第一章 Redis入门
1.1 节 什么是NoSql型数据库
- NoSQL ,泛指非关系型的数据库, NoSQL Not Only SQL,它可以作为关系型数据库的良好补充。
- NoSQL 不依赖业务逻辑方式存储,而以简单的key-value模式存储。因此大大的增加了数据库的扩展能力。
| SQL | NoSQL | |
|---|---|---|
| 数据结构 | 结构化 | 非结构化 |
| 数据关联 | 关联的 | 无关联的 |
| 查询方式 | SQL查询 | 非SQL查询 |
| 事务特征 | ACID | BASE |
| 存储方式 | 磁盘 | 内存 |
| 扩展性 | 垂直 | 水平 |
| 使用场景 | 数据结构固定;相关业务对数据安全性、一致性要求较高 | 数据结构不固定;对一致性,安全性要求不高,对性能要求高 |
常见NoSQL数据库:
Reids (键值对)
MongoDB(文档类型)
HBase (列类型)
Neo4j(Graph类型)
1.2 节 Reids介绍
redis是远程词典服务器,是一个基于内存的键值型NoSQL数据库。其主要特征如下:
键值(key-value)型,value支持多种不同数据结构,功能丰富;
单线程,每个命令具备原子性;(6以前只有单线程,之后有多线程)
低延迟,速度快(基于内存、IO多路复用、良好的编码);
支持数据持久化;
支持主从集群、分片集群;
支持多语言客户端;
1.3 节 Reids 命令
1.3.1 启动方式
1、默认启动
redis-server这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
2、指定配置启动
如果要让Redis以后台方式启动,则必须修改Redis配置文件redis.conf。
然后修改redis.conf文件中的一些配置:
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
# requirepass 123456Redis的其它常见配置:
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 16
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"
启动Redis:
# 进入redis安装目录
cd /usr/local/redis-6.2.6
# 启动
redis-server redis.conf
停止服务:
# 利用redis-cli来执行 shutdown 命令,即可停止 Redis 服务,
# 如果之前配置了密码,因此需要通过 -u 来指定密码
redis-cli shutdown
3、开机自启动
可以通过配置来实现开机自启。
首先,新建一个系统服务文件:
vi /etc/systemd/system/redis.service内容如下:
[Unit]
Description=redis-server
After=network.target[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /usr/local/redis-6.2.6/redis.conf
PrivateTmp=true[Install]
WantedBy=multi-user.target然后重载系统服务:
systemctl daemon-reload可以用下面这组命令来操作redis了:
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
#开机自启
systemctl enable redis
1.5 节 Redis桌面客户端
1、命令行客户端
redis-cli [options] [commonds]其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1
-p 6379:指定要连接的redis节点的端口,默认是6379
-a 123456:指定redis的访问密码其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong不指定commond时,会进入
redis-cli的交互控制台:
2、图形化客户端
resp等
3、编程客户端
第二章 Redis基本知识
Redis能读的速度是110000次/s,写的速度是81000次/s。
2.1 节 Reids 多路复用
- 在Redis6/7中,非常受关注的第一个新特性就是多线程。
- Redis的性能瓶颈有时会出现在网络IO的处理上,也就是说,单个主线程处理网络请求的速度跟不上底层网络硬件的速度。
- Redis的多IO线程只是用来处理网络请求的,对于读写操作命令Redis仍然使用单线程来处理。
