矩阵-矩阵乘法,或简称矩阵乘法,在 i X j(i 行 by j 列)矩阵 M 和 j x k 矩阵 N 之间产生 i X k 矩阵P。矩阵乘法是基本线性代数子程序(BLAS)标准的重要组成部分(见第3章中的“线性代数函数”边栏:可扩展并行执行)。该函数是许多线性代数求解器(如LU分解)的基础。正如我们将看到的,矩阵乘法为减少可以用相对简单的技术捕获的全局内存访问提供了机会。矩阵乘法函数的执行速度可以按数量级变化,这取决于全局内存访问的减少程度。因此,矩阵乘法为这种技术提供了一个很好的初始示例。
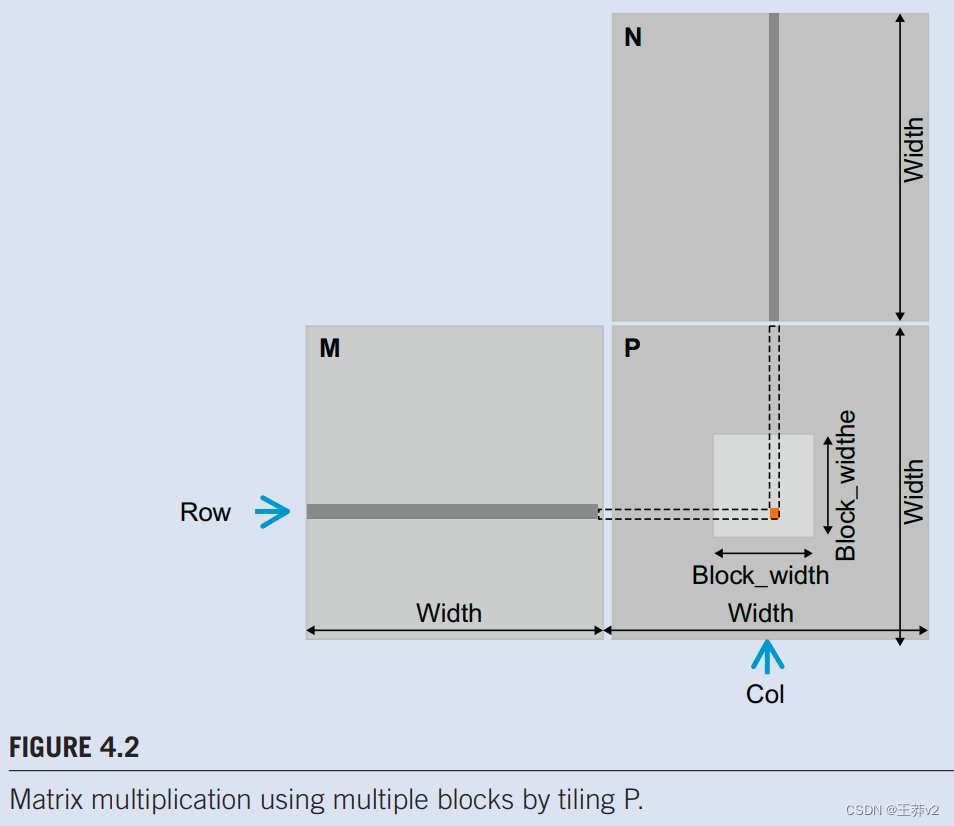
当执行矩阵乘法时,输出矩阵P的每个元素都是M行和N列的内积。我们将继续使用惯例,其中 P R o w , C o l P_{Row, Col} PRow,Col是垂直方向的Row位置的元素,水平方向的Col位置。如图4.2所示, P R o w , C o l P_{Row, Col} PRow,Col(P中的小方块)是由M的Row行(在M中显示为水平条带)和由N的Col列(在N中显示为垂直条带)形成的向量的内积。两个向量的内积,也称为点积,是单个向量元素的乘积之和,即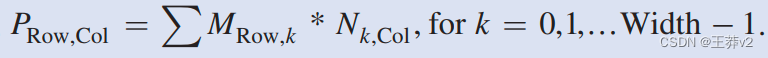
例如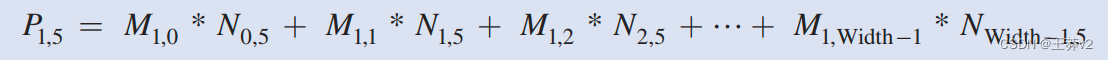
在我们最初的矩阵乘法实现中,我们使用与colorToGreyscaleConversion相同的方法将线程映射到P元素;即每个线程负责计算一个P元素。每个线程要计算的P元素的行和列索引如下:

通过这种一对一映射,Row和Col线程索引也是输出数组的行和列索引。图4.3显示基于此线程到数据映射的内核源代码。如果Row和Col都在范围内,读者应该立即看到计算Row、Col和if语句测试的熟悉模式。这些语句与colorToGreyscale转换中的对应语句几乎相同。唯一显著的区别是,我们假设矩阵MulKernel的平方矩阵,从而用宽度替换宽度和高度。
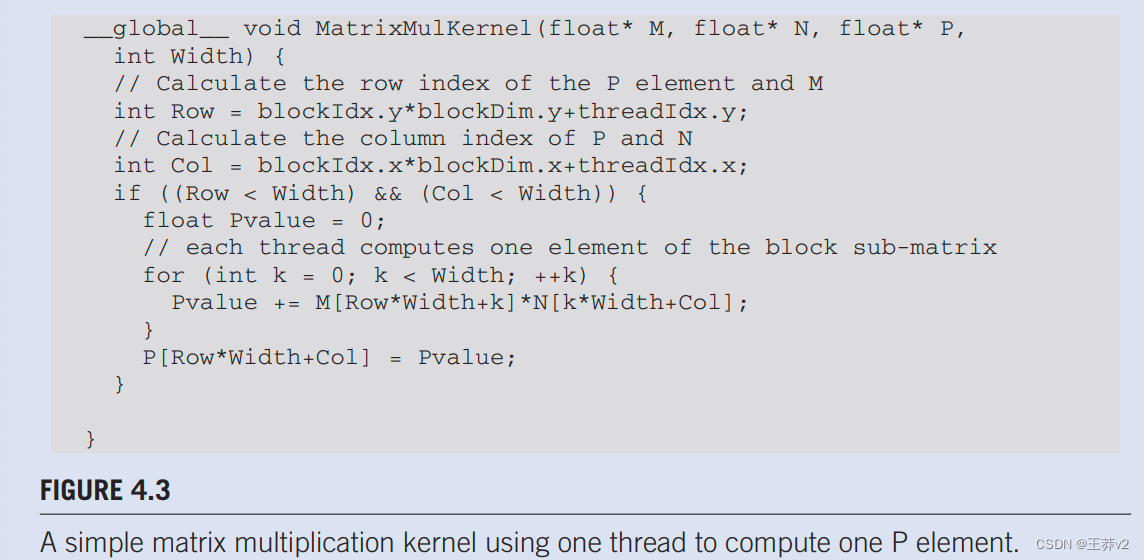
线程到数据映射有效地将P划分为tiles,其中一个在图4.2.中显示为一个大正方形。每个块负责计算其中一个4.2.。
