数据是大模型训练至关重要的一环。数据规模、质量、配比,很大程度上决定了最后大模型的性能表现。无论是大规模的预训练数据、精益求精的SFT数据都依托于一个完整的“获取-准备-处理-分析”数据流程。然而,当前的开源工具通常只专注于流程中的某一环节,很少有能够覆盖整个流程的项目。此外,这些工具处理的数据质量参差不齐,很难“干净地”从不同原始数据中提取表格、图片等结构化信息,这给构建大模型的训练数据集带来了极大的挑战。
智源发布FlagData聚焦在大模型时代的数据处理问题,旨在提供全面的、高效的大模型训练数据治理工具集,覆盖训练数据获取、清洗及迭代维护各个阶段,提高数据的利用率和质量,实现高效的数据处理及管理。当前FlagData v2.0全面升级支持多种原始格式高质量内容提取,提供大模型微调数据透视分析,用户可通过FlagData实现一站式的分布式数据处理,构建自己的数据处理平台。
↓ FlagData开源仓库
https://github.com/FlagOpen/FlagData
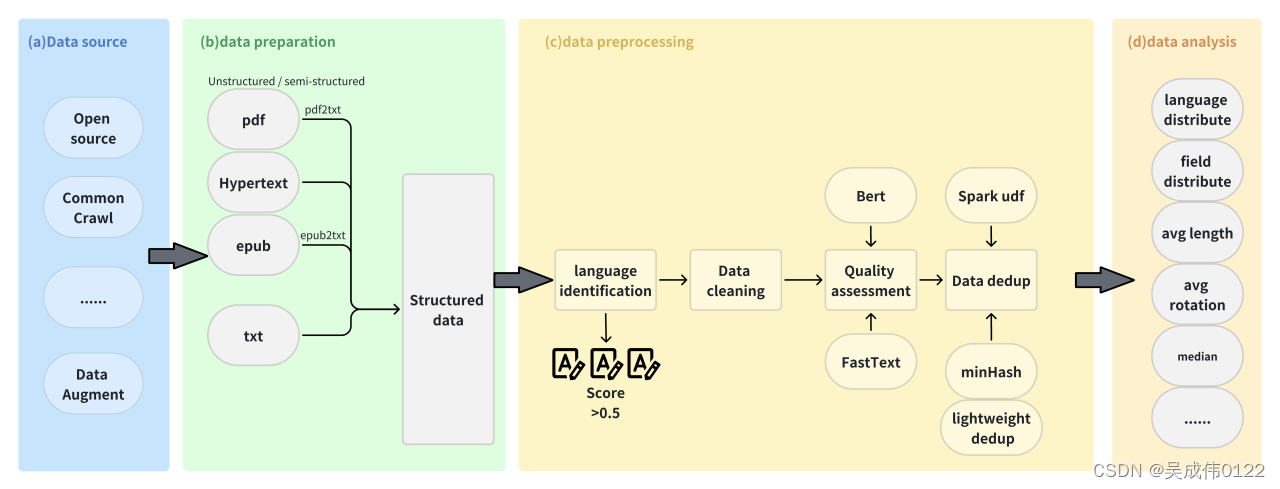
FlagData:全面、高效的大模型训练数据治理工具集
1. 实现多种原始格式数据的高质量内容提取,极大降低处理成本
大模型的发展依赖于干净、高质量的数据。然而,大多数数据难以发现、使用和清理。这些数据常以 HTML、PDF、CSV、PNG、PPTX 等不同格式存在,然而这些非结构化的数据形式难以让大模型“学到”有用的知识,“阅读”效率也欠佳。
在全面对比了主流开源数据工具之后,FlagData针对数据清洗任务进行了专门优化,并对现有开源工具中的相关功能进行了扩展升级,更好地适应大模型训练场景,从而降低了新手的使用门槛,帮助用户极大降低收集和清理数据的成本,让用户可以专注于难度更大的数据建模和分析任务上。
