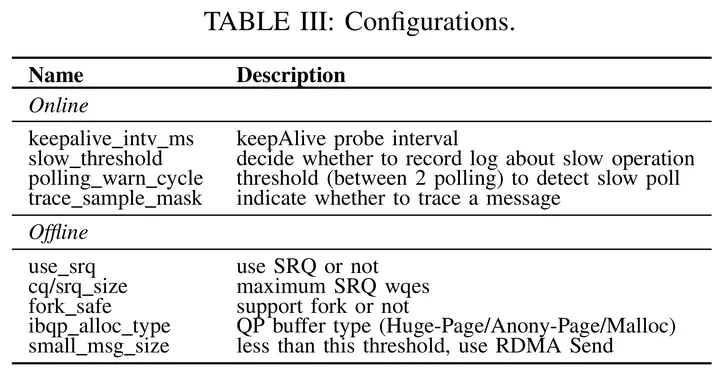
文章目录
- 简介
- 例子
- 继承结构概览
- 代码分析
- 成员变量
- 方法
- 迭代器
- 子列表
- 总结
- 参考链接
本人的源码阅读主要聚焦于类的使用场景,一般只在java层面进行分析,没有深入到一些native方法的实现。并且由于知识储备不完整,很可能出现疏漏甚至是谬误,欢迎指出共同学习
本文基于corretto-17.0.9源码,参考本文时请打开相应的源码对照,否则你会不知道我在说什么
简介
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。
例子
ArrayList的API使用起来还是比较简单的,例子的话简单看看就行。
ArrayList<String> sites = new ArrayList<String>();
sites.add("Google");
sites.add("Runoob");
sites.add("Taobao");
sites.add("Weibo");
System.out.println(sites); // 输出[Google, Runoob, Taobao, Weibo]
System.out.println(sites.get(1)); // 访问第二个元素,输出Runoob
sites.set(2, "Wiki"); // 修改第三个元素为Wiki
sites.remove(3); // 删除第四个元素
System.out.println(sites.size()); // 得到元素个数
// 使用for-each遍历
for (String i : sites) {System.out.println(i);
}
继承结构概览
当开始分析一个类之前,肯定得知道它继承了什么类或者接口,因为在该类中可能会调用父类的方法,因此有必要先去了解这个类的继承体系。ArrayList继承于AbstractList,AbstractList继承于AbstractCollection并实现List,AbstractCollection又实现Collection。用图表示如下,隐藏了不太算JCF相关的接口,比如Cloneable,Object这些,只保留集合相关的类和接口:
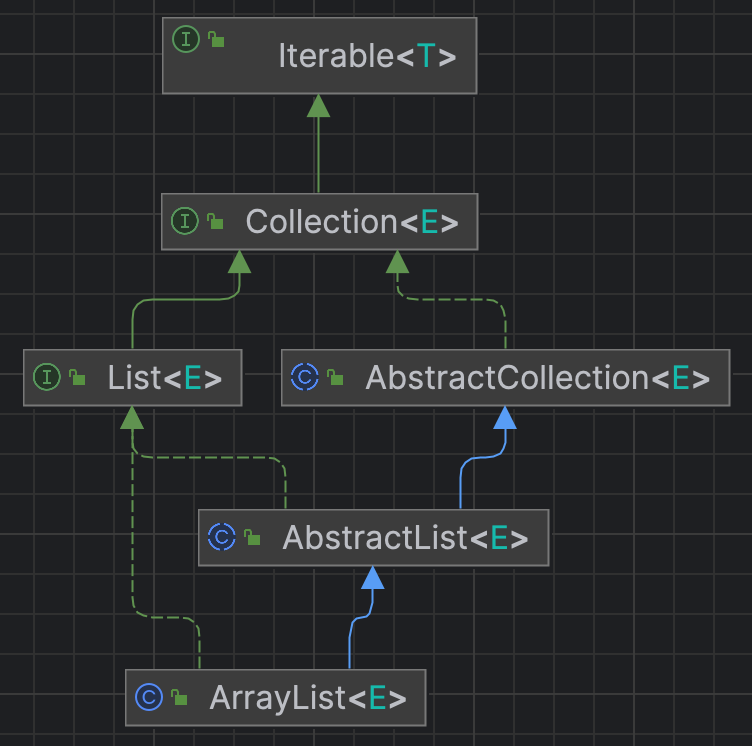
其中的AbstractCollection用于提供一个实现了Collection的抽象类,提供了一些在实现Collection接口时某些方法的通用实现,类似一个骨架,重复性工作都给你做好了,想要实现Collection的类可以首先考虑继承AbstractCollection。
类似地,AbstractList是List的骨架类,提供了一些在实现List接口时某些方法的通用实现。
不熟悉JCF的基础接口和类的话,可以先看这篇:JCF相关基础类接口/抽象类源码阅读
整明白JCF继承结构之后,看一下完整的继承结构:
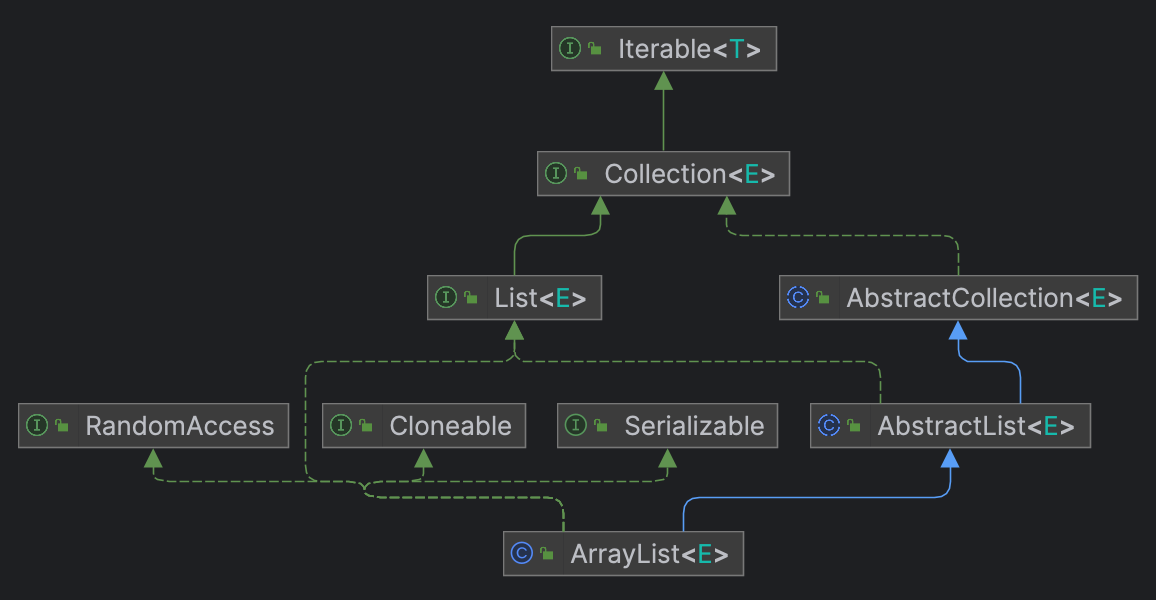
也就多了三个标记接口:RandomAccess、Cloneabl、Serializable,标记接口指的是没有任何方法的空接口,比如RandomAccess只是用来给使用ArrayList的用户说明这个类可以高效地实现随机访问。这些标记接口不影响我们分析类,想进一步了解可以参考我的JCF基础的博客,这里不再赘述。
代码分析
成员变量
ArrayList的成员变量很少,只有底层数组和size:
transient Object[] elementData;
private int size;
因此ArrayList其实就是一个对原始数组的封装,并且内部通过强制类型转换实现Object到泛型的转换。
因为是用数组实现的,数组本身的大小是固定的,当大小不足容下更多的元素,只能重新创建更大的新数组,而且为了避免频繁扩容带来的开销,扩容后的大小总是会 >= 实际元素的个数。因此引出两个概念:capacity和size,前者是数组的大小,即elementData.length,后者则是ArrayList实际存储了的元素个数,存于size变量中。