2.2 Redis相关命令
1.通用命令
| select number | 切换数据库 |
| FLUSHDB | 清空当前数据库中的所有 key。 |
| FLUSHALL | 删除所有数据库的所有 key |
| keys * | 查看当前库中所有的key 。 |
| exists key | 判断某个key是否存在,返回1表示存在,0不存在。 |
| type key | 查看当前key 所储存的值的类型 |
| del key | 删除已存在的key,不存在的 key 会被忽略。 |
| expire key time | 给key设置time秒的过期时间。设置成功返回 1 。 当 key 不存在返回 0。 |
| ttl key | 以秒为单位返回 key 的剩余过期时间。 |
| persist key | 移除给定 key 的过期时间,使得 key 永不过期。 |
2.String命令
String是Redis最基本的类型,一个key对应一个value。String是二进制安全的,意味着String可以包含任何数据,比如序列化对象或者一张图片。String最多可以放512M的数据。
| set key value | 用于设置给定 key 的值。如果 key 已经存储其他值, set 就重写旧值,且无视类型。 |
| get key | 用于获取指定 key 的值。如果 key 不存在,返回 nil 。 |
| append key value | 将给定的value追加到key原值末尾。 |
| strlen key | 获取指定 key 所储存的字符串值的长度。当 key 储存的不是字符串值时,返回一个错误。 |
| setex key time value | 给指定的 key 设置值及time 秒的过期时间。如果 key 已经存在, setex命令将会替换旧的值,并设置过期时间。 |
| setnx key value | 只有在key不存在时设置key的值 |
| getrange key start end | 获取指定区间范围内的值,类似between........and 的关系 |
| setrange key start value | 设置指定区间范围内的值,类似between........and 的关系 |
| incr key | 将 key 中储存的数字值增一。 如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 incr 操作。 如不是数字类型,那么返回一个错误。 |
| decr key | 将 key 中储存的数字值减一。同上 |
| incrby/decrby key step | 将key存储的数字值按照step进行增减。同上 |
| mset key1 value1 key2 value2 | 同时设置一个或多个 key-value |
| mget key1 key2 | 返回所有(一个或多个)给定 key 的值。 如果给定的 key 里面,有某个 key 不存在,那么这个 key 返回特殊值 nil 。 |
| getset key value | 将给定key值设为value,并返回key的旧值(old value),简单一句话(先get然后立即set)。 |
使用场景:
value 除了是字符串以外还可以是数字。
计数器
统计多单位的数量
粉丝数
对象缓存存储
分布式锁
3.List命令
- List是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- 底层是一个双向链表, 对两端操作性能极高,通过索引操作中间的节点性能较差。
- 一个List最多可以包含 $2^{32}-1$个元素 ( 每个列表超过40亿个元素)。
| lpush/rpush key1 value1 value2 value3…… | 从左边(头部)/右边(尾部)插入一个或多个值。 |
| lrange key start end | 返回key列表中的start和end之间的元素(包含start和end)。 其中 0 表示列表的第一个元素,-1表示最后一个元素。 |
| lpop/rpop key | 移除并返回第一个值或最后一个值。(值在键在,值光键亡 ) |
| lindex key index | 获取列表index位置的值(从左开始)。 |
| llen key | 获取列表长度。 |
| lrem key count value | 从左边开始删除与value相同的count个元素。 |
| linsert key before/after value newvalue | 在列表中value值的前边/后边插入一个new value值(从左开始)。 |
