一 文档简介
1.1 分库分表诞生的前景
随着系统用户运行时间还有用户数量越来越多,整个数据库某些表的体积急剧上升,导致CRUD的时候性能严重下降,还容易造成系统假死。
这时候系统都会做一些基本的优化,比如加索引、缓存、读写分离/主从复制,增删改都走主库,查询走从库。(数据量过大基本优化方式参考:百度安全验证)
但是这样没法提升主库写的能力,因为主库只有一个。这时候就要考虑分库分表了,一般数据库在设计的时候就会提前考虑到是否有分库分表场景需要,避免后期带来迁移的问题,而且最好对表的查询足够简单,尽量避免跨表跨库查询。
1.2 单表数据量的分析
业界流传着单表数量建议最大2kw条;(但是实际情况还可以进行具体分析:https://linpxing.cn/mysql_big_table_limit_990912/)![]() https://linpxing.cn/mysql_big_table_limit_990912/)
https://linpxing.cn/mysql_big_table_limit_990912/)
在阿里巴巴开发手册中建议:预估三年内单表行数超过500万行或者单表容量超过2GB才推荐进行分库分表。
二 分表详述
2.1 分库分表的方式(垂直拆分,水平复制)
一般系统模块都是访问同一个数据库资源,所有的表都存放在一个库里面;

2.1.1 垂直分库
把单一的数据库进行业务划分,专库专表
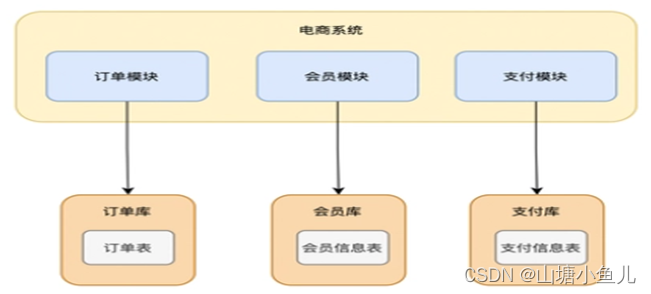
经过垂直拆分之后,每个模块都使用各自独立的数据库,减轻了数据库的压力,业务也更加清晰,拓展也更容易了,但是会增加连表查询以及事务处理的复杂度,无法解决单表数据量太大的问题
2.1.2 垂直分表
垂直拆分表主要解决一张表太多字段某个字段存储值为大文本会对io查询有损耗所以把本来属于同一个对象描述的属性拆分多个表,分布式微服务分库分表尽量不要严苛遵守数据库的3大范式,可参考不可严格遵循
相当于把一个大表根据字段拆分成多个小表 ,一个10w数据的表,变成两个10w数据的表
这样拆分的好处就是,假如只显示列表,不需要显示详细信息就很方便,例如一个订单是包含很多信息的,但是在后台通常不需要去获取订单的详情信息用作展示,一般只需要展示概要信息:下单用户、下单时间、金额等等重要信息。于是可以把一个订单表垂直拆分为两个表来处理
2.1.3 水平分库
把一个数据库分散成多个结构相同的数据库,本质就是复制操作
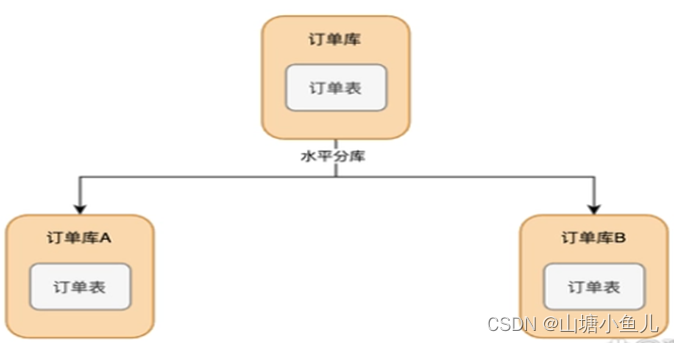
2.1.4 水平分表
一个表数据量太大,将一个表按不同的条件分散多个表中,把1000w的表拆分为两个500w的表
2.2 分表的规则
2.2.1 取范围
根据时间范围或者id范围分布到不同的库中,例如把2020年前的数据放到一个表中,之后的数据放到一个表中。把用户ID 0~100000放到一个表中,100000~200000的数据放到一个表中。
优点:使用分片字段范围查询比较方便
缺点:某段范围内热点数据可能被频繁读写,其他数据很少被查询
时间维度:使用ShardingJDBC实现按时间维度分表轻松支撑千万级数据_sharding jdbc按时间分表-CSDN博客;参考链接;
2.2.2 数值hash取模运算
根据某个字段进行运算均匀的分配到不同的表中
优点:分散比较均匀,不容易存在热点数据
缺点:数据太分散,导致范围查询比较麻烦,需要查询分库之后再合并
水平拆分的时候会导致多库多表的联合查询难度变大,以及多数据源管理的问题
2.3 分表的中间件
2.3.1 Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。由于Cobar发起人的离职,Cobar停止维护
2.3.2 TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
2.3.3 Atlas
是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定
2.3.4 Sharding Sphere
Sharding-JDBC是从当当网的内部架构 ddframe 里面的一个分库分表的模块脱胎出来的,用来解决当当的分库分表的问题,把跟业务相关的敏感的代码剥离后,就得到了 Sharding-JDBC。
2018 年 5 月,因为增加了 Proxy 的版本和 Sharding-Sidecar(尚未发布),Sharding-JDBC 更名为 Sharding Sphere,从一个客户端的组件变成了一个套件
2018 年 11 月,Sharding-Sphere 正式进入 Apache 基金会孵化器,这也是对Sharding-Sphere 的质量和影响力的认可。
2.3.5 Mycat
基于 Cobar 改造的,解决了cobar存在的问题,并且加入了许多新的功能在其中。青出于蓝而胜于蓝,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
三 Sharding Sphere
3.1 基本特性
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
在 maven 的工程里面,我们使用它的方式是引入依赖,然后进行配置就可以了,原来是 SSM(Spring+SpringMVC+MyBatis) 连接数据库,还是 SSM,因为它是支持 MyBatis 的。
3.2 核心概念
3.2.1 逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
3.2.2 真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
3.2.3 数据结点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
3.2.4 绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
3.2.5 广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
3.2.6 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
3.2.7 分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法
精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
3.2.8 分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
Hint分片策略
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
不分片策略
对应NoneShardingStrategy。不分片的策略。
相关链接:
Sharding-JDBC介绍 - 简书
ShardingSphere介绍与使用-CSDN博客
按时间分表:https://www.cnblogs.com/wang1221/p/16325709.html
分库分表-分片算法运用_分库和分表分片-CSDN博客策略;