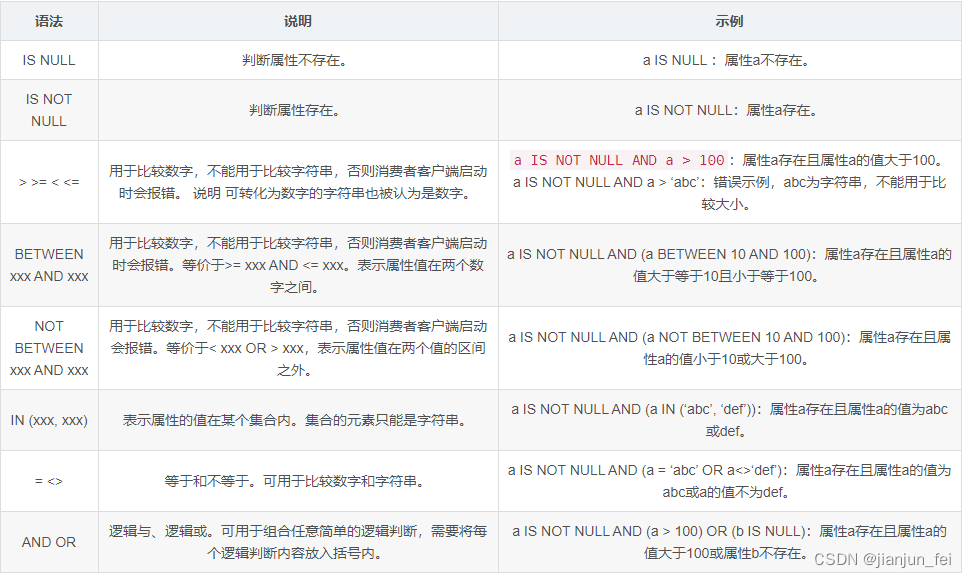
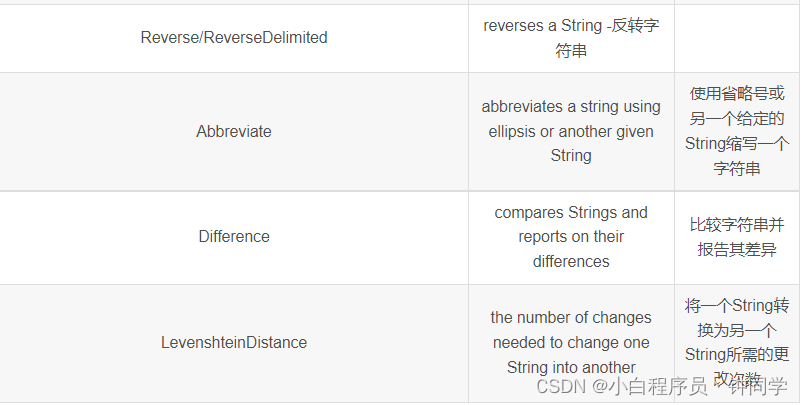
大家好,我是董董灿。
大模型越来越多了,大模型下沉的行业也越来越多。前几周一个在电厂工作的老哥发消息问我:大模型中所谓的多模态是什么意思?
我当时大概跟他解释了一下。
其实在人工智能领域,我们经常会听到"多模态"这个词,尤其是前段时间 GPT-4 发布更新之后,就支持了多模态,更是给了 GPT 爱好者一个很好的用户体验,包括我在内。
现在很多大模型,其实不光是 GPT-4,都是在朝着支持多模态的方向努力着。
那么对于非 AI 行业的人,或者 AI 行业初学者来说,应该如何认识和理解“多模态”这三个字呢?
今天就一起来看看吧。
1、什么是多模态
简单来说,多模态指的是数据或者信息的多种表现形式。
比如,我想把"我有一个苹果"这个信息传递给你,我可以用文字写出来,也可以用语言说出来,也可以用图片画出来,甚至我还可以拍成视频告诉你。
这就是典型的一种信息,多种存在形式上的多模态。

Photo by AI
我们可以这么理解,文本是一种模态,图像也是一种模态,甚至两种不同的语言,比如中文和英文,也各是一种不同的模态。
之所以相同的信息有那么多模态,是因为人类有多种感官来处理信息:比如听觉、嗅觉、视觉、触觉、味觉等,它们都可以获取并且处理不同形式的信息。
AI 如果真的想要模拟人类,实现通用人工智能(AGI),最重要的就是要实现对多模态的支持。
也就说,对于一个人工智能模型而言,它需要既可以处理文本,也可以处理图像,又可以处理语音,还可以处理其他任务等。

Photo by AI
2、深度学习中的多模态
在目前的人工智能任务中,我们所说的多模态更多的指对于 3V 任务的支持,也即 Verbal(文本)、Vocal(语音) 和 Visual(视觉)。
深度学习中有很多经典的任务,都是基于这三种任务之间互相转换的。
比如图像生成任务(Image Generation from Text),根据文本描述生成图像。

再比如反过来的图像描述任务(Image Captioning),根据图像来生成文本,就像是我们小学学的看图作文一样。

当然除了图像和文本之间的跨模态深度学习之外,还有文本和语音的跨模态,如微信支持的语音转文字功能。
还有语音转图片,如给一段话,按照话语中的描述转换为一张图片。
这种组合可以有很多种,就像是人一样,不同感官获取到了不同形式的信息,统一都会送给大脑来处理,处理完之后,以另一种形式表现出来。
人看到了图像,会用语言描述出来,AI 也需要具备这样的能力。
正因为如此,一旦大模型支持了多模态,就可以十分轻松地完成多种数据之间的转换,也就使得大模型在表现上离通用人工智能更近了一步。
很多同学在看了我的文章后,加我微信探讨如何入门深度学习。我最近也总结了自己之前学习的经验,开发一个计算机视觉从零入门的学习小册子专栏:https://blog.csdn.net/dongtuoc/category_12498033.html
欢迎查阅。