FlagData 能够有效地从多种不同原始格式数据中提取信息,并将其转换为干净、一致的 JSON 格式。JSON 格式对大模型训练非常友好,不仅便于进行分块、嵌入和集成到矢量数据库,还能轻松采用最先进的分块策略。将 PDF 和 EPUB 等原始数据转换 JSON 格式,可以确保了大模型训练过程中数据集能够持续更新。
此外,FlagData 集成了 pdf2txt 和 epub2txt 两个非结构化到文本的转换工具,能够识别表格、图表标题、正文、参考文献、页眉页脚、图像和公式等,并且为用户提供了两种数据处理方式:一种是将完整文档保存为 txt 文件,另一种是将图像、正文、参考文献等类别分别保存为 jsonList 格式。
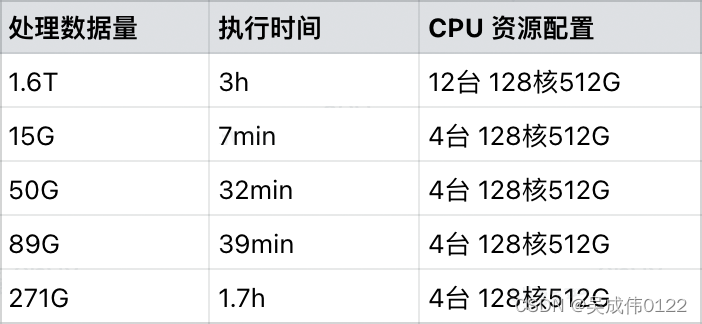
如下是主流工具的对比:
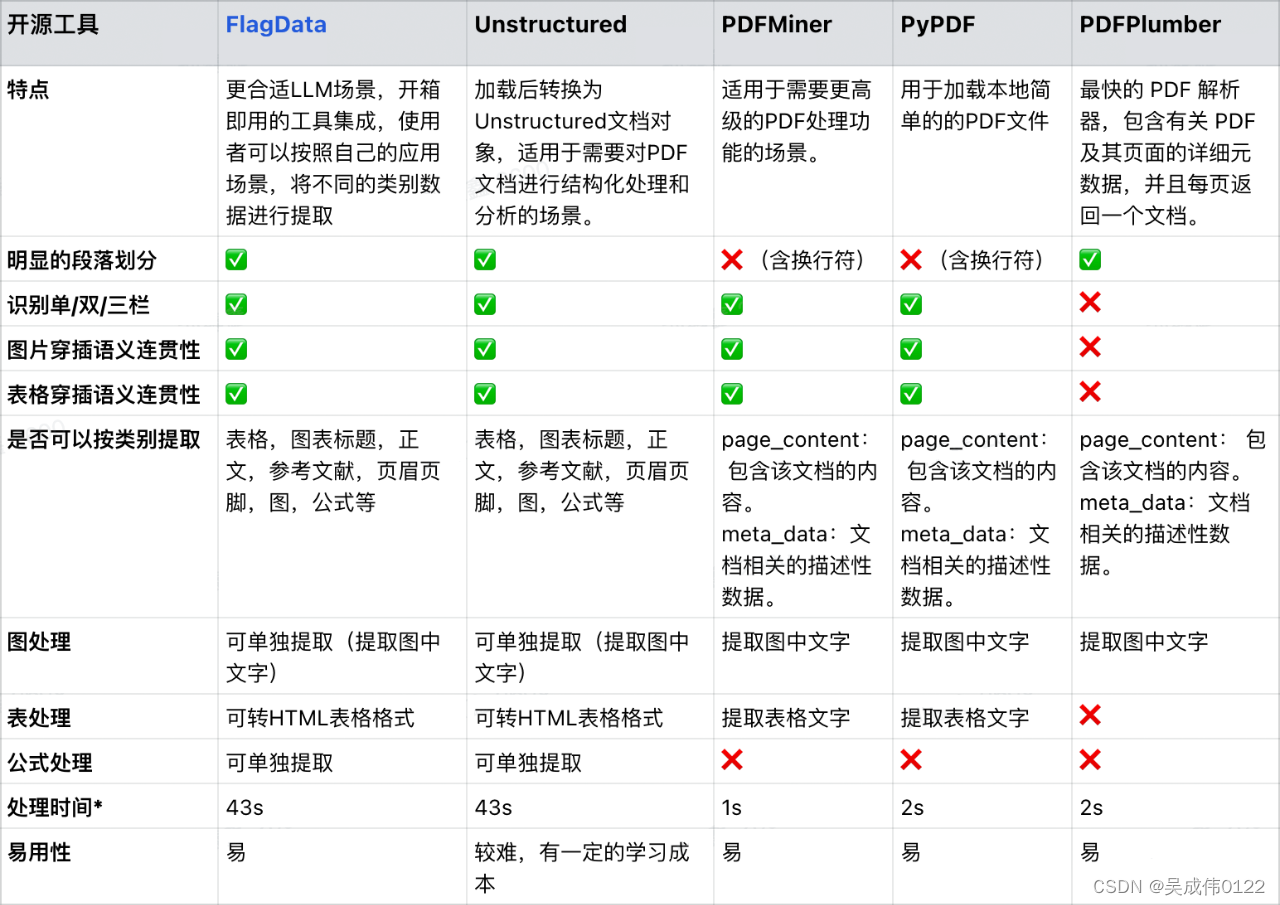
* 注:“处理时间”是对同一篇 arxiv 论文进行数据提取所花费的时间。