| lset key index value | 将索引为index的值设置为value |
使用场景
消息队列
排行榜
最新列表
4.Set命令
- 与List类似是一个列表功能,但Set是自动排重的。
- Set是String类型的无序集合,它底层其实是一个value为null的hash表,所以添加、删除、查找的时间复杂度都是O(1)。
| sadd key value1 value2…… | 将一个或多个元素添加到集合key中,已经存在的元素将被忽略。 |
| smembers key | 取出该集合的所有元素。 |
| sismember key value | 判断集合key中是否含有value元素,如有返回1,否则返回0。 |
| scard key | 返回该集合的元素个数。 |
| srem key value1 value2…… | 删除集合中的一个或多个成员元素,不存在的成员元素会被忽略。 |
| spop key | 随机删除集合中一个元素并返回该元素。 |
| srandmember key count | 随机取出集合中count个元素,但不会删除。 |
| smove sourcekey destinationkey value | 将value元素从sourcekey集合移动到destinationkey集合中。 如果 sourcekey集合不存在或不包含指定的 value元素,则smove 命令不执行任何操作,仅返回 0 。 |
| sinter key1 key2 | 返回两个集合的交集元素。 |
| sunion key1 key2 | 返回两个集合的并集元素。 |
| sdiff key1 key2 | 返回两个集合的差集元素(包含key1中的,不包含key2) |
使用场景: 黑白名单、随机展示、好友、关注人、粉丝、感兴趣的人集合。
5.Hash命令
Hash是一个键值对的集合。Hash 是一个 String 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
Hash存储结构优化
如果field数量较少,存储结构优化为类数组结构
如果field数量较多,存储结构使用HashMap
| hset key field value | 给key集合中的field赋值value。 如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。 如果字段已经存在于哈希表中,旧值将被重写 |
| hget key field | 从key哈希中,取出field字段的值。 |
| hmset key field1 value1 field2 value2…… | 批量设置哈希的字段及值。 |
| hexists key field | 判断指定key中是否存在field 如果哈希表含有给定字段,返回 1 。 如果哈希表不含有给定字段,或 key 不存在,返回 0 。 |
| hkeys key | 获取该哈希中所有的field。 |
| hvals key | 获取该哈希中所有的value。 |
| hincrby key field increment | 为哈希表key中的field字段的值加上增量increment
|
| hdel key field1 field2…… | 删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略。 |
| hsetnx key field value | 给key哈希表中不存在的的字段赋值 。 如果哈希表不存在,一个新的哈希表被创建并进行 hsetnx 操作。 |
使用场景:购物车、存储对象
6.Zset命令
Zset与Set非常相似,是一个没有重复元素的String集合。不同之处是Zset的每个元素都关联了一个分数(score),这个分数被用来按照从低分到高分的方式排序集合中的元素。集合的元素是唯一的, 但分数可以重复。
| zadd key score1 value1 score2 value2…… | 将一个或多个元素(value)及分数(score)加入到有序集key中。
|
| zrange key start end [withscores] | 返回key集合中的索引start和索引end之间的元素(包含start和end)。
|
| zrangebyscore key minscore maxscore [withscores] | 返回key集合中的分数minscore 和分数maxscore 之间的元素(包含minscore 和maxscore )。其中元素的位置按分数值递增(从小到大)来排序。 |
| zincrby key increment value | 为元素value的score加上increment的值。 |
