一、背景
kerberos认证是比较底层的认证,掌握好了用起来比较简单。
kettle完成kerberos认证后会存储认证信息在jvm中,之后直接连接hive就可以了无需提供额外的用户信息。
spark thriftserver本质就是通过hive jdbc协议连接并运行spark sql任务。
二、思路
kettle中可以使用js调用java类的方法。编写一个jar放到kettle的lib目录下并。在启动kettle后会自动加载此jar中的类。编写一个javascript转换完成kerbero即可。
二、kerberos认证模块开发
准备使用scala语言完成此项目。
hadoop 集群版本: cdh-6.2.0
kettle 版本: 8.2.0.0-342
2.1 生成kerberos工具jar包
2.1.1 创建maven项目并编写pom
创建maven项目,这里依赖比较多觉得没用的删掉即可:
注意:这里为了便于管理,很多包都是compile,最后通过maven-assembly-plugin复制到zip文件中!!!
<properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><scala.version>2.11.12</scala.version><scala.major.version>2.11</scala.major.version><target.java.version>1.8</target.java.version><hadoop.version>3.0.0-cdh6.2.0</hadoop.version><spark.version>2.4.0-cdh6.2.0</spark.version><hive.version>2.1.1-cdh6.2.0</hive.version><zookeeper.version>3.4.5-cdh6.2.0</zookeeper.version><jackson.version>2.14.2</jackson.version><httpclient5.version>5.2.1</httpclient5.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version><scope>compile</scope></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version><scope>compile</scope></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version><scope>compile</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.28</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>2.9.1</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>2.11.1</version><scope>provided</scope></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.11.1</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version><scope>compile</scope></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><scope>compile</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${scala.major.version}</artifactId><version>${spark.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_${scala.major.version}</artifactId><version>${spark.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_${scala.major.version}</artifactId><version>${spark.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>${hive.version}</version><scope>compile</scope></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive-thriftserver_${scala.major.version}</artifactId><version>${spark.version}</version><scope>compile</scope></dependency><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>${zookeeper.version}</version><scope>compile</scope></dependency><!-- jackon --><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>${jackson.version}</version><scope>compile</scope></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>${jackson.version}</version><scope>compile</scope></dependency><dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><version>${jackson.version}</version><scope>compile</scope></dependency><dependency><groupId>com.fasterxml.jackson.module</groupId><artifactId>jackson-module-scala_2.11</artifactId><version>${jackson.version}</version><scope>compile</scope></dependency><!-- https://mvnrepository.com/artifact/org.junit.jupiter/junit-jupiter-api --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.6.2</version><scope>test</scope></dependency><dependency><groupId>org.scalatest</groupId><artifactId>scalatest_2.11</artifactId><version>3.2.8</version><scope>test</scope></dependency><dependency><groupId>org.scalactic</groupId><artifactId>scalactic_2.12</artifactId><version>3.2.8</version><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.14</version><scope>provided</scope></dependency></dependencies><build><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.5.6</version><configuration></configuration><executions><execution><id>scala-compiler</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>scala-test-compiler</id><phase>process-test-resources</phase><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><!-- disable surefire --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.7</version><configuration><skipTests>true</skipTests></configuration></plugin><!-- enable scalatest --><plugin><groupId>org.scalatest</groupId><artifactId>scalatest-maven-plugin</artifactId><version>2.2.0</version><configuration><reportsDirectory>${project.build.directory}/surefire-reports</reportsDirectory><junitxml>.</junitxml><filereports>WDF TestSuite.txt</filereports></configuration><executions><execution></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><appendAssemblyId>false</appendAssemblyId>
<!-- <descriptorRefs>-->
<!-- <descriptorRef>jar-with-dependencies</descriptorRef>-->
<!-- </descriptorRefs>--><descriptors><descriptor>src/assembly/assembly.xml</descriptor></descriptors><archive><!-- <manifest>--><!-- <!– 你的mainclass入口,我就是test.scala 在scala文件夹下, 目录就是scr/main/scala –>--><!-- <mainClass>com.chenxii.myspark.sparkcore.Test</mainClass>--><!-- </manifest>--></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build><repositories><repository><id>cloudera</id><name>cloudera</name><url>https://repository.cloudera.com/artifactory/cloudera-repos/</url></repository></repositories>
</project>新建一个空白的xml文件,如下图:

maven-assembly-plugin插件会使用到assembly.xml,粘贴如下内容,至assembly.xml文件中,再修改下 自己的项目groupid。
<assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.3"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.3 http://maven.apache.org/xsd/assembly-1.1.3.xsd"><id>appserverB</id><formats><format>zip</format></formats><dependencySets><dependencySet><outputDirectory>/ext-lib</outputDirectory><includes><include>org.apache.hadoop:*</include><include>org.apache.hive:*</include><include>org.apache.hive.shims:*</include><include>org.apache.spark:spark-hive-thriftserver_*</include><include>org.apache.zookeeper:*</include><include>org.apache.curator:*</include><include>org.apache.commons:commons-lang3</include><include>org.apache.commons:commons-configuration2</include><include>org.apache.commons:commons-math3</include><include>com.fasterxml.jackson.core:*</include><include>com.fasterxml.jackson.dataformat:*</include><include>com.fasterxml.jackson.module:*</include><include>org.scala-lang:*</include><include>org.apache.thrift:libthrift</include><include>com.thoughtworks.paranamer:paranamer</include><include>com.google.re2j:re2j</include><include>com.fasterxml.woodstox:woodstox-core</include><include>org.codehaus.woodstox:stax2-api</include><include>org.apache.httpcomponents.core5:*</include><include>org.apache.httpcomponents.client5:*</include><include>org.apache.htrace:*</include><include>com.github.rholder:guava-retrying</include><include>org.eclipse.jetty:jetty-util</include><include>org.mortbay.jetty:*</include><include>自己的项目groupid:*</include></includes></dependencySet></dependencySets>
</assembly>
2.1.2 编写类
KerberosConf 暂时没啥用。
case class KerberosConf(principal: String, keyTabPath: String, conf: String="/etc/krb5.conf")
ConfigUtils 类用于生成hadoop 的Configuration,kerberos认证的时候会用到。
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import java.io.FileInputStream
import java.nio.file.{Files, Paths}object ConfigUtils {val LOGGER = org.slf4j.LoggerFactory.getLogger(KerberosUtils.getClass)var hadoopConfiguration: Configuration = nullvar hiveConfiguration: Configuration = nullprivate var hadoopConfDir: String = nullprivate var hiveConfDir: String = nulldef setHadoopConfDir(dir: String): Configuration = {hadoopConfDir = dirrefreshHadoopConfig}def getHadoopConfDir: String = {if (StringUtils.isEmpty(hadoopConfDir)) {val tmpConfDir = System.getenv("HADOOP_CONF_DIR")if (StringUtils.isNotEmpty(tmpConfDir) && fileOrDirExists(tmpConfDir)) {hadoopConfDir = tmpConfDir} else {val tmpHomeDir = System.getenv("HADOOP_HOME")if (StringUtils.isNotEmpty(tmpHomeDir) && fileOrDirExists(tmpHomeDir)) {val tmpConfDirLong = s"${tmpHomeDir}/etc/hadoop"val tmpConfDirShort = s"${tmpHomeDir}/conf"if (fileOrDirExists(tmpConfDirLong)) {hadoopConfDir = tmpConfDirLong} else if (fileOrDirExists(tmpConfDirShort)) {hadoopConfDir = tmpConfDirShort}}}}LOGGER.info(s"discover hadoop conf from : ${hadoopConfDir}")hadoopConfDir}def getHadoopConfig: Configuration = {if (hadoopConfiguration == null) {hadoopConfiguration = new Configuration()configHadoop()}hadoopConfiguration}def