是的,我曾经写过一些简单的爬虫程序,主要用于从网站上抓取特定信息,例如新闻数据、商品价格等。这些爬虫程序帮助我自动化地收集数据,节省了大量手动查找和整理的时间。
对于爬虫,我的理解是它是一种自动化程序,能够模拟人类在互联网上的浏览行为,按照一定的规则和策略,自动地抓取、解析并存储网页中的数据。爬虫技术广泛应用于数据采集、搜索引擎、竞品分析等领域,为数据分析、机器学习等提供了丰富的数据源。
然而,爬虫技术也带来了一些问题,比如对目标网站造成过大的访问压力,甚至可能导致网站崩溃;或者抓取到敏感、隐私数据,引发法律和道德问题。因此,很多网站都会采取反爬虫措施来保护自己的数据和资源。
反爬虫则是针对爬虫技术的一系列防御手段。常见的反爬虫策略包括:
-
限制访问频率:通过检测来自同一IP的请求频率,如果过高则拒绝服务,从而防止爬虫对网站造成过大压力。
-
设置验证码:在用户访问某些重要页面时,弹出验证码要求用户输入,以确认访问者是真实用户而非爬虫程序。
-
动态加载数据:通过Ajax等技术动态加载页面数据,使得爬虫难以直接获取到完整信息。
-
使用Robots协议:在网站根目录下放置robots.txt文件,声明哪些爬虫可以访问哪些页面,从而引导爬虫合理抓取数据。
-
数据混淆和加密:对页面中的敏感数据进行混淆或加密处理,增加爬虫解析数据的难度。
-
分布式防御:通过CDN等技术分散网站资源,使得爬虫难以定位到目标服务器的真实IP地址。
作为前端开发人员,我认为在开发过程中需要充分考虑到反爬虫的需求。一方面,我们要确保网站的数据和资源不被恶意爬虫滥用;另一方面,我们也要合理引导善意爬虫(如搜索引擎爬虫)正确地抓取和索引网站内容,以提升网站的曝光度和用户体验。在实际工作中,我通常会与后端开发人员紧密合作,共同制定和实施反爬虫策略。
