文章目录
- 1 简介
- 2 arm64 虚拟化相关硬件支持
- 2.1 arm64 cpu 虚拟化基本原理及硬件支持
- 2.2 系统寄存器捕获和虚拟寄存器支持
- 2.3 VHE 特性支持
- 2.4 内存虚拟化支持
- 2.5 IO 虚拟化支持
- 2.6 DMA 虚拟化支持
- 2.7 中断虚拟化支持
- 2.8 定时器虚拟化支持
- 3 arm64 kvm 初始化流程
- 3.1 初始化总体流程
- 3.2 aarch64 架构初始化总体流程
- 4 cpu虚拟化和 vcpu 运行流程
- 5 arm64 内存虚拟化流程
- 6 arm64 中断虚拟化
- 7 arm64 timer 虚拟化
1 简介
虚拟化类型:
hypervisor(guest 管理机) 又称为 VMM(virtual machine monitor)
(1)软件虚拟化
不借助硬件支持,通过软件完整的模拟一台虚拟机 => qemu tcg。
(2)硬件虚拟化
根据 VMM 实现不同,硬件虚拟化包含 type1 hypervisor 和 type2 hypervisor 两种类型。
type1(XEN,sel4) hypervisor 直接运行在硬件上,并管理系统中所有的硬件和虚拟机资源。
type2(KVM)hypervisor 会运行在一个 host os 上,host os 负责管理和控制系统的硬件资源。
- type2,host os 和 hypervisor 运行在不同的异常级别,通过异常方式实现功能调用,相对于 type1 效率更低
- 为了解决这个问题,arm8.1 增加了 VHE 拓展,使得 host os 和 hypervisor 都可以运行在 el2 级别,此时他们之间通过函数调用,效率与 type1 基本相同。
(2.1)半虚拟化
全虚拟化是指虚拟机上 guest os 不需要修改任何代码,其执行方式与真实硬件上完全相同,但是由于每次 guest os 的每次 io 都需要返回 hypervisor,中间涉及异常,上下文切换等,效率比较低。
半虚拟化为了提高虚机 IO 能力而实现,通过修改 guest os 中驱动代码,实现与 hypervisor 之间更高效的 IO 交互,从而提升虚机整体性能。典型方案是 virtio,定义了 guest os 驱动与 hypervisor 中模拟设备之间的 io 数据通信协议,通过 channel 方式管理数据传输,避免频繁的 io 操作。
虚拟化包含的内容:
让每个虚拟机 vm 都拥有完整的硬件视角,需要包含:cpu,内存,io 设备,中断控制器,定时器等。因此 hypervisor 需要提供相关的虚机化实现,如捕获到虚机 cpu 的敏感指令,并为其提供模拟实现。vm 视角下的物理内存是 hypervisor 的虚拟内存,因此 hypervisor 需要为其建立与实际物理内存的映射页表。捕获 vm 的 IO 访问,并提供对应的模拟实现。
2 arm64 虚拟化相关硬件支持
2.1 arm64 cpu 虚拟化基本原理及硬件支持
cpu 一般包含至少两个运行级别,用户级和特权级。用户级用于执行用户空间代码,具有较低的执行权限,特权级可执行操作系统内核代码,具有较高的执行权限。当特权级执行特殊指令时,触发异常并被 hyperviosr 捕获,hypervisor 负责模拟或者处理该异常。比如 guest os 执行 wfi,wfe 进入低功耗状态,对于管理机来说不会让你占用硬件资源,因此该类指令为敏感指令,当geust os 执行时将会触发异常,进入 hypervisor,hypervisor 捕获该异常,并将该 vcpu 调度出去,由其他 vcpu 使用。
因此 armv8 在虚拟化中提供了敏感指令和异常的捕获功能,可以通过配置 hypervisor 控制寄存器 hcr_el2 实现,它将 vm 执行的敏感指令或异常路由到 el2 中,hypervisor 捕获到相关异常后可为其模拟相关功能。
hcr_el2 相关 bit 描述如下:
(1)FMO:配置该位会将fiq中断路由到EL2
(2)IMO:配置该位会将irq中断路由到EL2
(3)AMO:配置该位会将serror异常路由到EL2
(4)TWI:配置该位会将WFI指令路由到EL2
(5)TWE:配置该位会将WFE指令路由到EL2
(6)TGE:该位只有在支持VHE的架构下才有效。当配置该位后所有需要路由到EL1的异常都会被路由到EL2。因此只要设置该位后,不再设置以上这些位,其对应的异常也会被路由到EL2下
2.2 系统寄存器捕获和虚拟寄存器支持
有些系统寄存器的值在 vmm 和 guest os 视角下并不相同,如 ID_AA64MMFR0_EL1 寄存器用于提供 cpu 支持的内存特性(其支持的最大物理地址范围,支持的 ASID 位数,大小端支持情况等)。对于这类寄存器每个 guest os 可以拥有其自身的属性值,因此 vmm 需要通过异常捕获 guest os 对其的访问,并在异常处理流程中为其提供一个虚拟值。
这类寄存器的访问频率并不高,因此捕获异常对性能影响有限。而对于高频访问的寄存器(如 MIDR_EL1,MPIDR_EL1)如果使用异常方式则对 vm 性能造成很大影响。
因此 arm 为该类问题提供了优化,即为该类寄存器专门提供了虚拟化版本,如为 MIDR_EL1 定义了 VMIDR_EL2,为MPIDR_EL1定义了VMPIDR_EL2。vmm 在切换到 vcpu 之前将其值写入这些虚拟寄存器中,当 guest os 访问 MIDR_EL1 时,其实际获取到的即为 VMIDR_EL2 中的值。通过这种方式,guest os 对这类寄存器的访问将不再需要触发异常。
2.3 VHE 特性支持
通过上面提到的方式,可以解决特殊指令等访问效率问题,但对于 kvm type2 类型的 hypervisor 设计来说,hypervisor 只是 host os 的一个组件,由于 host os 本身是一个操作系统(linux),他被定义运行在 el1。
若需要让其在 el2 运行,代码上会改动非常多,如在 linux 中使用 vbar_el1 访问异常向量表基地址寄存器,此时需要修改为 vbar_el2。并且 el1 支持两个页表基地址寄存器 ttbr0_el1 和 ttbr1_el1,而在 armv8.0 的 el2 异常等级中只包含一个 ttbr0_el2。
因此为了不修改 host os 本身代码,最初的 type2 方案中的 host os 被设计为运行在 el1,而 hypervisor 作为它的一个模块运行在 el2。
此时由于 hypervisor 和 host os 位于不同异常级别,因此它们之间的调用都需要通过异常完成,该流程需要执行上下文的保存和恢复,因此会影响 hypervisor 的效率,为了解决该问题,arm 在 armv8.1 架构之后增加了 VHE 特性,从而使得 host os 不经过改动就能运行在 el2 中。
VHE 主要是为了支持将 host os 运行在 EL2 中,以提高 hypervisor 和虚拟机之间的切换代价。
其主要包含以下特性:
(1)vhe 扩展了 EL2 的内存映射能力。在不支持 vhe 的 armv8.0 中 EL2 只有一个页表基地址寄存器 ttbr0_el2,因此其能映射的地址范围为0x0000 0000 0000 0000 – 0x000f ffff ffff ffff。
而 linux 内核要求的地址映射范围为 0xfff0 0000 0000 0000 – 0xffff ffff ffff ffff,且由于 EL0 和 EL1 都支持通过 ASID 将地址与进程关联,以避免在进程切换时刷新 tlb,从而减少进程切换的开销,而 armv8.0 的 EL2 并不支持 ASID,因此若不进行改造,EL2 在页表层级并不支持运行 host os。
为此 vhe 特性增加了 ttbr1_el2 寄存器以及对 asid 的支持,从而使 EL2 具有了与 EL0 和 EL1 相同的页表能力。
(2)由于 os 内核(如 linux)被设计为访问 EL1异常等级下的系统寄存器,因此为了在不修改代码的情况下使其实际访问 EL2 寄存器,vhe 实现了寄存器重定向功能。即在使能 vhe 之后,所有 EL1寄存器的访问操作都被硬件转换为对相应 EL2 寄存器的访问,如 OS 访问ttbr0_el1寄存器,则会按下图方式被重定向到 ttbr0_el2。
el2: msr ttbr0_el1, x0E2H == 1 -> ttbr0_el2E2H == 0 -> ttbr0_el1
这里还有一个问题,hypervisor 实际上还是有访问实际 el1寄存器的需求,因此 vhe 也对其做了扩展,当访问实际 el1寄存器时,则需要使用新的特殊指令。
el2: msr ttbr0_el2, x0E2H == 1 -> ttbr0_el1
(3)当支持 vhe 且 hcr.tge 被设置后,不管hcr_el2.imo/fmo/amo是否被设置,所有 EL0 和 EL1 的异常都会被路由到 EL2 中。