| zrem k1 php 删除php | 删除该集合下为value的元素。 |
| zcount key minscore maxscore | 统计该集合在minscore 到maxscore分数区间中元素的个数。 |
| zrank key value | 返回value在集合中的排名,从0开始。 |
使用场景:延时队列、排行榜、限流
7.Bitmaps
Redis提供了Bitmaps这个 “数据结构” 可以实现对位的操作,合理地使用位能够有效地提高内存使用率和开发效率。
| setbit key offset value | 设置Bitmaps中某个偏移量的值。 示例: 记录张三 1月份上班打卡情况 setbit zhangsan:1 0 1 |
| getbit key offset | 获取Bitmaps中某个偏移量的值。 |
| bitcount key [start end] | 统计字符串被设置为1的bit数量。一般情况下,给定的整个字符串都会被进行统计,可以选择通过额外的start和end参数,指定字节组范围内进行统计(包括start和end),0表示第一个元素,-1表示最后一个元素。 |
| bitop and/or destkey sourcekey1 sourcekey2…… | 将多个bitmaps通过求交集/并集方式合并成一个新的bitmaps。 |
使用场景:
活跃天数
打卡天数
登录天数
用户签到
统计活跃用户
统计用户是否在线
实现布隆过滤器
8.eographic命令
GEO,Geographic,地理信息的缩写。该类型就是元素的二维坐标,在地图上就是经纬度。Redis基于该类型,提供了经纬度设置、查询、范围查询、距离查询、经纬度Hash等常见操作。
| geoadd key ongitude latitude member | 用于存储指定的地理空间位置,可以将一个或多个经度 (longitude)、纬度(latitude)、位置名称(member)添加到指定的 key中。 # 将北京的经纬度和名称添加到china |
| geopos key member [member ……] | 从给定的 key 里返回所有指定名称(member)的位置(经度和纬度),不存在的返回 nil。 |
| geodist key member1 member2 [m|km|ft|mi] | 用于返回两个给定位置之间的距离。 |
| georadius key longitude latitude radius m|km|ft|mi | 以给定的经纬度(longitude latitude)为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离(radius )的所有位置元素。 |
9.HyperLogLog命令
- 做站点流量统计的时候一般会统计页面UV(独立访客:unique visitor)和PV(即页面浏览量:page view)。redis HyperLogLog是用来做基数统计的算法,HyperLogLog的优点是:在输入元素的数量或者体积非常非常大时,
- 基数:比如数据集{1,3,5,7,5,7,8},那么这个数据集的基数集为{1,3,5,7,8}, 基数(不重复元素)为5.基数估计就是在误差可接受的范围内,快速计算基数。
| pfadd key element1 element2…… | 将所有元素参数添加到 Hyperloglog 数据结构中。 添加元素到HyperLogLog中,如果内部有变动返回1,没有返回0。 |
| pfcount key1 key2…… | 计算Hyperloglog 近似基数,可以计算多个Hyperloglog ,统计基数总数。 |
| pfmerge destkey sourcekey1 sourcekey2…… | 将一个或多个Hyperloglog(sourcekey1) 合并成一个 Hyperloglog (destkey )。 |
第三章 Redis 配置文件

| units单位 | 配置大小单位,开头定义基本度量单位,只支持bytes,大小写不敏感。 |
| INCLUDES | 多个配置文件就可以在此通过 include/path/to/local.conf 配置进来,而原本的 redis.conf 配置文件就作为一个总闸。 |
| NETWORK |
|
| GENERAL |
|
| SNAPSHOTTING | 做持久化操作。
|
| REPLICATION |
|
| SECURITY | requirepass:设置redis连接密码。 |
| CLIENTS | maxclients :设置客户端最大并发连接数,默认无限制。 |
| MEMORY MANAGEMENT |
|
