并行程序的执行速度可能因计算硬件的资源限制而有很大差异。虽然管理并行代码和硬件资源约束之间的交互对于在几乎所有并行编程模型中实现高性能很重要,但这是一种实用技能,最好通过为高性能设计的并行编程模型中的实践练习来学习。在本章中,**我们将讨论CUDA设备中的主要资源约束类型,**以及它们如何影响内核执行性能[Ryoo 2008JICUDA C最佳实践]。为了实现他/她的goals,程序员通常必须找到达到高于应用程序初始版本所需性能水平的方法。在不同的应用中,不同的约束可能会占主导地位,并成为限制因素,通常称为瓶颈。**人们通常可以通过将一个资源使用情况交易给另一个资源来显著提高应用程序在特定CUDA设备上的性能。**如果这样缓解的资源约束实际上是应用战略之前的主要约束,并且因此加剧的约束不会对并行执行产生负面影响,那么这种策略就很有效。如果没有这种理解,性能调整将是工作;似是而非的策略可能会也可能不会导致性能提升。除了对这些资源限制的洞察力外,**本章还提供了原则和案例研究,旨在培养对可能导致高性能执行的算法模式类型的直觉。**它还建立了成语和想法,这些成语和想法可能会在您的性能调整过程中带来良好的性能改进。
5.1 GLOBAL MEMORY BANDWIDTH
CUDA内核性能的最重要因素之一是访问全局内存中的数据。CUDA应用程序利用了海量数据并行性。当然,CUDA应用程序倾向于在短时间内处理来自全局内存的大量数据。在第4章“内存和数据局部性”中,我们研究了利用共享内存来减少每个线程块中的线程集合必须从全局内存访问的数据总量的 tile 技术。在本章中,我们将进一步讨论内存合并技术,这些技术可以更有效地将数据从全局内存移动到共享内存和寄存器中。内存合并技术通常与分层技术结合使用,以允许CUDA设备通过更有效地利用全局内存带宽来发挥其性能潜力。
“最近的CUDA设备使用片上缓存来存储全局内存数据。此类缓存会自动合并更多内核访问模式,并在一定程度上减少了程序员手动重新排列其访问模式的需要。然而,即使有缓存,在可预见的未来,合并技术将继续对内核执行性能产生重大影响。
CUDA设备的全局存储器是用DRAM实现的。数据位存储在小电容器的DRAM单元中,其中存在或没有少量电荷可以区分0和1。从DRAM电池读取数据需要小电容器使用其微小的电荷驱动通往传感器的高电容线,并设置其检测机制,该机制确定电容器中是否存在足够的电荷,以符合“1”(请参阅“为什么DRAM如此缓慢?”侧边栏)。在现代DRAM芯片中,这个过程需要10纳秒。这与现代计算设备的亚纳秒时钟周期时间形成鲜明对比。由于相对于所需的数据访问速度(每字节的亚纳秒访问)来说,这是一个非常缓慢的过程,现代DRAM使用并行来提高其数据访问速率,通常称为内存访问吞吐量。
为什么DRAMS这么慢?
