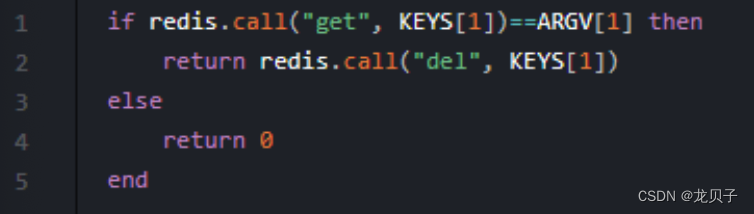
这里写目录标题
- 语法
- 其他
- 语法
- 函数的存储类
- 函数参数默认值
- 格式
- 默认参数位置
- 重载函数的默认参数
- 指针名与正常指针的自增自减以及解引用与++的优先级问题
- 指针的赋值、加减数字、加减指针
- 二维数组中的一些指针辨析+输出调用字符指针时 会将该指针以及之后的元素全部输出
- 二维数组未完全初始化时 某些特殊位置的值
- 取模运算的注意点
- 关于指针的类型的理解
- 三元运算符比 == 运算优先级更低
- 进制表示的前缀和后缀
- for循环中的break和continue
- 默认参数
- new动态规划数组初始化
- 用一个new动态创建一个数组时,后续更新大小
- 关系运算符\赋值符
- 宏定义
- 引用和new
- 总结引用
- 引用做函数参数
- 引用做函数返回值
- 引用和指针
- new二维数组
- 方式1
- 方式1的初始化
- 方式2(推荐)必须指定出列数
- struct与typedef
- 同步与异步
- sleep()
- 时间戳(计时)
- 枚举
- 结构体运算符重载
- 数组当做形参传递到函数里之后 就不可以进行数组元素的计算了
- 常量表达式与变量的区别
语法
其他
2\在函数之外 只能写变量的定义(包括定义时的初始化)以及函数的声明,具体的执行语句只能在函数体之内进行
如下是犯的一个很蠢的错误

1、数组名是个指针 但是 数组名是一个常量指针 不可以进行++操作或者+1等等改变值的操作 但是普通的指针变量可以
语法
函数的存储类
函数的存储类分两种,它们分别是 外部 函数和内部函数,其中 内部 函数的存储类说明不可省略,该说明符是 static 。
根据函数能否被其他源文件调用,分为内部函数和外部函数
外部函数,可以被其他源文件调用的函数
内部函数,只在定义的文件中有效
外部函数:
在一个源文件(A)定义好之后 在另一个源文件(B)调用之前,要在该源文件(B)中声明该函数,声明时加“extern”前缀,之后就可以在该文件(B)中使用之前文件定义好的函数了
定义一个函数 默认是外部函数 可以被其他源文件调用(但是要在其他文件中声明该函数,声明时也可以不加extern)
如下:
第一个源文件
int add(int x,int y)
{
return x+y;
}
第二个源文件
#include <stdio.h>
extern int add(int x,int y);
void main()
{
printf(“sum=%d\n”,add(1,2));
}
如下:
第一个源文件//第一个文件中不用声明命名空间以及iostream,因为该文件只是存个函数,不会进行输入输出
int add(int x,int y)
{
return x+y;
}
第二个源文件
#include <iostream>
using namespace std;extern int add(int x,int y);//extern可以省略
void main()
{
printf("sum=%d\n",add(1,2));
}
静态函数:
对于静态函数,在函数定义语句之前加上“static” 就变成了内部函数
该函数只在当前源文件有效,其他源文件无法感知到,并且由于是静态类,他的作用域是从他定义语句开始往下有效,直到当前的源文件末尾,他的寿命是等待程序结束,他才会消失
外部函数,只要声明一个函数原型,就可以调用其他源文件中的函数,但是,当多人开发时,可能出现函数重名的情况,不同源文件中的同名函数会相互干扰
此时,就需要一些特殊函数,只在定义的文件中有效,这类函数称为内部函数
代码示例:
第一个文件
#include <iostream>
using namespace std;
void show()
{
printf("%s \n","first.c");
}
第二个文件
#include <iostream>
using namespace std;
static void show()
{
printf("%s \n","second.c");
}
void main()
{
show();
}
输出结果:second.c
第二个文件中的静态函数独立于该文件,并且与其他文件不会冲突,允许该静态函数与其他函数重名,不会起冲突
函数参数默认值
格式
即设置形参时设置默认值 ,如int add(int a,int b=1)
上面的a就是默认参数
注意:
当函数有声明时,默认值的设置要放在声明中,函数定义时就不用设置了
同时 设置默认值时 可以用常量,也可以用含义变量的表达式,如:int fun(int x , int y=a+b);(其中,a和b是已定义过具有有效值的变量)
默认参数位置
!如果一个函数中有默认参数 ,那么默认参数都在最右侧,或者说,默认参数的右边都是默认参数,不能出现没有默认值的参数
原因:如果默认参数在中间 ,那么会出现二义性
出现二义性错误的原因是因为在C++中,函数调用时,如果省略某些参数,则编译器会按照参数的位置进行匹配,但是如果出现参数缺失的情况,编译器无法确定这个参数是应该被赋予默认值还是作为后续的参数传递,从而导致二义性错误。
举个例子,假设有如下函数定义:
void foo(int a, int b = 1, int c = 2);
当调用该函数时,可以使用以下两种方法:
foo(10, 20); // a=10, b=20, c=2
foo(10); // a=10, b=1, c=2
在第二种调用方式中,省略了参数 b 和 c,此时编译器会自动使用参数的默认值,即 b=1 和 c=2。
然而,如果出现以下调用方式:
foo(10, , 30); // 编译错误:二义性
这里省略了参数 b,并且给参数 c 赋值了 30,但是对于缺失的参数 b,编译器无法确定它应该被赋予默认值还是作为后续的参数传递,从而导致了二义性错误。
重载函数的默认参数
对重载函数设置默认参数值,对重载函数的选择会有影响

