwrl-wait-threshold设定时间,直接执行flush tables with read lock 命令,如果SQL 执行时间大于ftwrl-wait-threshold设定时间,则等待。
目前备份系统的命令使用方式是
baseDir = fmt.Sprintf("/data/mysql%d", port)
args = append(args, fmt.Sprintf("--defaults-file=%s/conf/my.cnf", baseDir))
args = append(args, fmt.Sprintf("--datadir=%s/data", baseDir))
args = append(args, fmt.Sprintf("--socket=%s/run/mysql.sock", baseDir))
args = append(args, fmt.Sprintf("--user=%s", user))
args = append(args, fmt.Sprintf("--password=%s", pwd))
args = append(args, "--slave-info")
args = append(args, fmt.Sprintf("--ftwrl-wait-timeout=%d", 250))
args = append(args, fmt.Sprintf("--open-files-limit=%d", 204800))
args = append(args, "--stream=xbstream")
args = append(args, "–backup")
args = append(args, fmt.Sprintf("--parallel=%d", parallel))
args = append(args, fmt.Sprintf("--throttle=%d", throttle))
args = append(args, "–compress")增量备份
args = append(args, fmt.Sprintf("--incremental-lsn=%s", incrLsn))每次备份,我们会主动获取incremental-lsn,为下次增量备份做准备。
2. TiDB 备份效率提升
【备份工具】:Mydumper、br工具
【备份方式】:逻辑备份 + 物理机备份
【备份时间】:00:00-10:00
TiDB 官方提供了br 物理机备份工具,加上物理机备份与文件系统结合,备份效率也得到的大大提升,目前TiDB 4.0 以上的版本使用物理机备份+ 增量备份,需要设置gc_time 为48h,否则增量备份会报错。而对4.0以下的版本继续使用Mydumper进行备份。
