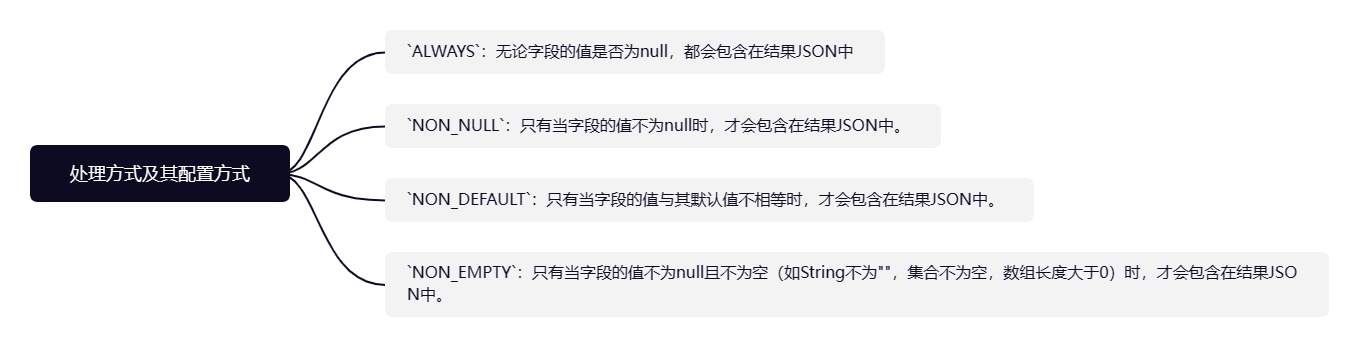
1描述
AdaBoost算法每次都是使用全部的样本进行训练,每一轮训练结束后,得到一个基学习器,并计算该基学习器在训练样本的预测误差率,然后根据这个误差率来更新下一轮训练时训练集合样本的权重系数和本轮基学习器的投票权重,目标是使得本轮被错误预测的样本在下一轮训练中得到更大的权重,使其得到更多的重视,并且预测越准确的基学习器在最后集成时占的投票权重系数更大,使其受到更多的重视,并且预测越准确的基学习器在最后集成时占的投票权重系数越大。这样,通过多轮迭代可以得到多个基学习器及其对应的投票权重,最后按照各自的权重进行投票来输出最终预测结果。
2.AdaBoost的工作过程
AdaBoost运行过程有四个需要解决的问题
(1).计算每一个训练集样本的权重
(2).训练基模型
(3).计算基学习器的投票权重
(4).计算各个基学习器的投票权重
第一个问题 计算每一次训练集样本的权重
首先,AdaBoost每一轮都会使用全部样本进行训练,但是每一轮都会改变样本的权重,它的方法是:用本轮得到的基训练器对所有训练样本进行一次预测,得到一个预测误差率;下一轮训练中各个训练样本的情况由该训练样本自身,本轮基学习器对该样本的预测值,本轮基学习器对训练样本的预测值,本轮基学习器对样本的整体预测误差率三者共同决定。
第二个问题 如何训练基模型
基分类器使用的是CART决策树,只要每一轮将原始样本按新的权重系数重新计算出来后,基学习器的训练和普通单模型训练过程是完全一致的。
第三个问题 如何计算基模型的预测误差率
对于分类问题可以使用0-1损失函数;对于回归问题,计算基模型的预测误差率可以使用均方差或者指数损失函数。
第四个问题 如何训练各个基学习器的投票权重
各个基学习器的投票权重ak是根据每一轮的预测误差率得到的,假设通过K轮迭代,得到了各个基学习器的投票权重ak,k=1,2,3,...K,那么对于结果为{-1,1}的二分类问题,最后的投票公式为:
其中,Tk(x)是第k个基学习器的预测结果值。但是实际问题不会是简单的二分类问题。
3.AdaBoost的多分类问题
假设有M个样本{(x1,y1),(x2,y2)......(xm,ym)},样本可以分为L个类别,类别分别为{c1,c2,...cl}
函数代表0-1损失函数
1.SAMME算法
(1).初始化数据的分布权重,采样平等对待的方式,也就是给每个样本的权重设置为wij=1/m
(2).使用带有权重的样本训练第一个基分类器T1(x)
(3).计算基分类器T1(x),在训练集上的分类误差率e1
(4).计算基分类器T1(x)的投票权重a1
(5).第二轮训练更新样本权重
分母是归一化,不影响,唯一有影响的是yi*T1(xi),代表预测和实际的乘积,当预测相同的时候,下一轮w会变小,如果不相同,则下一轮w会变大,代表对这个数据的关注度更高。其实我们可以令yi*Ti(xi) = 1或者-1,当预测与实际一致,则取1,不一致取-1
(6).利用更新后的第二轮样本权重再次训练得到第二个基分类器T2(x),计算分类器误差e2和投票权重a2,重复上面的步骤得到多个分类器和投票权重,最后把分类器组合起来
L={1,3,......k}
代表让分类器带权对样本x进行投票,然后选出得票最多的类别cl作为样本x的最终预测类别。
2.SAMME.R算法
1.同样的,先初始化每个数据的分布权重,采用平等对待的方式,每一个数据的权重设置为1/M
2.利用带权重的的训练数据集,采用单个基本模型进行训练,得到第一个基分类器T1(x)
3.利用基分类器T1(x)计算各训练样本xi属于各类别的的加权概率
4.计算基分类器T1(x)对样本xi在第L个类别上的投票权重
5.然后更新第二轮的训练集权重
6.归一化权重
7.利用更新后的第二轮样本权重再次训练第二个基分类器T2(x),再次计算预测概率和投票权重,重复上面的步骤,然后对基分类器进行组合。
4.AdaBoost回归
AdaBoost的回归问题与分类分类问题的基本过程差不多,只是在计算预测误差率时采用的方式不同,分类问题采用的是0-1损失,回归问题采用的是平方误差或者指数误差。在预测结果的时候,分类问题采用的是按权重投票决定最后的结果,而回归问题是取各基学习器预测结果乘以各自的权重后求和作为结果。
