19.1 时间同步的必要性
对于一些服务来说对时间要求非常严格,例如,图19-1所示由三台服务器搭建的ceph集群。

图19-1 三台机器搭建的集群对时间要求比较高
这三台服务器的时间必须要保持一样,如果不一样,就会显示报警信息。那么,如何能让这三台机器的时间保持一致?手动调整时间的方式肯定不行,因为手动调整时间最多只能精确到分,很难精确到秒。而且即使现在时间调整一致了,过一段时间之后,时间又可能又不一样了。
所以,需要设置这些服务器的时间能够自动去同步,如图19-2所示。
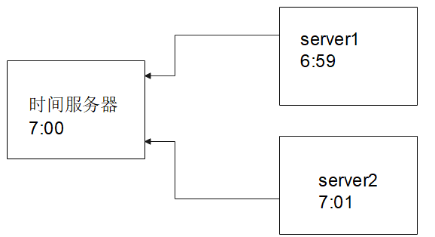
图19-2 通过时间服务器进行时间同步
这里假设我们有一个时间服务器时间为7:00,server1和server2设置好向此时间服务器进行时间的同步。
假设server1当前时间为6:59,它跟时间服务器一对比,“我的时间比时间服务器慢了一分钟”,然后它主板上的晶体芯片就会跳动得快一些,很快就“追”上了时间服务器的时间。
假设server2当前时间是7:01,它跟时间服务器一对比,“我竟然比时间服务器快了一分钟”,然后它主板上的晶体芯片就会跳动的慢一些,“等着”时间服务器。
下面就开始使用chrony来配置时间服务器。
19.2 配置时间服务器
拓扑图如图19-3所示。
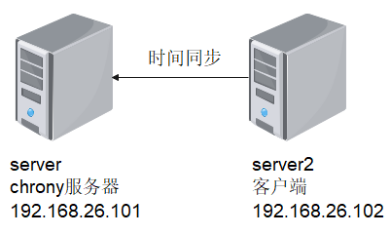
图19-3 本章实验拓扑图
这里把server配置成时间服务器,server2作为客户端向server1进行时间同步。
在安装系统时,如果已经选择了图形化界面,默认已经把chrony这个软件安装上了(如果没有安装,请先看后面软件包管理章节之后,然后自行安装上去)。
使用vim编辑打开/etc/chrony.conf,只修改我们能用的几行。
(1)指定所使用的上层时间服务器
pool 2.rhel.pool.ntp.org iburst修改为pool 127.127.1.0 iburst
pool后面跟的是时间服务器,因为这里把server作为chrony服务器,没有上一层的服务器,所以上层服务器设置为本地时钟的IP:127.127.1.0。
这里iburst的意思是如果chrony服务器出问题时,客户端会发送一系列的包给 chrony服务器对服务器进行检测。
(2)指定允许访问的客户端
修改allow所在行,把注释符#去掉,并把后面的网段改为192.168.26.0/24。
把
#allow 192.168.0.0/16
改成
allow 192.168.26.0/24
server配置成时间服务器之后,只允许192.168.26.0/24网段的客户端进行时间同步。如果要允许所有客户端都能向此时间服务器进行时间同步,可以写成allow 0/0 或allow all。
(3)把local stratum前的注释符#去掉。
把#local stratum 10 变为local stratum 10
这行的意思是即使服务器本身没有和时间服务器保持时间同步,那么也可以对外提供时间服务,这行注释要取消。
保存退出,去除空白行和注释行之后,最后修改之后的代码如下,黑体字是修改的内容。
[root@server ~]# egrep -v '#|^$' /etc/chrony.conf
pool 127.127.1.0 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 192.168.26.0/24
local stratum 10
keyfile /etc/chrony.keys
leapsectz right/UTC
logdir /var/log/chrony
[root@server ~]#
然后重启chronyd这个服务(注,这里是chronyd不是chrony),并设置开机自动启动,命令如下。
[root@server ~]# systemctl restart chronyd
[root@server ~]# systemctl enable chronyd
[root@server ~]#
chrony用的是UDP的123和323,命令如下。
[root@server ~]# netstat -nutlp | grep chronyd
udp 0 0 0.0.0.0:123 0.0.0.0:* 408855/chronyd
udp 0 0 127.0.0.1:323 0.0.0.0:* 408855/chronyd
udp6 0 0 ::1:323 :::* 408855/chronyd
[root@server ~]#
在防火墙中把这两个端口开放,命令如下。
[root@server ~]# firewall-cmd --add-port=123/udp --permanent
success
[root@server ~]# firewall-cmd --add-port=323/udp --permanent
success
[root@server ~]# firewall-cmd --reload
success
[root@server ~]#
这里加上选项–permanent的目的是让其永久生效,然后通过reload重新加载防火墙规则,让其立马也生效。具体防火墙的设置后面有专门章节讲解。
至此,用chrony搭建的时间服务器完成。
19.3 配置chrony客户端
把server2配置成时间服务器的客户端,也就是chrony客户端。
在server2(IP为192.168.26.102)上用vim编辑器修改/etc/chrony.conf ,修改下面的几行。
(1)修改pool那行,指定要从哪台时间服务器同步时间。
由原来的pool 2.rhel.pool.ntp.org iburst
改为 pool 192.168.26.101 iburst