3. MongoDB 备份效率提升
【备份工具】:mongodbdump + cp
【备份方式】:逻辑备份 + 物理机备份
【备份时间】:00:00-10:00
由于mongodbdump 逻辑备份对数据量大的实例备份十分困难,因此引入了MongoDB的物理备份。
-
物理备份实现逻辑
db.fsyncLock() 特性
db.fsyncLock() ensures that the data files are safe to copy using low-level backup utilities such as cp, scp, or tar. A mongod started using the copied files contains user-written data that is indistinguishable from the user-written data on the locked mongod.
Prior to MongoDB 3.2, db.fsyncLock() cannot guarantee that WiredTiger data files are safe to copy using low-level backup utilities.db.fsyncLock() 锁住整库后,可以直接对MongoDB 文件进行cp、scp或者tar 操作,因此,利用该特性进行物理机备份。
由于需要db.fsyncLock()需要锁整个库,为了不影响部分业务的读写分离要求,因此需要增加一个隐藏节点,为了节省资源,我们把其中3个副本中的一个副本作为隐藏节点,在任何业务需要时,可以直接转变为非隐藏节点提供服务,副本被设置为隐藏节点后,是不能对业务提供服务的,只做备份使用。
-
增加隐藏节点
增加隐藏节点
cfg = rs.conf()
cfg.members[2].priority = 0
cfg.members[2].hidden = true
cfg.members[2].votes = 1
rs.reconfig(cfg)隐藏节点需要具有投票,这样可以减少一个实例节点。
-
全备份命令
使用db.fsyncLock() 锁库
获取最新的oplog位置
next_ts=db.oplog.rs.find().sort({$natural:-1}).limit(1)
tar -cf 文件
使用 db.fsyncUnlock() 解锁记录oplog 位点是为了增量备份做准备
-
增量备份
增量备份是备份oplog,根据全备获取的最新的oplog 进行备份
使用db.fsyncLock() 锁库
last_ts=db.oplog.rs.find().sort({$natural:-1}).limit(1)