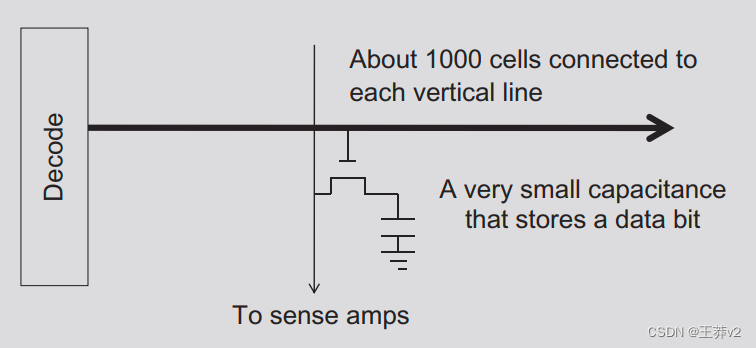
下图显示了DRAM单元格及其访问内容的路径。解码器是一个电子电路,它使用晶体管驱动连接到数千个电池出口门的线路。线路可能需要很长时间才能充满电或放电到所需的水平。
一个更艰巨的挑战是细胞将垂直线驱动到感应放大器,并允许感应放大器检测其内容。这是基于电荷共享。闸门释放出细胞中储存的少量电荷。如果电池含量为“1”,则微小的电荷必须将长位线大电容的电势提高到足够高的水平,从而触发感应放大器的检测机制。一个很好的比喻是,有人在长长的走廊的一端拿着一小杯咖啡,让另一个人闻到走廊上传播的香气,以确定咖啡的味道。
人们可以通过在每个单元中使用更大、更强的电容器来加快这个过程。然而,DRAM一直朝着相反的方向发展。每个电池中的电容器的尺寸都稳步缩小,因此随着时间的推移,其强度会降低,因此每个芯片中可以存储更多的位。这就是为什么DRAM的访问延迟没有随着时间的推移而减少。
每次访问DRAM位置时,都会实际访问一系列连续的位置,包括请求的位置。每个DRAM芯片中都提供了许多传感器,它们并行工作。每个人都在这些连续的位置中感知到一点的内容。一旦被传感器检测到,来自所有这些连续位置的数据可以以非常高的速度传输到处理器。访问和交付的这些连续位置被称为DRAM突发。如果应用程序集中使用这些突发的数据,DRAM可以以比访问真正的随机位置序列更高的速率提供数据。
认识到现代DRAM的突发组织,当前的CUDA设备采用一种技术,允许程序员通过将线程的内存访问组织成有利的模式来实现高全局内存访问效率。这种技术利用了warp中的线程在任何given时间点执行相同的指令这一事实。当warp中的所有线程执行负载指令时,硬件会检测它们是否访问连续的全局内存位置。也就是说,当warp中的所有线程访问连续的global内存位置时,可以实现最有利的访问模式。