另外还提前声明了两个静态空数组,作用如下:
// capacity为0时直接用它,避免重复创建空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 用于无参构造函数构造时,capacity为0,之后第一次扩容至少要到DEFAULT_CAPACITY。与EMPTY_ELEMENTDATA区分开来
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
方法
方法这块看起来讲得比较乱,其实顺序是按照源码从上到下的顺序讲的,并且函数之间的调用我会先讲被调用的函数,或者串讲。
ArrayList有三种构造函数:
// 空列表,capacity和size都为0,第一次扩容至少要扩容到DEFAULT_CAPACITY
public ArrayList();// capacity为initalCapacity,size为0
public ArrayList(int initialCapacity);// capacity和size都为c.length,保存的元素与c中的相同
public ArrayList(Collection<? extends E> c);
比较直观,不列实现代码了。下面看下其他方法,其中一些实现简单的方法就不细讲
// 将capacity缩小到刚好能容纳所有元素,具体是通过elementData = Arrays.copyOf(elementData, size)
public void trimToSize();// 确保数组大小至少为minCapacity
public void ensureCapacity(int minCapacity) {// 第二个条件:当elementData为DEFAULTCAPACITY_EMPTY_ELEMENTDATA,至少会扩容到DEFAULT_CAPACITY,因此minCapacity小于DEFAULT_CAPACITY的话,直接忽略本次扩容if (minCapacity > elementData.length&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA&& minCapacity <= DEFAULT_CAPACITY)) {modCount++;grow(minCapacity);}
}// 将数组扩容到至少minCapacity
private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 如果数组不是DEFAULTCAPACITY_EMPTY_ELEMENTDATA// 扩容为oldCapacity的1.5倍(希望扩容的大小),否则扩容到minCapacityint newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {// 如果数组是DEFAULTCAPACITY_EMPTY_ELEMENTDATA,至少扩容到DEFAULT_CAPACITYreturn elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}
}
这里grow(minCapacity)方法中,ArraysSupport.newLength是个什么的呢?简单来说这个函数是基于当前数组长度、希望增长的长度、最少增长的长度,来计算新的数组长度的。当然,里面还有更加细致的考量,了解一下即可:
// 基于当前数组的长度,计算新的长度
// minGrowth是最少要增长的长度
// prefGrowth是希望增长的长度
