本文将介绍如下内容:
- transformer中的mask机制
- Causal Decoder
- Prefix Decoder
- Encoder Decoder
- 总结
一、transformer中的mask机制
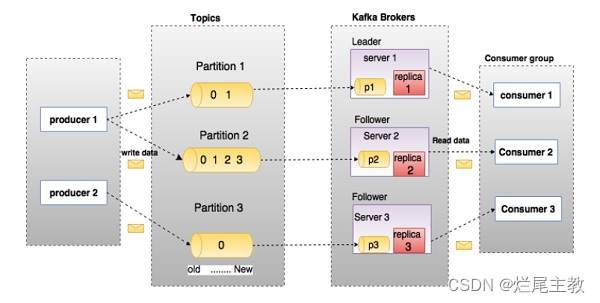
在Transformer模型中,mask机制是一种用于在self-attention中的技术,用以控制不同token之间的注意力交互。具体来说,Transformer中使用两种类型的mask:padding mask 和sequence mask**。**
1、Padding mask(填充掩码)
Padding mask(填充掩码):在自注意力机制中,句子中的所有单词都会参与计算。但是,在实际的句子中,往往会存在填充符(比如-1),用来填充句子长度不够的情况。Padding mask就是将这些填充符对应的位置标记为0,以便在计算中将这些位置的单词忽略掉。
例如,假设我们有一个batch_size为3、句子长度为5的输入序列:
[[1, 2, 3, -1, -1], [2, 3, -1, -1, -1], [1, -1, -1, -1, -1]
]
其中-1表示填充符,用于填充长度不到5的位置。则padding mask为:
[[1, 1, 1, 0, 0], [1, 1, 0, 0, 0], [1, 0, 0, 0, 0]
]
其中1表示可以参与计算的位置,0表示需要被忽略的位置。例如,第一句话前三个位置有具体的词,对应设为1;而最后两个位置是padding,对应设为0。huggingface的BertTokenizer分词所返回的attention mask指的就是padding mask:https://huggingface.co/docs/transformers/glossary#attention-mask
2、Sequence mask(序列掩码)
sequence mask用于在Decoder端的self-attention中,以保证在生成序列时不会将未来的信息泄露给当前位置的单词。
例如,假设我们要生成一个长度为5的序列。在第i个位置上生成的单词,需要将前i-1个单词作为输入,但是不能将第i个位置以后的单词作为输入。这就需要使用sequence mask将第i个位置以后的单词掩盖掉。具体而言,sequence mask会将第i个位置以后的所有位置标记为0,表示在计算中需要忽略这些位置的信息。