有了以上扩展之后,host os 就可以不经任何修改,而像运行在 EL1 中一样运行于 EL2 中。
2.4 内存虚拟化支持
首先有一下几个地址范围定义:
(1)HVA(host virtual address):host视角下的虚拟地址
(2)HPA(host physical address):host视角下的物理地址
(3)GVA(guest virtual address):guest视角下的虚拟地址
(4)GPA(guest physical address):guest视角下的物理地址
(5)IPA(intermediate physical address):它与gpa含义相同,是arm的对guest物理地址的一种命名方式
gva -> translation table 1 -> gpa -> translation table 2 -> hpaguest os 通过 stage1 访问物理地址(IPA),硬件通过 stage2 映射访问实际物理地址(PA)
影子页表:
不支持硬件虚拟化的系统中,由于只有一个 mmu,若其被 guest os 用于 GVA -> GPA 的转换,则由于无法访问到 HPA,从而导致内存访问失败。为了解决 GPA -> HPA 之间的内存转换,引入影子页表。
影子页表是 hvpervisor 将 GVA -> GPA 和 GPA -> HPA 两级页表转换关系合并成一张表,以实现 guest 内存访问的一种机制。
(1)hypervisor 为每个 vm 中的每个进程都维护一张合并了 GVA–>GPA 和 GPA–>HPA 两级页表关系的 shadow 页表。当 guest os 执行页表切换操作时,hypervisor 将截获该操作,并用这张合并后的页表替换掉 guest os 本身的页表。它就像影子一样覆盖掉了 guest os 的页表,因此其被称为影子页表
(2)guest os 在自身页表中建立 GVA 到 GPA 的映射关系
(3)当 guest os 通过 GVA 访问内存时,若该 GVA 在 shadow 页表中已建立,则可正常通过 MMU 访问内存,否则会引起缺页异常
(4)由于 hypervisor 在页表替换时知道被替换 guest os 页表的基地址,因此在缺页异常处理流程中可通过遍历其对应的页表,查询 GVA 对应的 GPA
(5)GPA 是在虚拟机初始化内存条时设置,并与一段 host 中的用户态虚拟地址 HVA 绑定,因此 hypervisor 可以通过 GPA 获取其对应的 HVA
(6)此时可通过 host 内存管理模块的 HVA 获取到其对应的 HPA
(7)最后对以上流程进行合并,计算得到 GVA–>HPA 之间的关系,并将其填到影子页表中
显然以上流程中页表创建的开销是比较大的,因此对虚拟机的性能会有比较大的影响。为此硬件引入了两级页表,通过第一级页表完成 GVA–>GPA 的转换,并且通过第二级页表完成 GPA–>HPA 的转换,从而提高了地址转换的效率。
Armv8 两级页表:
在硬件支持两级页表后,不需要 hypervisor 执行页表合并这个复杂操作。一级页表由 guest os 创建,用于 GVA -> GPA(IPA,stage 1)的换转,而二级页表由 hypervisor 创建,用于执行 GPA(IPA,stage 2) -> HPA 转换,同样对 guest os 是透明的。
与 ASID 类似,armv8 为每个虚机提供了 VMID,用于在 TLB 中标识地址是属于哪个虚机的。有了 VMID 之后,当 cpu 执行虚机切换操作时,就不需要失效 tlb 中的内容,当下次该 vm 再次被切换回来时,若 tlb 中包含了该 vm 先前的 entry,则这些 entry 依然有效,因此可以提高虚机切换的效率和运行性能。
由于 tlb entry 中每个 vm 含有自身的 VMID tag,而每个 VM 中的每个进程又含有对应的 ASID tag,因此在实际的页表转换时需要将它们进行合并。
同样由于 stage 1 页表和 stage 2 页表都可以设置各自的属性,因此在实际页表转换时 MMU 需要选择两级页表中访问限制更严格的属性,如:
stage 1(device),stage 2 (normal),此时选择 device。
2.5 IO 虚拟化支持
虚机除了模拟物理内存空间,还需要模拟外设的地址空间,以用于其对模拟设备的访问。由于虚机视角的物理地址是 IPA,因此 IPA 需要提供虚机对外设的访问能力。对于物理地址,只需要为 IPA 分配实际的物理页框,并为其建立 stage 2 页表即可,而对于 IO 地址的目的是为了操作设备的功能,因此需要将其与设备操作相关联。
如对于一个 vm 直通的外设,IPA 地址与实际设备的 IO 地址建立页表,即可使 VM 具备了对实际设备的控制能力。而在虚拟化系统中,大部分设备都并不是某一个 VM 独享的,这种情况下 hypervisor 需要捕获 VM 的 IO 地址访问操作,并根据 IO 访问信息模拟相关设备的能力。此时不需要为这些 IO 建立 stage 2 映射,而是当 vm 访问这些地址时就会产生缺页异常,vmm 再根据 HPFAR_EL2 寄存器获取到异常地址,并根据 ESR_EL2 获取产生异常原因,最后再根据这些信息执行实际的设备模拟流程。
2.6 DMA 虚拟化支持
系统除了 cpu 外,dma 也是需要访问内存的 master 设备。在 guest os 视角中,只能感知 IPA 地址存在,因此 guest 操作 DMA 时会以 IPA 地址作为 DMA 数据搬移的源地址和目的地址。
由于 IPA 地址并非总线上的实际物理地址,因此若直接执行 DMA 操作会导致地址访问错误。同样若没有硬件拓展,vmm 可以捕获所有 DMA 控制器的 IO 操作,当捕获到 DMA 地址设置操作时,vmm 为 dma 地址分配实际物理内存,并将物理地址写入实际的 DMA 寄存器,同时建立 IPA 到 HPA 的内存映射。
上述方法效率低,从而引入 SMMU,通过 SMMU 为 master 设备创建 stage 2 映射,从而使 DMA 可以通过 IPA 直接看到 PA。
vmm 只需要为 DMA 创建 SMMU 页表,将其 IPA 转换为 PA 即可实现 DMA 的内存访问操作。
2.7 中断虚拟化支持
如果没有硬件支持中断虚拟化时,此时 guest os 正常的初始化中断控制器,异常向量表,注册中断函数。vmm 需要为 vm 模拟一个虚拟的中断控制器,捕获 guest os 中断相关的设置,并将其转发给虚拟中断控制器处理。若虚拟中断与物理中断关联,还需要根据与实际中断的映射关系,获取其对应的物理中断信息,并将其设置到物理中断控制器中。
当中断触发时,首先由 hypervisor 捕获物理中断,然后根据其物理中断与虚拟中断的映射关系设置虚拟中断控制器的状态信息,以向 vcpu 注入中断。在切换到 vcpu 之前 hypervisor 检查虚机中断是否被触发,并确定是否需要跳转到 vcpu 的中断处理入口。
为了提高效率和简化虚拟中断注入流程,GIC 在硬件层面提供了虚拟中断注入功能。如 GICv3 提供了一组 list register寄存器用于hypervisor为vcpu注入虚拟中断,并且为vcpu在硬件层面提供了vIRQ和vFIQ中断信号,用于响应注入到list register中的中断。最后,GICv3还为vcpu提供了一组虚拟cpu interface寄存器,vcpu可以像处理普通中断一样操作这组寄存器,完成中断信息读取、应答和结束等流程。
在增加硬件支持以后,armv8架构虚拟中断的流程就会变为如下这个样子:
(1)hypervisor 为 GICv3 模拟虚拟 distributor 和虚拟 redistributor。由于虚拟cpu interface已经由硬件支持,因此不再需要hypervisor模拟
(2)guest os的中断配置信息由hypervisor捕获,并发送给虚拟distributor和虚拟redistributor处理
(3)hypervisor捕获实际的物理中断,查找其对应的虚拟中断信息,并将虚拟中断信息写入list register寄存器中,以向vcpu注入虚拟中断
(4)hypervisor调度中断对应的vcpu运行,由于virq/vfiq已经被触发,vcpu进入中断处理流程。此时,其对cpu interface的操作实际上都会被GICv3转换为对虚拟cpu interface的操作,并直接作用于GIC硬件。
2.8 定时器虚拟化支持
Armv8架构的每个cpu都包含一个generic timer定时器,该定时器可以通过比较器与系统计数器比较,以确定定时器是否到期。当定时器到期时,可以产生一个PPI中断以触发定时器事件。
但是在支持虚拟化之后,由于物理cpu是被vcpu共享的,因此它们可能需要在物理cpu上交替运行。