我们现在把注意力转向每个线程所做的工作。回想一下, P R o w , C o l P_{Row,Col} PRow,Col是M的Row行和N的Col列的内积。在图4.3中,我们使用for-loop来执行此内积操作。在进入循环之前,我们将局部变量Pvalue初始化为0。循环的每个迭代都从M的行访问一个元素,从N的Coith列访问一个元素,将两个元素乘以一起,并将乘积累积到Pvalue中。
首先,我们专注于访问for-loop中的M元素。回想一下,M被线性化成一个等价的1D数组,其中M的行一个接一个地放置在内存空间中,从0行开始。因此,第1行的开头元素是M[1width],因为我们需要考虑其他行的所有元素。一般来说,第Row行的开头元素是M[RowWidth]。由于一行的所有元素都放置在连续的位置,因此Rowt行的第k个元素位于M[Row*Width+k]。该方法应用于图4.3.
我们现在把注意力转向N。如图4.3所示,第Col列的开头元素是第0行的第Col元素,即N[Col]。访问第Col列中的每个附加元素需要跳过整个行。原因是同一列的下一个元素实际上是下一行的同一元素。因此,第Col列的k"元素是N[k*width+Col]。
执行退出for-loop后,所有线程在Pvalue变量中都有其P元素值。然后,每个线程使用一维等价索引表达式Row*Width+Col来写入其P元素。同样,这种索引模式与colorToGreyscaleConversion内核中使用的索引模式相似。
我们现在用一个小例子来说明矩阵乘法内核的执行。图4.4显示4×4 P,BLOCK_WIDTH=2。小尺寸允许我们将整个示例放入一张图片中。P矩阵现在分为四个tile,每个块计算一个tile。我们通过创建2×2线程数组的块来做到这一点,每个线程计算一个P元素。在示例中,块(0,0)的线程(0,0)计算 P 0 , 0 P_{0,0} P0,0,而块(1,0)的线程(0,0)计算 P 2 , 0 P_{2,0} P2,0。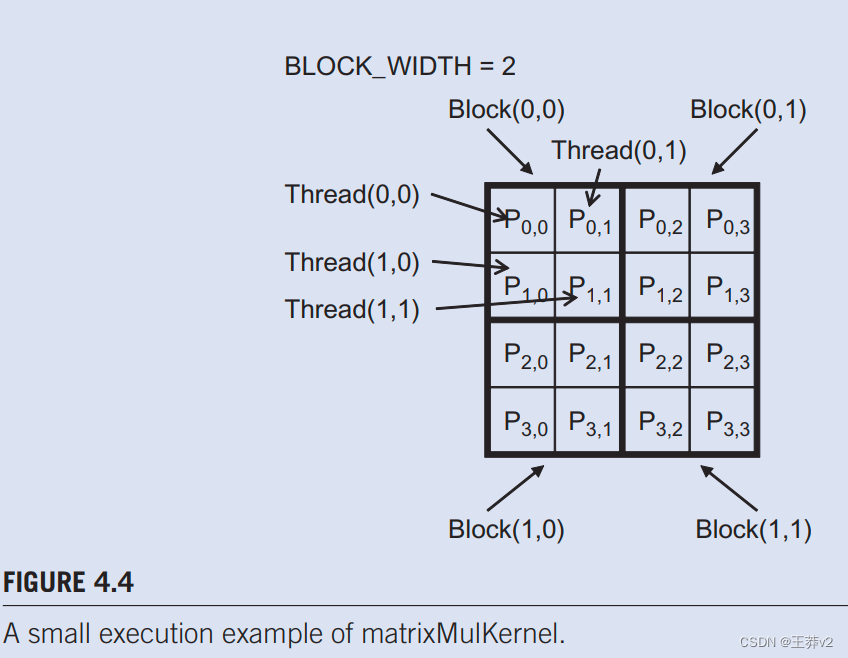
矩阵中的 Row 和 Col 在matrixMulKernel标识了要由线程进行缓存的P元素。行还标识M的行,而Col将N的列标识为线程的输入值。图4.5说明了每个线程块中的乘法操作。对于小矩阵乘法示例,块中的线程(0,0)产生四个点乘积。块(0,0)中线程(1,0)的行和Col变量是00 + 1= 1和00 + 0= 0。它映射到P1.0,并计算M第1行和N第0列的点积。