本文要比较不同LLM架构,其实是在比较sequence mask。事实上,用户所使用的LLM所做的都是seq2seq任务,用户输入一个文本prompt,LLM对应输出一个文本completion。为了方便以后的讨论,采用A Survey of Large Language Models这篇综述中的例子,用户输入的prompt为A Survey of,期望语言模型的输出为Large Language Models。
二、Causal Decoder
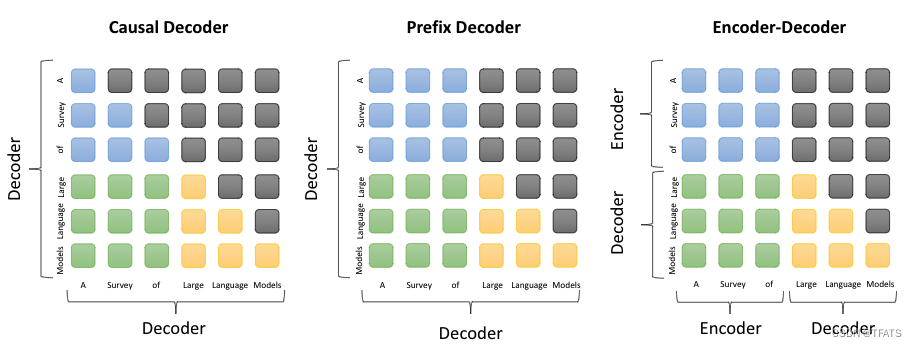
Causal LM是因果语言模型,目前流行的大多数模型都是这种结构,别无他因,因为GPT系列模型内部结构就是它,还有开源界的LLaMa也是。Causal Decoder架构的典型代表就是GPT系列模型,**使用的是单向注意力掩码,**以确保每个输入token只能注意到过去的token和它本身,输入和输出的token通过Decoder以相同的方式进行处理。在下图中,灰色代表对应的两个token互相之间看不到,否则就代表可以看到。例如,”Survery”可以看到前面的“A”,但是看不到后面的“of”。Causal Decoder的sequence mask矩阵是一种典型的下三角矩阵。
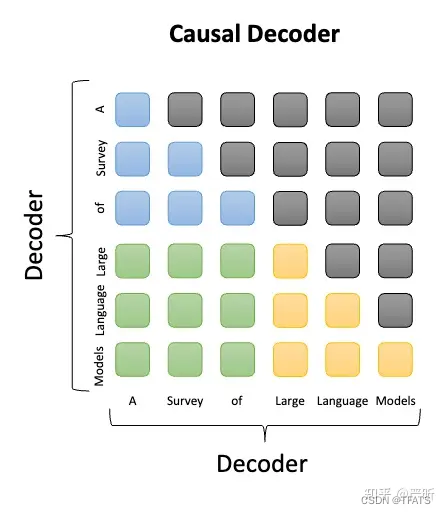
Causal LM只涉及到Encoder-Decoder中的Decoder部分,采用Auto Regressive模式,直白地说,就是根据历史的token来预测下一个token,也是在Attention Mask这里做的手脚。
参照着Prefix LM,可以看下Causal LM的Attention Mask机制(左)及流转过程(右)。
三、Prefix Decoder
Prefix LM,即前缀语言模型,Prefix Decoder架构也被称为non-causal Decoder架构,该结构是Google的T5模型论文起的名字,望文知义来说,这个模型的”前缀”有些内容,但继续向前追溯的话,微软的UniLM已经提及到了。
Prefix LM其实是Encoder-Decoder模型变体,为什么这样说?解释如下:
(1) 在标准的Encoder-Decoder模型中,Encoder和Decoder各自使用一个独立的Transformer
( 2) 而在Prefix LM,Encoder和Decoder则共享了同一个Transformer结构,在Transformer内部通过Attention Mask机制来实现。
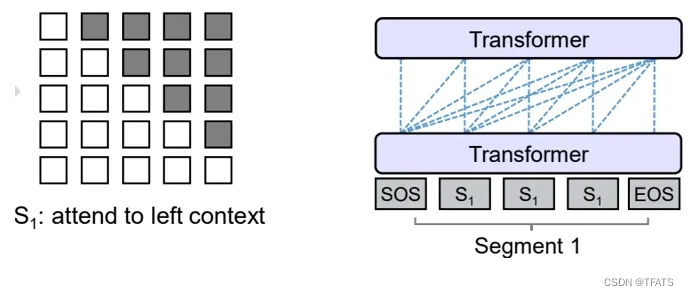
Prefix LM是输入部分采用双向注意力,而输出部分采用单向注意力;和Encoder-Decoder不同的是,处理输入和输出的模型参数是完全共享的,从这一点看,它又和causal Decoder比较接近,都属于Decoder-Only架构:
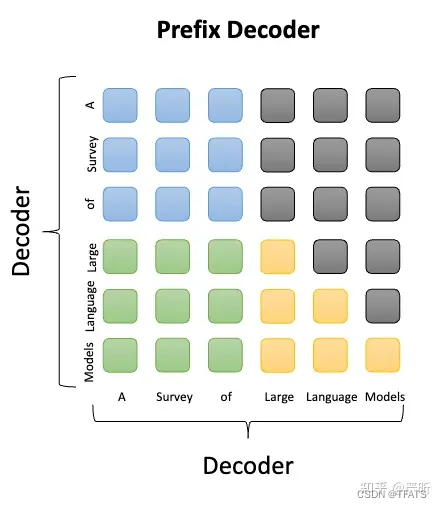
与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用Auto Encoding (AE-自编码)模式,即前缀序列中任意两个token都相互可见,而Decoder部分采用Auto Regressive (AR-自回归)模式,即待生成的token可以看到Encoder侧所有token(包括上下文)和Decoder侧已经生成的token,但不能看未来尚未产生的token。
下面的图很形象地解释了Prefix LM的Attention Mask机制(左)及流转过程(右)。
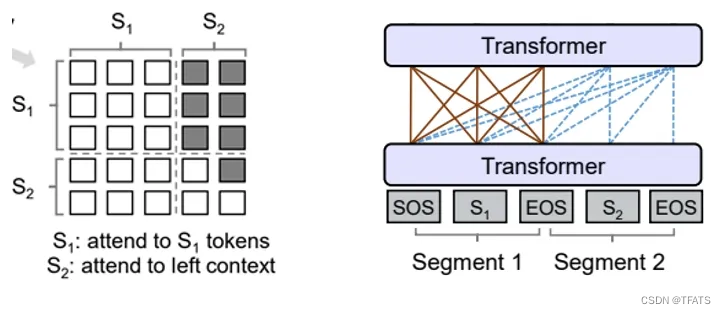
Prefix LM的代表模型有UniLM、T5、GLM(清华滴~)
四、Encoder Decoder
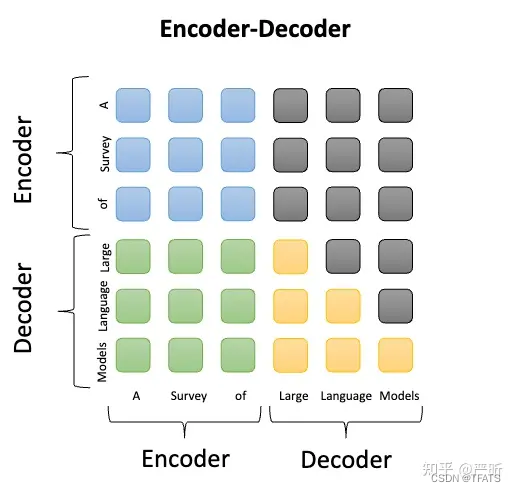
Transformer最初被提出来的时候采用的就是Encoder-Decoder架构,模型包含两部分Encoder和Decoder,两部分参数独立。其中Encoder将输入序列处理为一种中间表示,而Decoder则基于中间表示自回归地生成目标序列,典型的LLM是Flan-T5。Encoder部分采用双向注意力,对应的prompt的每个token都可以互相看到;而Decoder部分仍然采用单向注意力,对应的completion仍然保证前面的token看不到后面的token:
五、总结
前缀语言模型可以根据给定的前缀生成后续的文本,而因果语言模型只能根据之前的文本生成后续的文本。
在 A Survey of Large Language Models 中有几种LLM更详细的对比:
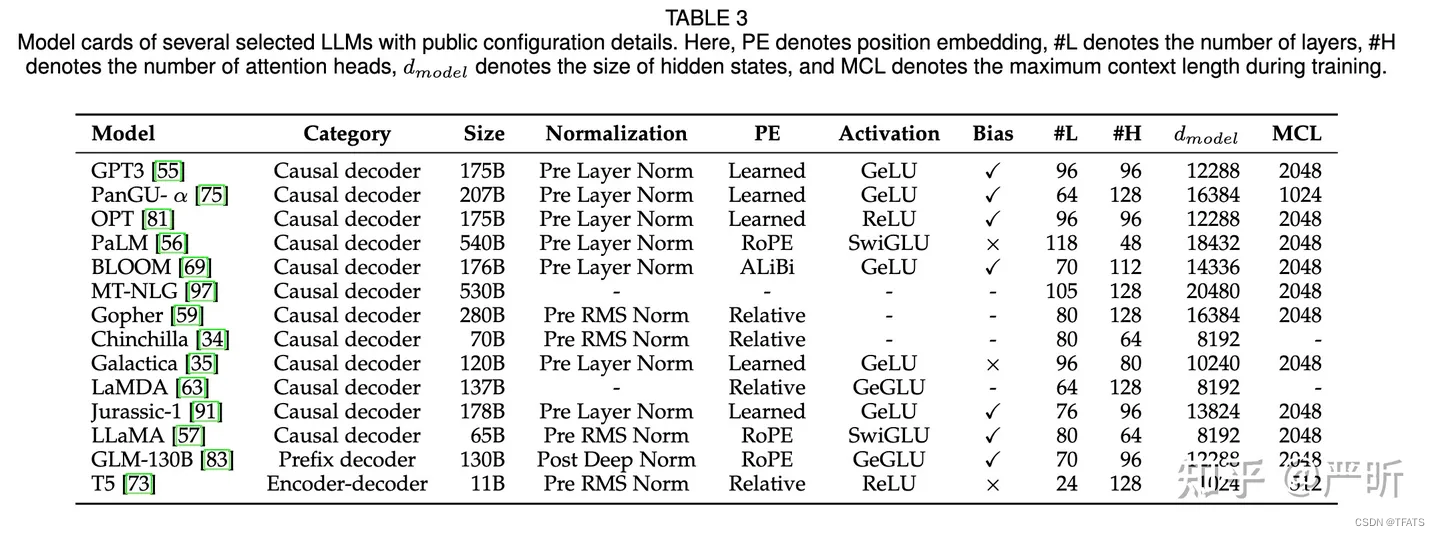
注意力机制相关的对比如下:
| 模型架构 | 代表LLM | 注意力机制 | 是否属于Decoder-Only |
|---|---|---|---|
| Causal Decoder | GPT3/ChatGPT | 纯单向 | YES |
| Encoder-Decoder | Flan-T5 | 输入双向 | NO |
| Prefix Decoder | GLM-130B/ChatGLM-6B | 输入双向,输出单向 | YES |
参考:
- LLM面面观之Prefix LM vs Causal LM
- 管中窥豹:从mask入手对比不同大语言模型的架构