| APPEND ONLY MODE |
|
| LUA SCRIPTING | lua-time-limit:一个lua脚本执行的最大时间,单位为ms。默认值为5000. |
| REDIS CLUSTER |
|
第四章 Redis Java客户端
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/connect/clients/
推荐使用的java客户端 包括:
Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map、Queue等,而且支持跨进程的同步机制:Lock、Semaphore等待,比较适合用来实现特殊的功能需求。
4.1 节 Jedis 客户端
4.1.1.案例
<!--jedis-->
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version>
</dependency>
<!--连接池-->
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.11.1</version>
</dependency>
<!--单元测试-->
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.0</version><scope>test</scope>
</dependency>/*** jedis入门程序*/
public class JedisTest {Jedis jedis;@BeforeEachpublic void before(){//建立连接jedis = new Jedis("192.168.184.129",6379);//设置密码jedis.auth("123456");//选择库jedis.select(0);}@Testpublic void stringTest(){//存数据jedis.set("name","张三");//获取数据System.out.println(jedis.get("name"));}@Testpublic void hashTest(){//存数据jedis.hset("user:1","name","张三");jedis.hset("user:1","age","22");//取数据Map<String, String> map = jedis.hgetAll("user:1");System.out.println(map);}@AfterEachpublic void after(){if(jedis!=null){jedis.close();}}
}4.1.2.Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式。
public class JedisConnectionFactory {private static JedisPool jedisPool;static {//配置连接池JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(8);poolConfig.setMaxIdle(8);poolConfig.setMinIdle(0);// 创建连接池对象,参数:连接池配置、服务端ip、服务端端口、超时时间、密码jedisPool = new JedisPool(poolConfig, "192.168.184.129", 6379, 1000, "123456");}public static Jedis getJedis(){return jedisPool.getResource();}public static void main(String[] args) {System.out.println(JedisConnectionFactory.getJedis());}
}4.2 节 SpringDataRedis 客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis。
提供了对不同Redis客户端的整合(Lettuce和Jedis)
提供了RedisTemplate统一API来操作Redis
支持Redis的发布订阅模型
支持Redis哨兵和Redis集群
支持基于Lettuce的响应式编程
支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化
支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:
| API | 返回值类型 | 说明 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作String类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作Hash类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作List类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作Set类型数据 |
| redisTemplate.opsForZset() | ZSetOperations | 操作SortedSet类型数据 |
| redisTemplate | 通用命令 |
4.2.1 实例
<dependencies><!--redis依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--common-pool--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency><!--Jackson依赖--><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency>
</dependencies>配置Redis
spring:redis:host: 192.168.184.129port: 6379password: 123456lettuce:pool:max-active: 8max-idle: 8min-idle: 0max-wait: 100ms@SpringBootTest
public class RedisTeplateTests {@Autowiredprivate RedisTemplate redisTemplate;@Testpublic void testString() {// 写入一条String数据redisTemplate.opsForValue().set("name", "张三");// 获取string数据Object name = redisTemplate.opsForValue().get("name");System.out.println("name = " + name);}
}4.2.2.自定义序列化
RedisTemplate可以接收任意Object作为值写入Redis。只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化。
可以自定义RedisTemplate的序列化方式,代码如下:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){// 创建RedisTemplate对象RedisTemplate<String, Object> template = new RedisTemplate<>();// 设置连接工厂template.setConnectionFactory(connectionFactory);// 创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 设置Key的序列化template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());// 设置Value的序列化template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);// 返回return template;}
}采用了JSON序列化来代替默认的JDK序列化方式。 整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。
4.2.3.StringRedisTemplate
当需要存储Java对象时,手动完成对象的序列化和反序列化。
@SpringBootTest
public class StringRedisTemplateTest {@Autowiredprivate StringRedisTemplate stringRedisTemplate;// JSON序列化工具private static final ObjectMapper mapper = new ObjectMapper();@Testvoid testSaveUser() throws JsonProcessingException {// 创建对象User user = new User();user.setId(2);user.setName("李四");user.setAge(33);// 手动序列化String json = mapper.writeValueAsString(user);// 写入数据stringRedisTemplate.opsForValue().set("user:2", json);// 获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:2");// 手动反序列化User user1 = mapper.readValue(jsonUser, User.class);System.out.println("user1 = " + user1);}