refreshHadoopConfig: Configuration = {hadoopConfiguration = new Configuration()configHadoop()}def configHadoop(): Configuration = {var coreXml = ""var hdfsXml = ""val hadoopConfDir = getHadoopConfDirif (StringUtils.isNotEmpty(hadoopConfDir)) {val coreXmlTmp = s"${hadoopConfDir}/core-site.xml"val hdfsXmlTmp = s"${hadoopConfDir}/hdfs-site.xml"val coreExists = fileOrDirExists(coreXmlTmp)val hdfsExists = fileOrDirExists(hdfsXmlTmp)if (coreExists && hdfsExists) {LOGGER.info(s"discover hadoop conf from hadoop conf dir: ${hadoopConfDir}")coreXml = coreXmlTmphdfsXml = hdfsXmlTmphadoopAddSource(coreXml, hadoopConfiguration)hadoopAddSource(hdfsXml, hadoopConfiguration)}}LOGGER.info(s"core-site path : ${coreXml}, hdfs-site path : ${hdfsXml}")hadoopConfiguration}def getHiveConfDir: String = {if (StringUtils.isEmpty(hiveConfDir)) {val tmpConfDir = System.getenv("HIVE_CONF_DIR")if (StringUtils.isNotEmpty(tmpConfDir) && fileOrDirExists(tmpConfDir)){hiveConfDir = tmpConfDir} else {val tmpHomeDir = System.getenv("HIVE_HOME")if (StringUtils.isNotEmpty(tmpHomeDir) && fileOrDirExists(tmpHomeDir)) {val tmpConfDirShort = s"${tmpHomeDir}/conf}"if (fileOrDirExists(tmpConfDir)) {hiveConfDir = tmpConfDirShort}}}}LOGGER.info(s"discover hive conf from : ${hiveConfDir}")hiveConfDir}def configHive(): Configuration = {if (hiveConfiguration != null) {return hiveConfiguration} else {hiveConfiguration = new Configuration()}var hiveXml = ""val hiveConfDir = getHiveConfDirif (StringUtils.isEmpty(hiveConfDir)) {val hiveXmlTmp = s"${hiveConfDir}/hive-site.xml"val hiveExist = fileOrDirExists(hiveXml)if (hiveExist) {LOGGER.info(s"discover hive conf from : ${hiveConfDir}")hiveXml = hiveXmlTmphadoopAddSource(hiveXml, hiveConfiguration)}}LOGGER.info(s"hive-site path : ${hiveXml}")hiveConfiguration}def getHiveConfig: Configuration = {if (hiveConfiguration == null) {hiveConfiguration = new Configuration()configHive()}hiveConfiguration}def refreshHiveConfig: Configuration = {hiveConfiguration = new Configuration()configHive()}def hadoopAddSource(confPath: String, conf: Configuration): Unit = {val exists = fileOrDirExists(confPath)if (exists) {LOGGER.warn(s"add [${confPath} to hadoop conf]")var fi: FileInputStream = nulltry {fi = new FileInputStream(confPath)conf.addResource(fi)conf.get("$$")} finally {if (fi != null) fi.close()}} else {LOGGER.error(s"[${confPath}] file does not exists!")}}def toUnixStyleSeparator(path: String): String = {path.replaceAll("\\\\", "/")}def fileOrDirExists(path: String): Boolean = {Files.exists(Paths.get(path))}
}
KerberosUtils 就是用于认证的类。
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.security.UserGroupInformation
import org.apache.kerby.kerberos.kerb.keytab.Keytab
import org.slf4j.Loggerimport java.io.File
import java.net.URL
import java.nio.file.{Files, Paths}
import scala.collection.JavaConversions._
