👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

👀 Perplexity 官宣 7360 万美元B轮融资,打造世界上最快最准确的答案平台

https://blog.perplexity.ai/blog/perplexity-raises-series-b-funding-round
补充一份背景:Perplexity 是目前首屈一指的AI搜索引擎,引入了 OpenAI GPT、Anthropic Claude 等最先进的大模型。不同于传统搜索引擎的结果列表,用户使用 Perplexity 时在搜索框中输入问题,可以直接获得结构化的答案,包括来源链接、明确答案和相关问题等
1月4日,Perplexity 官方发推宣布完成B轮融资,加上去年的A轮融资,Perplexity 目前融资金额已经超过1亿美元。本轮投资人团队可谓星光熠熠:IVP领投 (也是种子轮和A轮投资者),NVIDIA、NEA、Bessemer、Elad Gil、Jeff Bezos、Nat Friedman、Databricks、Tobi Lutke、Guillermo Rauch、Naval Ravikant、Balaji Srinivasan、Factorial Funds、Kindred Ventures、DVC、Austen Allred 和 Erik Torenberg 参与投资。
此外,Perplexity 还在其官方博文 (👆 链接) 中分享了一些关键里程碑数据:
月活用户超过 1000 万
2023年服务查询次数超过 5 亿
移动应用程序安装人数超过 100 万

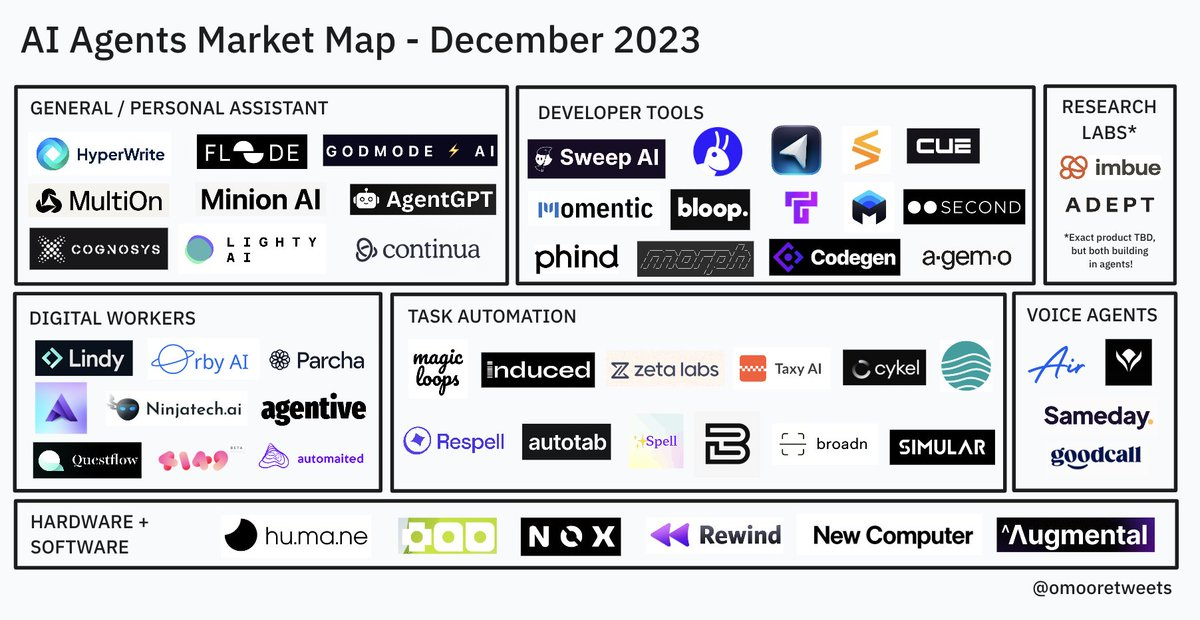
👀 a16z | Olivia Moore 商业洞察:AI Agents 发展现状与行业地图
https://twitter.com/omooretweets/status/1740774601876177375
补充一份背景:Olivia Moore 是 a16z 的消费领域合伙人;a16z (Andreessen Horowitz) 是科技行业的知名风险投资公司,以早期敏感和成长期果断著称,在全球科技行业中具有重要影响力
2023年12月30日,Olivia Moore 在 X 平台分享了她整理的 AI Agent 行业地图 & 追踪的60家 Agent 产品清单。
什么是AI Agent
Agents 是跨系统工作并为用户执行任务的 bots
原文:I define agents as bots that work across systems to EXECUTE tasks for users.