在这种情况下,硬件将所有这些访问合并或合并为对连续DRAM位置的合并访问。例如,对于warp的给定负载指令,如果线程0访问全局内存位置N,线程1位置N+1,线程2位置N+2等,所有这些访问都将被合并,或者在访问DRAM时合并为连续位置的单个请求。这种合并访问允许DRAM以突发方式交付数据。
不同的CUDA设备也可能对N施加对齐要求。例如,在一些CUDA设备中,N需要对齐到16字的边界。也就是说,N的下6位都应该是0位。由于存在二级缓存,最近的CUDA设备已经放宽了这种对齐要求。
请注意,现代CPU在其缓存内存设计中也能识别DRAM突发组织。CPU缓存行通常映射到一个或多个DRAM突发。在它们触摸的每条缓存行中充分利用字节的应用程序往往比随机访问内存位置的应用程序实现更高的性能。本章介绍的技术可以进行调整,以帮助CPU程序实现高性能。
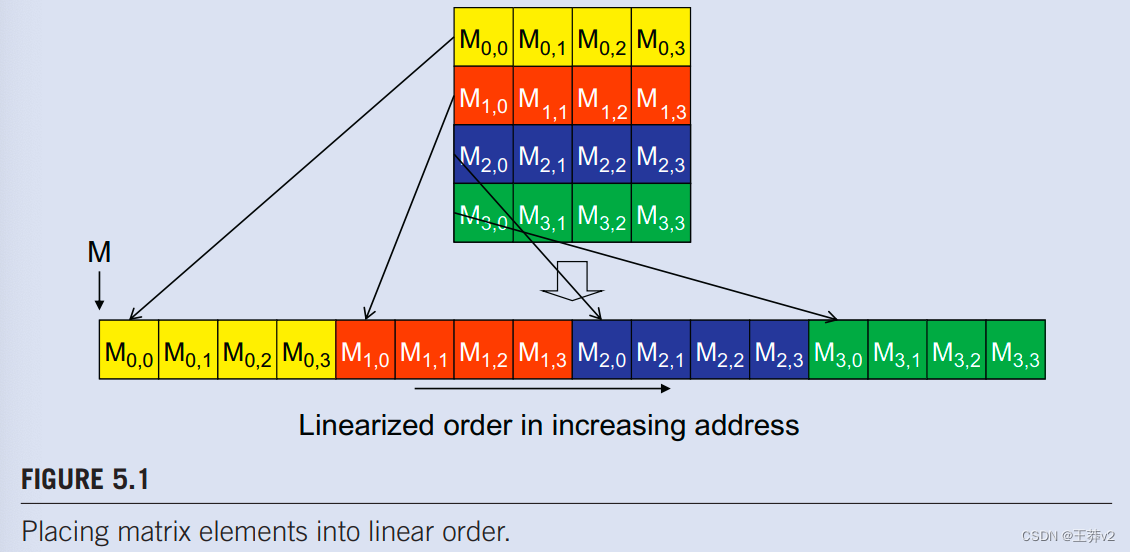
为了了解如何有效使用合并硬件,我们需要回顾在访问C多维数组元素时如何形成内存地址。回顾第3章,可扩展并行执行(图3.3,复制为图5.1为方便起见)C和CUDA中的多维数组元素根据行主要约定放置在线性寻址内存空间中。术语行大调是指数据放置保留了行结构的事实:一行中的所有相邻元素都被放置在地址空间中的连续位置。在图中5.1,0行的四个元素首先按其在行中的外观顺序放置。然后放置第1行中的元素,然后是第2行的元素,然后是第3行的元素。应该清楚的是,M0.0和M1.0.虽然在二维矩阵中似乎是连续的,但在线性寻址内存中放置了四个位置。
