1.视图
先介绍一下视图:
从SQL的角度来看,视图和表是相同的,两者的区别在于表中存储的是实际的数据,而视图中保存的是SELECT语句(视图本身并不存储数据)。
使用视图可以轻松完成跨多表查询数据等复杂操作。
视图中不能包含ORDER BY和对视图的更新操作(INSERT、DELETE、UPDATE)
创建视图的方法
CREATE VIEW 视图名称(<视图列名1><视图列名2><视图列名3>......)
AS
<SELECT语句>
创建一个视图
CREATE VIEW productSum(product_type,cnt_product)
AS
SELECT product_type,COUNT(*)FROM productGROUP BY product_type;
使用一个视图
SELECT product_type,cnt_productFROM productSum;

我们这里解释一下,我们首先通过创建了一个视图Productsum,然后通过SELECT语句获取视图中的数据,这样我们就不用了每次需要数据时都SELECT创建新的数据表,需要注意的是,原表product的数据产生变化后,视图数据也会随着变化,非常方便。
之所以能够实现上述功能,是因为视图就是保存好的SELECT语句定义视图时可以使用任何SELECT语句,既可以使用WHERE,GROUP BY,HAVING,也可以通过SELECT*来指定全部列。
使用视图的查询
在FROM子句中使用视图的查询,通常有如下两个步骤:
- 首先执行定义视图的SELECT语句。(创建视图)
- 根据得到的结果,再执行在FROM子句中使用视图的SELECT语句。(从视图中取数据)
- 也就是说视图的查询通常需要执行2条以上的SELECT语句。这里没有用两条,而用了两条以上,是因为还可能出现以视图为基础创建视图的多重视图。例如:我们可以以productsun视图创建productsumjim视图。
--基于productsum创建新的视图
CREATE VIEW productsumjim(product_type,cnt_product)
AS
SELECT product_type,cnt_productFROM productsumWHERE product_type="办公用品";--查看视图
SELECT product_type,cnt_productFROM productsumjim;

虽然语法上没有错误,但是我们还是尽量少使用在视图上创建视图,这是因为对于多数DBMS来说,多重视图会降低SQL的性能。因此还是建议大家使用单一视图。
视图的限制 ——定义时不能使用ORDER BY
虽然我们前面说过定义视图时我们能使用任何SELECT语句,但是有一点例外就是ORDER BY,因此下面的语法是错误的。
CREATE VIEW productsum(product_type,cnt_product)
AS
SELECT product_type,COUNT(*)FROM productGROUP BY product_typeOEDER BY product_type --这里是错误的,不能使用ORDER BY语句。
1.4视图的限制——对视图的更新
对视图的更新有着很严格的限制:
- SELECT子句中未使用DISTINCT
- FROM子句中只有一张表
- 未使用GROUP BY子句
- 未使用HAVING子句
接下来,我们就对视图进行更新。
--创建一个视图
CREATE productjim(product_id,product_name,product_type,sale_price,purchase_price,regist_date)
AS
SELECT *FROM productWHERE product_type="办公用品";--向视图中添加数据行
INSERT INTO productjim VALUES('0009','铅笔','办公用品',95,10,'2009-11-30')删除视图
DROP VIEW 视图名称(<视图列名1>,<视图列名2>,......)
DROP VIEW productsum;
子查询
我们先来说一下子查询和视图:子查询是将用来定义视图的SELECT语句直接用于FROM语句中。
我们使用子查询来实现一个视图
--在from子句中直接书写定义视图的SELECT语句
SELECT product_type,cnt_productFROM(SELECT product_type,COUNT(*) AS cnt_productFROM productGROUP BY product_type) AS productsum;
可以看出结果一模一样。但是有一个不同点:子查询是一张一次性视图,在数据库中并不会创建productsum,下次使用时需要重新定义。

这里我们使用了一个两层的子查询,原则上来说,子查询的层数没有明确的限制。
--一个三层的子查询
SELECT product_type, cnt_productFROM (SELECT *FROM (SELECT product_type, COUNT(*) AS cnt_productFROM ProductGROUP BY product_type) AS ProductSumWHERE cnt_product = 4) AS ProductSum2;