mongodump --host= 127.0.0.1 --port=27010 --username=mg_backup --password=123ASD123 --gzip --authenticationDatabase=admin -d local -c oplog.rs \
-q '{ts:{$gt:Timestamp("next_ts")}}' --archive=oplog.inc_2
使用 db.fsyncUnlock() 解锁因此,备份逻辑上也进行了改造,对于 小于20G的实例,使用mongodbdump逻辑备份,对于大于20G 的实例使用物理机备份。由于物理机备份直接拷贝物理文件,备份速度快了很多。而逻辑增量备份是备份oplog,oplog设置基本都在50G左右,因此逻辑增量备份也能满足需求。
-
物理恢复
① 全备恢复
tar -xf bull_back -C xxxx使用空实例,不直接接入之前的副本集中
② 增量恢复
mongorestore --archive=65.gzip --port=11303 --gzip --oplogReplay物理恢复主要用于MongoDB的定点恢复,日常添加从节点,都是使用MongoDB自身的数据同步。由于MongoDB 在公司占比份额较少,而且出现误删数据的几率也小,自维护MongoDB 依赖,仅仅出现过2次MongoDB定点恢复的案例。
4. 性能提升总结
基于备份逻辑及备份方式的改变,备份效率提高很大,未改造前,MySQL两天成功率才能达到98%以上,改造完毕后,MySQL备份基本在10点以前就能完成所有的备份,而且备份成功率能达到100%。
TiDB更改br 物理机备份后,成功率也提升至100%,而版本低于4.0以下的TiDB依旧使用Mydumper备份,但成功率也实现了质的飞跃。
MongoDB自从改成物理机备份后,成功率也提升至100%。虽然MongoDB的备份文件使用率不高,但使用备份文件恢复数据多达6次以上。
3.2 文件系统演化
文件系统使用的是vivo资源的对象存储系统。vivo对象存储提供海量、安全、低成本、高可靠的云存储服务,提供12个9的数据持久性,99.995%的数据可用性。提供多种语言SDK,开发者可快速便捷接入对象存储。
产品优势:
-
服务稳定可靠:提供12个9的数据可靠性保障。
-
存储空间大:提供PB级存储能力,存储空间按需扩展无上限;单个Bucket的容量无限制,单个文件(对象)最大支持48.8TB。
-
成本低:根据不同数据类型选择选择不同性能存储规格降低服务器成本,通过纠删码、数据删重、压缩等技术节省存储空间。
-
数据安全有保障:支持桶和对象级别的权限控制,通过防盗链、多种加密方法保障数据安全。
-
使用便捷:可通过SDK、控制台进行上传下载。