以下是两个 FlagData 提取复杂内容的例子。对多栏排版数据,FlagData进行了针对性优化,能处理绝大多数多栏信息;在论文表格提取,FlagData 将表格转化为 HTML 格式并且无多余字符,ChatGPT 大模型能够正确“读懂”表格内容。





2. 提供大模型微调数据透视功能
一般来说,大模型微调数据处理的关键步骤包括:
-
数据探索和理解:对微调数据进行初步的分析和探索,了解数据的分布、类别不平衡、特征之间的相关性等。这种理解有助于更好地选择微调策略和模型配置。
-
微调策略选择:如选择合适的优化器、调整学习率的策略、冻结哪些层等,以便让模型更快地收敛并取得更好的性能。
-
数据配比的选择:即通过对不同来源的数据做合适的上采样和下采样调整其在预训练数据中的占比。预训练的过程是比较耗资源的且训练过程往往是不可逆的,实验代价比较大,枚举比较完备的消融实验更是不太可能。同时单单数据维度就有很多种变量,尤其是数据配比,有中英文配比,不同来源的数据配比,不同任务的数据配比,不同质量的数据配比(被过滤的低质量仍可能有比较多的误过滤的好样本)。在实际的模型开发中,开发者往往在更小规模的模型上做消融实验对比,以此决定数据配比。
-
例如,ChatGPT3.5数据配比应该是OpenAI最核心的“秘密”和领先之处。
-
此外,专业领域的数据占比也是关键。专业知识需要和世界性知识进行合理的搭配才能训练出较好的领域大模型,否则大模型会同时损失世界性知识的问答效果以及专业性知识的问答能力。
-
针对大模型微调数据集构建的需求,FlagData 提供大模型多维度的数据透视功能:
-
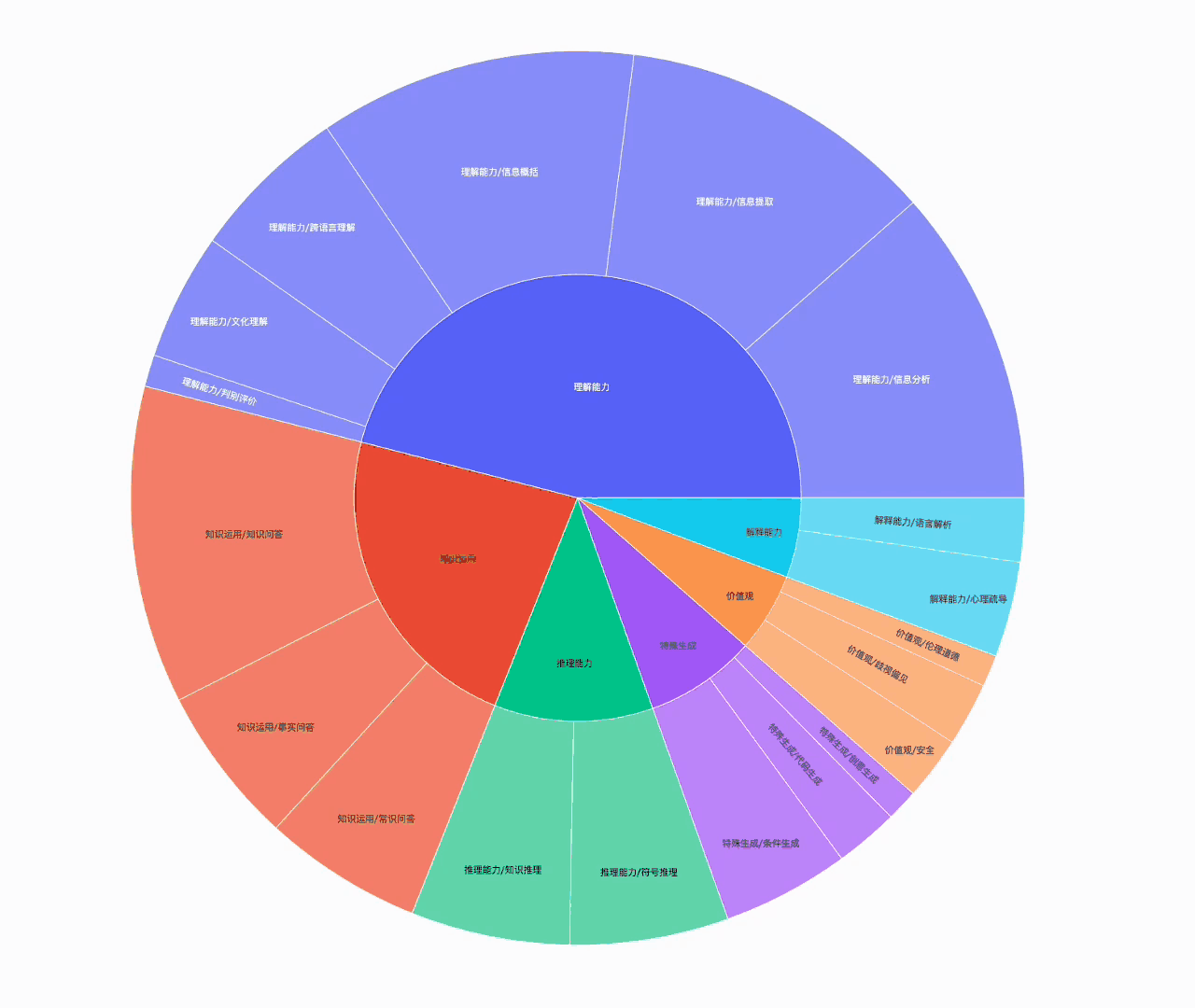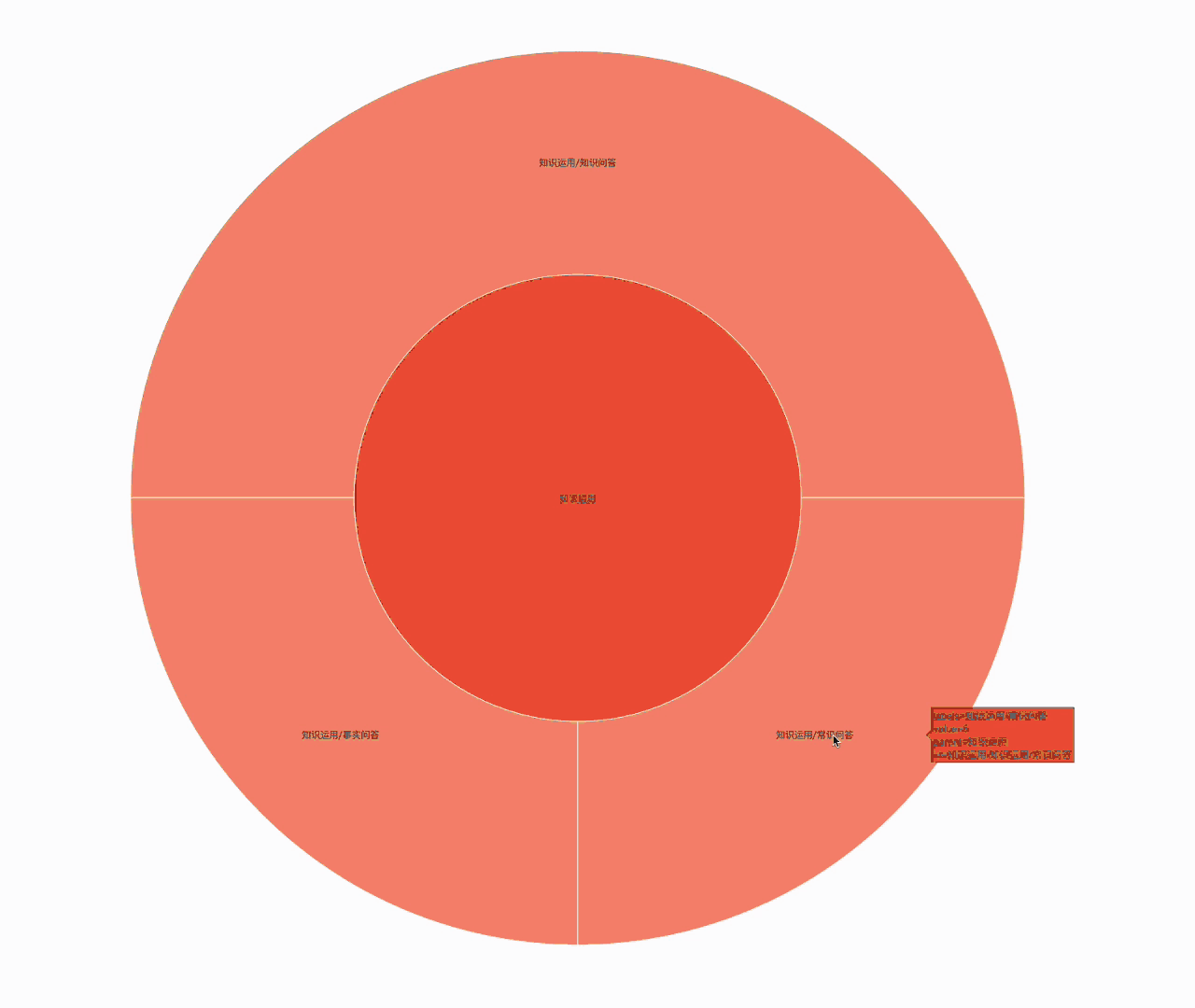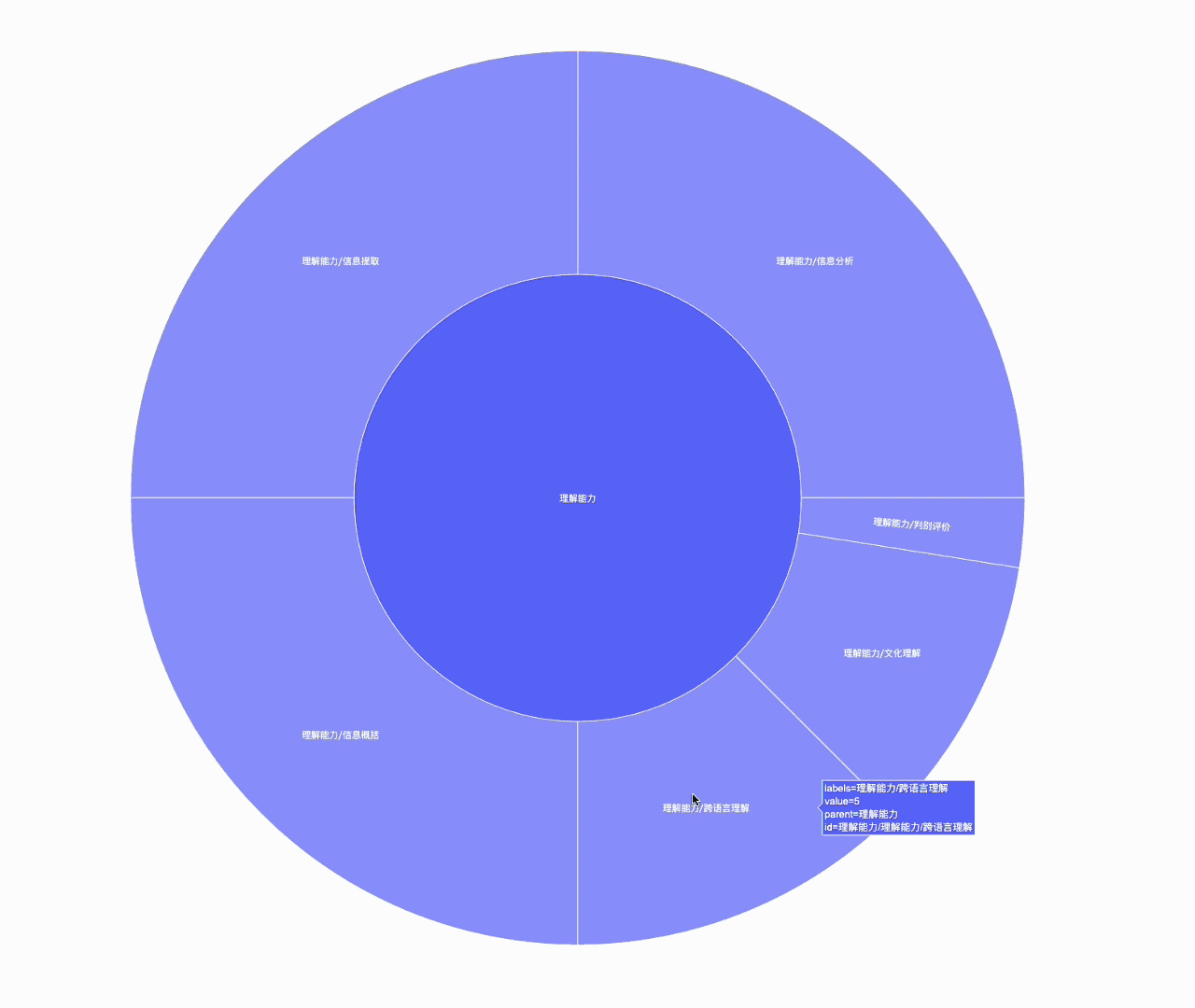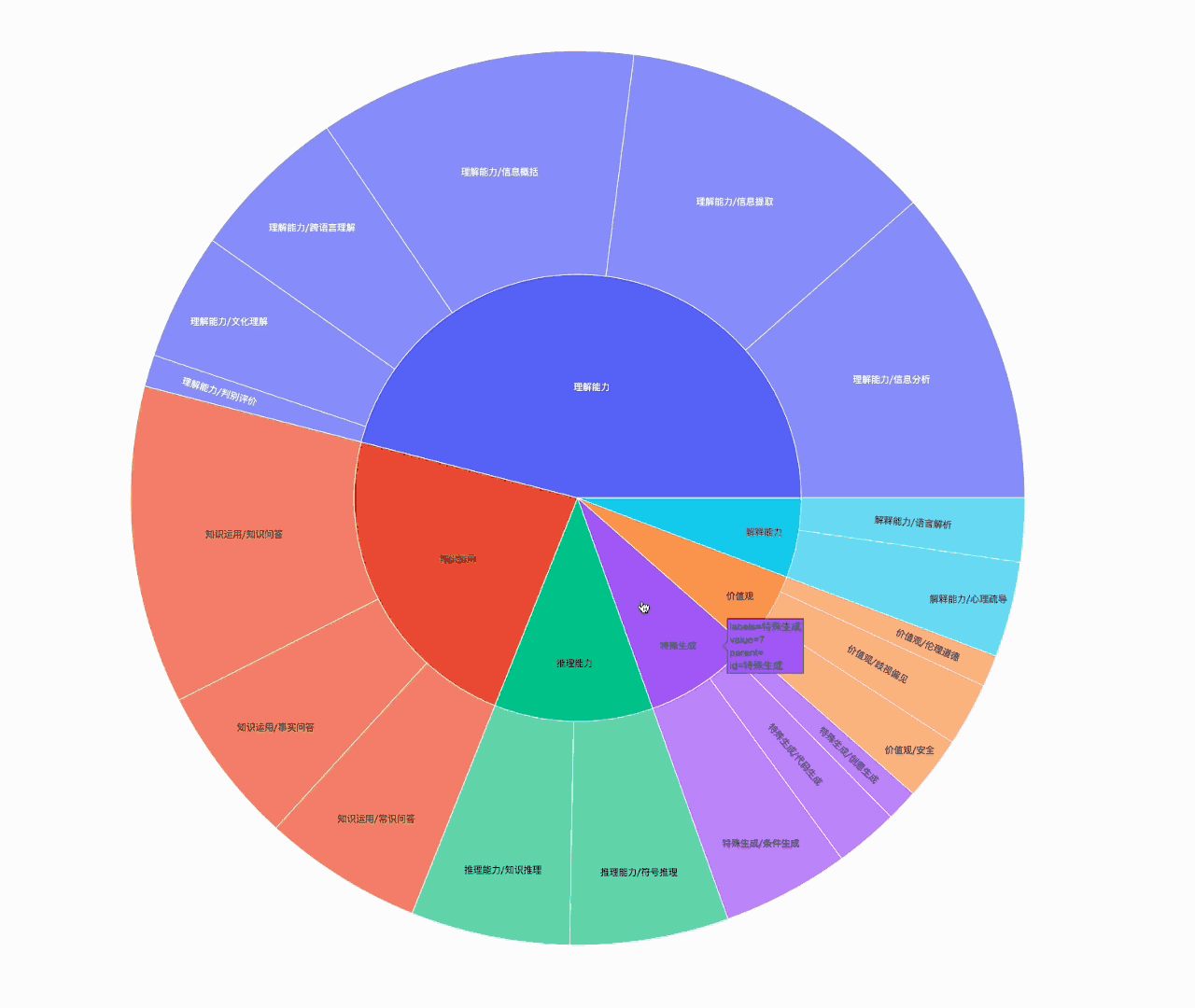
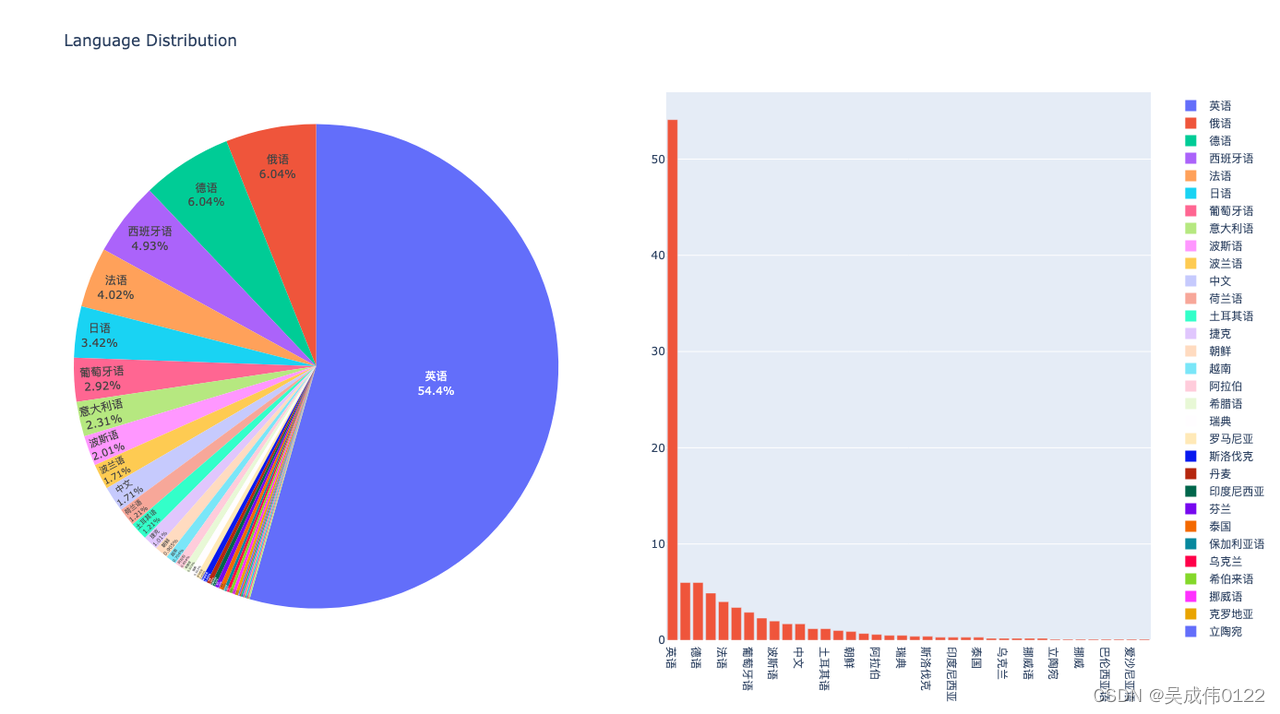
