使用 pg_stat_statements 优化查询

就使用量和社区规模而言,PostgreSQL 是增长最快的数据库之一,得到许多专业开发人员的支持,并得到广泛的工具、连接器、库和可视化应用程序生态系统的支持。 PostgreSQL 也是可扩展的:使用 PostgreSQL 扩展,用户可以向 PostgreSQL 的核心添加额外的功能。
今天,我们很高兴与大家分享,最流行和最广泛使用的 PostgreSQL 扩展之一 pg_stat_statements 。
pg_stat_statements 允许您快速识别有问题或缓慢的 Postgres 查询,从而提供对数据库性能的可观察性。
什么是 pg_stat_statements?
pg_stat_statements 是一个 PostgreSQL 扩展,用于记录有关正在运行的查询的信息。识别数据库中的性能瓶颈,这个过程通常感觉就像一场猫捉老鼠的游戏。快速编写的查询、索引更改或复杂的 ORM 查询生成器可能(并且经常)对数据库和应用程序性能产生负面影响。
如何使用 pg_stat_statements
正如我们将在这篇文章中向您展示的那样, pg_stat_statements 是一个非常宝贵的工具,可以帮助您确定哪些查询执行缓慢且性能不佳以及原因。例如,可以查询 pg_stat_statements 以了解查询被调用了多少次、查询执行时间、查询的命中缓存率(内存中与磁盘上有多少数据可以满足要求)以及其他有用的统计信息,例如查询执行时间的标准差。
如何在postgres中使用 pg_stat_statements
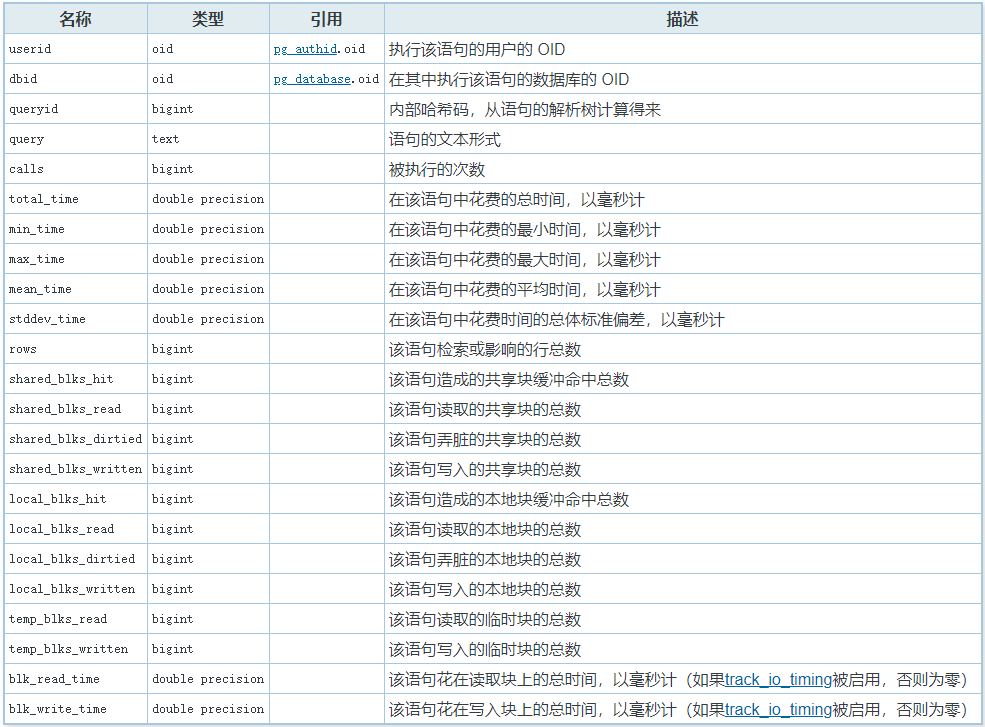
连接到数据库后,从 pg_stat_statements 视图查询 postgres数据库的统计数据非常简单。该视图返回许多数据列(超过 30 列!)。
SELECT * FROM pg_stat_statements;userid|dbid |queryid |query
------+-----+--------------------+------------------------------16422|16434| 8157083652167883764|SELECT pg_size_pretty(total_by10|13445| |<insufficient privilege> 16422|16434|-5803236267637064108|SELECT game, author_handle, gu16422|16434|-8694415320949103613|SELECT c.oid,c.*,d.description10|16434| |<insufficient privilege> 10|13445| |<insufficient privilege> ... |... |... |...