对于交替运行的两个 vcpu,定时器如何共享?
为了解决该问题,armv8为 vm 同时提供了虚拟定时器和物理定时器。
Physical Count Virtual offset(cntpct_el0) (cntoff_el2)Virtual Count(cntvct_el0)
其中虚拟计数器提供了一个与物理计数器之间的 offset 偏移量,该值可以由 vmm 进行设置。当不同 vcpu 运行时,为其设置不同的 offset。
3 arm64 kvm 初始化流程
kvm是基于linux内核实现的一种type 2虚拟化方案,它作为内核的一个模块负责虚拟化环境初始化,虚拟机和虚拟cpu模拟,以及IO捕获与转发等功能。在kvm中虚拟机和虚拟cpu分别通过host os的进程和线程实现,并且由host os的调度器对其进行调度。
除了像中断控制器之类的关键设备,kvm 不会模拟设备工作,因此它通常与 qemu 结合使用。由 qemu 执行实际的 IO 设备模拟,以及虚拟机创建和参数配置功能。kvm 提供 ioctl 向用户导出一组虚拟机管理接口。
3.1 初始化总体流程
kvm 初始化的主要目的是为虚拟机的创建和运行提供必要的软硬件环境,总体流程如下:
arm_init -> kvm_init-> kvm_arch_init-> kvm_irqfd_init-> alloc_workqueue-> cpuhp_setup_state_nocalls-> kvm_starting_cpu-> kvm_dying_cpu-> register_reboot_notifier-> blocking_notifier_chain_register-> kmem_cache_create_usercopy-> misc_register-> register_syscore_ops-> kvm_init_debug-> debugfs_create_dir-> kvm_vfio_ops_init-> kvm_register_device_ops
可以看到 kvm 初始化流程主要包括以下几个部分:
(1)架构相关的初始化
(2)电源管理接口注册回调,处理kvm在电源管理流程中的行为
(3)为 kvm 注册字符设备,提供 ioctl 接口
(4)其他一些辅助功能
(1)电源管理接口注册回调
可以热插拔的 cpu 和休眠的系统上,cpu可以进行 online/offline 的状态转换。
kvm_syscore_ops提供了系统挂起和恢复的回调。
register_reboot_notifier提供了在系统reboot后,下线时的通知回调,这里对应调用架构自己实现的 kvm_arch_hardware_disable。
而cpuhp_setup_state_nocalls则提供了cpu重新上线/下线的回调,上线则对应 reboot 时的kvm_arch_hardware_enable,
下线同样对应kvm_arch_hardware_disable。
(2)ioctl 接口注册
kvm 的 ioctl 接口注册在 misc_register 中完成,提供了kvm_dev_ioctl回调接口。
对应的该 ioctl 接口可以分为三个类型:kvm ioctl,vm ioctl,vcpu ioctl。
kvm ioctl 全局控制 kvm,vm ioctl 对英语特定 vm 虚机控制,vcpu ioctl 特定于 vcpu 控制。
vm ioctl 通过全局的 KVM_CREATE_VM 命令创建一个 vm fd,并且绑定匿名 inode,该匿名 inode 对应 kvm_vm_fops ioctl 回调。
vcpu ioctl 通过上面的 vm ioctl 命名 KVM_CREATE_VCPU 命名创建一个 vcpu fd,并绑定匿名 inode,该匿名 inode 对应 kvm_vcpu_fops ioctl 回调。
(3)其他一些辅助功能
kvm_irqfd_init为 eventfd 创建了一个全局的工作队列,它用于在虚机被关闭时:关闭所有与其相关的 irqfd,并等待该操作完成。kvm_init_debug用于为 kvm 创建 debugfs 相关接口kvm_vfio_ops_init用于为 vfio 注册设备回调函数
(4)架构相关初始化 kvm_arch_init
armv8的虚拟化方案有两种方式:nvhe 和 vhe。
vhe 实现虚拟支持 VHE 拓展,该实现中 host os 和 guest os 都运行在 el2,此时 host os 和 hypervisor 公用所有的 el2 寄存器,且 host 可以直接通过函数调用的方式调用hypervisor接口,因此 vhe 模式下的 kvm 模块初始化流程更简单,主要包括一些 host context 初始化,以及虚拟 gic 和 timer 的初始化。
nvhe 实现相对则是更早期的实现,只需要硬件支持虚拟化即可,不需要 vhe 拓展。nvhe 的 host os 和 hypervisor 运行在不同异常级别,hypervisor 处于 el2,host os 处于 el1。比如 host os 需要通过异常(hvc)的方式进入 hypervisor,并且为 el2 的 hypervisor 独立设置异常处理函数,映射代码段,数据段等,因此初始化相对复杂,见下面。
3.2 aarch64 架构初始化总体流程
kvm_arch_init-> is_hyp_mode_available-> is_kernel_in_hyp_mode-> !in_hyp_mode && kvm_arch_requires_vhe-> check_kvm_target_cpu-> kvm_target_cpu-> init_common_resources-> kvm_get_vmid_bits-> kvm_set_ipa_limit-> init_hyp_mode (nvhe 模式 true)-> kvm_mmu_init-> per_cpu(kvm_arm_hyp_stack_page, cpu) = stack_page;-> create_hyp_mappings-> kvm_map_vectors-> init_subsystems-> _kvm_arch_hardware_enable-> hyp_cpu_pm_init-> kvm_vgic_hyp_init-> kvm_timer_hyp_init-> kvm_perf_init-> kvm_coproc_table_init
(1)is_hyp_mode_available:由于管理机需要运行在 el2,所以这里通过判断启动是否是在el2来判断是否支持hypervisor(可以参考之前的 arm64 启动流程分析中关于 el2_setup 的解析)。
(2)is_kernel_in_hyp_mode: 判断当前所处的异常级别判断自己是否支持 vhe,如果支持 VHE 那么 host 此时是处于 el2 的,那么 is_kernel_in_hyp_mode 返回 ture。
(3)!in_hyp_mode && kvm_arch_requires_vhe:如果没有支持 vhe,但是 kvm_arch_requires_vhe 表示我们需要 VHE 这个特性,那么此处如果不成立,则 kvm 不可用,直接返回 -ENODEV。
(4)check_kvm_target_cpu:该函数通过 smp_call_function_single ipi 在每个 cpu 上执行,通过读取 cpu 的型号并判断是否合法。
(5)init_common_resources:获取 vmid bits,以及通过读取 SYS_ID_AA64MMFR0_EL1,并根据支持的大小页判断当前系统配置的 page size 能否被硬件支持,通过解析出能够支持的最大物理地址长度。
(6)init_hyp_mode:如果没有支持 vhe,那么则会进入该流程,下面详细说明。
init_hyp_mode
(1)kvm_mmu_init
之前说过,nvhe 模式 hypervisor 和 host os 处于不同级别,此时我们处于 el1,我们需要为 el2 的 hypervisor 创建页表映射:
int kvm_mmu_init(void)
{int err;hyp_idmap_start = kvm_virt_to_phys(__hyp_idmap_text_start);hyp_idmap_start = ALIGN_DOWN(hyp_idmap_start, PAGE_SIZE);hyp_idmap_end = kvm_virt_to_phys(__hyp_idmap_text_end);hyp_idmap_end = ALIGN(hyp_idmap_end, PAGE_SIZE);hyp_idmap_vector = kvm_virt_to_phys(__kvm_hyp_init);