import scala.collection.JavaConverters._object KerberosUtils {val LOGGER: Logger = org.slf4j.LoggerFactory.getLogger(KerberosUtils.getClass)def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String, hadoopConf: Configuration): Boolean = {val authType = hadoopConf.get("hadoop.security.authentication")if (!"kerberos".equalsIgnoreCase(authType)) {LOGGER.error(s"kerberos utils get hadoop authentication type [${authType}] ,not kerberos!")} else {LOGGER.info(s"kerberos utils get hadoop authentication type [${authType}]!")}UserGroupInformation.setConfiguration(hadoopConf)System.setProperty("java.security.krb5.conf", krb5ConfPath)System.setProperty("javax.security.auth.useSubjectCredsOnly", "false")UserGroupInformation.loginUserFromKeytab(krb5Principal, krb5KeytabPath)val user = UserGroupInformation.getLoginUserif (user.getAuthenticationMethod == UserGroupInformation.AuthenticationMethod.KERBEROS) {val usnm: String = user.getShortUserNameLOGGER.info(s"kerberos utils login success, curr user: ${usnm}")true} else {LOGGER.info("kerberos utils login failed")false}}def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String): Boolean = {val hadoopConf = ConfigUtils.getHadoopConfigloginKerberos(krb5Principal, krb5KeytabPath, krb5ConfPath, hadoopConf)}def loginKerberos(kerberosConf: KerberosConf): Boolean = {loginKerberos(kerberosConf.principal, kerberosConf.keyTabPath, kerberosConf.conf)}def loginKerberos(krb5Principal: String, krb5KeytabPath: String, krb5ConfPath: String,hadoopConfDir:String):Boolean={ConfigUtils.setHadoopConfDir(hadoopConfDir)loginKerberos(krb5Principal,krb5KeytabPath,krb5ConfPath)}def loginKerberos(): Boolean = {var principal: String = nullvar keytabPath: String = nullvar krb5ConfPath: String = nullval classPath: URL = this.getClass.getResource("/")val classPathObj = Paths.get(classPath.toURI)var keytabPathList = Files.list(classPathObj).iterator().asScala.toListkeytabPathList = keytabPathList.filter(p => p.toString.toLowerCase().endsWith(".keytab")).toListval krb5ConfPathList = keytabPathList.filter(p => p.toString.toLowerCase().endsWith("krb5.conf")).toListif (keytabPathList.nonEmpty) {val ktPath = keytabPathList.get(0)val absPath = ktPath.toAbsolutePathval keytab = Keytab.loadKeytab(new File(absPath.toString))val pri = keytab.getPrincipals.get(0).getNameif (StringUtils.isNotEmpty(pri)) {principal = prikeytabPath = ktPath.toString}}if (krb5ConfPathList.nonEmpty) {val confPath = krb5ConfPathList.get(0)krb5ConfPath = confPath.toAbsolutePath.toString}if (StringUtils.isNotEmpty(principal) && StringUtils.isNotEmpty(keytabPath) && StringUtils.isNotEmpty(krb5ConfPath)) {ConfigUtils.configHadoop()// ConfigUtils.configHive()val hadoopConf = ConfigUtils.hadoopConfigurationloginKerberos(principal, keytabPath, krb5ConfPath, hadoopConf)} else {false}}
}
2.1.3 编译打包
mvn package 后maven-assembly-plugin会在target/生成出一个zip包。zip包最里层的各种jar就是需要的jar包了,将这些jar包都放到 kettle 的lib目录或自定义的目录(自定义方法请看下文)就好。
注意:
(1)本例中的kettle8.2中的KETTLE_HOME/plugins\pentaho-big-data-plugin\hadoop-configurations 目录下有几个hadoop plugin,在kettle9之前的版本全局只能有一个hadoop,选择使用哪个hadoop需要在文件KETTLE_HOME/plugins\pentaho-big-data-plugin\plugin.properties的active.hadoop.configuration=...配置,就是文件夹的名字,比如此次配置hdp30作为hadoop plugin 基础的hadoop版本,注kettle9以后的版本不是这么配置的,这个hadoop版本越接近实际集群的版本越好,kettle每次此启动都尝试加载此目录下的类,不一样也可以!!!