我们浏览了图4.3中for-loop的执行。用于块(0,0)中的线程(0,0)。在第0次迭代(K=0)期间,RowWidth+k=04 + 0 = 0和kwidth+Co1=04 + 0= 0。因此,我们正在访问M[0]和N[0],根据图3.3,它们相当于Mo.o和No,o的1D。.请注意,这些确实是M的第0行和N的0列的其他元素。在第一次迭代(k=1)期间,RowWidth+k=04+1=1和kWidth+Col=14+0=4。我们正在访问M[1]和N[4],根据图3.3.,它们相当于M 0,1和N 1,0的1D。这些是M的0行和N的0列的第一个元素。
在第二次迭代(k=2)期间,RowWidth+K=04+2=2和kWidth+Col=8,导致M[2]和N[8]。因此,访问的元素是MMo.2和d_N2.0的1D等价物。最后,在第3次迭代(k=3)中,行宽度+ k=04+ 3和kWidth+ Col= 12,这导致M[3]和N[12],1D等价于M0.3和N3.0。我们现在已经验证了for-loop在M的0行和N的0列之间执行内积。在循环之后,线程写入P[Row*Width+Col],这是P[0],相当于 P0,0.的1D。因此,块(0,0)中的线程(0,0)成功计算了M的0行和N的0列之间的内积,并将结果存入P0.0。
我们将把它作为练习,供读者手动执行并验证块(0,0)或其他块中其他线程的for-loop。
请注意,matrixMulKernel 可以处理每个维度中多达16×65,535个元素的矩阵**。在大于该极限的矩阵要相乘的情况下,可以将P矩阵划分为大小可以由网格覆盖的子矩阵。然后,我们可以使用主机代码迭代启动内核并完成P矩阵。或者,我们可以更改内核代码,以便每个线程计算更多的P元素。**
我们可以通过计算图4.3.中矩阵乘法内核代码的预期性能水平来估计内存访问效率的影响。就执行时间而言,内核的主导部分是执行内部乘积计算的for-loop:
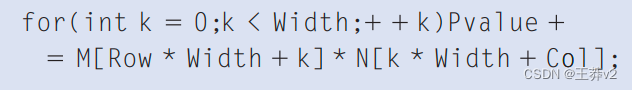
在这个循环的每次迭代中,都会为一个浮点乘法和一个浮点加法执行两个全局内存访问。一个全局内存访问获取M元素,另一个获取N元素。一个浮点运算将获取的M和N元素相乘,另一个将乘累积到P值中。因此,循环的compute-to-global-memory-access比为1.0。从我们在第3章(可扩展并行执行)的讨论中,这一比例可能会导致模制GPU的峰值执行速度的利用率低于2%。我们需要将现代设备的计算吞吐量的比率至少提高一个数量级,以实现良好的利用率。在下一节中,我们将展示我们可以在CUDA设备中使用特殊内存类型来实现这一目标。