...merged_hyp_pgd = (pgd_t *)__get_free_page(GFP_KERNEL | __GFP_ZERO);if (!merged_hyp_pgd) {kvm_err("Failed to allocate extra HYP pgd\n");goto out;}__kvm_extend_hypmap(boot_hyp_pgd, hyp_pgd, merged_hyp_pgd,hyp_idmap_start);} else {err = kvm_map_idmap_text(hyp_pgd);if (err)goto out;}io_map_base = hyp_idmap_start;return 0;
...
}static int kvm_map_idmap_text(pgd_t *pgd)
{int err;/* Create the idmap in the boot page tables */err = __create_hyp_mappings(pgd, __kvm_idmap_ptrs_per_pgd(),hyp_idmap_start, hyp_idmap_end,__phys_to_pfn(hyp_idmap_start),PAGE_HYP_EXEC);if (err)kvm_err("Failed to idmap %lx-%lx\n",hyp_idmap_start, hyp_idmap_end);return err;
}
内核中类似 .hyp.idmap.text, "ax" ,__hyp_text 标记段则是需要被映射到 el2 的 hypervisor 的文本段,并通过上述 __create_hyp_mappings 首先完成 idmap 映射,其余的段会在后续继续在 hyp_pgd中建立映射。而创建完成的 hyp_pgd pgd 页表将会在 _kvm_arch_hardware_enable 中通过 kvm_call_hyp 调用一同传递到 el2:
ENTRY(__kvm_call_hyp)
alternative_if_not ARM64_HAS_VIRT_HOST_EXTNhvc #0ret
alternative_else_nop_endifb __vhe_hyp_call
ENDPROC(__kvm_call_hyp)
(2)hypervisor栈和percpu内存分配
该流程主要为 hypervisor(所有物理cpu)运行时分配对应的栈:
/** Allocate stack pages for Hypervisor-mode*/for_each_possible_cpu(cpu) {unsigned long stack_page;stack_page = __get_free_page(GFP_KERNEL);if (!stack_page) {err = -ENOMEM;goto out_err;}per_cpu(kvm_arm_hyp_stack_page, cpu) = stack_page;}
同样的 kvm_arm_hyp_stack_page 在 cpu_init_hyp_mode 中通过 kvm_call_hyp 一并传递到 el2。
(3)create_hyp_mappings。。。:在这里将会完成 hyp text,data,bss ,vector段,stack 的映射:
/** Map the Hyp-code called directly from the host*/err = create_hyp_mappings(kvm_ksym_ref(__hyp_text_start),kvm_ksym_ref(__hyp_text_end), PAGE_HYP_EXEC);if (err) {kvm_err("Cannot map world-switch code\n");goto out_err;}err = create_hyp_mappings(kvm_ksym_ref(__start_rodata),kvm_ksym_ref(__end_rodata), PAGE_HYP_RO);if (err) {kvm_err("Cannot map rodata section\n");goto out_err;}err = create_hyp_mappings(kvm_ksym_ref(__bss_start),kvm_ksym_ref(__bss_stop), PAGE_HYP_RO);if (err) {kvm_err("Cannot map bss section\n");goto out_err;}err = kvm_map_vectors();if (err) {kvm_err("Cannot map vectors\n");goto out_err;}/** Map the Hyp stack pages*/for_each_possible_cpu(cpu) {char *stack_page = (char *)per_cpu(kvm_arm_hyp_stack_page, cpu);err = create_hyp_mappings(stack_page, stack_page + PAGE_SIZE,PAGE_HYP);if (err) {kvm_err("Cannot map hyp stack\n");goto out_err;}}
到这里 nvhe 模式的映射相关初始化完成。
init_subsystems
(1)_kvm_arch_hardware_enable:有如下流程:
cpu_hyp_reinit-> cpu_hyp_reset-> if is_kernel_in_hyp_mode-> kvm_timer_init_vhe-> else-> cpu_init_hyp_mode-> kvm_arm_init_debug-> kvm_vgic_init_cpu_hardware
-
cpu_hyp_reset 如果host是 nvhe 模式,则通过 hvc 调用HVC_RESET_VECTORS:
ENTRY(__hyp_stub_vectors) ... ... el1_sync: ... ... 3: cmp x0, #HVC_RESET_VECTORSbeq 9f // Nothing to reset!/* Someone called kvm_call_hyp() against the hyp-stub... */ldr x0, =HVC_STUB_ERReret9: mov x0, xzreret ENDPROC(el1_sync)目前无事可做。
-
kvm_timer_init_vhe
如果支持 vhe 则在这里初始化 vhe timer: /** On VHE system, we only need to configure trap on physical timer and counter* accesses in EL0 and EL1 once, not for every world switch.* The host kernel runs at EL2 with HCR_EL2.TGE == 1,* and this makes those bits have no effect for the host kernel execution.*/ void kvm_timer_init_vhe(void) {/* When HCR_EL2.E2H ==1, EL1PCEN and EL1PCTEN are shifted by 10 */u32 cnthctl_shift = 10;u64 val;/** Disallow physical timer access for the guest.* Physical counter access is allowed.*/val = read_sysreg(cnthctl_el2);val &= ~(CNTHCTL_EL1PCEN << cnthctl_shift);val |= (CNTHCTL_EL1PCTEN << cnthctl_shift);write_sysreg(val, cnthctl_el2); }如果是 nvhe,那么调用 cpu_init_hyp_mode static void cpu_init_hyp_mode(void *dummy) {phys_addr_t pgd_ptr;unsigned long hyp_stack_ptr;unsigned long stack_page;unsigned long vector_ptr;/* Switch from the HYP stub to our own HYP init vector */__hyp_set_vectors(kvm_get_idmap_vector());pgd_ptr = kvm_mmu_get_httbr();stack_page = __this_cpu_read(kvm_arm_hyp_stack_page);hyp_stack_ptr = stack_page + PAGE_SIZE;vector_ptr = (unsigned long)kvm_get_hyp_vector();__cpu_init_hyp_mode(pgd_ptr, hyp_stack_ptr, vector_ptr);__cpu_init_stage2(); }后续的kvm_vgic_hyp_init,kvm_timer_hyp_init等均首先在如 irq-gic-v3/arch_timer 的初始化中检测出与虚拟化相关的支持信息,并在这里对应做虚拟化相关的硬件初始化(未详细分析)。