(2)由于集群版本可能和任何上边的hadoop plugin都不一致,此时需要把集群版本的依赖jar包提前加载,所以需要把相关依赖放在KETTLE_HOME/lib下,如果想放在另设目录比如KETTLE_HOME/ext-lib。win下可以把Spoon.bat中的两处set LIBSPATH=后都追加;..\ext-lib,注意是分号分隔。当然linux下,修改spoon.sh在LIBPATH=$CURRENTDIR最后都追加:..\ext-lib,注意是冒号分隔,之所有要有..是因为项目启动类是KETTLE_HOME/launcher\launcher.jar中。

类和包报错说明:
报错一:
kettle8.2报错很难理解,9之后的版本好得多:如下内容实际Watcher类找不到,但实际是有的。
2024/01/03 17:34:01 - spark-read-ha-sample.0 - Error connecting to database: (using class org.apache.hive.jdbc.HiveDriver)
2024/01/03 17:34:01 - spark-read-ha-sample.0 - org/apache/zookeeper/Watcher
报错二:
出现这种问题的是也是java类加载错误,应该是不同的classloader加载类导致不识别。
loader constraint violation: loader (instance of java/net/URLClassLoader) previously initiated loading for a different type with name "org/apache/curator/RetryPolicy"
报错三:
出现此问题,暂时无法解释。
java.lang.IllegalArgumentException: port out of range:-1at java.net.InetSocketAddress.checkPort(InetSocketAddress.java:143)at java.net.InetSocketAddress.createUnresolved(InetSocketAddress.java:254)at org.apache.zookeeper.client.ConnectStringParser.<init>(ConnectStringParser.java:76)at org.apache.zookeeper.ZooKeeper.<init>(ZooKeeper.java:447)at org.apache.curator.utils.DefaultZookeeperFactory.newZooKeeper(DefaultZookeeperFactory.java:29)at org.apache.curator.framework.imps.CuratorFrameworkImpl$2.newZooKeeper(CuratorFrameworkImpl.java:150)at org.apache.curator.HandleHolder$1.getZooKeeper(HandleHolder.java:94)at org.apache.curator.HandleHolder.getZooKeeper(HandleHolder.java:55)at org.apache.curator.ConnectionState.reset(ConnectionState.java:262)at org.apache.curator.ConnectionState.start(ConnectionState.java:109)at org.apache.curator.CuratorZookeeperClient.start(CuratorZookeeperClient.java:191)at org.apache.curator.framework.imps.CuratorFrameworkImpl.start(CuratorFrameworkImpl.java:259)at org.apache.hive.jdbc.ZooKeeperHiveClientHelper.configureConnParams(ZooKeeperHiveClientHelper.java:63)at org.apache.hive.jdbc.Utils.configureConnParams(Utils.java:520)at org.apache.hive.jdbc.Utils.parseURL(Utils.java:440)at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:134)at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107)
以上三个问题的解决方法是:
将hadoop,hive,zookeeper 和 curator包都放在lib目录或自定义加载目录!!!虽然KETTLE_HOME\plugins\pentaho-big-data-plugin\hadoop-configurations 目录下选定的hadoop plugin (本例中是hdp30)也有相关依赖,但实际上lib目录和hadoop plugin类不能混用,相关的包必须放在一起,切记,血泪教训!!!不用管lib目录和hadoop plugin中存在不同版本的jar包!!!
由于kettle设计的比较负责支持很多插件,此问题应该是由于不同进程不同类加载器所加载的类不能通用所致。
2.2 启动kettle和类加载说明
debug模式启动:SpoonDebug.bat
 如果还想看类加载路径可以在
如果还想看类加载路径可以在Spoon.bat中的set OPT= 行尾添加jvm选项 "-verbose:class" 。
如果cmd黑窗口中文乱码可以把SpoonDebug.bat中的 "-Dfile.encoding=UTF-8" 删除即可。
kettle会把所有jar包都缓存,都存储在kettle-home\system\karaf\caches目录下。
日志里打印的所有 bundle数字目录下得jar包都是在缓存目录下。
 如果kettle在运行过程中卡掉了,不反应了,八成是因为操作过程中点击了cmd黑窗口,此时在cmd黑窗口内敲击回车,cmd日志就会继续打印,窗口也会恢复响应。
如果kettle在运行过程中卡掉了,不反应了,八成是因为操作过程中点击了cmd黑窗口,此时在cmd黑窗口内敲击回车,cmd日志就会继续打印,窗口也会恢复响应。
2.3 编写js通过kerberos认证