经过一系列的改造,备份效果得到了大大的改观,使用对象存储以后,基本不再考虑文件系统的压力及高可用性,省去了很多麻烦。而且对象存储无法直接查看和操作备份文件,文件的获取均需要程序操作,任何人员无法直接获取,增加了文件安全性。
3.3 备份系统功能扩展
1. 中转机组件
MySQL 集群添加实例的流程:先把备份文件从对象存储上下载到目标物理机上、合并解压备份文件、应用日志、启动实例、配置该实例成为主库的从库,添加从库实例完毕。
该添加从库实例功能上线后,我们发现物理机的原住民会突然出现并发执行SQL增加,业务服务访问数据库变慢的情况,经过排查发现:备份文件在合并解压时,会出现严重的io行为,该行为直接影响物理机上的原住民。
为了解决这个问题,增加了中转机,先把备份文件下载至中转机,在中转机上合并解压文件,并把应用日志后的恢复文件通过Linux的pv工具限速,传送至目标机器上,从而不对物理机上原住民产生影响。
2. 恢复模块
恢复模块依旧沿用之前的恢复策略,在增加中转机的情况下,让业务运行更稳定,更安全。
目前恢复模块主要用于增加从库实例,也应用于已经扩展的自动化迁移功能。经备份逻辑的改造,恢复模块相较于旧的恢复模块,在效率、安全性上提升了很多。
3. 备份校验模块
备份校验模块是为了验证备份文件的有效性做的一个模块,为了实现这功能,我们设计了两套方案。
方案1:
恢复实例+10分钟同步验证,如果10分钟同步主库无报错,就认为备份文件是有效的。但会消耗至少一个MySQL实例资源,同时要较久的同步时间和一致性校验时间,落地有成本和效率问题,本方案未采用。
方案2
目前使用的备份校验标准:
① 设定备份流程:
(1)备份开始前,如果是逻辑备份(数据小于20G),获取所有表行数并记录。如果是物理备份,记录/data目录大小
(2)备份结束后,如果是逻辑备份(数据小于20G),获取所有表行数并记录。如果是物理备份,记录/data目录大小
② 备份恢复流程:
(1)备份恢复到某个MySQL实例,物理备份额外要求执行MySQLcheck 确保没有坏的数据表。
(2)校验备份前后库表差异,
-
一致则要求备份恢复后的库表结构也和备份前后一致。
-
前后不一致则不校验恢复后库表结构
(3)校验备份前后数据差异,逻辑备份校验表行数,物理备份校验数据目录大小,要求偏差小于10%
我们为了保障核心数据库的备份文件有效性,特设定了以下标准:
-
设定优先级,对特定的数据库设定较高的优先级
-
必须保障每月验证一次的频率
-
每个数据库每年必须验证一次
4. 定点恢复模块
定点恢复模块主要应用于误删数据后的恢复工作,该系统的架构图如下:
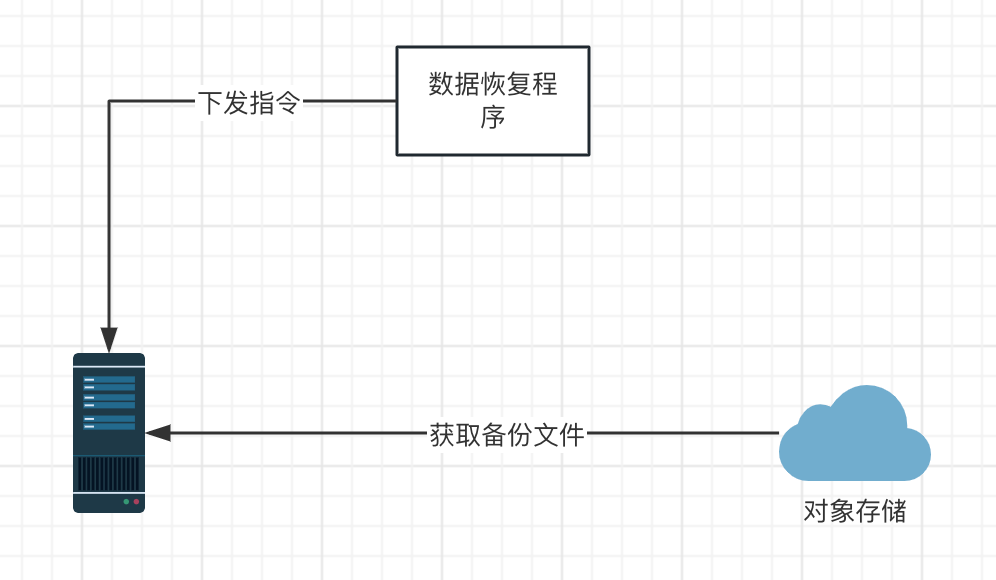