到这里,kvm 的初始化流程基本结束,后续就可以通过 ioctl 来创建虚机,vcpu 了。
ps:arch 相关的初始化比如虚拟化 gic,timer的初始化这里没有进行详细分析。
4 cpu虚拟化和 vcpu 运行流程
后续基于支持 VHE 特性的虚拟化进行分析,目前大多数设备都支持 VHE。
linux cpu 上下文切换
在linux 中一个从一个任务切换到另一个任务主要通过 context_switch 进行切换,其中涉及到了 mm 切换,cpu 切换,这主要看下 cpu 上下文切换,直接看代码:
/** Register switch for AArch64. The callee-saved registers need to be saved* and restored. On entry:* x0 = previous task_struct (must be preserved across the switch)* x1 = next task_struct* Previous and next are guaranteed not to be the same.**/
ENTRY(cpu_switch_to)mov x10, #THREAD_CPU_CONTEXTadd x8, x0, x10mov x9, spstp x19, x20, [x8], #16 // store callee-saved registersstp x21, x22, [x8], #16stp x23, x24, [x8], #16stp x25, x26, [x8], #16stp x27, x28, [x8], #16stp x29, x9, [x8], #16str lr, [x8]add x8, x1, x10ldp x19, x20, [x8], #16 // restore callee-saved registersldp x21, x22, [x8], #16ldp x23, x24, [x8], #16ldp x25, x26, [x8], #16ldp x27, x28, [x8], #16ldp x29, x9, [x8], #16ldr lr, [x8]mov sp, x9msr sp_el0, x1ret
ENDPROC(cpu_switch_to)
NOKPROBE(cpu_switch_to)
将正在执行的任务1的 cpu 寄存器保存到其上下文中,然后将任务2上一次调度时保存的上下文恢复到 cpu 寄存器中,即可完成一次切换,切换主要包括 x18-x28,fp,sp,pc 寄存器。至于为什么是这些寄存器,是根据规范定义的调用约定决定的,具体可以查阅相关资料。
vcpu entry
vcpu 的运行与进程上下文切换类似,当 host os 需要切换到 vcpu 运行时,就将 vcpu 对应的 guest 上下文恢复到对应的物理 cpu 中。当 guest 退出时则将 cpu 状态保存到 vcpu 上下文中。
不过实际上与任务切换还是存在一些区别。首先任务是 host os 内的管理实体,拥有相同的系统寄存器配置,切换时不需要改变系统寄存器的值。而 vcpu 上运行的是 guest os,它所有的寄存器配置可能与 host os 不同,因此在进行上下文切换时需要保存和恢复的寄存器更多,比如包含系统寄存器等。
另一个差异是任务的切换都是在 host os 内核中,而 guest os 与管理机运行在不同异常等级级别,因此其切换流程还需要伴随着异常等级的改变。即切换前后都位于 os 所处的 el2 级别,而切换后 guest os 处于 el1 级别。
(补充:host os 进入 guest os 是host在 el2 通过 eret 指令返回到 el1 实现,具体可以查阅代码)
vcpu exit
在不考虑 el3 安全拓展时,非虚拟化环境下 host os 可以控制所有系统资料,包括内存,io 地址,中断处理以及所有指令的执行。但在虚拟化环境下,guest os 一般不能直接访问 io,敏感指令(如 wfi,wfe),以及物理中断等。
比如管理机(host os kvm)可以配置 guest 在执行到敏感指令时触发异常,并且该异常被路由到 el2 的管理机中。同样的 io 地址在 stage 2 也表设置为不指向实际物理地址时,则 guest os 一旦访问 io 地址则会触发缺页异常,并该异常路由到 el2 的管理机中。
因此,el2 管理机通过捕获这些异常,就可以为 guest os 模拟相关操作,并将模拟结果返回,而 guest os 自身不感知这些行为。
(补充:guest os 退出回到 guest os 是 guest 发生了访问 io,访问敏感指令,中断等触发异常返回到 el2)
vcpu 调度
上面说到 guest os 只有在触发异常,产生中断时才会退出 guest os返回 host os,处理完成后再次返回 guest os。在 vcpu 视角下,除了管理机代理其处理了异常外,物理cpu像被其独占。
实际上站在 host os 角度,vcpu 只是 host os 创建的一个普通线程,因此受到 host os 的调度器管理。当 vcpu 线程时间片用尽时,则会被调度出去,让出物理cpu。这里涉及两个上下文:
(1)vcpu 所在的普通线程上下文
(2)vcpu guest 和 host 之前切换的上下文
在 schedule中有 fire_sched_in_preempt_notifiers 和 fire_sched_out_preempt_notifiers。vcpu 运行前向 preempt_notifiers 通知链注册一个通知,该通知包含其线程应该被 sched in 和 sched out 时需要执行的回调。
当 vcpu 正在运行 guest 程序时,host 触发 timer 中断,并在中断中检测到需要调度程序。因此触发 schedule_irq。
调度器在调度前通过preempt_notifiers通知链中所有回调。
回调执行到 vcpu 切出操作,在该操作中先保存 guest 上下文,然后恢复 vcpu 对应线程的上下文,到这里完成 vcpu 退出,并且 vcpu 对应的线程也即将被调度出去。
当该 vcpu 对应线程再次被调度回来运行时,则同样通过preempt_notifiers执行通知,回调 vcpu entry,恢复 vcpu 的 guest 上下文。
vcpu 生命周期
(1)vcpu创建并初始化完成后,host的用户空间将通过KVM_RUN的ioctl进入内核空间切入guest运行。在切换流程中,先将切前的cpu寄存器保存到host上下文中,然后将guest上下文恢复到cpu寄存器中
(2)物理cpu切换到guest状态,开始执行guest指令
(3)当guest遇到敏感指令,或IO操作等需要切换回host处理的流程时,将退出guest
(4)host根据退出原因,判断其应该是由内核态还是用户态处理
(5)若其由内核态处理,则直接执行处理流程,并在处理完成后重新切入guest。guest则从上次被中断的位置继续向下运行
(6)若其需要用户态执行,则需要先切换到用户态。用户态执行完相关流程后,再次通过ioctl进入内核态,并切入guest运行
(7)vcpu的运行流程即是以上这些步骤的循环往复,直到虚拟机结束执行为止
vcpu创建流程
入口在 vm ioctl KVM_CREATE_VCPU 中:
kvm_vm_ioctl_create_vcpu-> kvm_arch_vcpu_create-> kvm_vcpu_init-> kvm_timer_vcpu_init-> kvm_arm_reset_debug_ptr-> kvm_vgic_vcpu_init-> create_hyp_mappings-> preempt_notifier_init-> kvm_create_vcpu_debugfs-> create_vcpu_fd-> kvm_arch_vcpu_postcreate
(1)preempt_notifier_init:vcpu 的 preempt_notifiers,用于任务的 vcpu 切换。
(2)create_vcpu_fd:创建 vcpu ioctl 相关