如果当前 用户无权访问的查询将隐藏查询文本和标识符,该列显示 <insufficient privilege>
pg_stat_statements收集所有数据库和用户的数据,如果允许任何用户查询性能数据,则会对安全带来挑战。因此,尽管任何用户都可以从视图中查询数据,但只有超级用户和专门授予 pg_read_all_stats 权限的用户才能查看所有用户级别的详细信息,包括 queryid 和 query
尽管您使用的当前用户拥有数据库并拥有很多权限,但如果它不是超级用户,无法查看服务集群内所有其他查询的详细信息。
因此,对于您想要执行的任何查询,最好按 userid 过滤 pg_stat_statements 数据。
-- current_user will provide the rolname of the authenticated user
SELECT * FROM pg_stat_statements pssJOIN pg_roles pr ON (userid=oid)
WHERE rolname = current_user;userid|dbid |queryid |query
------+-----+--------------------+------------------------------16422|16434| 8157083652167883764|SELECT pg_size_pretty(total_by16422|16434|-5803236267637064108|SELECT game, author_handle, gu16422|16434|-8694415320949103613|SELECT c.oid,c.*,d.description... |... |... |...
仅查询 current_user 用户,显示所有详细信息和统计信息
添加过滤器后,仅显示您有权访问的数据。如果您在服务中为特定应用程序创建了其他帐户,您还可以过滤到这些帐户。
为了使我们的示例查询的其余部分更易于使用,建议您将此基本查询与CTE 结合使用。此查询表单将返回相同的数据,但使查询的其余部分更容易编写。
-- current_user will provide the rolname of the authenticated user
WITH statements AS (
SELECT * FROM pg_stat_statements pssJOIN pg_roles pr ON (userid=oid)
WHERE rolname = current_user
)
SELECT * FROM statements;userid|dbid |queryid |query
------+-----+--------------------+------------------------------16422|16434| 8157083652167883764|SELECT pg_size_pretty(total_by16422|16434|-5803236267637064108|SELECT game, author_handle, gu16422|16434|-8694415320949103613|SELECT c.oid,c.*,d.description... |... |... |...
显示与之前相同结果的查询,但这次使用 CTE 中的基本查询,以便稍后进行更简洁的查询
现在我们知道如何仅查询我们有权访问的数据,让我们回顾一下对于发现查询潜在问题最有用的一些列。
calls: 调用此查询的次数。total_exec_time: 执行查询所花费的总时间(以毫秒为单位)。rows: 此查询检索到的总行数。shared_blks_hit:查询读取时已缓存的块数。shared_blks_read: 为满足对此查询表单的所有调用而必须从磁盘读取的块数。
关于上述数据列的三个快速提醒:
- 自上次启动服务或超级用户手动重置这些值以来,所有值都是累积的。
你可以使用 SELECT pg_stat_statements_reset(); 重置统计信息
2. 在参数化查询后,所有值都针对相同的查询语句,并基于生成的散列 queryid 。
3. 由于增加的开销很小,当前配置不跟踪查询计划统计信息。将来我们可能会通过用户配置允许这样做。
使用这些数据列,让我们看一些常见的查询,它们可以帮助您缩小有问题的查询的范围。
长时间运行的 PostgreSQL 查询
查找值得您关注的慢 Postgres 查询的最快方法之一是查看每个查询的平均总时间。这不是时间加权平均值,因为数据是累积的,但它仍然有助于构建从哪里开始的相关背景。
调整 calls 值以满足您的特定应用程序需求。查询更高(或更低)的调用总数可以帮助您识别不经常运行但非常昂贵的查询,或者运行频率比您预期高得多且运行时间比应有的时间长的查询。
-- query the 10 longest running queries with more than 500 calls
WITH statements AS (
SELECT * FROM pg_stat_statements pssJOIN pg_roles pr ON (userid=oid)
WHERE rolname = current_user
)
SELECT calls, mean_exec_time, query
FROM statements
WHERE calls > 500
AND shared_blks_hit > 0