文本内容和领域分析:对文本数据进行领域分析,了解微调数据的主题,以确保模型在微调阶段对数据有充分的理解。
-
语言特征分析:分析文本中的语言特征,有助于了解文本的语言风格和复杂度。
-
文本本长度分析:分析文本的长度分布情况,包括句子长度、段落长度、文档长度等,有助于确定微调过程中所需的最大长度限制或截断策略。
以下是文本内容的领域分析和语言分析的效果图:
3. 一站式高效分布式数据处理功能
FlagData 使用 MinHashLSH 算法和 Spark 分布式数据分析引擎,提供 TB级/小时的分布式数据去重能力。
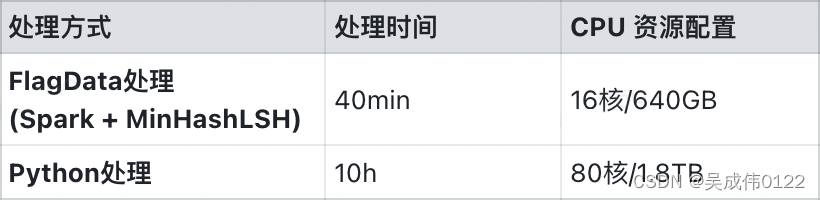
Spark + MiniHashLSH 也是GPT-3技术报告[1]中所披露的数据去重处理方案。MinHashLSH(最小哈希局部敏感哈希)算法是将文本转换为一系列哈希值,以便比较文本之间的相似性。