(3)kvm_vcpu_init:主要逻辑在这里:
对应架构相关的 vcpu 创建初始化流程,主要初始化一些与 cpu 相关的硬件状态,如 timer,pmu,vgic 的 redistributor和 sgi,ppi 中断等。
vcpu 的运行
vcpu 在运行时需要处理中断,信号,pmu,timer等状态,这里主要分析一些重要流程,入口是 vcpu ioctl kvm_arch_vcpu_ioctl_run:
kvm_arch_vcpu_ioctl_run-> kvm_vcpu_first_run_init-> kvm_handle_mmio_return-> vcpu_load-> preempt_notifier_register-> kvm_arch_vcpu_load-> kvm_vgic_load-> kvm_timer_vcpu_load-> kvm_vcpu_load_sysregs-> kvm_arch_vcpu_load_fp-> update_vttbr-> check_vcpu_requests-> guest_enter_irqoff-> kvm_arm_vhe_guest_enter-> kvm_vcpu_run_vhe-> sysreg_save_host_state_vhe-> __activate_vm-> __activate_traps-> sysreg_restore_guest_state_vhe-> do {/* Jump in the fire! */exit_code = __guest_enter(vcpu, host_ctxt);/* And we're baaack! */} while (fixup_guest_exit(vcpu, &exit_code));-> sysreg_save_guest_state_vhe-> __deactivate_traps-> sysreg_restore_host_state_vhe-> kvm_arm_vhe_guest_exit-> guest_exit-> handle_exit_early-> handle_exit (如果 host os 能够处理,则不用退回到 user 去,直接返回 update_vttbr 继续准备进入 vcpu 执行)-> vcpu_put
5 arm64 内存虚拟化流程
内存虚拟化基本概念:
-
Guest:需要一块或者多块物理内存,并且物理内存地址由 guest 自己指定,并且为了实现多任务和内存权限管理,还能够通过页表实现虚拟地址和物理地址的转换。
-
Host:新增一级页表,可以将 guest 所看到的物理地址映射到 host 实际的物理地址上。
-
Armv8硬件:通过两级页表映射实现该机制。
guest hyp [host os] phys虚拟地址 -> stage1 table -> [IPA] -> stage2 table -> [PA]
根据上述流程有如下命名:
(1)GVA:guest 视角下的虚拟地址
(2)GPA:guest 视角下的物理地址(host 视角下的 IPA 地址)
(3)HPA:host 视角下的物理地址
(4)HVA:host 视角下的虚拟地址
host只需要管理和维护 HVA 到 GPA 的关系即可,不需要像影子页表一样自己维护 mmu 映射。
HVA 到 GPA 触发映射流程如下:
当 guest 建立虚拟地址到物理地址映射时(GVA -> GPA),由于实际上 host 没有给 guest 的 GPA 分配实际的物理地址,因此 guest 一旦访问 GPA 时,cpu 则会触发缺页异常,该异常将被 host 捕获。
此时 hyp(host os)根据异常开始为 HVA 到 GPA 建立一个维护数据并为其实际映射物理地址(stage2),映射完成返回到 guest 后,guest 即可顺利访问实际映射的物理地址。
虚拟机内存设置
为虚拟机分配 GPA 内存是通过 host 的 vm ioctl 发起完成的,因此 HVA 在这里实际是用户态程序(qemu)的虚拟地址。为了描述它们之间的关系,kvm 定义了如下结构:
/** Note:* memslots are not sorted by id anymore, please use id_to_memslot()* to get the memslot by its id.*/
struct kvm_memslots {u64 generation;struct kvm_memory_slot memslots[KVM_MEM_SLOTS_NUM];/* The mapping table from slot id to the index in memslots[]. */short id_to_index[KVM_MEM_SLOTS_NUM];atomic_t lru_slot;int used_slots;
};struct kvm_memory_slot {gfn_t base_gfn;unsigned long npages;unsigned long *dirty_bitmap;struct kvm_arch_memory_slot arch;unsigned long userspace_addr;u32 flags;short id;
};
用户态程序通过 kvm_vm_ioctl_set_memory_region 设置一块 guest 内存描述到 struct kvm_memory_solt 中。
kvm_vm_ioctl_set_memory_region-> kvm_set_memory_region-> __kvm_set_memory_region一块内存描述如下:
/* for KVM_SET_USER_MEMORY_REGION */
struct kvm_userspace_memory_region {__u32 slot;__u32 flags;__u64 guest_phys_addr;__u64 memory_size; /* bytes */__u64 userspace_addr; /* start of the userspace allocated memory */
};
内存设置完成后并没有建立实际的 stage2映射,当 guest 访问 IPA 会触发缺页异常,此时 host 将会实际建立 stage2 映射,流程如下:
__kvm_hyp_vector-> el1_sync-> __guest_exit-> handle_exit-> handle_trap_exceptions (ARM_EXCEPTION_TRAP)-> kvm_get_exit_handler-> kvm_handle_guest_abort// io abort-> io_mem_abort-> user_mem_abort// 流程很多,没有详细分析-> ...
6 arm64 中断虚拟化
一般 kvm 不模拟设备,不过中断控制器和timer由内核完成了模拟(它们处于虚拟运行的关键路径上),armv8 目前最常用的中断控制器是 GICv3,它支持中断虚拟化以及额外中断虚拟化拓展,包括安全拓展,vcpu interface 虚拟化。gicv3 布局大致如下:

外设将中断电平线连接到 GICv3,cpu 可以通过GICv3的寄存器设置中断的触发方式,优先级以及路由方式等属性。当中断被触发后,则通过 cpu 与 gic 之间的中断信号线 IRQ 或者 FIQ 通知 CPU。随后,cpu 通过中断向量表进入中断处理流程,在中断处理完成后通过 GIC 的 EOI 寄存器通知中断处理完成,GIC内部修改其状态机进行下一次的中断分发。
备注:使用 irq 还是 fiq 根据 gic 配置决定,大致有如下配置:
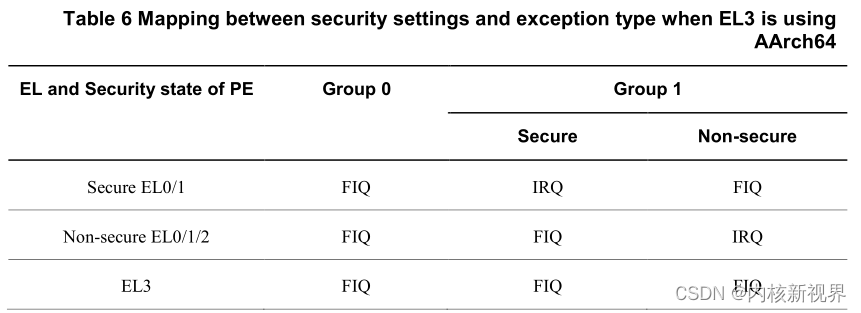
即 group0 的中断都是 fiq,el3 的都是 fiq 中断,另外 安全世界的 el1/el0,如果gic配置为se group1 则是 irq,no se group1 是 fiq。
非安全世界 el0/el1/el2,se group1 是fiq,no se group1 是 irq。linux 处于 non secure el1/el2,gicv3 为 non-serucre group1 所有 linux 收到的都是 irq 中断。
除了 IRQ 和 FIQ,CPU 和 GIC 之间还有 vIRQ 和 vFIQ。它们是GICv3为了支持虚拟化拓展而设计的,主要目的是用于向 vcpu 发送中断信号。
gic 组件
为了实现中断的配置,接收,仲裁和路由功能,GICv3设计了如下组件,包含 SPI,PPI,SGI 和 LPI 四种中断类型,以及分发器,重分发器,ITS 和 cpu interface 四大组件,关系如下:

分发器主要包含两部分功能:
(1)作为可编程接口,可以配置 GICD 寄存器,对中断控制器的全局属性以及 SPI 类型中断属性进行配置