AI Agent 发展历程
开始,Auto-GPT 项目在 GitHub 爆火,一个月内就收获了 50K+ Star,将 Agent 这个概念带入大众视野
随后,BabyAGI、AgentGPT、Godmode 等项目先后问世
这催生了大量的 Agent 产品,其中先行者包括 HyperWriteAI 、 MultiON_AI 、 Minion AI、 lindy.ai 等
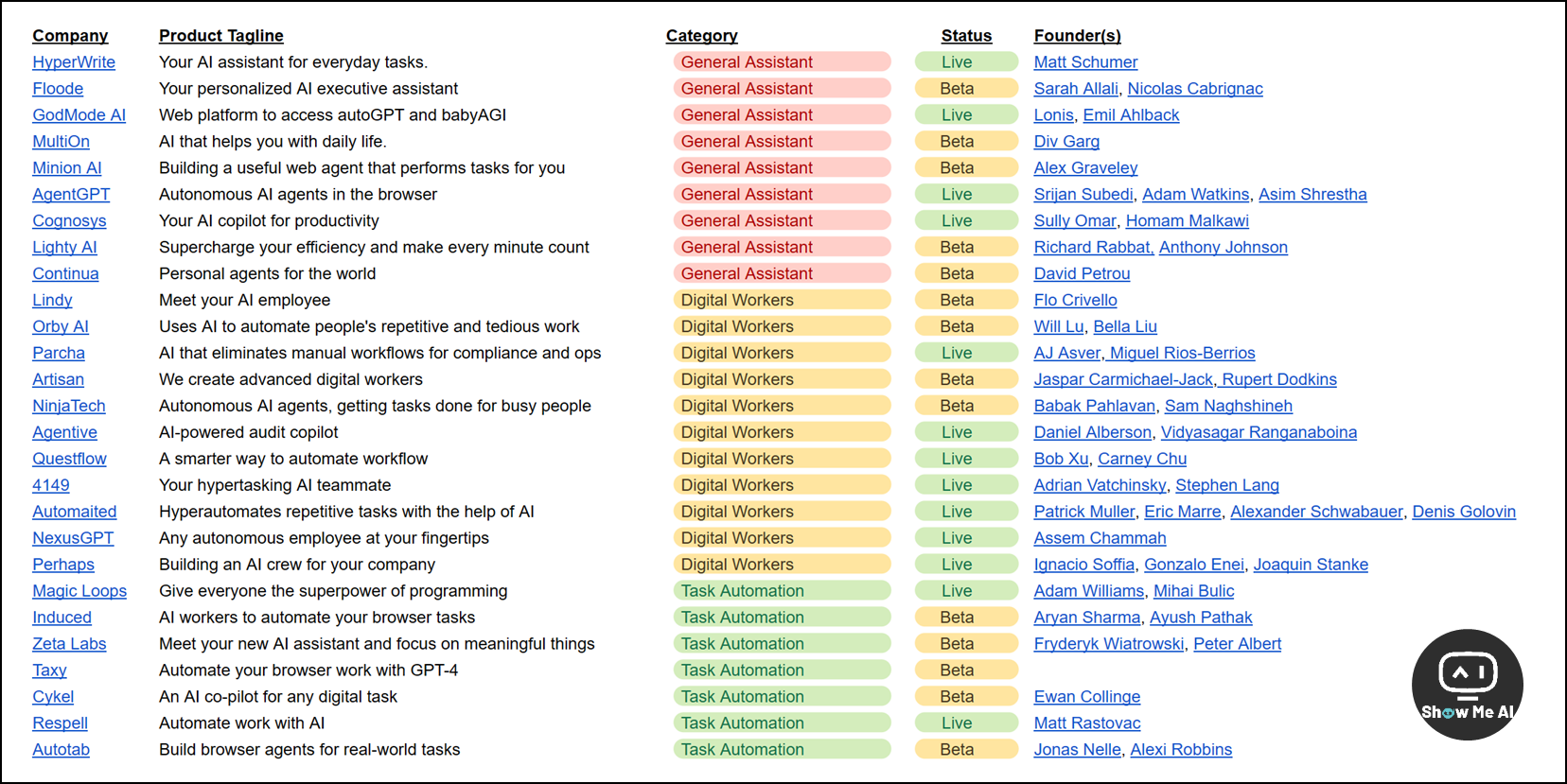
https://docs.google.com/spreadsheets/d/1QeCDcZzgaf6_2jSqyDLYmdB_0JpQsBTfuAhUnk3o250
2023年,大多数 Agent 产品在黑客松中被创建和展示,但多数处于 Demo 阶段或 Beta 测试阶段。但是,2024年这一情况将会有很大改变,产品发布和升级会更加频繁。
Olivia Moore 分享了她正在追踪的60个 Agent 产品清单 (👆 链接),并划分为8类。果断收藏!! 快速跟上 Agent 这个 2024 年的大热门~
HyperWrite:https://www.hyperwriteai.com/personal-assistant
Floode:https://floodehq.com
GodModeAI:https://godmode.space
MultiOn:https://www.multion.ai
MinionAI:https://minion.ai
AgentGPT:https://agentgpt.reworkd.ai
Cognosys:https://www.cognosys.ai
LightyAI:https://www.lighty.ai
Continua:https://www.continua.ai
Lindy:https://www.lindy.ai
OrbyAI:https://www.orby.ai
Parcha:https://www.parcha.ai
Artisan:https://artisan.co
NinjaTech:https://www.ninjatech.ai
Agentive:https://www.goagentive.com
Questflow:https://www.questflow.ai
4149:https://4149.ai
Automaited:https://www.automaited.com
NexusGPT:https://gpt.nexus
Perhaps:https://www.getperhaps.com
MagicLoops:https://magicloops.dev
Induced:https://www.induced.ai
ZetaLabs:https://www.zetalabs.ai
Taxy:https://taxy.ai
Cykel:https://www.cykel.ai
Respell:https://www.respell.ai
Autotab:https://www.autotab.com
Spell:https://spell.so
BreakTrue:https://breaktrue.ai
Broadn:https://www.broadn.io
Simular:https://www.simular.ai
Lutra:https://lutra.ai
Air:https://www.air.ai
Sindarin:https://www.sindarin.tech
Sameday:https://www.gosameday.com
Goodcall:https://goodcall.com
SweepAI:https://sweep.dev
Grit:https://www.grit.io
Cursor:https://cursor.sh
CodeStory:https://codestory.ai
Cue:https://www.getcue.ai
Momentic:https://momentic.ai
Bloop:https://bloop.ai
Tusk:https://usetusk.ai
Mutable:https://mutable.ai
Second:https://www.second.dev
Phind:https://phind.com
Morph:https://morph.so
Codegen:https://www.codegen.com
Agemo:https://agemo.ai
Imbue:https://imbue.com
Adept:https://www.adept.ai
Humane:https://hu.ma.ne
Tab:https://mytab.ai