}
第五章 Redis 发布订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。
Redis的发布订阅
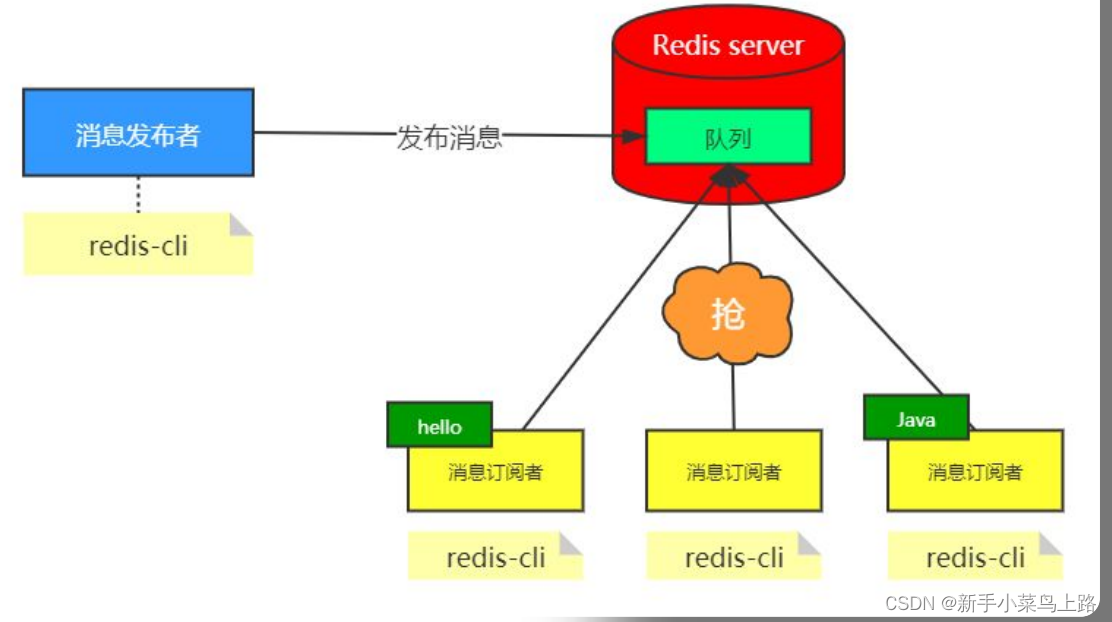
发布订阅命令
订阅 :subscribe 主题名字
发布命令 :publish 主题名字 消息
注意: 发布的消息没有持久化,如果在订阅的客户端收不到hello,只能收到订阅后发布的消息。
第六章 Redis 慢查询
6.1 节 什么是慢查询
Redis执行命令过程如下:
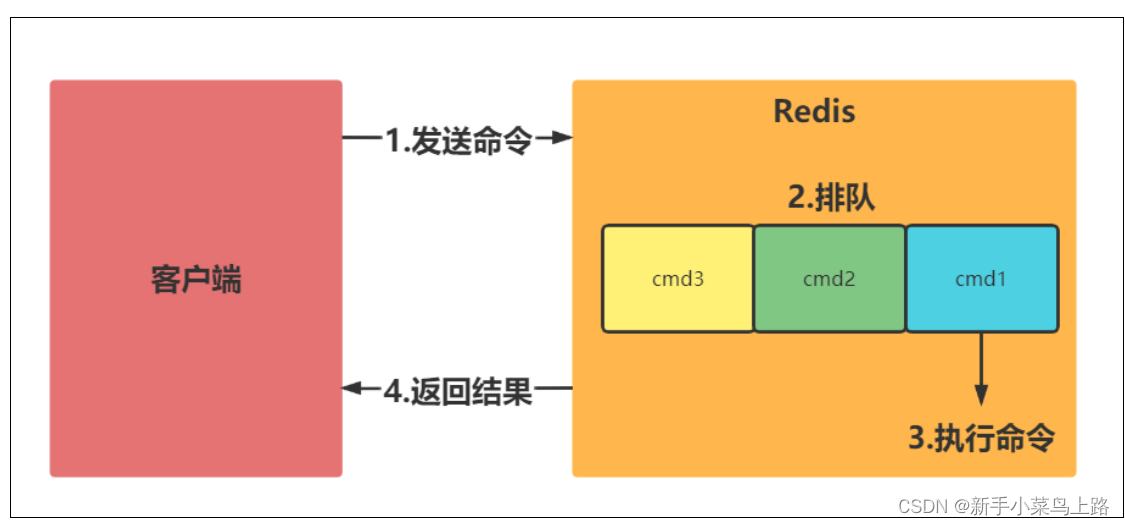
说明:
慢查询发生在第3阶段。
客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素。
慢查询日志是存放在Redis内存列表中。
6.2 节 慢查询日志
- 慢查询日志是Redis服务端在命令执行前后计算每条命令的执行时长,当超过某个阈值是记录下来的日志。
- slowlog get 命令获取慢查询日志,在 slowlog get 后面还数字,指定获取慢查询日志的条数。
- slowlog len 命令获取慢查询日志的长度。
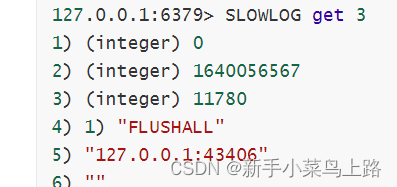
参数:
唯一标识ID
命令执行的时间戳
命令执行时长
执行的命名和参数
6.3 节 配置慢查询参数
配置慢查询参数如下:
命令执行时长的指定阈值 slowlog-log-slower-than:
slowlog-log-slower-than的作用是指定命令执行时长的阈值,执行命令的时长超过这个阈值时就会被记录下来。
存放慢查询日志的条数 slowlog-max-len。
slowlog-max-len的作用是指定慢查询日志最多存储的条数。
配置慢查询参数:
【1】查看慢日志配置

【2】可以直接修改Redis配置文件
slowlog-log-slower-than 1000
slowlog-max-len 1200【3】可以使用 config set 命令动态修改。

第七章 Redis 流水线 pipeline
7.1 节 Redis网络通讯模型弊端
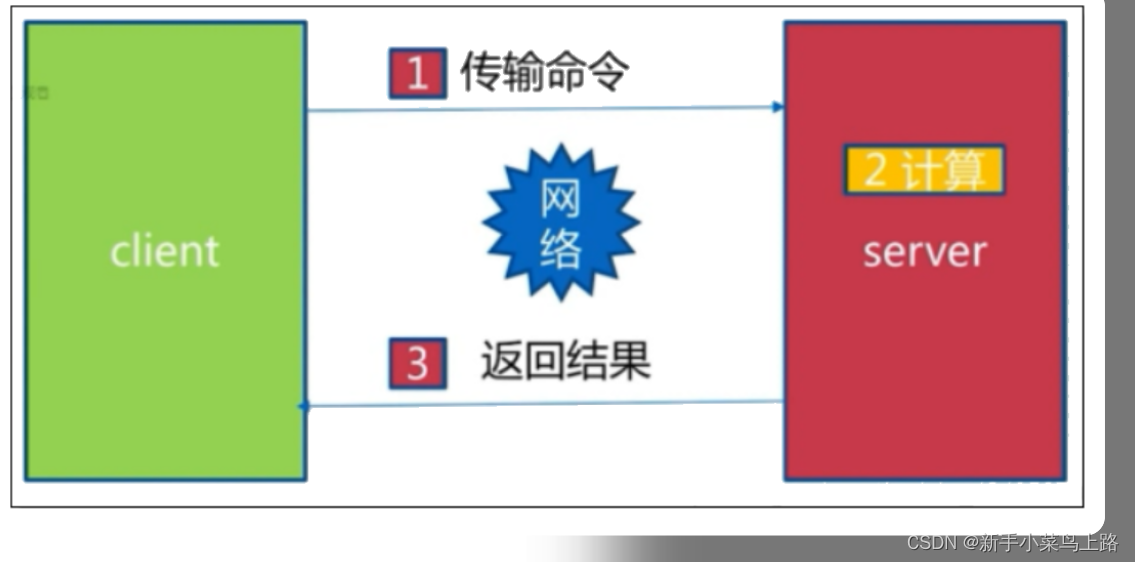
1次网络命令通信模型
经历了1次时间 = 1次网络时间 + 1次命令时间。
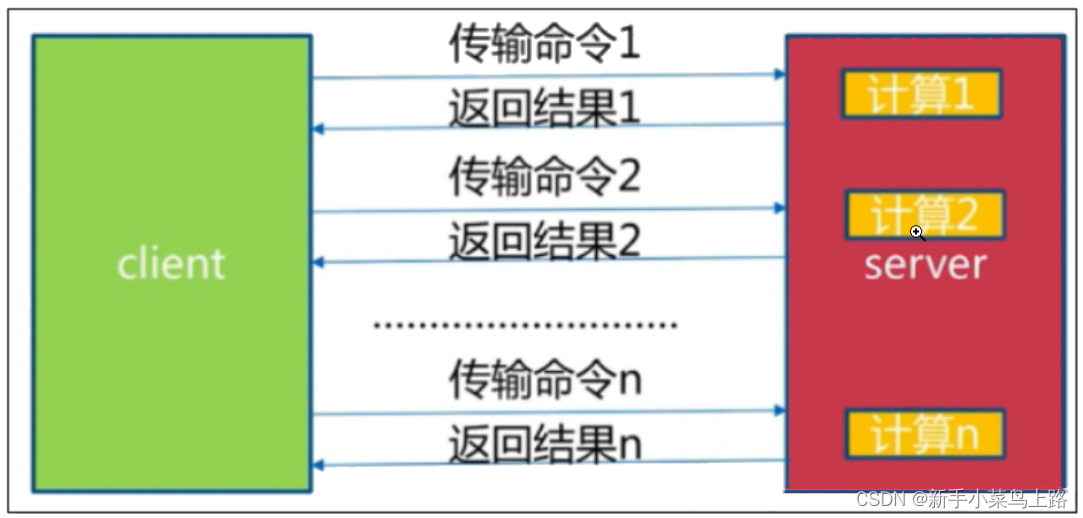
批量网络命令通信模型
经历了 n次时间 = n次网络时间 + n次命令时间
8.2 节 什么是流水线
经历了 1次pipeline(n条命令) = 1次网络时间 + n次命令时间,这大大减少了网络时间的开销,这就是流水线。

pipeline-Jedis实现:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>@Test
void test3() {redisTemplate.executePipelined((RedisConnection connection)->{long start = System.currentTimeMillis();Object k1 = connection.get("k1".getBytes());Object k2 = connection.get("k2".getBytes());Object k3 = connection.get("k3".getBytes());long end = System.currentTimeMillis();System.out.println("话费时间:"+(end-start));return null;});}
第八章 Redis 持久化机制(重要)
8.1 节 Redis持久化概述
- 持久化机制是指把内存中的数据存为硬盘文件, 这样当Redis重启或服务器故障时能根据持久化后的硬盘文件恢复数据。
- redis持久化的意义,在于故障恢复。
- Redis提供了两个不同形式的持久化方式RDB(Redis DataBase)和AOF(Append Only File)。
8.2 节 RDB持久化机制