配置信息就是填写kerberos的配置。
javascript代码完成kerberos认证。

配置信息内填写如下:

javascript代码内容如下:
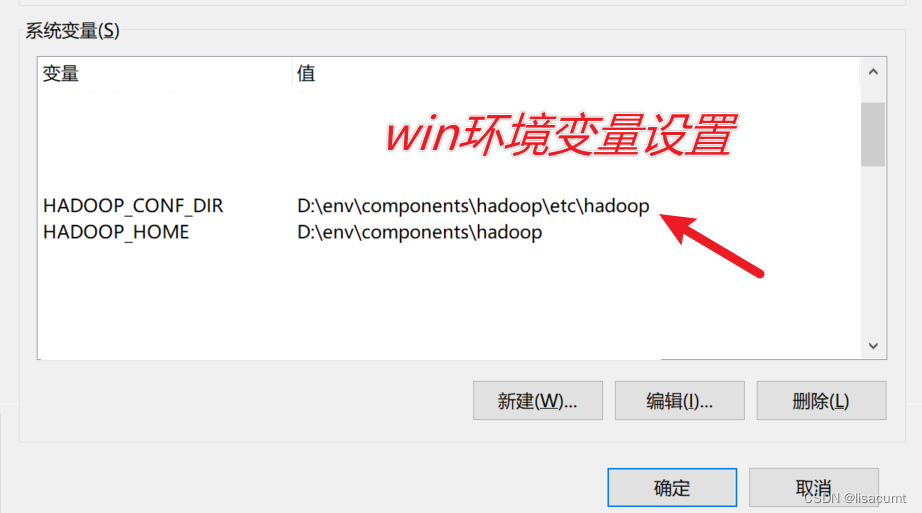
kerberos认证中是需要HADOOP_CONF_DIR的,如果调用没有hadoop_conf_dir参数据方法就是去环境变量中取了。


// 给类起个别名,java没有这种写法,python有。
var utils = Packages.全类路径.KerberosUtils;
// 使用 HADOOP_CONF_DIR 或 HADOOP_HOME 环境变量,配置登录 Kerberos
var loginRes = utils.loginKerberos(krb5_principal,krb5_keytab,krb5_conf);// 使用用户提供的 hadoop_conf_dir 登录kerberos
// hadoop_conf_dir 参数可以从上一步获取,也可以直接写死。
// var loginRes = utils.loginKerberos(krb5_principal,krb5_keytab,krb5_conf,hadoop_conf_dir);
添加一个写结果的模块!

好了,执行启动!

如果报如下错误,说明kettle没有找到java类,检查类路径和包是否错误!
TypeError: Cannot call property loginKerberos in object [JavaPackage utils]. It is not a function, it is "object". (script#6)
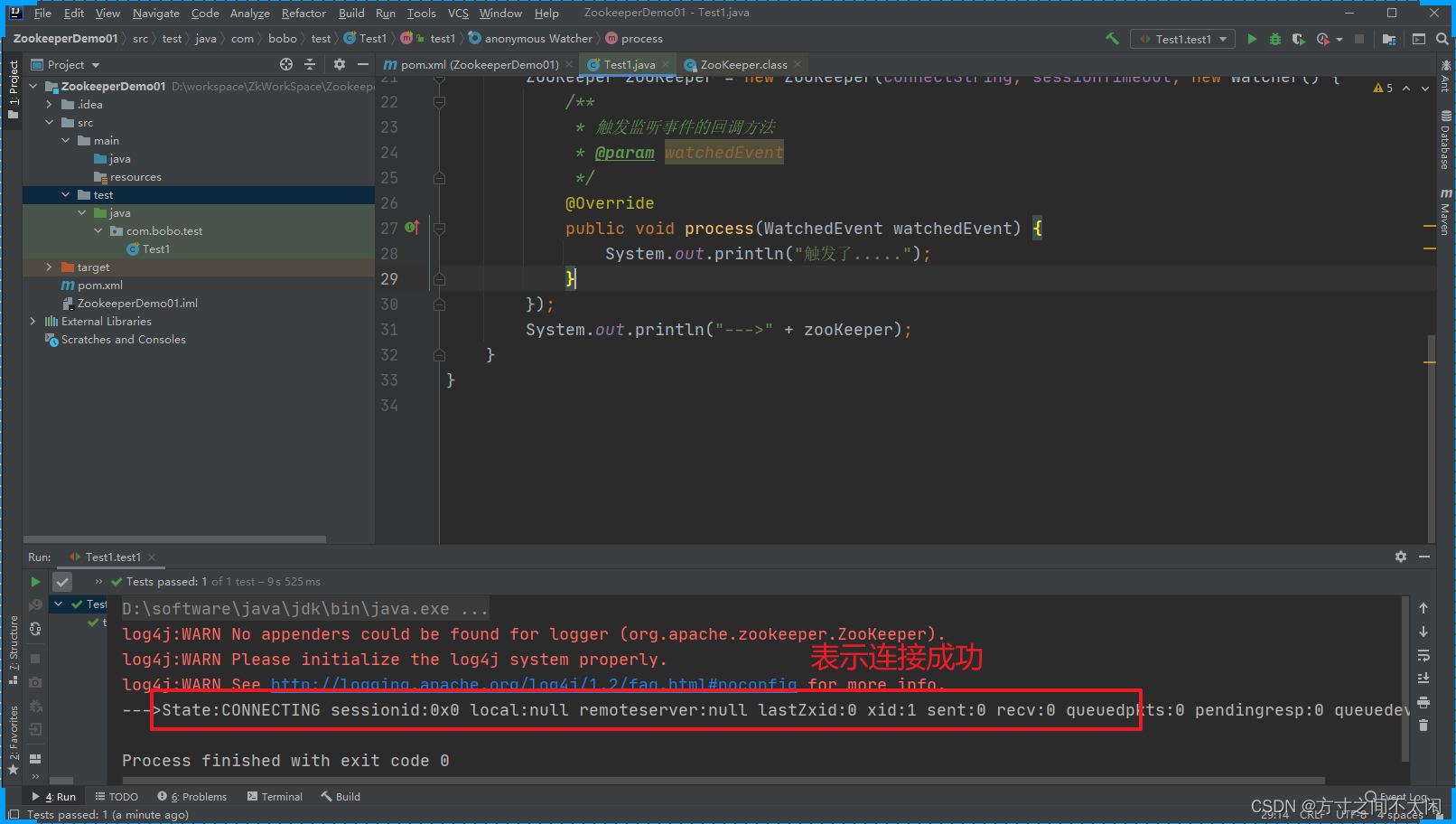
如果打印如下内容,说明执行认证成功了。