如上图所示:
当重载函数add 其中一个有默认参数 一个没有
但是如果除去默认参数 两个重载的参数列表相同,那么就会出现二义性
这时,就算你传入一个参数,他既可以调用第一个add 也可以调用第二个add 就出现了二义性
所以要尽量避免这种重载

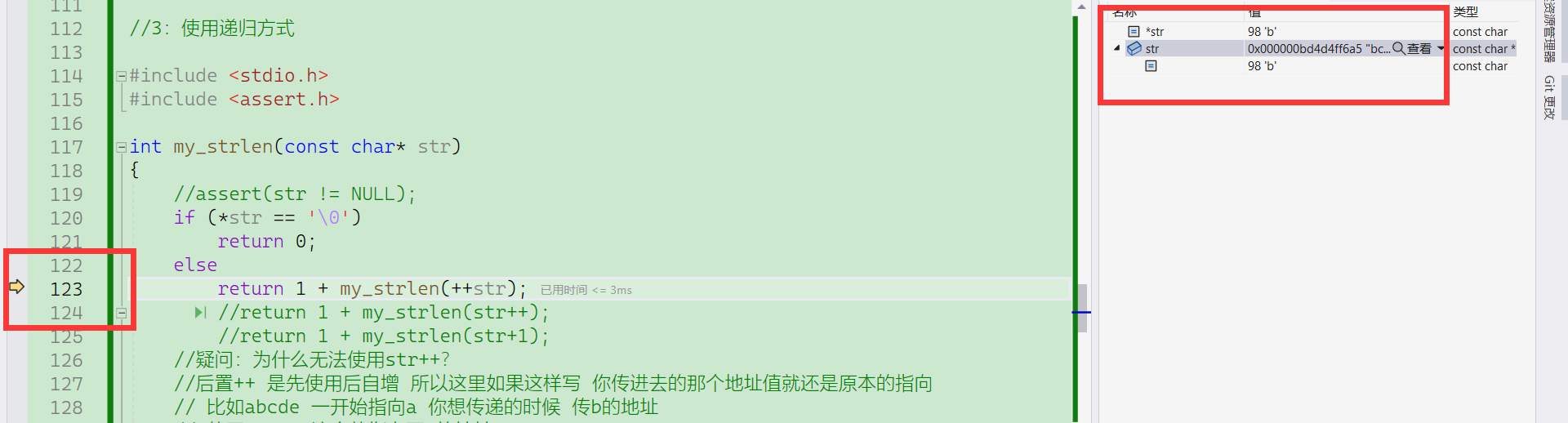
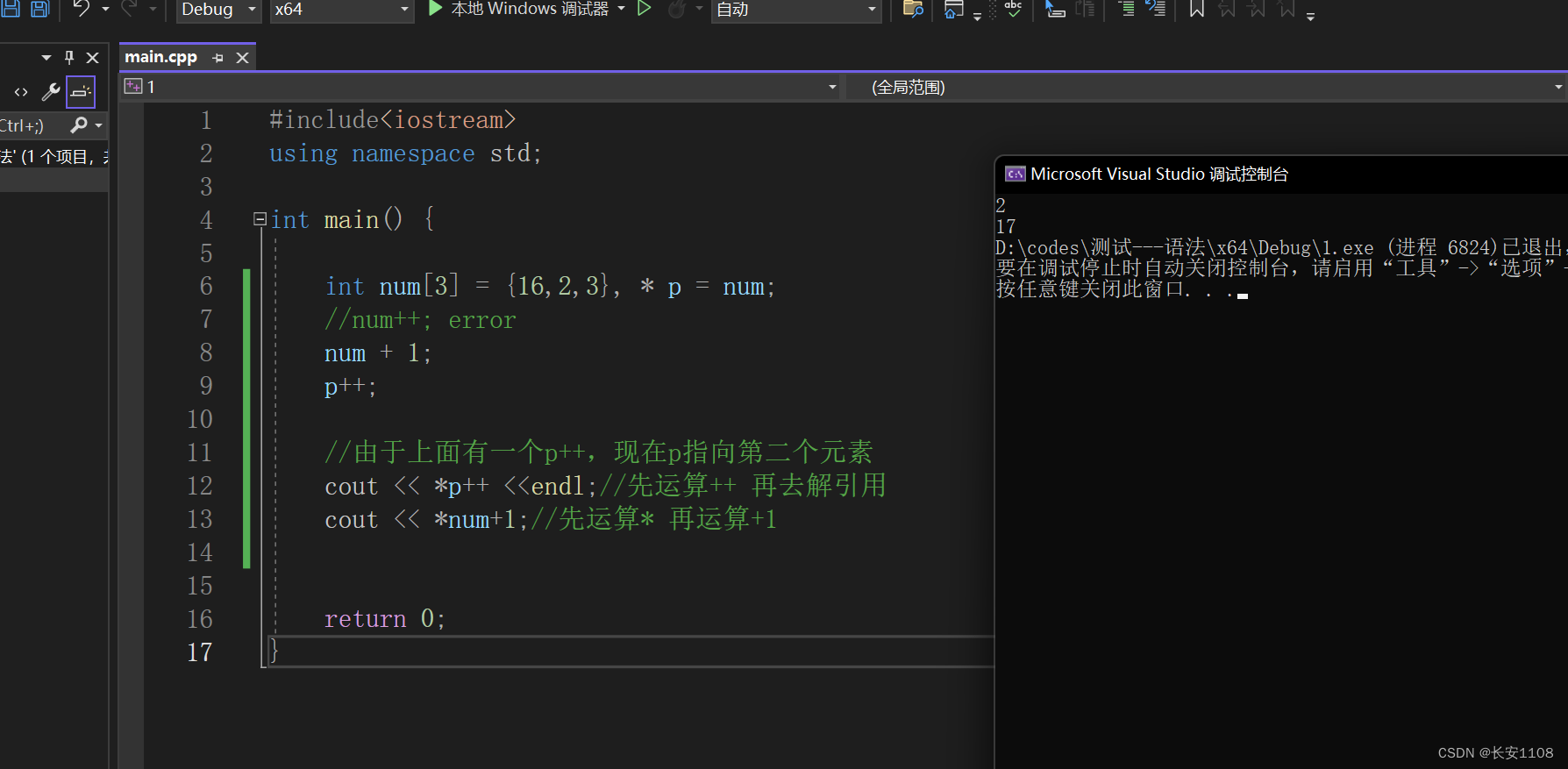
指针名与正常指针的自增自减以及解引用与++的优先级问题
数组名是数组的指针 同时也是数组首元素的指针 他是一个指针常量
对于自增自减
数组名不可以使用 因为他是常量 但是可以+1或者-1是允许的
将数组名赋值给一个指针变量后 该指针属于普通指针 可以自增自减 也可以+1-1
对于解引用与自增自减的优先级问题
p++ 是先++后解引用 但是由于是p++,所以p++整体的值仍然是p加之前的值
对于p+1 是先解引用后+1(*num+1也一样)
指针的赋值、加减数字、加减指针
指针的赋值:给指针赋值时一定要类型相同,级别一致
一个指针加减一个数字 表示该指针移动几位
一个指针不能加指针
一个指针减一个指针 表示两个指针之间有几个元素
指针可以比较
在指向同一个数组中两个元素的两个指针可以比较 结果是指针的位置前后
同一个位置:==
不同位置:> <
指向同一个对象的指针也可以比较 结果是相等
二维数组中的一些指针辨析+输出调用字符指针时 会将该指针以及之后的元素全部输出