ORDER BY mean_exec_time DESC
LIMIT 10;calls|mean_exec_time |total_exec_time | query
-----+---------------+----------------+-----------2094| 346.93 | 726479.51 | SELECT time FROM nft_sales ORDER BY time ASC LIMIT $1 |3993| 5.728 | 22873.52 | CREATE TEMPORARY TABLE temp_table ... |3141| 4.79 | 15051.06 | SELECT name, setting FROM pg_settings WHERE ... |
60725| 3.64 | 221240.88 | CREATE TEMPORARY TABLE temp_table ... | 801| 1.33 | 1070.61 | SELECT pp.oid, pp.* FROM pg_catalog.pg_proc p ...|... |... |... |
平均执行时间最长的查询
我们用于这些查询的示例数据库基于 NFT 销售数据。作为正常过程的一部分,您可以看到创建了一个 TEMPORARY TABLE 来读取新数据并更新现有记录,作为轻量级提取-转换-加载过程的一部分。
自该服务启动以来,该查询已被调用 60,725 次,并且创建该表花费了大约 4.5 分钟的总执行时间。相比之下,显示的第一个查询平均执行时间最长,每次大约 350 毫秒。它检索 nft_sales 表中最旧的时间戳,并且自服务器启动以来已使用超过 12 分钟的执行时间。
从工作角度来看,找到提高第一个查询性能的方法将对整体服务器工作负载产生更显着的影响。
Hit Cache Ratio 缓存命中率
与计算中的几乎所有事物一样,当可以在内存中查询数据而不是访问外部磁盘存储时,数据库往往会表现最佳。如果 PostgreSQL 必须从存储中检索数据来满足查询,那么通常会比所有需要的数据都已加载到 PostgreSQL 的保留内存空间中要慢。我们可以通过称为缓存命中率的值来测量查询执行此操作的频率。
缓存命中率是对满足查询所需的数据在内存中可用的频率的度量。较高的百分比意味着数据已经可用并且不必从磁盘读取,而较低的值可能表明服务器存在内存压力并且无法跟上当前的工作负载。
如果 PostgreSQL 必须不断地从磁盘读取数据来满足相同的查询,则意味着其他操作和数据会优先,并且每次都会将查询所需的数据“推送”回磁盘。
这是时间序列工作负载的常见场景,因为较新的数据首先写入内存,如果没有足够的可用缓冲区空间,则使用较少的数据将被逐出。如果您的应用程序查询大量历史数据,较旧的超表块可能无法加载到内存中并准备好快速服务查询。
一个好的起点是经常运行且缓存命中率低于 98% 的查询。这些查询是否倾向于提取长时间段的数据?如果是这样,这可能表明没有足够的 RAM 来有效地存储这些数据足够长的时间,然后再将其逐出以获取新数据。
根据应用程序查询模式,您可以通过增加服务器资源来提高命中缓存率,考虑调整索引以减少表存储,或对定期查询的旧块使用 数据库 压缩。
-- query the 10 longest running queries
WITH statements AS (
SELECT * FROM pg_stat_statements pssJOIN pg_roles pr ON (userid=oid)
WHERE rolname = current_user
)
SELECT calls, shared_blks_hit,shared_blks_read,shared_blks_hit/(shared_blks_hit+shared_blks_read)::NUMERIC*100 hit_cache_ratio,query
FROM statements
WHERE calls > 500
AND shared_blks_hit > 0
ORDER BY calls DESC, hit_cache_ratio ASC
LIMIT 10;calls | shared_blks_hit | shared_blks_read | hit_cache_ratio |query
------+-----------------+------------------+-----------------+--------------118| 441126| 0| 100.00| SELECT bucket, slug, volume AS "volume (count)", volume_eth...261| 62006272| 22678| 99.96| SELECT slug FROM streamlit_collections_daily cagg...¶ I2094| 107188031| 7148105| 93.75| SELECT time FROM nft_sales ORDER BY time ASC LIMIT $1... 152| 41733229| 1| 99.99| SELECT slug FROM streamlit_collections_daily cagg...¶ I154| 36846841| 32338| 99.91| SELECT a.img_url, a.name, MAX(s.total_price) AS price, time...... |... |... | ... | ...
