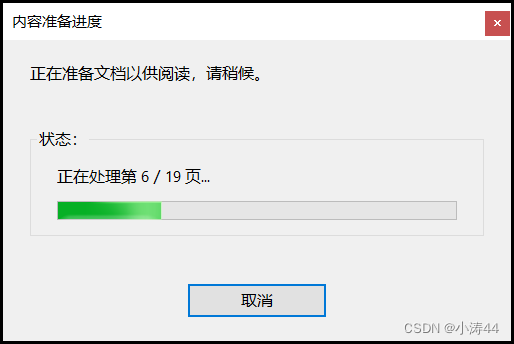
数组如何寻址
a[n]=起始地址+(n*字节数) 译:a[2]=100+(2*4) 2为下标、4为int类型字段占四个字节
LinkedList
LinkedList为双向链表结构,链表结构又分为单向、双向、以及循环。
// 双向链表
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}}//单向链表private static class Node<E> {E item;Node<E> next;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;}}//循环链表private static class Node<E> {E item;Node<E> next;Node<E> prev;Node<E> head;Node<E> tail;Node(Node<E> prev, E element, Node<E> next, Node<E> head, Node<E> tail) {this.item = element;this.next = next;this.prev = prev;this.head=head;this.tail=tail;}}
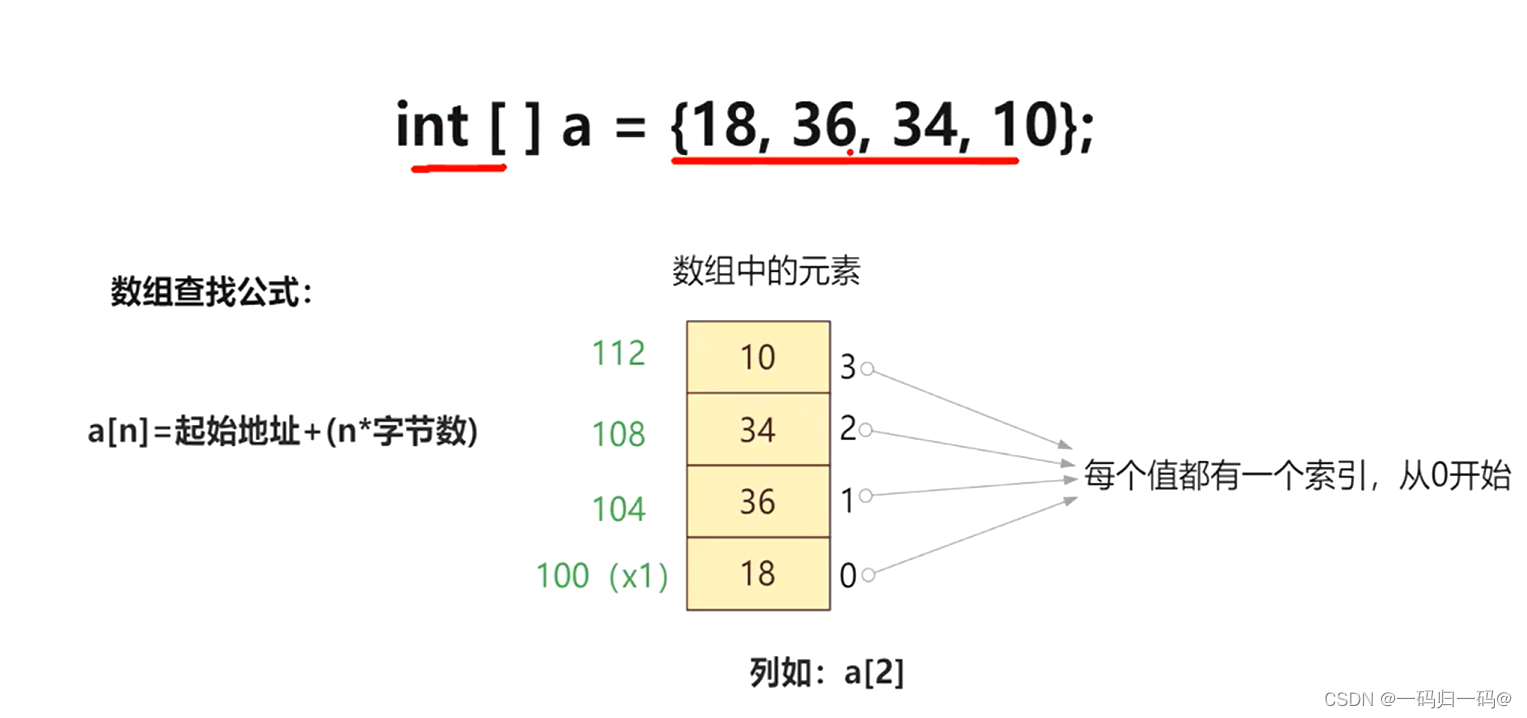
HashMap
数据结构:数组+链表+红黑树
注意:单个链表的长度达到8时会转换为红黑树,但是删除元素后长度小于6时则会将红黑树转换为链表

当lies存入后,foes值存入时出现Hash冲突,则用链表存储foes。若lies这个数组节点的链表长度大于8且Hash表大于64时该链表结构转换为红黑树
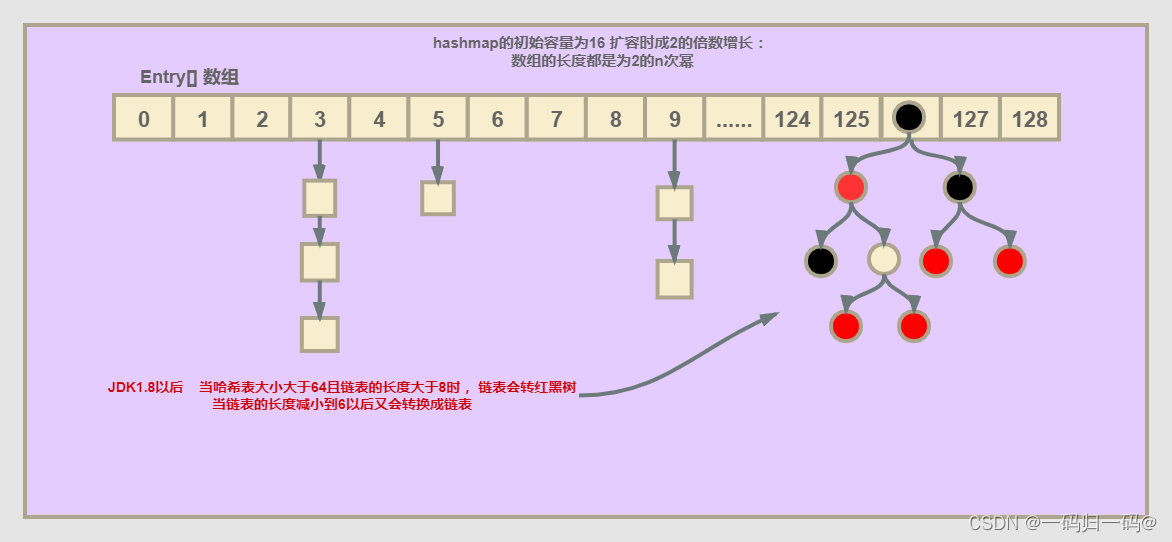
链表的插入规则以及问题
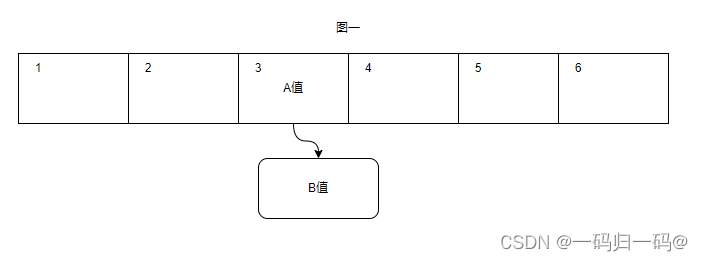
JDK1.7头插法
先插入A值后插入B值,在插入B值时出现与A值的Hash冲突,那么B值会替代A值原有的位置,然后将B值的next指向A值。
图一为A值插入后的初始状态

图二为插入A值后插入B值,B值取代A值的位置,B值next指向A值
JDK1.8 尾插法,插入A值后插入B值,A值的next指向B。