Nox:https://www.noxdevices.com
Rewind:https://www.rewind.ai
NewComputer:https://new.computer
Augmental:https://www.augmental.tech
Wispr:https://www.wispr.ai
Claros:https://www.claros.so
🉑 大厂技术解决方案 | 网易云音乐 AI Agent 探索实践

本篇文章介绍了大语言模型时代下的 AI Agent 概念,并且以 LangChain 为例详细介绍了 AI Agent 背后的实现原理,随后展开介绍了网易云音乐在实践 AI Agent 过程中的遇到的问题及优化手段。
阅读本篇文章,除了可以掌握业界主流的 AI Agent 实现原理及实践优化手段,还能够了解自研 AI Agent 技术以及理解 Open AI 最新提出的 Assistants API~
一. 前言
二. AI Agent 简介:AI Agent 是指使用大语言模型作为推理引擎、自主进行任务规划和执行调度的智能代理,用于辅助编程、个人助理等场景
三. 如何来构建 AI Agent:通过官方示例,展示使用 LangChain 框架构架 Agent 的详细操作步骤
四. 云音乐 Adora 平台在 Agent 方面的实践:将 Adora 平台的服务转换为 LangChain 的 Tools,并且通过可视化界面构建 Agent 智能体 (Adora 是网易云音乐内部的智能数字助理搭建平台,提供了LLM相关服务和配置中心)
五. 总结:Assistants API 的封装 与 LangChain Agent 有许多共通之处
网易云音乐的技术团队,分享了其详细的探索过程和优化方案,非常不错!!把要点整理列写如下,感兴趣推荐阅读完整全文:
三. 如何来构建 AI Agent
3.1 LangChain Agent 使用示例
通过一个官方示例来展示,如何使用 LangChain 框架来增强大语言模型的数学运算能力
示例:用户询问5到10之间随机数的平方,LangChain Agent 通过调用大语言模型和内置的计算器工具来完成任务
3.2 LangChain Agent 执行步骤拆解
执行步骤一:Agent 首先调用大语言模型,将用户输入与系统提示结合,大语言模型建议使用随机数生成工具
执行步骤二:Agent调用随机数生成器工具,生成一个随机数
执行步骤三:再次调用大语言模型,将随机数和工具调用结果传递给它,以继续思考
执行步骤四:调用计算器工具,计算随机数的平方
执行步骤五:最后再次调用大语言模型,将所有信息整合,得出最终结果
3.3 LangChain Agent 的魔法咒语 (指令序列)
LangChain Agent 背后的运行原理,即通过一系列预设的指令序列来指导大语言模型如何使用工具和执行任务
咒语包括:工具的 JSON Schema 定义、如何使用工具的指示、以及生成内容的结构 (ReAct框架)
四. 云音乐 Adora 平台在 Agent 方面的实践
4.1 基础能力整合
- 如何将 Adora 平台的服务转换为 LangChain 的 Tools,以及如何通过可视化界面构建 Agent 智能体,实现了基础能力的整合
4.2 问题及优化手段
问题1 - 如何高效地调试 Agent:将 Agent 的执行日志进行采集和提炼,以结构化的方式在前端呈现,帮助开发者理解Agent的执行逻辑
问题2 - 如何解决 Agent 执行的异常中断:改写 DynamicStructuredTool 逻辑,当工具入参不符合预期时,不直接抛错,而是给 LLM 返回错误提示,让其继续思考
问题3 - 如何让 Agent 请求用户协助:调整工具描述和系统提示词,确保 LLM 能够正确地向用户提问,并在必要时将控制权交给用户
问题4 - 模型推理能力、响应速度:实践中推理能力更强的模型 (如gpt-4.0-0613) 耗时更长,而响应速度更快的模型 (如gpt-3.5-turbo-0613) 任务完成率较低 ⋙ 阅读原文

👀 a16z | Justine Moore 商业洞察:当AI遇上「约会」

https://twitter.com/venturetwins/status/1730274418432286933
补充一份背景:Justine Moore 也是 a16z 的投资合伙人,并且与上一条的 Olivia Moore 是一对双胞胎姐妹花~
这是 Justine Moore 在12月初在X平台的「AI x Dating」主题分享,并且讨论了人工智能将会为约会产品带来什么样的重大影响。
从最初的报纸分类广告,到约会网站,再到移动端 App,每一轮新的平台都会出现「帮助寻找爱情」的全新产品。那么人工智能将如何重塑约会场景呢?