这里指定时间服务器为192.168.26.101,即向192.168.26.101进行同步时间
(2)修改makestep那行,格式如下。
makestep 阈值 limit
客户端向服务器同步时间有两种方式:step和slew。
step:跳跃着更新时间,如时间由1点直接跳到7点。
slew:平滑着移动时间,晶体芯片跳动的快一些,就好比秒针的转速"快镜头"一般。
如果客户端和服务器时间相差较多,则通过step的方式更新,如果客户端和服务器相时间差不多,则通过slew平滑的方式更新时间。那么,时间相差多或不多的标准是什么呢?就要看时间差是否超过makestep后面的阈值了。
举个例子,makestep 10 3的意思是如果本机和时间服务器的时间相差10s以上,就认为客户端和服务器的时间相差较多,则前三次更新用step的方式来更新。客户端通过这种方式会更新地很快,有些应用程序因为时间的突然跳动,会带来问题。
如果客户端和服务器的时间相差低于10s以内,就认为两者时间相差不多,就通过slew的方式,这种方式更新的速度会比较慢,但比较平稳。
把原来的makestep 1.0 3 改成:makestep 200 3
如果客户端和时间服务器的时间相差200s以上,则认为时间相差较多,此时会通过step的方式进行调整时间。
保存退出,并重启chronyd服务,命令如下。
[root@server2 ~]# systemctl restart chronyd
[root@server2 ~]# systemctl enable chronyd
[root@server2 ~]#
为了更细致地看到两台机器的时间差,先配置从server2可以无密码ssh到server上。先生成密钥对,命令如下。
[root@server2 ~]# ssh-keygen -N "" -f /root/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /root/.ssh/id_rsa....输出...
[root@server2 ~]#
配置到server的密钥登录,命令如下。
[root@server2 ~]# ssh-copy-id 192.168.26.101...输出...
root@192.168.26.101's password: 此处输入192.168.26.101的root密码...输出...
[root@server2 ~]#
给server2上通过date命令设置时间,使得server2和server的时间相差200s,命令如下。
[root@server2 ~]# date -s "2023-12-19 23:50:00" ; hwclock -w
2023年 12月 19日 星期二 23:50:00 CST
[root@server2 ~]#
然后同时显示两台机器的时间,命令如下。
[root@server2 ~]# date ; ssh 192.168.26.101 date
2023年 12月 19日 星期二 23:50:08 CST
2023年 12月 19日 星期二 23:56:34 CST
[root@server2 ~]#
这里可以看到,时间相差了6分钟,即360s多。
然后重启server2的chronyd服务,等待几秒之后再次查看
[root@server2 ~]# date ; ssh 192.168.26.101 date
2023年 12月 19日 星期二 23:57:17 CST
2023年 12月 19日 星期二 23:57:17 CST
[root@server2 ~]#
可以看到,时间很快就同步了,因为这是通过step的同步方式,会很快。
再次修改时间,命令如下。
[root@server2 ~]# date -s "2023-12-19 00:00:00" ; hwclock -w
2023年 12月 19日 星期二 00:00:00 CST
[root@server2 ~]#
[root@server2 ~]# date ; ssh 192.168.26.101 date
2023年 12月 19日 星期二 00:00:03 CST
2023年 12月 19日 星期二 00:01:13 CST
[root@server2 ~]#
两台机器的时间相差在1分10s,大概是70s,这个值低于200s,即在makestep的阈值范围之内,此时客户端向服务器进行时间同步时只能使用slew的方式同步。
此时重启chronyd服务,也不会保持时间同步,命令如下。
[root@server2 ~]# date ; ssh 192.168.26.101 date
2023年 12月 19日 星期二 00:01:54 CST
2023年 12月 19日 星期二 00:03:03 CST
[root@server2 ~]#
此时可以看到,并没有同步,因为slew同步的速度比较慢。
此时如果通过执行chronyc makestep手动step同步,则会立即同步时间,命令如下。
[root@server2 ~]# chronyc makestep
200 OK
[root@server2 ~]# date ; ssh 192.168.26.101 date
2023年 12月 19日 星期二 00:05:55 CST
2023年 12月 19日 星期二 00:05:55 CST
[root@server2 ~]#
这样就可以看到立即同步成功了。
通过chronyc -n sources -v查看现在同步状况,如图20-4所示。
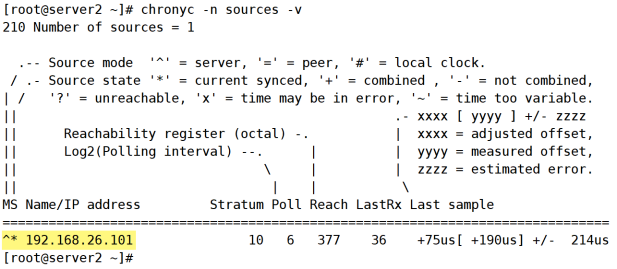
图20-4 查看同步状况
这里可以看到,server2是向192.168.26.101进行同步时间的。
作业
配置server2,使其向阿里云的时间服务器同步时间,阿里云时间服务器地址是ntp.aliyun.com。