首先,需要与开发人员沟通误删数据时间点,从主库中寻找对应的binlog 位点,或者是gtid信息,并在我们的内部管理系统daas上的【备份管理】中选择出指定的备份文件,并在daas管理系统提数据恢复工单,工单界面图如下:
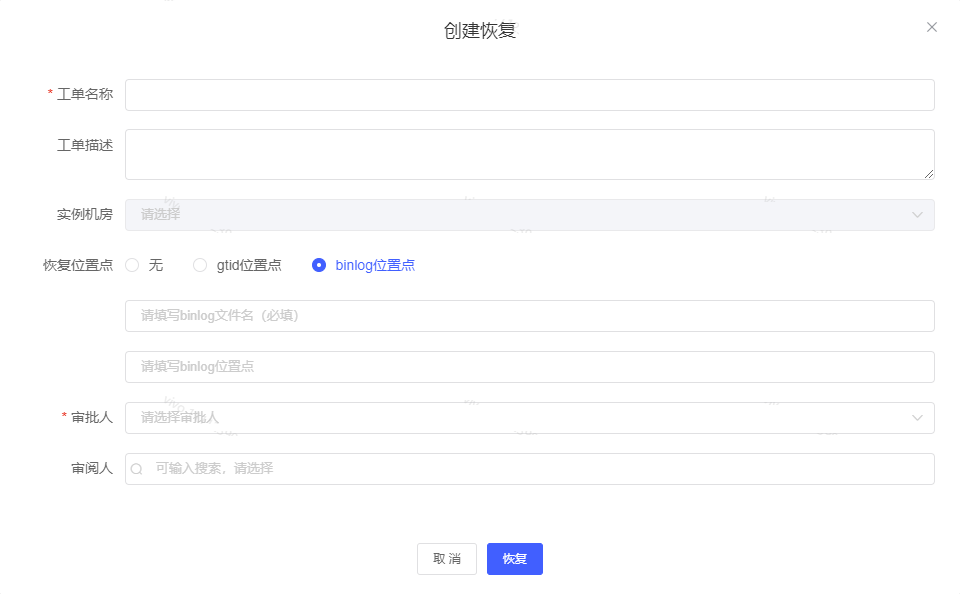
恢复位置点,我们有三种选择方式,选择无,及时恢复到某个备份文件即可,不再追binlog,gitd位点是用于开启gtid的数据库服务,binlog位点是应对未开启gtid的数据库服务。在审批人(一般是该项目开发的负责人)通过后,定点恢复模块便对恢复机器下发命令,从对象存储获取指定的备份文件,恢复数据,通过start slave until 命令恢复至指定的位置点。
以下是恢复完成后的工单详情,通过访问目标ip和目标端口来查看恢复的数据。
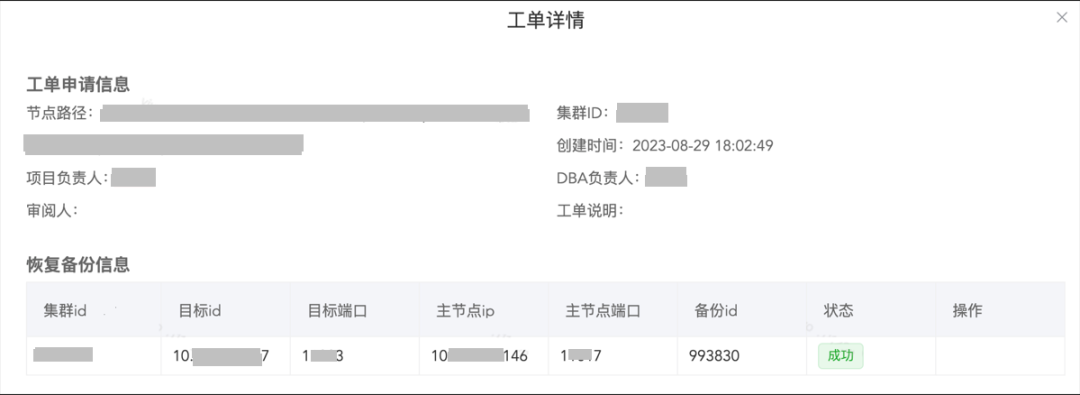
定点恢复受限于物理机磁盘限制,因为要应对各种大小的数据库,我们准备了一个非常大的物理磁盘,不过该磁盘是普通的ssd,因此恢复时间上会比较慢。而且恢复时长也跟数据库的备份文件大小有关,数据库越大,恢复越慢。由于MySQL数据库现在使用了物理备份,恢复单个表只能先全库恢复,再追位点,因此恢复效率比较低。如果是基于Mydumper 逻辑备份的,恢复单个表,会非常快速,因为只需要把恢复的表拷贝出来,即可单独恢复。然而目前却无法实现,在备份效率和定点恢复效率上,我们选择了前者。
定点恢复只需要DBA找到具体的恢复时间点,然后配置恢复页面,系统会自动为我们创建实例,恢复至指定的时间点,从而恢复数据。该操作减少DBA的直接恢复操作,并且以此功能作为一个保底的数据恢复,在定点恢复执行的过程中,如果DBA 有其他方案,可以直接使用另外一套方案来恢复,两个方案同时进行,对恢复数据增加双层保险。
目前误删数据还有许多事情可以去做,使用更多的恢复方案提高恢复效率。
5. 自动化迁移模块
自动迁移模块是基于备份文件实现的,vivo的MySQL组件使用的是物理机混合部署,磁盘使用的是4T的nvme 盘,因此会受到磁盘容量的影响。我们是多实例部署,共享cpu,内存,磁盘空间。随着业务的增长,磁盘使用容量会慢慢的增加,我们目前设定磁盘使用88%时,便自动提单迁移实例。之所以选择磁盘使用率的88%,是因为我们的报警是从90%开始,主要是为了降低磁盘方面的告警。
目标:
-
提高物理机磁盘使用率
-
减少DBA人工迁移的工作量
-
提高迁移效率
-
单个工单形成扩容、主从切换、域名切换、回收的闭环
选择实例的规则:
-
从库优先迁移
-
磁盘使用率10%左右的优先迁移
-
实例资源小于100G的不迁移
迁入物理机选择规则:
获取满足需求的物理机: 满足 【物理机磁盘使用率】+ 【迁移实例磁盘使用量】 小于物理机磁盘使用率80%