关联子查询
介绍一下关联子查询:关联子查询会在细分的组内进行比较时使用。
- 关联子查询和GROUP BY子句一样,也可以对表中的数据进行切分。
- 关联子查询的结合条件如果未出现在子查询中就会发生错误。
例如:我们查询各种商品种类中高于该种类的平均销售单价的商品。--发生错误的语句 SELECT product_id,product_name,sale_price FROM product WHERE sale_price > (SELECT AVG(sale_price) FROM product GROUP BY product_type);--这里会报错,因为不是唯一值
--发生错误的语句
SELECT product_id,product_name,sale_priceFROM productWHERE sale_price > (SELECT AVG(sale_price) FROM product GROUP BY product_type);--这里会报错,因为不是唯一值
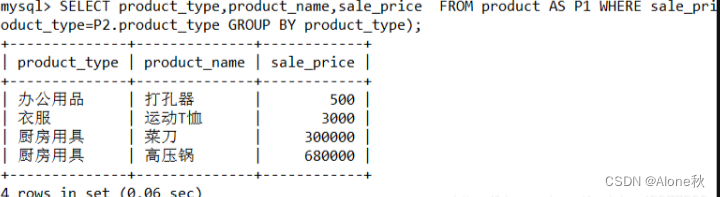
正确的方式应该是:
SELECT product_type,product_name,sale_priceFROM product AS P1WHERE sale_price >(SELECT AVG(sale_price) FROM product AS P2WHERE P1.product_type=P2.product_typeGROUP BY product_type);
结果如下:
数据库常见的面试题
设计到的表有:
- t_student:学生信息表,包含学生编号(student_id)、学生姓名(student_name)等字段。
- t_course:课程信息表,包含课程编号(course_id)、课程名称(course_name)等字段。
- t_teacher:教师信息表,包含教师编号(teacher_id)、教师姓名(teacher_name)等字段。
- t_score:成绩信息表,包含学生编号(student_id)、课程编号(course_id)、成绩(score)等字段。
面试题1/7
1.查询"01"课程比"02"课程成绩高的学生的信息及课程分数:
SELECT s.student_id, s.student_name, sc1.course_score AS score1, sc2.course_score AS score2
FROM student s
JOIN score sc1 ON s.student_id = sc1.student_id AND sc1.course_id = '01'
JOIN score sc2 ON s.student_id = sc2.student_id AND sc2.course_id = '02'
WHERE sc1.course_score > sc2.course_score;
2.查询同时存在"01"课程和"02"课程的情况:
SELECT DISTINCT s.student_id, s.student_name
FROM student s
JOIN score sc1 ON s.student_id = sc1.student_id AND sc1.course_id = '01'
JOIN score sc2 ON s.student_id = sc2.student_id AND sc2.course_id = '02';
3.查询存在"01"课程但可能不存在"02"课程的情况(不存在时显示为 null )
SELECT s.student_id, s.student_name, COALESCE(sc2.course_score, NULL) AS score2
FROM student s
LEFT JOIN score sc2 ON s.student_id = sc2.student_id AND sc2.course_id = '02';
4.查询不存在"01"课程但存在"02"课程的情况:
SELECT s.student_id, s.student_name
FROM student s
LEFT JOIN score sc1 ON s.student_id = sc1.student_id AND sc1.course_id = '01'
WHERE sc1.course_score IS NULL;
5.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩:
SELECT student_id, student_name, AVG(course_score) AS average_score
FROM student s
JOIN score sc ON s.student_id = sc.student_id
GROUP BY student_id, student_name
HAVING average_score >= 60;
6.查询在t_mysql_score表存在成绩的学生信息:
SELECT DISTINCT s.student_id, s.student_name
FROM student s
JOIN score sc ON s.student_id = sc.student_id;
7.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null ):
SELECT s.student_id, s.student_name, COUNT(DISTINCT sc.course_id) AS course_count, SUM(COALESCE(sc.course_score, 0)) AS total_score
FROM student s
LEFT JOIN score sc ON s.student_id = sc.student_id
GROUP BY s.student_id, s.student_name;
面试题8/15
8.查询「李」姓老师的数量:
SELECT COUNT(*) AS count
FROM teacher t
WHERE t.teacher_name LIKE '李%';
9.查询学过「张三」老师授课的同学的信息:
SELECT DISTINCT s.student_id, s.student_name
FROM student s
JOIN score sc ON s.student_id = sc.student_id
JOIN course c ON sc.course_id = c.course_id
JOIN teacher t ON c.teacher_id = t.teacher_id
WHERE t.teacher_name = '张三';
10.查询没有学全所有课程的同学的信息
SELECT s.student_id, s.student_name
FROM student s
WHERE NOT EXISTS (SELECT * FROM course cWHERE NOT EXISTS (SELECT * FROM score sc WHERE sc.student_id = s.student_id AND sc.course_id = c.course_id)
);
11.查询没学过"张三"老师讲授的任一门课程的学生姓名:
SELECT s.student_name
FROM student s
WHERE NOT EXISTS (SELECT * FROM course cJOIN score sc ON c.course_id = sc.course_idJOIN teacher t ON c.teacher_id = t.teacher_idWHERE t.teacher_name = '张三' AND sc.student_id = s.student_id
);
12.查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩:
SELECT s.student_id, s.student_name, AVG(sc.course_score) AS average_score
FROM student s
JOIN score sc ON s.student_id = sc.student_id
WHERE sc.course_score < 60
GROUP BY s.student_id, s.student_name
HAVING COUNT(sc.course_id) >= 2;
13.检索"01"课程分数小于 60,按分数降序排列的学生信息:
SELECT s.student_id, s.student_name, sc.course_score
FROM student s
JOIN score sc ON s.student_id = sc.student_id AND sc.course_id = '01'
WHERE sc.course_score < 60
ORDER BY sc.course_score DESC;
14.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩:
SELECT s.student_id, s.student_name, sc.course_id, sc.course_score, (SELECT AVG(course_score) FROM score WHERE student_id = s.student_id) AS average_score
FROM student s
JOIN score sc ON s.student_id = sc.student_id
ORDER BY average_score DESC;
15.查询各科成绩最高分、最低分和平均分:
SELECT course_id, MAX(course_score) AS highest_score, MIN(course_score) AS lowest_score, AVG(course_score) AS average_score,SUM(CASE WHEN course_score >= 60 THEN 1 ELSE 0 END) / COUNT(*) AS pass_rate,SUM(CASE WHEN course_score >= 70 AND course_score < 80 THEN 1 ELSE 0 END) / COUNT(*) AS medium_rate,SUM(CASE WHEN course_score >= 80 AND course_score < 90 THEN 1 ELSE 0 END) / COUNT(*) AS good_rate,SUM(CASE WHEN course_score >= 90 THEN 1 ELSE 0 END) / COUNT(*) AS excellent_rate
FROM score
GROUP BY course_id;