图5.2说明了用于内存合并的有利与不利的CUDA内核2D行主要数组数据访问模式。从图4.7中召回。 在我们的简单矩阵乘法内核中,每个线程访问M数组的一行和N数组的一列。读者在继续之前应查看第4.3节。图5.2(A)说明了M数组的数据访问模式,其中warp中的线程读取相邻的行。也就是说,在迭代0期间,线程在0到第31行的warp读取元素0中。在迭代1期间,这些相同的线程读取0到31行的元素1。任何访问都不会合并。更有利的访问模式如图5.2(B)所示,其中每个线程读取N的一列。在迭代0期间,warp 0中的线程读取0到31列的元素1。所有这些通道都将合并。
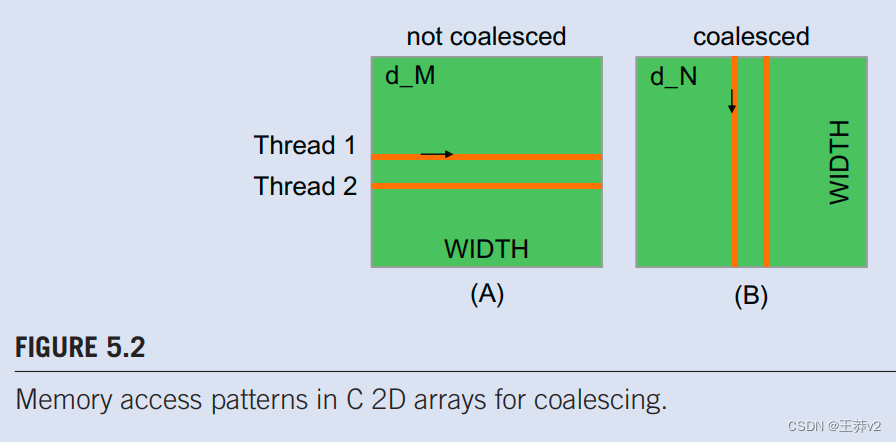
为了理解为什么图5.2(B)中的模式比图5.2(A)中更有利,我们需要更详细地审查如何访问这些矩阵元素。图5.3显示了访问4×4矩阵的有利访问模式的一个小例子。图5.3顶部的箭头。显示内核代码的访问模式。这种访问模式是由图4.3中对N的访问生成的。
N[k*Width + Col]
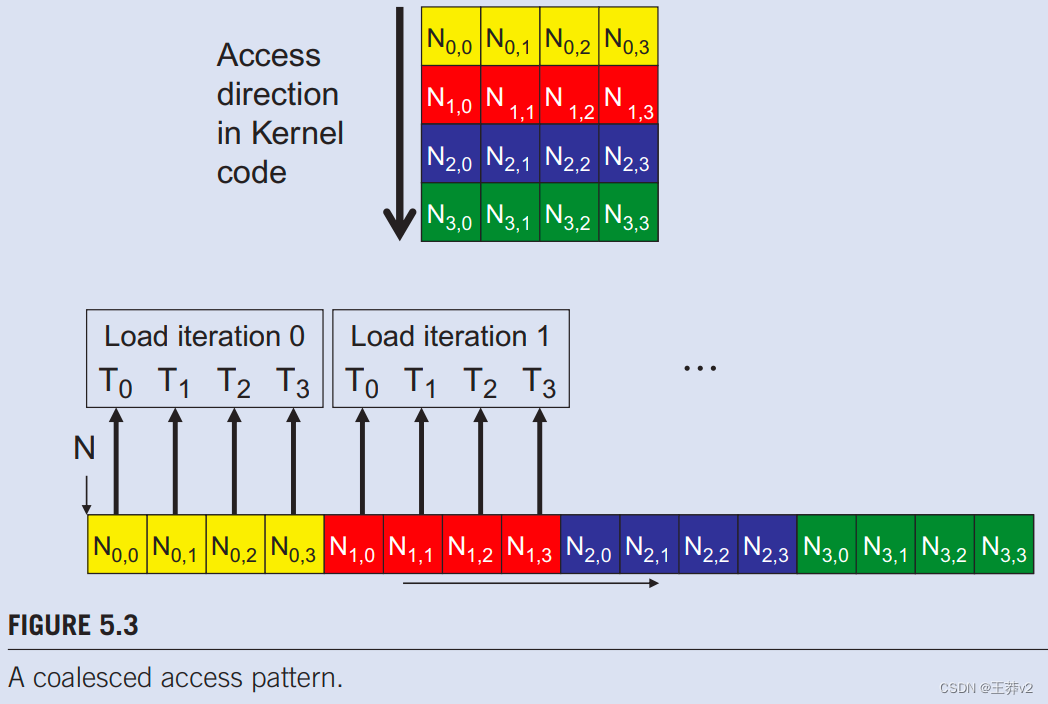
在k循环的给定迭代中,所有线程的kWidth值都是相同的。召回Col=blockIdx.xblockDim.x+threadIdx.x。由于blockIndx.x和 blockDim.x 的值对同一块中的所有线程都具有相同的值,因此k*width+Col中唯一在线程块之间变化的部分是threadldx.x。由于相邻线程具有连续的threadldx.x值,因此其访问的元素将具有连续的地址。例如,在图5.3中,假设我们使用的是4x4块,并且warp大小为4。也就是说,对于这个玩具示例,我们只使用1个块来计算整个P矩阵。Width,blockDim.x,blockIdx.x为4、4, 和0的值, 对于块中的所有线程。在迭代0中,k值为0,每个线程用于访问 N 的索引