2024/01/02 18:18:04 - 写日志.0 -
2024/01/02 18:18:04 - 写日志.0 - ------------> 行号 1------------------------------
2024/01/02 18:18:04 - 写日志.0 - loginRes = Y
三、包装模块开发
keberos认证会在jvm存储信息,这些信息如果想使用必须前于hive或hadoop任务一个job
结构如下:

kerberos-login 就是刚刚写的转换。
必须如上包装,层数少了,认证不过去!!!
四、连接hdfs




如果项目中使用也必须使用前面的包装模块把hadoop任务包在里边!
五、连接hive或者spark thriftserver
连接hive和spark thriftserver是一样的。以下以spark举例说明。

注意连接hive或者spark之前一定先手动运行下刚刚的kerberos-login认证模块!!!,否则测试连接和特征列表都将就失败或报错!!!
4.1 zookeeper的ha方式连接

# 主机名称:
# 注意这里主机名会后少写一个:2181
zk-01.com:2181,zk-02.com:2181,zk-03.com# 数据库名称:
# 后边把kerberos连接参数也加上。zooKeeperNamespace 参数从HIVE_HOME/conf/hive-site.xml或SPARK_HOME/conf/hive-site.xml文件获取即可。而serviceDiscoveryMode=zooKeeper是固定写法。
default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=spark2_server# 端口号:
# 主机名故意少写一个,就在这里补上了。
2181
 先手动运行下kerberos认证模块,再测试连接下:
先手动运行下kerberos认证模块,再测试连接下:
填写完毕后,可以点击特征列表按钮,找到URL项查看格式,应为
jdbc:hive2://zk-01.com:2181,zk-01.com:2181,zk-01.com:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=...
 测试连接:
测试连接:

4.2 单点连接方式


# 主机名称
# 就是hive server2 的主机 host,不要写IP# 数据库名称:
# HIVE_HOME/conf/hive-site.xml或SPARK_HOME/conf/hive-site.xml中找到配置 hive.server2.authentication.kerberos.principal
# 比如spark/_HOST@XXXXX.COM
# 本质也是在default数据库后边拼接连接字符串
default;principal=spark/_HOST@XXXXX.COM# 端口号也在SPARK_HOME/conf/hive-site.xml中找到配置hive.server2.thrift.port有
10016
填写完毕后,可以点击特征列表按钮,找到URL项查看格式,应为:jdbc:hive2://host:port/default;principal=... 格式。