一个字符串占一行
第一维大小指的是列数
以下以int a[3][3]为例
1、在二维数组中 a[3]只有一个中括号 代表第一个中括号 这是一个指针 指向第四行的指针,在此基础上加1 是指针在第四行向右移一位(这是一级指针)
2、而图中c选项:数组名+3 表示的是第四行的首元素的指针(例如 a+3) 对其加3是 指针向下一行移动 (但是是二级指针)
3、二维数组的数组名实际上是第一行数组的地址的指针 (二级指针),于是有如下关系:
*数组名 等价于 数组名[0] (&数组名[0])等价于数组名
*a a[0] &a[0] a
当有两个中括号时 才是数组名正常中括号取元素
二维数组未完全初始化时 某些特殊位置的值


会严格按照初始化的位置进行初始化 严格按照该在的位置进行操作 不会平铺
取模运算的注意点
1.不要对浮点数使用该运算符,那将是无效的。
2.如果第一个操作数为负数,那么得到的模也为负数;如果第一个操作数为正数,那么得到的模也为正数。
3.取模公式:a % b == a - (a/b) * b
关于指针的类型的理解
指针也是一个系统内置数据类型 将其视为一种数据类型即可
任何一个指针变量 都是用来存地址的 具体存的数据类型的指针被分为了不同类型的指针
不同类型的指针负责存不同类型数据的地址信息
包括 指向整型一维数组的指针与指向整型变量的指针 是不一样的
一个是int型指针 一级指针
一个是数组指针 二级指针
三元运算符比 == 运算优先级更低

例如:a==b ? c:d;
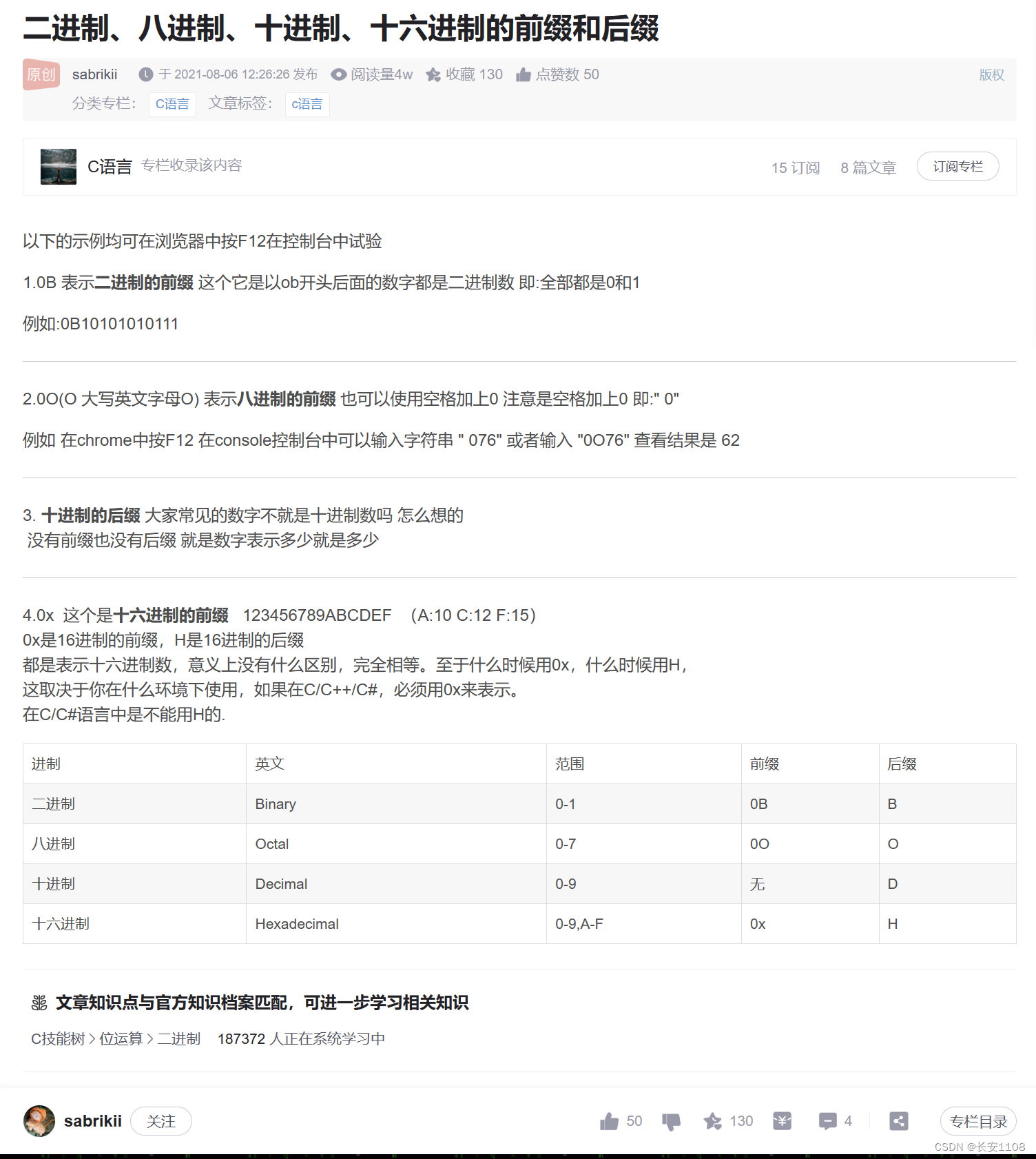
进制表示的前缀和后缀
for循环中的break和continue
在for循环中一旦break被触发后 那么就会跳出当前for循环