我们为什么需要新的约会产品
现存的约会类产品,算法设计的核心目的是让用户为更高阶的功能付费,因此不会积极撮合匹配而是让用户一直留在池子里保持单身
因此,现有的约会产品通常起不到什么作用
除了在App上划来划去,我们还有其他选择吗
线下撮合:媒人经过一系列的精心策划,进行线下的配对;但是价格昂贵,超出了大多数人的考虑范围
公开文档:制作一份「与我约会」公开文档是一种流行的线上约会新方式,而且AI可以参与重塑整个 Dating 过程并最终取代现有的所有App
AI+Dating 一些现有应用案例
- 个人简介优化
如何在个人简介中更好地展示自己呢 (比如选择怎样的图片,如何更有趣地描述自己)?之前是公开文档然后获取其他人留下的评价,而AI能让这一过程更加私密&更加智能
RoastD、PhotoAI.me、GlowUp
- 帮助发送信息
会聊天是一项强大的技能;AI可以帮助写一段开场白,还可以提供回复建议避免冷场,对于不善于表达的人来说是非常必要的辅助工具
Rizz 、SwoonChat
- 约会指导教练
如何判断一段关系是否健康呢?遇到矛盾和分析该如何沟通呢?以往我们习惯于截图发给朋友或者社区来寻求建议,而现在AI可以提供更加全面的建议了
Meeno、Maia、Pi
- 快速牵线搭桥
现有的约会应用效率低到让人难以置信;但是AI媒人可以高效加速这一过程:获取你的全部信息、分析其他数百万人的信息,推荐最匹配的约会对象、安排约会、聊天沟通并提供反馈、继续……
KeeperMatch、Snack Dating、Cuffed、Mila
🉑 拾象投研关于 2024 年 LLM 发展的预判:人类跨入新摩尔定律时代

https://www.xiaoyuzhoufm.com/episode/65910adb991e2ee60880f151
补充一份背景:拾象科技 CEO 李广密是一位非常优秀的投资人,也是一位优质的分享者——有着清晰的思考框架,更有密集的内幕和满满的细节~ 不愧是肉身在硅谷沉浸大半年的一线投资者 👍👍👍
我们在之前日报中分享了 拾象创始人李广密播客 和对应的「文字整理版」。社群和社交平台上,大家都表示信息密度非常高!可以完整捕捉到李广密对中美大模型市场的深刻洞察,以及对未来行业布局、发展方向、发展节奏、关键要素等等核心话题的大胆预判。
今天这篇文章可以看作上次播客的「划重点+进阶版」,重新梳理了拾象投研对2024年大语言模型发展的关键。以下是内容要点,同样推荐度拉满。当然,我们还是要有独立思考和判断,不迷信权威,用真实世界的发展来佐证和调整自己的判断框架~
预测1:2024 年上半年是 LLM 军备竞赛关键赛点,格局形成后很难再改变
如果以 GPT-4 作为门槛,首轮模型竞赛已经决出了前三名:OpenAI 、Anthropic 和 Google Gemini;还有另外 3 家公司具备这个潜力:Character.AI、X.ai 和 Bytedance
头部开源模型的能力会长期保持着与最好模型半代到一代的差距,但开源模型的使命是帮助模型能力商品化
2024年上半年是大模型最后的决赛窗口,模型能力的提升将非常迅速
模型公司的融资和估值几乎全由科技巨头定价和主导,独立IPO难度大,被收购的可能性更高
Scaling Law 是目前提升模型智能能力的唯一路径;但 Scaling Law 没有理论支撑,难以准确预测模型能力何时会遇瓶颈
Post-training pipeline 是 OpenAI 最关键的 secret sauce,其他公司要追赶需要建立高效的训练流程
推理能力仍是目前 LLM 持续进步和落地的核心,产品是支线
预测2: 数据短缺问题成为模型 bottleneck,合成数据是关键解法