也就是说,在这个线程块中,访问N的索引只是threadldx.x的值。T0、T1、T2、T3访问的N元素是NLO]、N[1]、N[2]和N[3]。图5.3的“加载迭代0”框说明了这一点。.这些元素位于全局内存中的连续位置。硬件检测到这些访问是由warp中的线程和全局内存中的连续位置进行的。它将这些访问合并成一个合并的访问。这允许DRAM以高速率提供数据。
在下一次迭代中,k值为1。每个线程用于访问N的索引为:

T0、T1、T2、T3在此迭代中访问的N个元素是N[5]、N[6]、N[7]和N[8],如图5.3.中的“加载迭代1”框所示。所有这些访问再次合并成一个统一的访问,以提高DRAM带宽利用率。
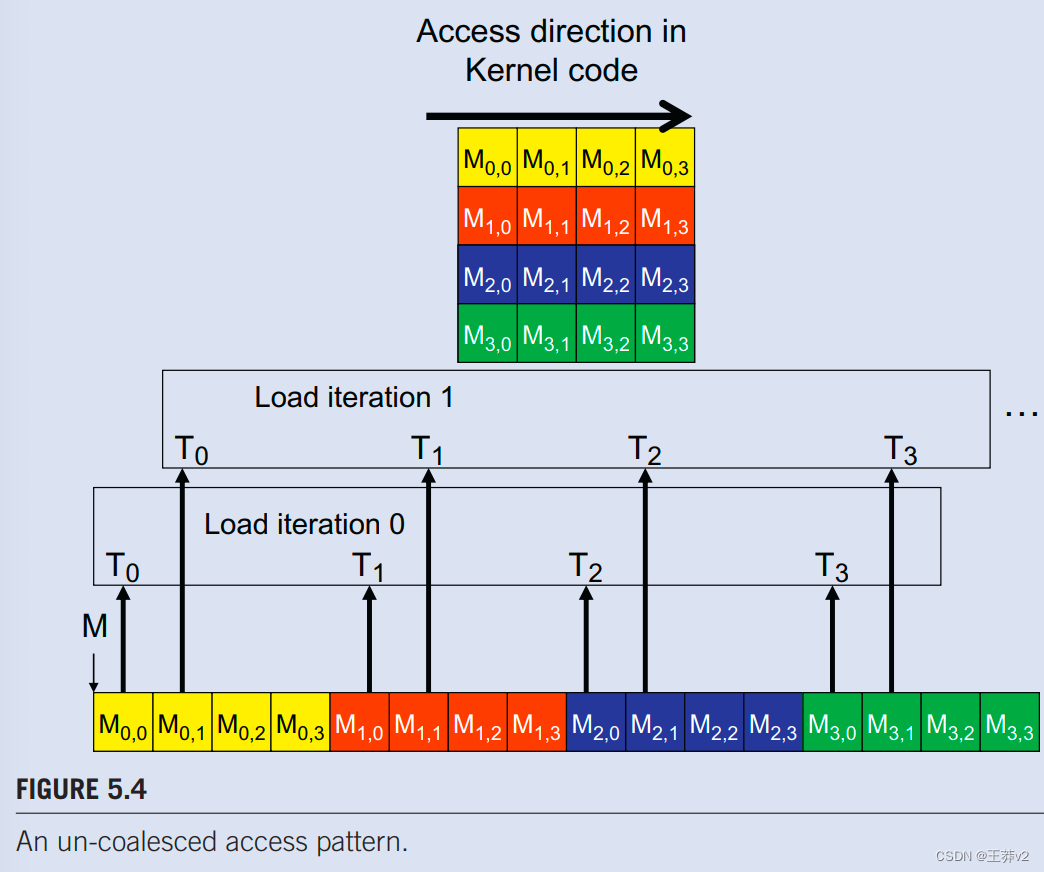
图5.4显示了未合并的矩阵数据访问模式示例。图顶部的箭头显示,每个线程的内核代码按顺序访问行的元素。图5.4顶部的箭头显示了一个线程的内核代码的访问模式。此访问模式由图4.3中对M的访问生成。
M[Row*Width+k]
在k循环的给定迭代中,所有线程的kwidth值都是相同的。从图4.3中召回。该Row=blockIdx.yblockDim.y+threadIdx.y。由于 blockIndx.y 和 blockDim.y 的值对同一块中的所有线程具有相同的值,因此 RowWidth+k 中唯一可以在线程块之间变化的部分是threadldx.y。在图5.4中,我们再次假设我们正在使用4×4块,并且 warp 大小为4。块中所有线程的 Width, blockDim.y, blockIdx.y 的值为4、4和0。在迭代 0 中,k值为 0。每个线程用于访问M的索引为:

也就是说,访问M的索引只是threadldx.x4的值。T0、T1、T2、T3访问的M元素是M[0]、M[4]、M[8]和M[12]。图5.4.中的“负载迭代0”框说明了这一点。这些元素不在全局内存中的连续位置。硬件不能将这些访问合并到合并访问中。
在下一次迭代中,k值为1。每个线程用于访问M的索引为:

T0、T1、T2、T3访问的M元素是M[1]、M[5]、M[9]和M[13],如图5.4.中的“加载迭代1”框所示。同样,这些访问不能合并为合并访问。
对于一个现实的矩阵,每个维度中通常有数百甚至数千个元素。相邻线程在每次迭代中访问的M元素可以相隔数百个甚至数千个元素。底部的“加载迭代0”框显示了线程如何访问 0 th迭代中的这些非连续位置。硬件将确定对这些元素的访问彼此相距甚远,不能合并。因此,当内核循环通过一行遍默时,对全局内存的访问效率比内核通过一列的情况要低得多。
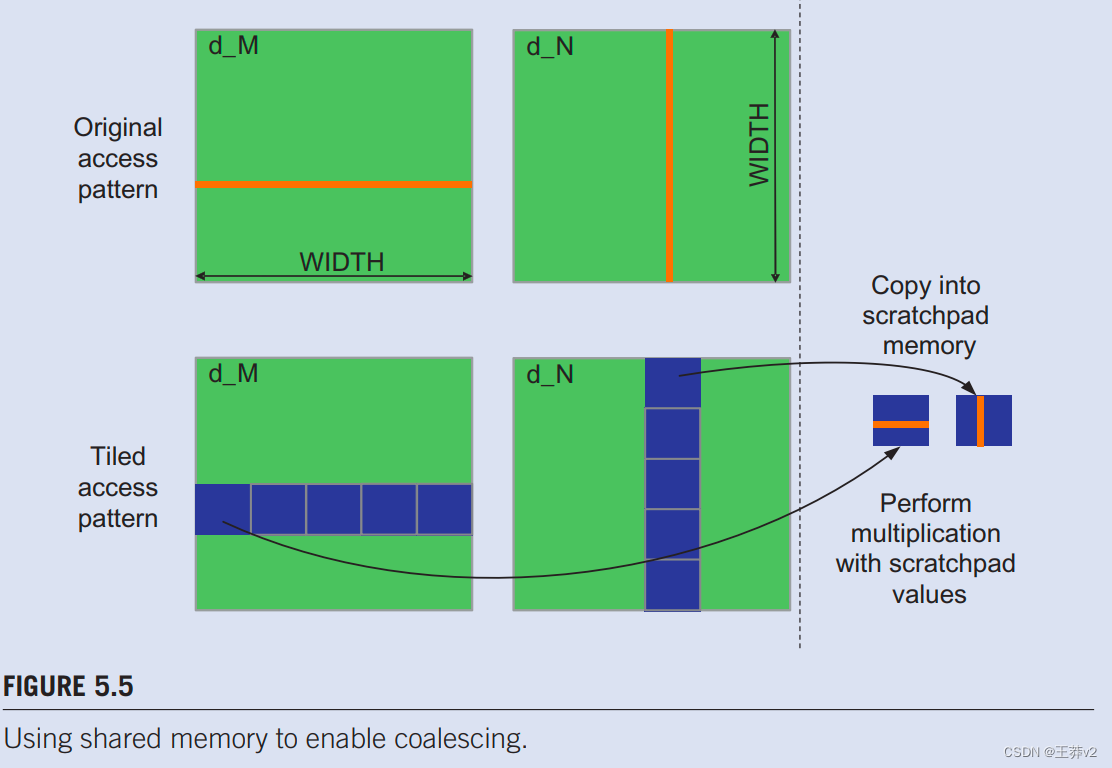
如果算法本质上需要内核代码来沿行方向遍复数据,则可以使用共享内存实现内存聚合。这个技术,称为corner turning,如图5.5所示。用于矩阵乘法。每个线程从M读取一行,这是一个无法合并的模式。幸运的是,可以使用tile算法来实现合并。正如我们在第4章“内存和数据位置”中讨论的那样,块的线程可以首先合作地将tile加载到共享内存中。必须注意确保这些tile以凝聚模式加载。一旦数据在共享内存中,它们可以按行或列访问,性能变化要小得多,因为共享存储器本质上是作为高速片上内存实现的,不需要合并来实现高数据访问率。
我们复制图4.16 这里如图5.6,其中矩阵乘法内核加载矩阵M的两块,N到共享内存。回想一下,在每个阶段(第9-11行)开始时,线程块中的每个线程负责将一个M元素和一个N元素加载到Mds和Nds中。请注意,每个tile都涉及TILE_WIDTHZ线程。线程使用threadldx.y和threadldx.y来确定要加载的元素。
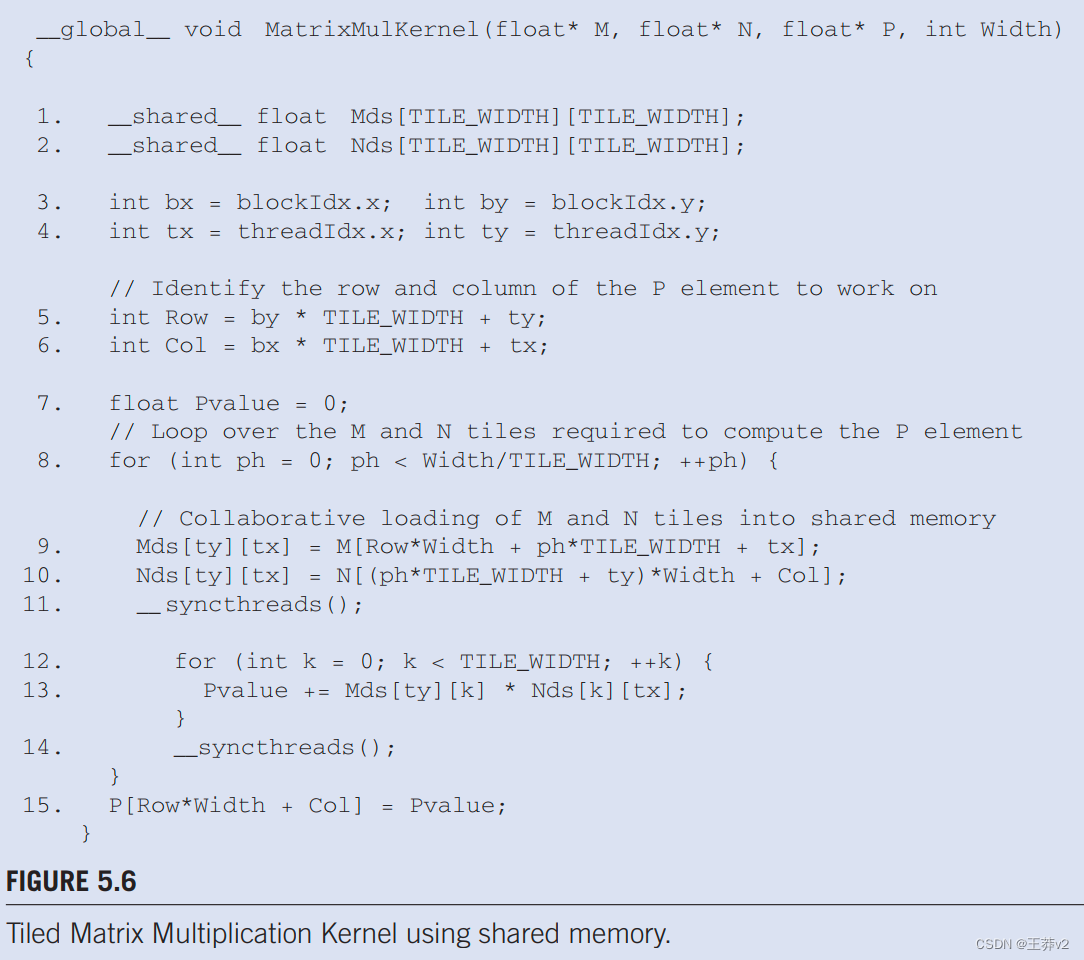