流程图如下:
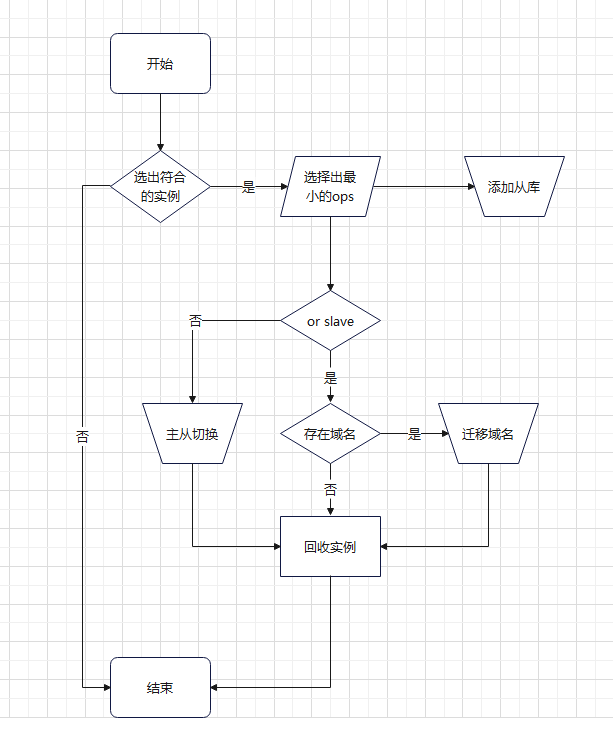
自动化迁移工单图
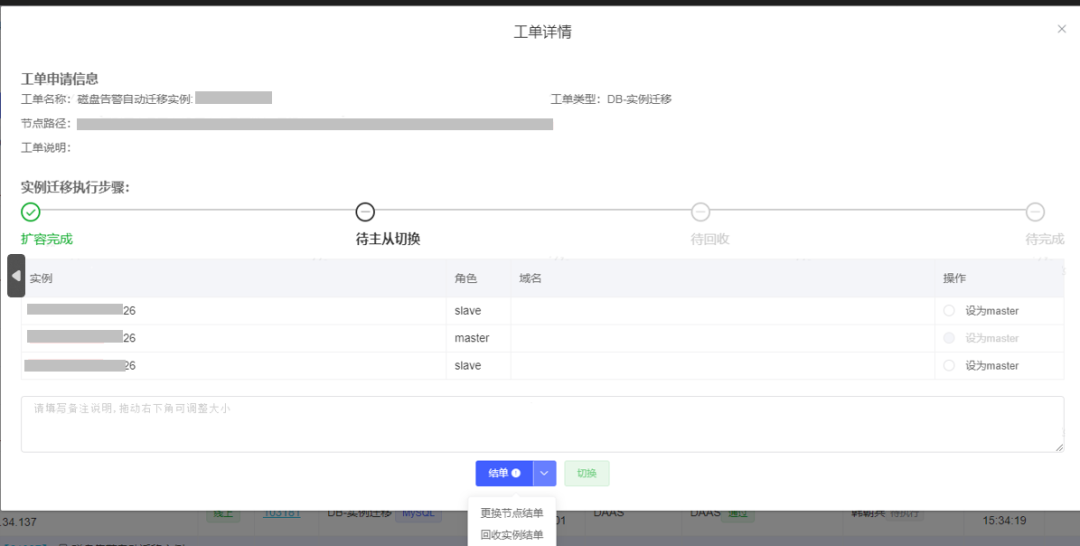
该功能包含扩容节点、主从切换、迁移域名、回收实例等步骤。如果出现选择的实例不易迁走,可以使用【更改节点结单】或者【回收实例结单】功能完成整个工单的闭环。
目前该项功能已经投入使用,直至目前已经提单259个,提高迁移效率达95%以上。
3.4 新备份恢复系统的不足
1. MongoDB shard 备份缺陷
由于MongoDB shard 引入,MongoDB shard 备份还未有更好的备份方案。目前MongoDB shard 依旧是使用物理备份,但是对数据恢复上还存在不足。在恢复至某一个时间点上,还需要使用oplog单独对每个分片进行恢复,恢复起来步骤复杂。
2. 数据恢复效率不高
数据恢复是在数据被误删的时候发起的操作,虽然使用频率较低,但是该功能却是非常重要的,目前恢复数据是基于全库恢复+binlog重做,恢复效率较低,依旧有很多的恢复方案亟待加入,提高恢复数据的效率,减少因误删数据产生的影响。
四、总结
4.1 安全
旧系统主要是文件系统安全,由于使用的是GlusterFS文件系统,物理机备份主要是挂载到目标机器上,导致登录物理机后,可以不受限制的操作备份文件,非常危险,虽然异地灾备文件系统只挂载至备份控制机,权限控制的比较严格,但是由于拷贝速度的限制,异地的副本已名存实亡。
使用新系统后,备份文件存储于多个机房之中,某个机房全部宕机,也不影响备份文件的读取,因此对备份文件保护得到了加强。同时由于对象存储系统未使用挂载形式,因此,DBA和系统工程师无法下载备份文件,也无法操作备份文件系统,让备份文件更加安全。
4.2 效率
受限于旧文件系统效率写入以及逻辑备份速度,MySQL 备份2天才能完成一轮备份,MongoDB 由于实例太大,受限于mongodbdump 本身的特性,备份时间很长,而且很容易失败。虽然优化后,改成ssd 盘备份,但受限于盘的大小,MongoDB 的备份效率依旧不好。
通过更换文件系统,以及备份策略,极大的提高了备份效率,备份从之前的2天完成备份,提高至10个小时完成备份。
自动化迁移在减少DBA选择实例的同时,也能形成完整的闭环,DBA在操作的时候只需要根据工单的流程即可,极大的提高了工作效率。
4.3功能模块扩展
自从使用Java 语言后,并且有专门的 Java 开发人员的介入,新功能需求得到了实现,经过多轮的优化,目前新备份恢复系统运行非常稳定。基于备份文件,我们扩展了定点恢复模块、自动化迁移方案、以及机器故障自动发起迁移等功能,极大的提高DBA的工作效率,让我们有更多的时间去解决企业的痛点。