2024年很多模型会在数据环节遭遇瓶颈,Transformer 结构对数据量的要求非常大
提升合成数据多样性和质量是确保模型训练的关键,但简单的用 GPT-4 生成数据会带有模型自身的缺陷
有两条可能的技术路线:一类是用数学/代码可以进行严格验证的形式语言,让模型生成的数据能够得到自动化地验证;另一类是通过RL强化学习算法,通过 AI feedback 为主 human feedback 为辅的方式进行纠偏和迭代
预测3:2024 年会迎来端侧 LLM hype,会有开源模型团队被硬件厂商收购
2024 年将有开源模型团队被硬件厂商收购,端侧小模型将受到重视
手机、PC、车等硬件厂商有动力收购开源小模型,手机厂商尤为激进
Google 推出的 Gemini 系列模型中的 Nano 是围绕 on-device 需求设计的,将被嵌入 Pixel 8 Pro 并开放给 Android 开发者
预测4:多模态成为 LLM 在 2024 年的主流叙事
多模态理解将成为LLM的主流叙事,图像和视频生成能力将得到显著提升
图像生成、视频生成和3D生成是多模态理解的关键领域,但3D生成可能距离技术临界点更远
预测5:视频生成会在 2024 年迎来「ChatGPT 时刻」
视频生成领域将在 2024 年迎来类似于 ChatGPT 在文本生成领域所取得的突破性进展,预示着视频生成技术将达到一个新的成熟水平
当前视频生成技术主要分为两类:基于扩散模型 (Diffusion-based) 和基于语言模型 (Language Model-based) ;扩散模型目前占据主导地位,但 Transformer-based 的路线因其易于扩展而受到关注,两条技术路线的研究界限正在变得模糊
预测6:新摩尔定律会解锁更多新应用的可能性,LLM-Native App 会在未来6-12个月迎来大规模爆发
新摩尔定律:模型训练成本每18个月除以4,模型推理成本每18个月除以10,模型能力每1-2年提升一代,过程中会逐步解锁新应用
LLM 产品的数据飞轮和网络效应能否成真将揭晓:目前 ChatGPT 并没有像搜索和推荐一样具备很强的数据飞轮效应
新时代产品天才画像会更加清晰:移动时代做过亿级 DAU 产品的产品经理可能并不会自动变成 LLM 时代的好产品经理
改良版 Character.ai 玩家将收敛:2023年市场上有大量公司尝试复制 Character.ai 但进展一般,甚至连 Character.ai 是不是个好故事都不一定
预测7:2024 年,亿级 ARR 产品将批量出现,更多公司 5% 以上的收入贡献将来自 AI
2024年,LLM-Native App 将有望实现亿级 ARR,这标志着 LLM 在商业化应用上的显著进展
随着模型能力的不断提升和更多 AI-naive 产品/ feature 的发布,预计到 2024 年将有更多公司的 5% 以上的收入贡献来自AI相关的新功能、新产品和客户
预测8:2024 是布局 Data Center 的重要时机,算力、Cooling 以及互联等环节均存在机遇
硬件侧竞争加剧,电源短缺问题加剧,网络创新将是关键
NVIDIA 将在推理侧重点宣传 Grace 架构的吞吐量优势,AMD 是 NVIDIA 在高端推理市场的唯一对手
预测9:围绕 LLM 将发生一起具有影响力的网络安全事故
微软在 2023 年经历了几起重大的数据泄露事故,包括 Azure 账户泄露和 AI GitHub 库的意外数据泄露,这表明即使是大型科技公司也面临着网络安全的挑战
随着 LLM 的广泛应用,预计 2024 年将发生一起具有影响力的网络安全事故,这可能会引起对AI安全问题更广泛的关注和讨论