(2)根据配置可以设定中断分组,优先级,以及亲和性,并且将 SPI 和 SGI 中断路由到特定的重分发器和 cpu interface 上。
重分发器位于分发器和cpu interface之间,包含如下两部分功能:
(1)可以配置GICR寄存器,对 PPI 和 SGI 类型中断属性进行配置,设定中断触发类型,中断使能以及中断优先级等,还包括了电源管理,LPI中断管理。
(2)能将最高优先级的 pending 中断发送到与其对应的 cpu interface 上。
cpu interface 可以用于物理中断,虚拟中断处理,以及可为管理机提供虚拟机控制接口,包括 SGI 中断产生,PPI,SGI 的优先级设置,最高 pending优先级读取以及应答,deactivate,完成操作执行等。
ITS 是 gicv3 的高级特性,作用是将一个来自设备的输入 eventID转换为 LPI 中断号,并确定该中断将被发送的目的 PE。
虚拟中断原理
虚拟中断的实现需要cpu和gic共同配合,首先GICv3提供了一组名为list register(LR)的寄存器,host可以通过将中断信息写入该寄存器来触发虚拟中断。其次,cpu在原先irq和fiq两条中断线的基础上又增加了两条虚拟中断线virq和vfiq,以用于虚拟中断的接收。
在虚拟中断被触发后,guest需要通过cpu interface执行中断的应答、结束等操作。为了提高中断处理效率,GICv3又在硬件上支持了一组虚拟cpu interface寄存器。使guest可以直接操作这些寄存器,从而避免了需要host模拟cpu interface设备
由于物理设备的中断通常都需要由host处理,因此若guest的中断与物理中断关联,则应该先路由给host处理。armv8可以通过hcr_el2寄存器配置该能力:
(1)若未使能vhe,可通过设置hcr_el2.FMO和hcr_el2.IMO,以将EL1的guest中断路由到EL2
(2)若使能了vhe,则可通过设置hcr_el2.TGE,将EL1的guest中断路由到EL2
Host执行相应处理后,就可以通过设置lr寄存器,将其以虚拟中断的方式注入到给guest。下图为其总体框图:
 (1)外设触发 irq 中断,gic 的分发器接收中断,通过分发器仲裁确定应该发送到 cpu,
(1)外设触发 irq 中断,gic 的分发器接收中断,通过分发器仲裁确定应该发送到 cpu,
(2)target cpu 确定以后,将中断发送给该 cpu 的重分发器
(3)重分发器将中断发送到其对应的 cpu interface 上
(4)该中断被路由到 el2 的管理机中断入口
(5)管理机不处理该中断,但是触发异常 vcpu exit,退回到 host,在host handle exit 中重新使能该中断,中断再次触发,并有 host 中断处理函数进行中断处理
(6)host 通过写 lr 向 guest 注入虚拟中断,并切入 guest 执行
(7)虚拟中断触发 virq,并进入 guest 的中断入口函数
(8)guest 执行中断处理流程,并通过虚拟 cpu interface 执行中断应答和 EOI 操作。
(9)若该虚拟中断与物理中断关联,则 EOI 实际是到实际的物理中断上。
(10)中断处理完成。
更详细的例子:
根据之前 cpu 进入 guest 的流程:
kvm_arch_vcpu_ioctl_run-> __kvm_vcpu_run_vhe-> __guest_enter
在 __kvm_vcpu_run_vhe 之前,有 __activate_traps操作:
static void activate_traps_vhe(struct kvm_vcpu *vcpu)
{u64 val;val = read_sysreg(cpacr_el1);val |= CPACR_EL1_TTA;val &= ~CPACR_EL1_ZEN;if (!update_fp_enabled(vcpu)) {val &= ~CPACR_EL1_FPEN;__activate_traps_fpsimd32(vcpu);}write_sysreg(val, cpacr_el1);write_sysreg(kvm_get_hyp_vector(), vbar_el1);
}static inline void *kvm_get_hyp_vector(void)
{return kern_hyp_va(kvm_ksym_ref(__kvm_hyp_vector));
}
也就是说,将 guest 的异常处理向量表设置为了 host的 __kvm_hyp_vector,那么当 guest 触发中断后会进入 __kvm_hyp_vector,而在这个里面根据之前的流程知道会执行 __guest_exit那么返回到__guest_enter后面的代码,并且通过 __deactivate_traps恢复原来的异常向量表,并且后续流程有local_irq_enable();由于中断实际未被处理,电平信号存在,再次触发中断,此时进入实际的中断处理中处理中断。
那么此时物理中断如何调用到guest虚拟中断的中断处理函数,以 arch timer 为例:
kvm_timer_hyp_init-> err = request_percpu_irq(host_vtimer_irq, kvm_arch_timer_handler,"kvm guest timer", kvm_get_running_vcpus());
kvm_arch_timer_handler-> kvm_timer_update_irq-> kvm_vgic_inject_irq-> vgic_queue_irq_unlock-> list_add_tail(&irq->ap_list, &vcpu->arch.vgic_cpu.ap_list_head);
处理完成后,vcpu 继续运行,进入下一次 vcpu 循环,此时有:
kvm_vgic_flush_hwstate-> vgic_flush_lr_state-> vgic_populate_lr-> vgic_v3_populate_lr-> vcpu->arch.vgic_cpu.vgic_v3.vgic_lr[lr] = val;
将 ap_list 中上的虚拟中断写到 vgic_lr 寄存器context中,并且再次切换回 guest 流程中,此时由于 lr 寄存器写入了中断信息,gic 会确保使 virq 中断线触发,guest将实际触发该中断,并开始guest的中断处理。
除了硬件中断触发上述流程以外,host 还可以主动向 LR 注入虚拟中断。这种用于模拟设备的触发中断,以及 vcpu 之间发送 ipi 中断。
另一方面,由 guest 发起的配置 cpu interface,分发器,重分发器流程:
GICv3 只实现了 cpu interface 虚拟化,那么 guest 配置 cpu interface,可以直接配置,但是GICv3没有实现分发器和重分发器的虚拟化,所以需要 host 来实现 分发器和重分发器的模拟,当 guest 访问 GICv3的分发器和重分发器时将会触发 IO 异常并返回 host,由host 来执行对应寄存器的模拟工作。
GICv3 只实现 cpu interface 虚拟化理由很简单,cpuinetface 直接和 cpu 硬件模块连接,cpu 可以直接通过 msr,mrs 访问系统寄存器,可以加快 cpu interface 寄存器的访问,因此中断触发,cpu 需要频繁访问 GICC_SGRI 相关寄存器来读取中断号,写 EOI 结束中断处理,为了提高性能是有必要去实现虚拟化的,而分发器和重分发器只有在初始化配置时会访问,没有必要去实现虚拟化。
arm64 kvm中vgic 分发器和重分发器,lr寄存器组件的模拟实现
分发器:
分发器和重分发器的虚拟设备模拟在内核中实现,但是 io 基地址(分发器,重分发器基地址),中断数量需要用户空间配置,因此也是通过匿名inode来实现控制这些配置的。
路径在 vm ioctl 的 kvm_ioctl_create_device中。
static int kvm_ioctl_create_device(struct kvm *kvm,struct kvm_create_device *cd)