测试连接:

五、其他
kettle读取Hive表不支持bigint和timstamp类型解决
六 kettle使用技巧
6.1 kettle 任务嵌套使用相对目录
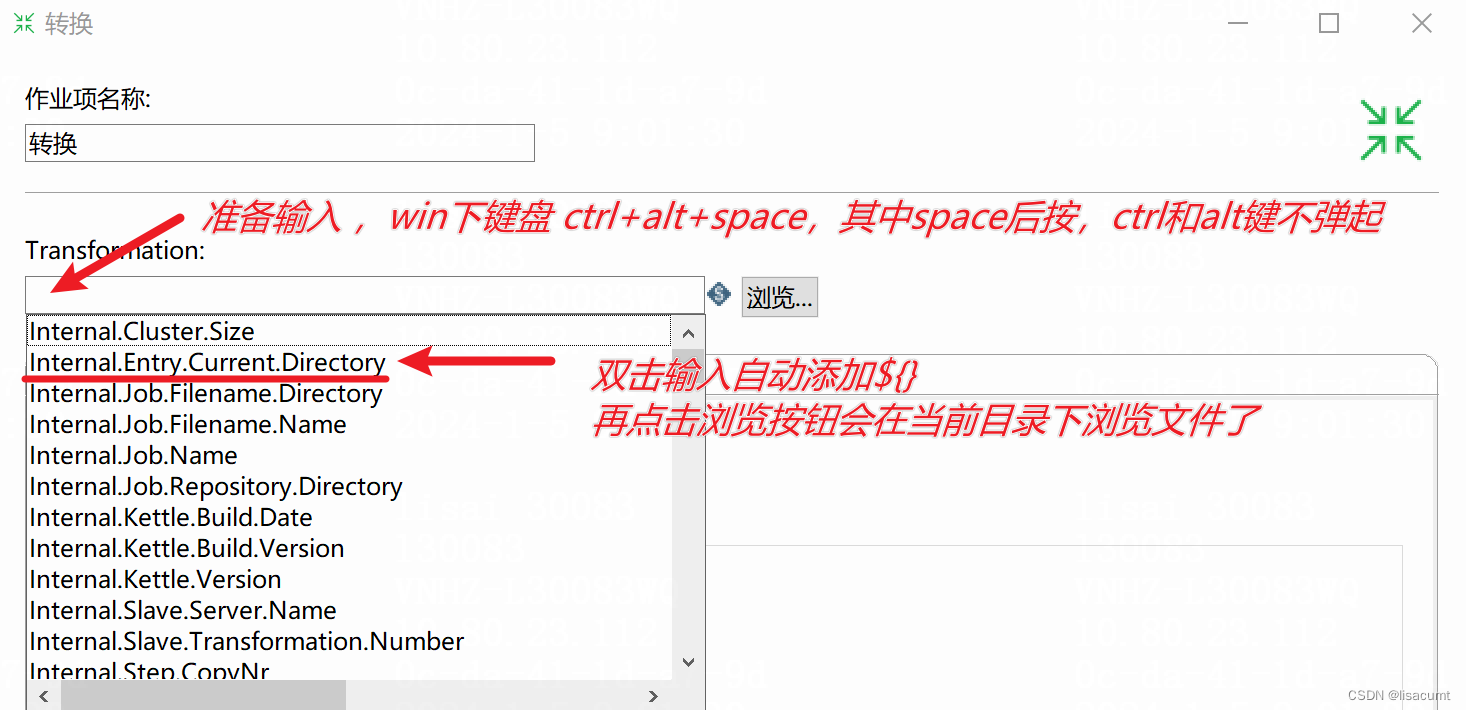
以上内容殊荣输入也是可以的:${Internal.Entry.Current.Directory} 。
参考文章:
hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现
kettle开发篇-JavaScript脚本-Day31
kettle组件javaScript脚本案例1
kettle配置javascript环境 kettle javascript
Javascript脚本组件
Kettle之【执行SQL脚本】控件用法 文章介绍了环境变量和 占位符 ? 的使用方法。