预测10 :具身智能还需 1-2 年才能真正迎来突破
具身智能,即机器人领域的 Embodied AI,虽然在2023年引起了广泛关注,但预计在1-2年内才能看到真正的突破
Google 发布的 PaLM-E 和 RT-2 模型,以及Tesla的人形机器人 Optimus 的进展,都展示了通用人形机器人的可能性;然而由于涉及到软硬件一体化的复杂系统工程,通用机器人的实现需要更多的耐心和时间 ⋙ 阅读原文

🉑 微软「Generative AI for Beginners」课程 · 学习笔记 (中文)

https://app.heptabase.com/w/87c086b90e0b4d1583896a3a43a22fbdca0fd8430117c351e552989454025ad0
即刻@SketchK 分享了ta的微软「Generative AI for Beginners (生成式人工智能入门课)」课程中文版学习笔记!内容要点和逻辑架构很清晰,超级酷!访问 👆 这个链接就可以放大查看详细内容啦!以上是整体截图展示。

https://microsoft.github.io/generative-ai-for-beginners/
微软推出的「Generative AI for Beginners (生成式人工智能入门课)」课程,一共12小节,每节课包含「视频介绍 + 图文讲解 + 示例代码 + 课程作业 + 更多资源链接」,是学习生成式人工智能基础知识和应用开发技能的首选入门课~以下是课程大纲与课程核心内容的介绍,有感兴趣的内容,可以访问 👆 上方链接开始学习啦:
课程介绍:基础设置和课程结构
生成式人工智能和大语言模型 (LLMs) 介绍:理解概念、发展现状和工作原理
探索和比较不同的 LLMs:测试、迭代和比较不同的大语言模型,为应用场景选择正确的模型
负责任地使用生成式人工智能:理解基础模型的局限性和人工智能背后的风险
理解提示工程基础:提示工程最佳实践的实践应用,理解提示词的结构和用法
创建高级提示:尝试不同的提示词技巧,使用提示工程技术提高提生成结果的质量
构建文本生成应用:使用 Azure OpenAI 构建文本生成应用,使用token和温度来控制模型的输出
构建聊天应用:构建和集成聊天应用,识别关键指标
构建搜索应用向量数据库:了解语义搜索与关键词搜索,了解文本嵌入以及它们如何应用于搜索
构建图像生成应用:了解图像生成及其用途,构建一个图像生成的应用
构建低代码AI应用:使用低代码为教育初创公司构建一个学生作业追踪器
通过函数调用集成外部应用:了解函数调用是什么以及如何使用,设置一个函数调用并从外部API检索数据
设计AI应用的用户体验 (UX):了解开发生成式人工智能应用时的应用用户体验设计原则
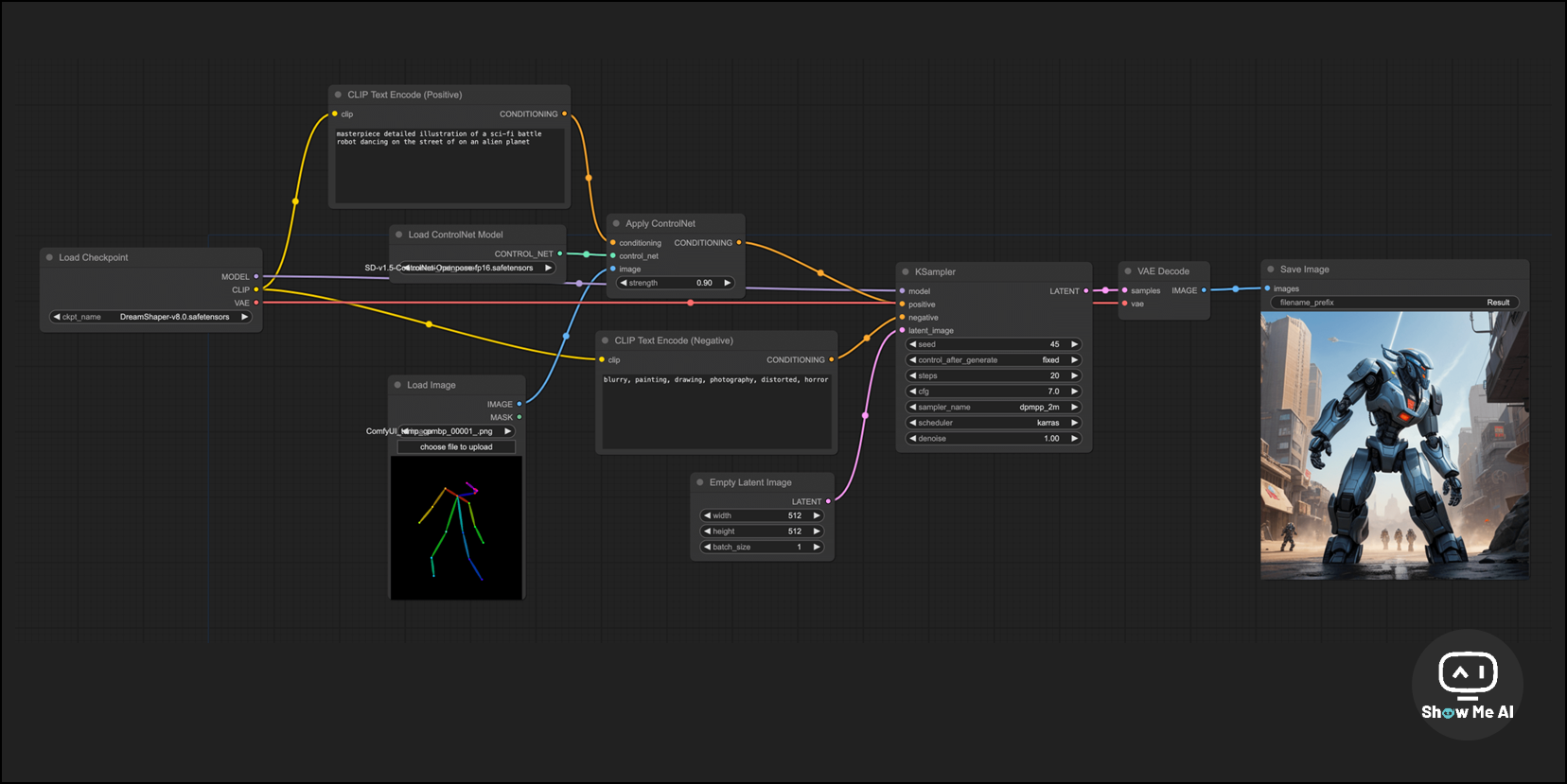
🉑 面向新手的 ComfyUI 中文教程,掌握更高级的AI图像生成工作流
https://www.comflowy.com/zh-CN
补充一份背景:ComfyUI 是一个基于节点流程的 Stable Diffusion 图形用户界面和后台,可以使用图形/节点/流程图的界面设计和执行高级 Stable Diffusion 管道,通过将不同节点连接在一起来构建图像生成的工作流
这是一份面向新手的 ComfyUI 中文教程,旨在帮助大家快速上手 ComfyUI,以及了解 Stable Diffusion 模型和 ComfyUI 的基本原理。教程总共分为四个部分:
学习前的准备
安装 ComfyUI
下载 & 导入模型