回归问题的处理过程与分类差不多
(1).初始化样本权重,采用平等对待的方式
(2).利用权重对数据进行分类,训练基学习器T1(x)
(3).计算误差e1,这里的误差是计算相对误差,先求最大的误差,然后所有误差除以最大误差,最后根据样本权重求加权误差
(4).计算投票权重
a1 = e1/(1-e1)
(5)按照上面的流程训练第二个分类器
(6).把全部的分类器集成起来
5.scikit-learn关于AdaBoost的用法
以分类为例子
class sklearn.ensemble.AdaBoostClassifier(
estimator=None, #基分类器的设置,新版本以及不是这样了
*,
n_estimators=50, #分类器个数
learning_rate=1.0, #学习率
algorithm='SAMME.R',#算法类型
random_state=None, #随机数种子
base_estimator='deprecated'#基分类器
)
可以获得属性
estimator_:estimator
The base estimator from which the ensemble is grown.
New in version 1.2:
base_estimator_was renamed toestimator_.base_estimator_ :estimator
Estimator used to grow the ensemble.
estimators_:list of classifiers
The collection of fitted sub-estimators.
classes_:ndarray of shape (n_classes,)
The classes labels.
n_classes_:int
The number of classes.
estimator_weights_:ndarray of floats
Weights for each estimator in the boosted ensemble.
分类器权重
estimator_errors_:ndarray of floats
Classification error for each estimator in the boosted ensemble.
分类器误差
feature_importances_:ndarray of shape (n_features,)
The impurity-based feature importances.
特征重要性
n_features_in_:int
Number of features seen during fit.
特征数量
feature_names_in_:ndarray of shape (
n_features_in_,)Names of features seen during fit. Defined only when
Xhas feature names that are all string特征的名称-只有在特征有被定义名字的时候用的上
也就是我们可以指定学习率,基分类器数量。
能够查看特征的重要程度。
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
#加载数据
data = load_iris()#分数据
X = data['data']
y = data['target']X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=42)cls = AdaBoostClassifier(n_estimators=10,learning_rate=0.9)cls.fit(X_train, y_train)
y_pred = cls.predict(X_test)
print(confusion_matrix(y_test, y_pred))#查看各个属性
print('特征重要性',cls.feature_importances_)
print('类别',cls.n_classes_)