在for循环中一旦触发continue 那么还是会在for循环中 会继续下一个i++ 而不会跳出for循环

默认参数

函数参数列表规定了某个参数的值的话 在函数调用时 可以不传这个位置的参数 该参数有一个默认值
new动态规划数组初始化

直接在后面进行大括号初始化即可
用一个new动态创建一个数组时,后续更新大小
这种定义方式可根据变量 n 动态申请内存,不会出现存储空间浪费的问题。但是,如果程序执行过程中出现空间不足的情况时,则需要加大存储空间,此时需要进行如下操作:
1、新申请一个较大的内存空间,即执行int * temp = new int[m];
2、将原内存空间的数据全部复制到新申请的内存空间中,即执行memecpy(temp, p, sizeof(int)*n);
3、将原来的堆空间释放,即执行delete [] p; p = temp;
关系运算符\赋值符
== 与 =
如果想在一个循环里选出一些特别的值 那么
不可以单纯加一个if(){}
还要加else
不然运行完if后 还会去运行if下面的语句
宏定义

宏定义最后端不可以加分号
引用和new


在重构赋值运算符时 重构函数体内要进行两个对象属性值的赋值 (将b对象的属性值赋值给a对象)
对于第一行 是默认调用编译器提供的浅拷贝 注意第一张图 Person类的age是指针类型变量 所以p.age是指针变量,而this->age也是指针类型变量 所以编译通过,指针赋值指针;
对于第二行 我们进行深拷贝 也就是将要赋值的值在堆区开辟空间 并把数据放进去,用到new
new的语法: new 数据类型(初始值)
所以括号里应该传入一个实体值 而p.age 是类Person的属性值 通过类的定义可以看到 p.age是一个指针 所以不能直接传入 而是应该解引用 从而是一个实体值;
注意 参数是Person &p 这里将p视为一个变量 一个Person类型的变量 也就是类的对象 p是实参对象的别名 并不是地址 只不过p和实参对象共用一块地址
返回值是Person& 那么return的数据(return的值会替代函数名 也就是函数调用时 函数名最终就是return后面的数据) 必须是Person的实体变量 /因为引用类型的变量定义是 数据类型& 别名=变量名/ 因为函数类型(也就是返回值类型)是引用类型 而引用类型本身就是一个实体变量 是一个实体变量的别名 可以当做实体变量来看待 这里将引用作为返回值 是想返回该实体变量 从而该函数就会返回一个实体变量 从而后续可以将函数调用这个句子当做变量来用 可以实现链式编程
当形参是引用类型 实参可以传入实体变量 也可以传入一个地址 都可以
引用类型 实际上是实体类型 而不是指针类型 例如 int&a=b;
a的数据类型与b一致
总结引用
引用做函数参数
1、引用做函数参数 实际上就是变量的别名 传入一个实参 而形参是引用类型 那么在函数体内外 就建立了实时联系
2、因为引用类型与外面的实参有实时联系 所以在数据结构里 常常认为引用类型的功能也有返回的作用
引用做函数返回值
1、首先要注意 引用做函数返回值时 return 必须返回一个实体变量 (无论基本数据类型的变量 还是自定义类型变量) 因为函数类型就是引用 而引用类型实际上就是实体变量类型
2、引用做函数返回值 主要的功能或者想要实现的是 函数调用后 直接返回一个实体变量 而不是值 这样可以对函数进行一些操作 例如++,–。例如 int & test()++;或者直接用一个变量接住也可以 例如 int b = int &test();
3、注意 一旦引用做函数返回值 那么return的变量必须是一个长寿命变量 也就是外部的(在堆区创建)或者静态的
或者实现链式编程 因为链式编程就是对象不停的调用 并返回对象 供下一次调用
引用和指针
引用可以引指针
例如
int *p;//p是一个指针
int *& rp= p;//rp是指针p的一个引用 也是他的一个别名 rp实质上也是一个指针
int a=10;
rp=&a;//rp可以正常拿到int数据类型的地址
这时 p和rp是一个作用 且值都是10;
new二维数组
方式1