选修:安装插件、云端安装
基础篇:介绍 ComfyUI 的基本使用方法以及 Stable Diffusion 模型的基本原理,使用 ComfyUI 搭建基础的 Stable Diffusion 并使用文生图的方式输出各种各样的图
Stable Diffusion 基础
ComfyUI 基础
ComfyUI 基础
SD Prompt 基础
Embedding
LoRA
基础选修:模型推荐、Prompt 进阶、LoRA 推荐
中级篇:介绍更多方法提升图片分辨率、修改生成图片的部分内容、加强对生成过程的控制等,能够相对精准地控制模型的输出
图生图
Upscale
In/Outpainting
ControlNet
中级选修:SD 进阶、图生图进阶、Upscale 进阶、ContorlNet 进阶
高级篇 (更新中):综合初中级学到的内容,做出更复杂的图片以及学会文生视频相关的操作,能够从容生成满意的图片以及视频
Model Merging
Text2Video
🉑 图解 RAG 技术与算法,一文完全搞定 RAG 原理与实践

https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
补充一份背景:RAG (Retrieval-Augmented Generation,检索增强生成) 为 LLM 提供从某些数据源检索到的信息,来提高文本生成任任务的效率和质量
RAG = Search + LLM prompting,可以看作是搜索+大语言模型的结合
RAG是2022年后最流行的大语言模型系统架构之一,有很多产品都是基于RAG构建的。LangChain 和 LlamaIndex 是两个流行的开源 RAG 库。
这篇文章厉害了!用图示的形式非常完整地介绍了 RAG 技术原理,并提供了完备的进阶资源链接,包括研究、实践、教程等等,可以帮助开发者更深入地了解 RAG 技术。
🔔 基础 RAG 图解

RAG技术的基本概念和基本实现步骤:RAG流程的起点是一系列被用作信息检索来源的文本文档;然后将文本分割成有意义的文本块 (chunks) 并使用某种 Transformer 模型来嵌入这些块,将它们转换成向量;创建一个索引来存储向量化的内容;最后为LLM创建提示词,基于 LLM 检索到的上下文来回答用户查询
更多学习资源:RAG入门知识,包括如何准备数据、选择模型以及构建搜索索引等
🔔 高级 RAG 技术图解
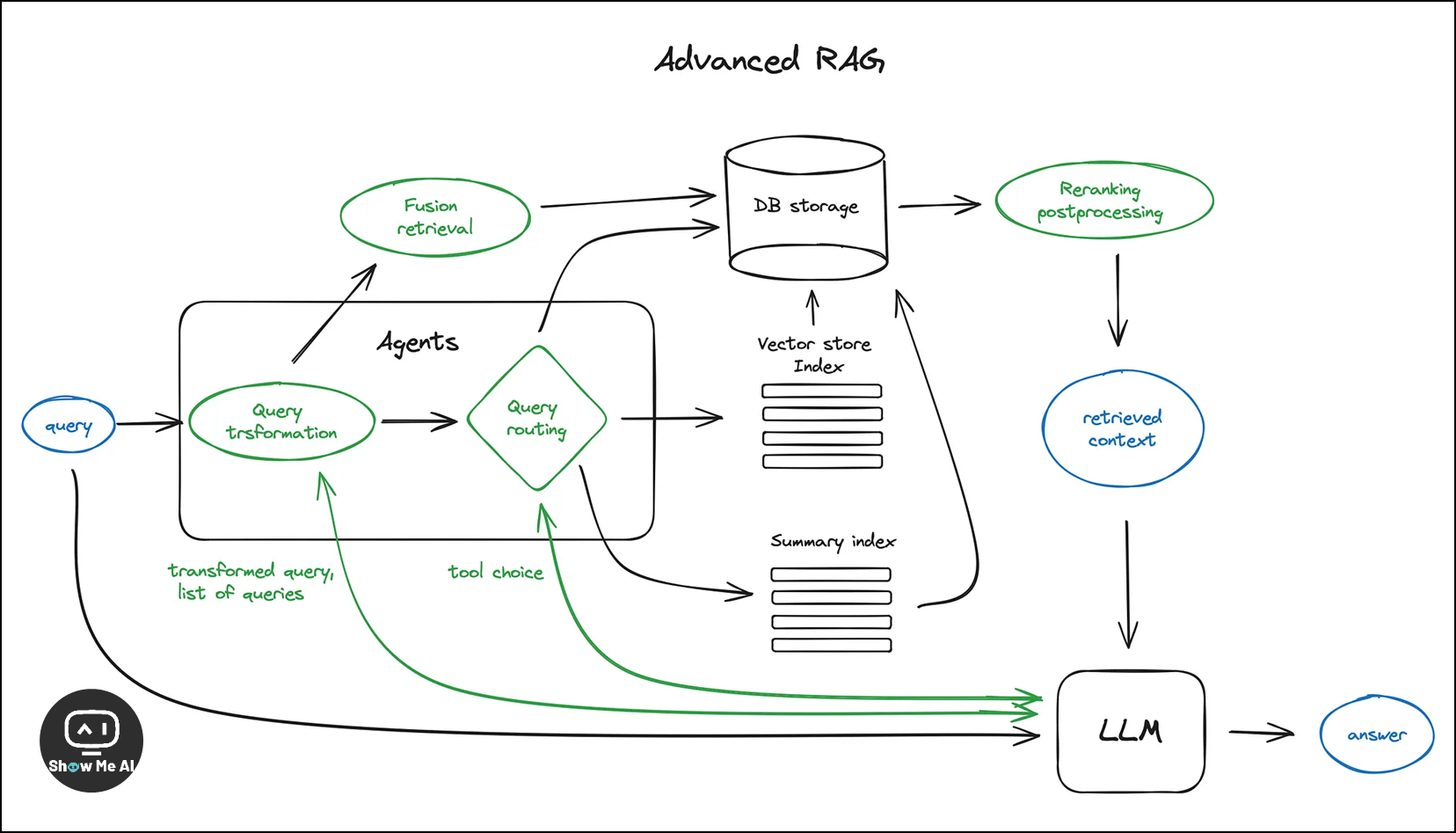
- Chunking & vectorisation / 块分割与向量化:
1.1 Chunking:强调了将文本分割成有意义的块的重要性,以保持其语义完整性;块的大小是一个需要考虑的参数,因为它影响搜索效率和文本嵌入的准确性
1.2 Vectorisation:选择一个模型来嵌入这些块,如搜索优化的模型;在 LlamaIndex 中 NodeParser 类提供了高级选项来处理文本分割和向量化
- Search index / 搜索索引
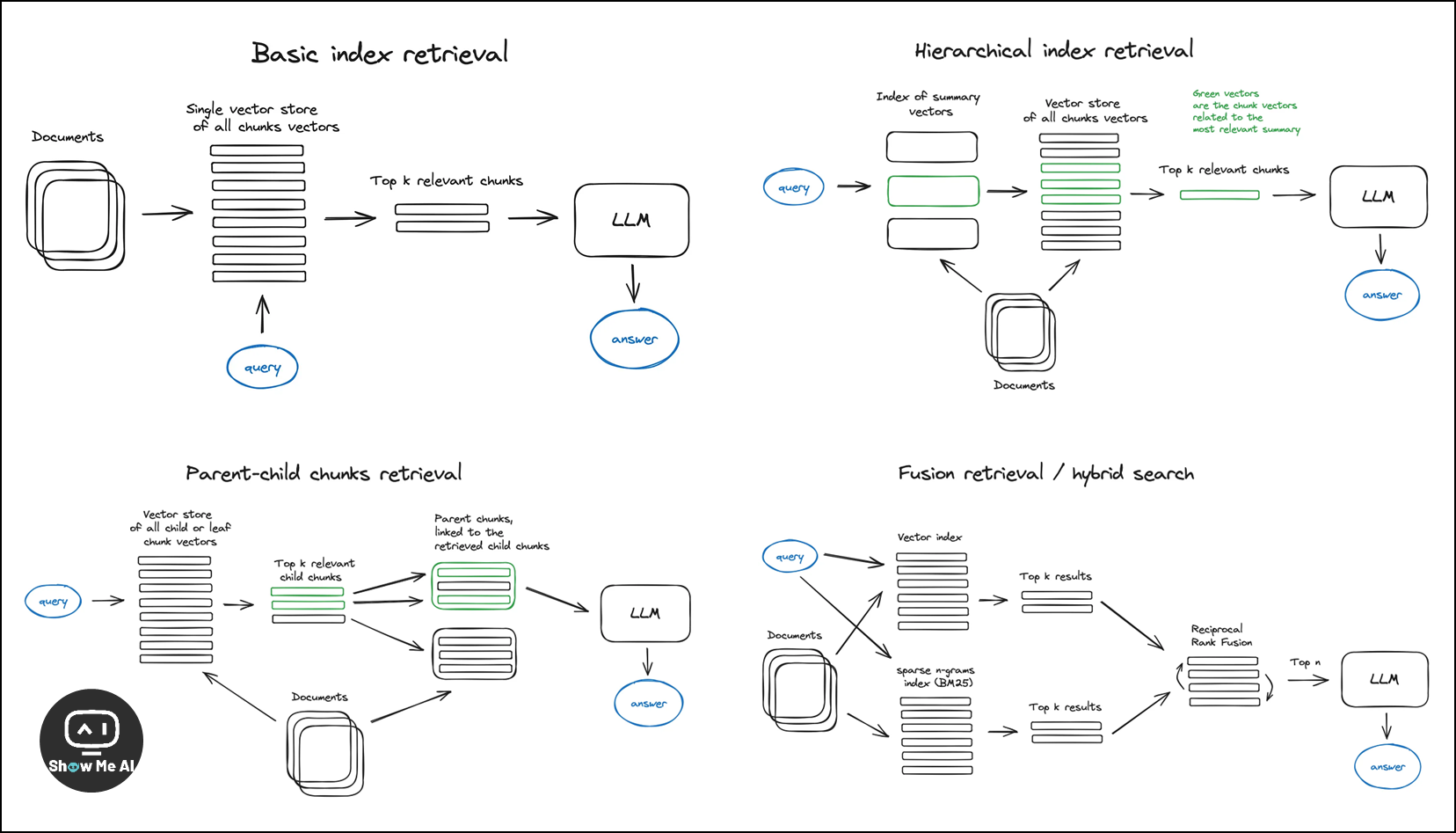
2.1 Vector store index / 向量存储索引:介绍了使用向量索引来存储向量化的内容,以及如何使用高效的向量索引算法如faiss、nmslib或annoy来优化检索
2.2 Hierarchical indices / 分层索引:提出了创建两个索引的方法,一个由摘要组成,另一个由文档块组成,以便在大量文档中高效检索