M元素加载在第9行,其中每个线程的索引计算使用ph来定位tile的左端。线性化索引计算等价于二维数组访问表达式M[Row][ph*TILE_SIZE+tx]。请注意,线程使用的列索引仅在threadIdx方面有所不同。行索引由blockldx.y和threadldx.y(第5行)确定,这意味着具有相同blockIdx.y/threadIdx.y和相邻threadldx.x值的同一线程块中的线程将访问相邻的M元素。也就是说,tile 的每一行由TILE_WIDTH线程加载,这些线程的线程ldx在y维度上相同,在x维度中是连续的。硬件将聚合这些负载。
在N的情况下,行索引 phTILE_SIZE+ty 对所有具有相同 threadldx.y 值的线程具有相同的值。问题是具有相邻 threadIdx.x 值的线程是否访问一行的相邻N个元素。注意每个线程的列索引计算, Col=bxTILE_SIZE+tx(见第6行)。第一项,bx*TILE_SIZE,对于同一块中的所有线程都是相同的。第二个项,tx,只是threadldx.x值。因此,具有相邻threadldx.x值的线程可以连续访问相邻的N个元素。硬件将凝聚这些负载。
**在 tile 算法中,对 M 和 N 元素的负载都是合并的。**因此,与简单的矩阵乘法相比,tile 矩阵乘法算法有两个优势。**首先,由于共享内存中数据的重用,内存负载的数量减少了。其次,剩余的内存负载被合并,从而进一步提高DRAM带宽利用率。**这两个改进彼此具有倍增效应,并显著提高了内核的执行速度。在当前一代设备上,平铺内核的运行速度比简单内核快30多倍。
图5.6中的第5、6、9、10行。形成了一个常用的编程模式,用于在tile算法中将矩阵元素加载到共享内存中。我们还想鼓励读者通过第12行和第13行的点积循环来分析数据访问模式。请注意,warp中的线程不会访问Mds的连续位置。这不是问题,因为Mds在共享内存中,不需要合并即可实现高速数据访问。