{struct kvm_device_ops *ops = NULL;struct kvm_device *dev;bool test = cd->flags & KVM_CREATE_DEVICE_TEST;int ret;if (cd->type >= ARRAY_SIZE(kvm_device_ops_table))return -ENODEV;ops = kvm_device_ops_table[cd->type];if (ops == NULL)return -ENODEV;if (test)return 0;dev = kzalloc(sizeof(*dev), GFP_KERNEL);if (!dev)return -ENOMEM;dev->ops = ops;dev->kvm = kvm;mutex_lock(&kvm->lock);ret = ops->create(dev, cd->type);if (ret < 0) {mutex_unlock(&kvm->lock);kfree(dev);return ret;}list_add(&dev->vm_node, &kvm->devices);mutex_unlock(&kvm->lock);if (ops->init)ops->init(dev);kvm_get_kvm(kvm);ret = anon_inode_getfd(ops->name, &kvm_device_fops, dev, O_RDWR | O_CLOEXEC);if (ret < 0) {kvm_put_kvm(kvm);mutex_lock(&kvm->lock);list_del(&dev->vm_node);mutex_unlock(&kvm->lock);ops->destroy(dev);return ret;}cd->fd = ret;return 0;
}
主要根据 kvm_device_ops_table 来决定是创建哪一类设备,有如下设备可用:
enum kvm_device_type {KVM_DEV_TYPE_FSL_MPIC_20 = 1,
#define KVM_DEV_TYPE_FSL_MPIC_20 KVM_DEV_TYPE_FSL_MPIC_20KVM_DEV_TYPE_FSL_MPIC_42,
#define KVM_DEV_TYPE_FSL_MPIC_42 KVM_DEV_TYPE_FSL_MPIC_42KVM_DEV_TYPE_XICS,
#define KVM_DEV_TYPE_XICS KVM_DEV_TYPE_XICSKVM_DEV_TYPE_VFIO,
#define KVM_DEV_TYPE_VFIO KVM_DEV_TYPE_VFIOKVM_DEV_TYPE_ARM_VGIC_V2,
#define KVM_DEV_TYPE_ARM_VGIC_V2 KVM_DEV_TYPE_ARM_VGIC_V2KVM_DEV_TYPE_FLIC,
#define KVM_DEV_TYPE_FLIC KVM_DEV_TYPE_FLICKVM_DEV_TYPE_ARM_VGIC_V3,
#define KVM_DEV_TYPE_ARM_VGIC_V3 KVM_DEV_TYPE_ARM_VGIC_V3KVM_DEV_TYPE_ARM_VGIC_ITS,
#define KVM_DEV_TYPE_ARM_VGIC_ITS KVM_DEV_TYPE_ARM_VGIC_ITSKVM_DEV_TYPE_MAX,
};
当我们创建 gicv3 设备时,kvm_arm_vgic_v3_ops回调将被调用:
struct kvm_device_ops kvm_arm_vgic_v3_ops = {.name = "kvm-arm-vgic-v3",.create = vgic_create,.destroy = vgic_destroy,.set_attr = vgic_v3_set_attr,.get_attr = vgic_v3_get_attr,.has_attr = vgic_v3_has_attr,
};vgic_v3_set_attr-> vgic_set_common_attr
static int vgic_set_common_attr(struct kvm_device *dev,struct kvm_device_attr *attr)
{int r;switch (attr->group) {case KVM_DEV_ARM_VGIC_GRP_ADDR: {u64 __user *uaddr = (u64 __user *)(long)attr->addr;
...case KVM_DEV_ARM_VGIC_GRP_NR_IRQS: {u32 __user *uaddr = (u32 __user *)(long)attr->addr;
...case KVM_DEV_ARM_VGIC_GRP_CTRL: {
...}return -ENXIO;
}vgic_v3_set_attr可以配置分发器的基地址,支持的中断数量,初始化分发器。
分发器配置完成后,还需要将其对应抽象的 io设备和 io region 注册到上面提到的 kvm_bus 总线管理中,用于实际的 guest 访问设备模拟设备操作,这个会在首次运行 vcpu 时被调用:
kvm_arch_vcpu_ioctl_run-> kvm_vcpu_first_run_init-> kvm_vgic_map_resources-> vgic_v3_map_resources-> vgic_register_dist_iodev
注册包括设置 io region 的模拟函数,设置 region 数量。
而对应的 vgic_v3_dist_registers数组有如下寄存器注册进去:
static const struct vgic_register_region vgic_v3_dist_registers[] = {REGISTER_DESC_WITH_LENGTH_UACCESS(GICD_CTLR,vgic_mmio_read_v3_misc, vgic_mmio_write_v3_misc,NULL, vgic_mmio_uaccess_write_v3_misc,16, VGIC_ACCESS_32bit),REGISTER_DESC_WITH_LENGTH(GICD_STATUSR,vgic_mmio_read_rao, vgic_mmio_write_wi, 4,VGIC_ACCESS_32bit),REGISTER_DESC_WITH_BITS_PER_IRQ_SHARED(GICD_IGROUPR,vgic_mmio_read_group, vgic_mmio_write_group, NULL, NULL, 1,VGIC_ACCESS_32bit),
...
...
};
完成注册后,那么guest就可以访问分发器器并操作了。比如guest访问GICD_CTLR寄存器时将会最终在host调用到vgic_mmio_read_v3_misc或者vgic_mmio_write_v3_misc,并返回对应结果。
重分发器:
重分发器和分发器类似不重复说明
list register:
该流程比较简单,不需要用户配置,只需要在kvm初始化流程中初始化即可:
kvm_arch_init-> init_subsystems-> _kvm_arch_hardware_enable-> cpu_hyp_reinit-> kvm_vgic_init_cpu_hardware-> kvm_call_hyp(__vgic_v3_init_lrs);void __hyp_text __vgic_v3_init_lrs(void)
{int max_lr_idx = vtr_to_max_lr_idx(read_gicreg(ICH_VTR_EL2));int i;for (i = 0; i <= max_lr_idx; i++)__gic_v3_set_lr(0, i);
}
可以看到首先从 GICv3 获取到 lr 的数量,并且依次将其全部初始化为 0。
中断注入
spi 和 ppi 中断注入流程一致的,sgi 稍微不同。
kvm 包含三种虚拟中断注入形式:
(1)与实际硬件中断绑定的虚拟中断
(2)由模拟设备产生的中断
(3)vcpu 之间发送的 ipi 中断
为了管理这些虚拟中断,每个 vcpu 结构体都有一个 ap_list 链表。该链表表示已经被注入到特定 vcpu 中,单尚未写到 list register 中的虚拟中断,ap 表示 active 和 pending。
硬件中断注入
上面已经演示
模拟设备的中断注入
模拟中断注入通过 irqfd 实现(基于evnetfd),因此要模拟中断注入需要先建立 eventfd,再创建irqfd:
kvm_vm_ioctl-> kvm_ioeventfd-> kvm_assign_ioeventfd-> ioeventfd_ops// 用户态注入中断
ioeventfd_ops-> ioeventfd_write-> eventfd_signal// 唤醒 irqfd 对应的工作队列完成中断注入-> wake_up_locked_poll
ipi 注入
这个最简单,host 只需要捕获到 guest 写 gicv3的ipi寄存器异常,然后在host完成 vcpu 注入即可。
7 arm64 timer 虚拟化
主要是在进入和退出 vcpu 时恢复和保存 vcntl 相关的寄存器数据,比较简单跳过。