在指定的时间间隔内将内存的数据集快照写入磁盘,也就快照,它恢复时是将快照文件直接读到内存里。
8.2.1 RDB基本配置
配置dump.rdb文件
- RDB保存的文件,在redis.conf中配置文件名称,默认为dump.rdb。
- RDB保存的文件默认在Redis启动时命令行所在的目录下。
RDB触发机制-主要三种方式 :
第一种:
快照默认配置:
save 3600 1:表示3600秒内(一小时)如果至少有1个key的值变化,则保存。
save 300 100:表示300秒内(五分钟)如果至少有100个 key 的值变化,则保存。
save 60 10000:表示60秒内如果至少有 10000个key的值变化,则保存。
给redis.conf添加新的快照策略,30秒内如果有5次key的变化,则触发快照。
- save 30 5
第二种: 执行flushall命令,也会触发rdb规则。
第三种:手动触发Redis进行RDB持久化的命令有两种: save与bgsave
8.2.2 RDB高级配置
| stop-writes-on-bgsave-error | 默认值是yes。当Redis无法写入磁盘的话,直接关闭Redis的写操作。 |
| rdbcompression | 默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。 redis会采用LZF算法进行压缩。 |
| rdbchecksum | 默认值是yes。在存储快照后,是否使用CRC64算法来进行数据校验。 |
只需要将rdb文件放在Redis的启动目录,Redis启动时会自动加载dump.rdb并恢复数据。
8.2.3 RDB的优势与劣势
| 优势 |
|
| 劣势 |
|
8.3 节 AOF持久化机制
AOF :以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来。
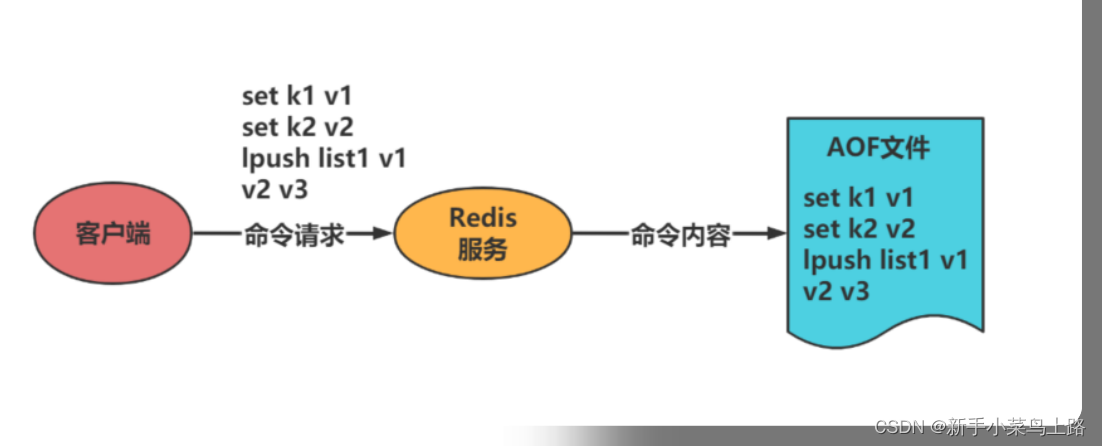
- AOF默认不开启,可以在redis.conf中配置文件名称,默认为appendonly.aof。
- AOF文件的保存路径,同RDB的路径一致,如果AOF和RDB同时启动,Redis默认读取AOF的数据。
8.3.1 AOF启动/修复/恢复
开启AOF
设置Yes:修改默认的appendonly no,改为yes。
AOF同步频率设置
appendfsync always 始终同步,每次Redis的写入都会立刻记入日志,性能较差但数据完整性比较好。
appendfsync everysec 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
appendfsync no redis不主动进行同步,把同步时机交给操作系统。
| 优势 |
|
| 劣势 |
|
8.4 节 如何选用持久化方式
用AOF来保证数据不丢失,作为数据恢复的第一选择,用RDB来做不同程度的冷备,在AOF文件都丢失或损坏不可用的时候,还可以使用RDB来进行快速的数据恢复。
第九章 总结(面试题)
【1】你都用过哪些Redis数据类型?
答:String、List、Set、Map、ZSet、BitMaps、GEO、HyperLogLog。
常规缓存用String类型 、对象经常修改字段用Map类型 、BitMaps处理打卡上班记录等问题,GEO处理地理坐标类问题,HyperLogLo处理PV,UV等基数统计操作。
List可以实现排行榜,最新列表等功能。Set实现共同联系人,黑白名单功能。
ZSet可以实现特定条件的排行榜。按照人气排行,人气作为存储分数。
【2】说一下发布订阅机制?
答:发布订阅机制可以实现类似你订阅某个频道后,该频带给你发送消息的功能,订阅频道命令
subscribie 频道 # 发送消息 publish 频道名 消息
【3】如何解决慢查询问题?
答:通过慢查询日志解决,slowlog len获取慢查询记录数,再通过slowlog get n获取具体信息去排查。
还可以通过
> config set slowlog-log-slower-than 1000 OK > config set slowlog-max-len 1200 OK > config rewrite OK
慢查询阈值根据QPS(每秒查询率)设置
【4】说一下说什么是流水线操作
答:一次网络连接 执行n条redis指令。
【5】说以下Redis持久化机制?
答:Redis支持两种持久化机制:RDB和AOF。RDB是快照持久化,读写速度快,占用磁盘空间小。但有丢失数据风险。AOF通过记录命令日志持久化,不易丢失数据,但是占用磁盘空间大,读写速度慢。RDB适合做冷备,如一天一备份的常规备份。AOF适合做redis正常重启前的数据备份,不会丢失数据。