!! 记得释放之后 把指针指向NULL
定义一个指针类型为基本元素的数组,再对每个元素分别都new一个数组并且用数组的元素名接住
注意 最后析构的时候 也要把每个数组名的数组都析构掉 并且析构掉大数组
(可以参照new一维数组的方法来对照着记二维数组)
new后面是每个元素的数据类型 当数据类型加了一个星星的时候 每个元素的数据类型就变成了指针 这样就可以对每个元素再次进行new了
当看到后面加了星星 前面补一个*就可以
方式1的初始化

直接在对行进行new的时候 最后加上一个中括号 可以啥也不写 或者填个0 就可以把数组整个初始化为0
方式2(推荐)必须指定出列数

一个指针数组 来new出来一个二维数组
new出来之后 就可以直接使用
补充:数组指针 也就是指向数组的指针
数组指针就是定义一个指针 他指向一个数组
格式: 数据类型 + (*指针名) 【所指向的数组的元素个数】
例如 int (*p) 【3】
意为一个指针p 指向一个具有三个元素的数组 同时p也被称为二级指针
通常使用数组指针来指向二维数组的某一行,于是可以用该指针来表示二维数组
代码示例:
int a[2][3] ={4,5,6,7,8,9};
int (*p)[3]=a;for(int i=0;i<2;i++){for(int j=0;j<3;j++){cout<<"p[i][j]"<<endl;}
}
p指向二维数组的首元素 那么就可以用p来表示二维数组了
也可以理解为p指向了二维数组的第一行 但是指针可以递增 所以p可以++ 意为移到第二行 依次类推 p可以指向二维数组的任意一个元素
struct与typedef

struct是结构体类型
typedef是给类型起别名
对于第一个:数据类型是struct{int val;} 这整个(包括花括号里的内容一起)是一个数据类型的声明(也称为匿名结构体),后面跟了A,那么A就是该结构体类型的变量
对于第二个:结构体类型声明有了名称:A 而B是A结构体的变量
第三个:struct{int val;} 这整个(包括花括号里的内容一起)是一个数据类型的声明(也称为匿名结构体),
先是一个匿名结构体 之后用typedef给匿名结构体起别名 所以 A就是匿名结构体的别名 A这次不再是变量 而是结构体的名称 是数据类型的声明
第四个:对结构体C 起别名
第一个别名是A:所以A也是结构体类型的声明 而不是结构体变量
第二个别名是B 这里的B等价于C 但是可以利用B进行指针的操作
因为C是结构体类型 所以 等价于 C 星 变量
星B 变量
!B是指向结构体的指针!
同步与异步

sleep()

时间戳(计时)

clock_t是一种类型 它定义的变量可以存储时间瞬时值
clock()是一个函数 可以返回当前的时间戳 也就是当前时间距离1970年1月1日0.0.0的时间差
这两个配合 可以进行计时操作

补充:可以进行游戏帧率的设置

枚举

结构体运算符重载


一共四种方法 第一种方法演示:

数组当做形参传递到函数里之后 就不可以进行数组元素的计算了

sizeof(nums)/sizeof(nums【0】) 可以算出数组的元素个数
但是仅限于在定义数组的函数内才可以
如果将数组作为形参 传递到函数里 那么就不可以用这种方法 因为一旦当做形参传递数组 数组就变成了指针 就不会传入整个数组的大小 所以不可以在函数里求函数外的数组的元素个数 只能在函数外求出 然后当做形参传递进去
常量表达式与变量的区别
顾名思义