2.3 Hypothetical Questions and HyDE / 假设问题和HyDE:讨论了让LLM为每个块生成问题并嵌入这些问题向量的方法,以提高搜索质量
2.4 Context enrichment / 上下文丰富:解释了如何通过扩展检索到的较小块的上下文来提高搜索质量,可以通过扩展句子窗口或递归地将文档分割成更大的父块和较小的子块
2.5 Fusion retrieval or hybrid search / 融合检索或混合搜索:结合了基于关键词的传统搜索算法和现代的语义或向量搜索,以提高检索结果

Reranking & filtering / 重排名与过滤:通过过滤、重排名或对检索结果进行某些转换来精炼检索结果;在LlamaIndex中,有多种可用的Postprocessors,可以根据相似度得分、关键词、元数据或使用其他模型如LLM进行重排名
Query transformations / 查询转换:使用 LLM 作为推理引擎来修改用户输入以提高检索质量;将复杂查询分解为子查询、使用LLM生成更一般的查询以及重写查询以改进检索
Chat Engine / 聊天引擎:构建一个能够处理对话上下文的 RAG 系统,以支持后续问题、指代消解或与先前对话上下文相关的任意用户命令
Query Routing / 查询路由:LLM 根据用户查询做出决策,选择是进行总结、搜索数据索引还是尝试不同的路径,并将输出合成为单个答案
Agents in RAG / RAG 中的代理:代理是具有推理能力的 LLM,配备有一组工具和要完成的任务;在RAG中使用代理的多文档代理方案,其中每个文档代理都有工具,以及顶层代理负责查询路由和最终答案合成
Response synthesizer / 响应合成器:基于所有精心检索到的上下文和初始用户查询生成答案,常见的响应合成方法包括迭代精炼答案、总结检索到的上下文以及生成多个答案并进行拼接或总结
🔔 More
Encoder and LLM fine-tuning
Encoder fine-tuning:对编码器进行微调以提高嵌入质量,从而提高上下文检索质量的可能性
Ranker fine-tuning:使用交叉编码器对检索结果进行重排名
LLM fine-tuning:OpenAI 最近提供 LLM 微调 API,以及在 RAG 设置中微调 GPT-3.5-turbo 以「蒸馏」GPT-4 知识;Meta AI Research 提出了 RA-DIT,这是一种调整 LLM 和检索器 (即双编码器) 的方法,用于在查询、上下文和答案的三元组上进行微调
Evaluation
在 RAG 系统的评估中,会考虑答案的相关性、答案基于上下文的忠实度、检索上下文的相关性等指标;关键且最可控的指标是检索上下文的相关性
OpenAI cookbook 中展示了一个稍微高级的方法,不仅考虑命中率,还考虑了平均倒数排名 (Mean Reciprocal Rank)
LangChain 拥有一个相先进的评估框架 LangSmith,可以在其中实现自定义评估器
LlamaIndex 有一个 rag_evaluator llama pack 快速工具,可以用公共数据集评估流程
Conclusion
提到了其他需要考虑的因素,如基于 Web 搜索的 RAG (例如LlamaIndex的RAGs和webLangChain) ,深入研究代理架构 (包括OpenAI在这方面的最新投入) ,以及关于 LLMs 长期记忆的一些想法
看好小型 LLMs 的未来,最近发布的 Mixtral 和 Phi-2 模型正引领着这一方向
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!