如果发现hash取模后的数组索引位下无元素则直接新增,若不是空那就说明存在hash冲突,则判断数组索引位链表结构中的第一个元素的key以及hash值是否与新的key一致则直接覆盖,若不一致则判断当前的数组索引下的链表结构是否为红黑树,若为红黑树则走红黑树的新增方法,若不为红黑树则遍历当前链表结构,遍历中发现某个节点元素的next为null是则直接将新元素指针与next进行关联,若在遍历到next为空前判断到,某个节点的key以及key的hash值与新的key与新的keyhash值一致时则走覆盖。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//扩容HashMapif ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//hash是key的hash值取模,如果tab[hash]等于null说明该数组索引下没有值则直接插入if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;//数组索引下链表为一时才会触发 》》如果hash值以及key值一致则覆盖if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//若当前节点为红黑树则通过红黑树的方式将元素添加到树中else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {//当不是相同key或不是红黑树时遍历当前数组索引的链表结构for (int binCount = 0; ; ++binCount) {//遍历到链表中某个节点的next节点为空则直接将链表最后一个节点的next指针指向新的元素if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);//若发现添加元素后链表长度大于8则将当前数组索引的链表转换为红黑树结构if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}//若发现hash值以及key一致则认为要覆盖if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//两个覆盖逻辑,若发现一致则覆盖if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
ConcurrentHashMap