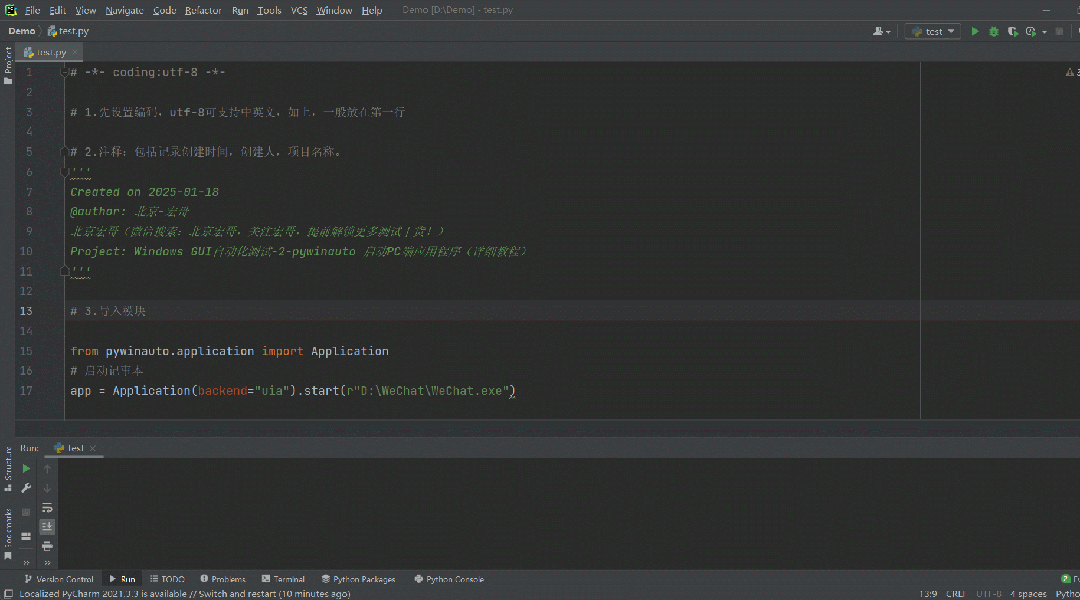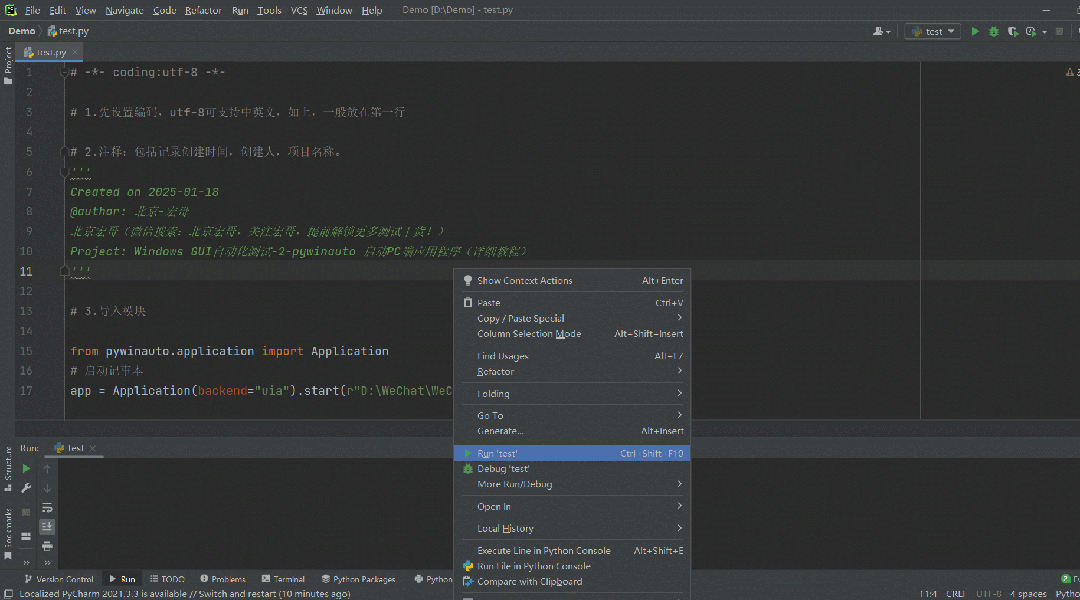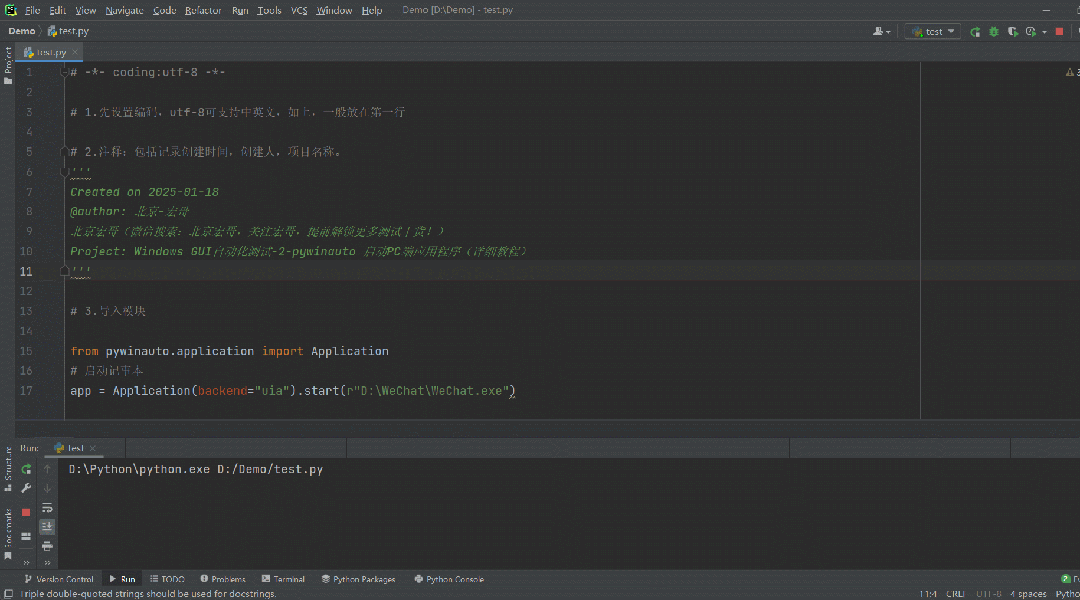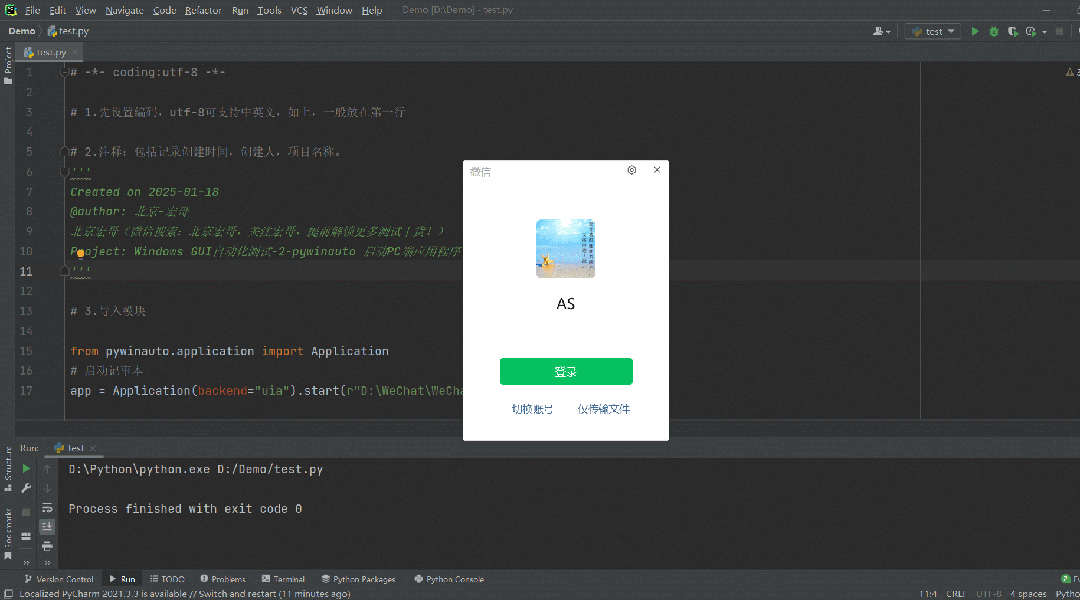
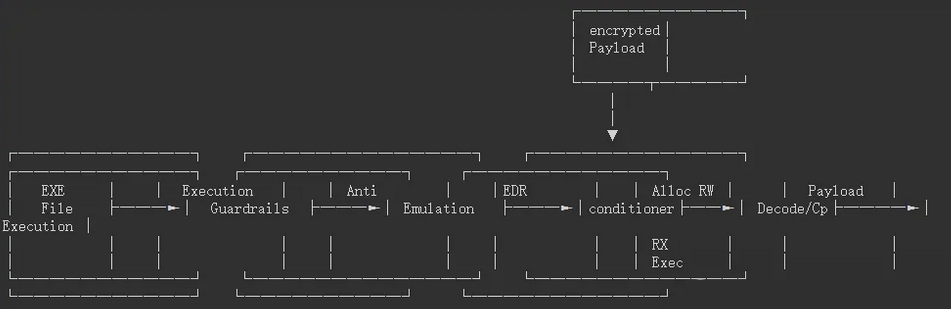


![(原创)[开源][.Net Standard 2.0] SimpleMMF (进程间通信框架)更新 v1.1,极低CPU占用](https://img2024.cnblogs.com/blog/1686429/202501/1686429-20250117160759172-690917223.png)