显示每个查询的缓存命中率的查询,包括从磁盘或内存中准备好满足查询的缓冲区数量
该示例数据库不是很活跃,因此与传统应用程序可能显示的相比,总体查询计数不是很高。在上面的示例数据中,调用次数超过 500 次的查询是“常用查询”。
我们可以从上面看到,最昂贵的查询之一也恰好具有最低的缓存命中率,为 93.75%。这意味着大约 6% 的时间,PostgreSQL 必须从磁盘检索数据来满足查询。虽然这看起来可能不是很多,但在大多数情况下,最常调用的查询的比例应该为 99% 或更高。
如果仔细观察,您会发现这与我们第一个示例中突出的查询相同,该示例展示了如何查找长时间运行的查询。很快我们就发现我们可以通过某种方式调整这个查询来获得更好的性能。就目前而言,它是每次调用最慢的查询,并且它始终必须从磁盘而不是内存中读取一些数据。
具有高标准差的查询
作为最后一个示例,让我们看另一种方法,使用查询执行时间的标准差来判断哪些查询通常具有最大的改进机会。
查找最慢的查询是一个很好的起点。然而,平均值只是故事的一部分。尽管 pg_stat_statements 没有提供跟踪时间加权平均值的方法,但它确实跟踪所有调用和执行时间的标准偏差。
这有什么作用?
标准差是一种评估每个查询执行所花费的时间与总体平均值相比的方法。如果标准偏差值很小,则所有查询的执行时间都相似。如果标准偏差值很大,则表明查询的执行时间在不同请求之间存在显着差异。
确定特定查询的标准差好坏需要更多数据,而不仅仅是平均值和标准差。为了充分利用这些数字,我们至少需要添加查询的最小和最大执行时间。通过这样做,我们可以开始形成查询所需的总体执行时间的心理模型。
在下面的示例结果中,我们仅显示一个查询的数据,以便于阅读,这与我们在上一个示例输出中看到的 ORDER BY time LIMIT 1 查询相同。
-- query the 10 longest running queries
WITH statements AS (
SELECT * FROM pg_stat_statements pssJOIN pg_roles pr ON (userid=oid)
WHERE rolname = current_user
)
SELECT calls, min_exec_time,max_exec_time, mean_exec_time,stddev_exec_time,(stddev_exec_time/mean_exec_time) AS coeff_of_variance,query
FROM statements
WHERE calls > 500
AND shared_blks_hit > 0
ORDER BY mean_exec_time DESC
LIMIT 10;Name |Value |
------------------+-----------------------------------------------------+
calls |2094 |
min_exec_time |0.060303 |
max_exec_time |1468.401726 |
mean_exec_time |346.9338636657108 |
stddev_exec_time |212.3896857655582 |
coeff_of_variance |0.612190702635494 |
query |SELECT time FROM nft_sales ORDER BY time ASC LIMIT $1|
显示每个查询的最小值、最大值、平均值和标准差的查询
在这种情况下,我们可以从这些统计数据中推断出一些事情:
- 对于我们的应用程序,此查询会被频繁调用(请记住,对于此示例数据库来说,超过 500 次调用就已经很多了)。
- 如果我们结合平均值查看整个执行时间范围,我们会发现平均值不居中。这可能意味着存在执行时间异常值或数据存在偏差。两者都是进一步研究该查询的执行时间的充分理由。
- 此外,如果我们查看变异系数列(coefficient of variation column),即标准差与平均值之间的比率(也称为变异系数),我们会得到 0.612,这是相当高的。一般来说,如果这个比率高于 0.3,那么数据的变化就相当大。由于我们发现数据差异很大,这似乎意味着,不是一些异常值扭曲了均值,而是有许多执行时间比应有的时间要长。这进一步确认应进一步调查该查询的执行时间。
当我一起检查这三个查询的输出时,这个特定的 ORDER BY time LIMIT 1 查询似乎很突出。它的每次调用速度比大多数其他查询要慢,它通常需要数据库从磁盘检索数据,并且执行时间似乎随着时间的推移而发生巨大变化。只要我了解此查询的使用位置以及应用程序可能受到的影响,我就会发现肯定会把这个“第一点”查询放在我需要改进的事情列表中。
加快 PostgreSQL 查询速度
pg_stat_statements 扩展是一个非常宝贵的监视工具,特别是当您了解如何在数据库和应用程序上下文中使用统计数据时。
例如,每天或每月调用几次的昂贵查询可能不值得立即进行调整。相反,每小时调用数百次(或更多)的中等速度的查询可能会更好地利用您的查询调优工作。
如果您想了解如何定期存储指标快照以及如何从静态累积信息转移到时间序列数据以实现更高效的数据库监控,请查看博客文章Point-in-Time PostgreSQL Database and Query Monitoring With pg_stat_statements。
原文连接
参考文章:
PostgreSQL高耗sql利器pg_stat_statements部署使用分享 - UCloud云社区