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;//若为空则初始化,ConcurrentHash new时不会初始化容器if (tab == null || (n = tab.length) == 0)tab = initTable();//若发现数组索引位下无元素则采用cas乐观锁的方式进行put。else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}//若上述条件不满住且当前槽位的hash值为-1则说明当前正在扩容中并加速扩容,等待下一次循环走入下方的elseelse if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;//若当前数组索引下的元素不为空则说明出现hash冲突,可以用链表存储则将当前元素加锁synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;//判断新key与遍历的元素key是否一致,若一致则直接覆盖if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;//若发现链表中没有一致的key,那就就将新元素插入到最后一个元素的后面if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}//若发现“链表”为树的结构则通过红黑树的方式进行putelse if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}//最终判判断决定是否将链表结构是否要转换成红黑树if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}

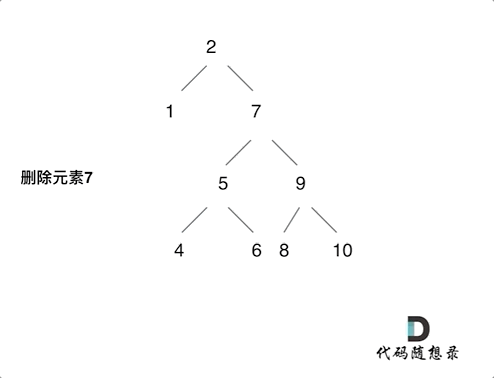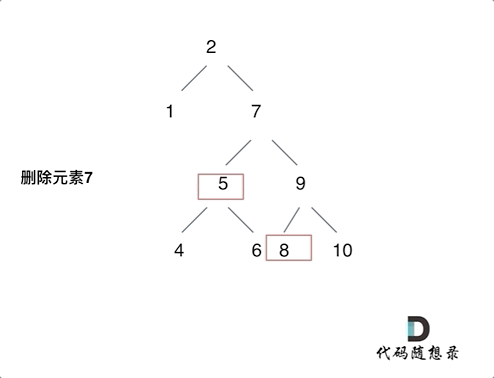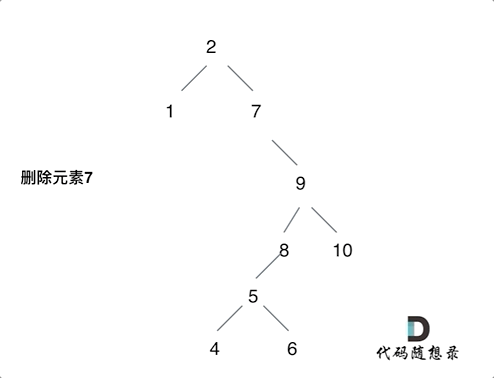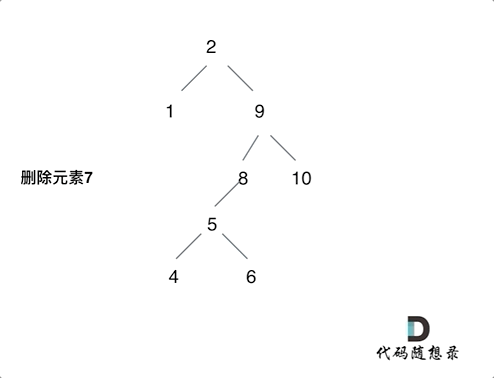

![[C#]C# OpenVINO部署yolov8实例分割模型](https://img-blog.csdnimg.cn/direct/48d6f935d195433dbf9570b92947a532.jpeg)