在FlagData中,用户可以根据需要在FlagData配置中设置更高的 threshold 值(相似性阈值),以便只保留那些非常相似的文本,而丢弃那些相似性稍微低一些的文本,经验默认值为0.87。
相比SimHash等算法,FlagData 中的 MinHashLSH 算法,在准召率以及处理速度上都具有优势。以下是一个实际的例子:该文本在开头、编辑姓名等方面有细微区别,利用 FlagData 可以识别出这两段文本高度相似。

尽管Spark封装了许多高级API,但是对于没有Spark使用经验的同学来讲仍需要花很多时间学习,FlagData 提供了一个基础示例,用户可以直接使用python编写 Spark的UDF(用户自定义函数),注册自己的Spark函数算子。即使用户对Spark并不是非常了解,也可以完成 sparkSession创建、udf函数定义、注册、使用、执行等完整流程。另外,FlagData 还提供了“小白教程”帮助用户创建 Spark 集群进行分布式数据处理(详细步骤参考 FlagData deduplication模块)。
未来规划
FlagData 将继续致力于构建一个更加全面的数据处理工具箱:
-
实现跨任务自动化,覆盖大模型训练数据、推理数据的开发及其维护各个阶段;
-
建设数据血缘和标签体系,实现对情感和情绪的分析,识别文本中的实体、关键词和上下文关系,以方便用户可以有选择地使用数据增强模型在特定领域的性能表现。
-
深入探索能够处理多模态数据的解决方案
-
建立一个评估数据质量和人工智能技术的统一标准。
欢迎各界使用 FlagData 并提供反馈,大家可以通过 GitHub issue 与我们沟通:
https://github.com/FlagOpen/FlagData/issues
注释:
[1] Language Models are Few-Shot Learners, https://arxiv.org/pdf/2005.14165.pdf