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {int prefLength = oldLength + Math.max(minGrowth, prefGrowth); // might overflowif (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) {// 如果希望增长的长度合适,则直接返回return prefLength;} else {// 希望增长的长度不适合,继续计算return hugeLength(oldLength, minGrowth);}
}private static int hugeLength(int oldLength, int minGrowth) {int minLength = oldLength + minGrowth;if (minLength < 0) {// minLength > Integer.MAXthrow new OutOfMemoryError("Required array length " + oldLength + " + " + minGrowth + " is too large");} else if (minLength <= SOFT_MAX_ARRAY_LENGTH) {// minLength <= SOFT_MAX_ARRAY_LENGTH,说明prefGrowth > minGrowth但是prefGrowth会导致prefLength > SOFT_MAX_ARRAY_LENGTH,那么让结果尽量接近prefGrowth,直接返回SOFT_MAX_ARRAY_LENGTHreturn SOFT_MAX_ARRAY_LENGTH;} else {// minLength > SOFT_MAX_ARRAY_LENGTH 并且 minLength < Integer.MAX,倒也可以返回minLength。SOFT_MAX_ARRAY_LENGTH实际上是照顾JVM的实现,因为有的JVM对最大数组大小的限制在Integer.MAX附近,而SOFT_MAX_ARRAY_LENGTH可以保证不会超出大部分JVM最大数组的限制return minLength;}
}
继续看其他的方法:
// ArrayList继承了Cloneable,支持克隆一个新的ArrayList。底层数组与克隆的底层数组是两个不同的实例,但里面的元素都是一样的
public Object clone() {try {// 获取浅拷贝ArrayList<?> v = (ArrayList<?>) super.clone();// 创建新数组v.elementData = Arrays.copyOf(elementData, size);// 新的ArrayList,modCount(结构性修改次数)自然是0v.modCount = 0;return v;} catch (CloneNotSupportedException e) {// this shouldn't happen, since we are Cloneablethrow new InternalError(e);}
}// 将元素插入index为下标的位置,原来[index, size)的元素都往后移动
public void add(int index, E element) {rangeCheckForAdd(index);modCount++;final int s;Object[] elementData;if ((s = size) == (elementData = this.elementData).length)elementData = grow();// 将从index开始到数组末尾的元素,整体复制到index+1开始的位置// remove(index)的实现也是用这个System.arraycopy,只不过是index+1的位置复制到index而已System.arraycopy(elementData, index,elementData, index + 1,s - index);elementData[index] = element;size = s + 1;
}// 当两个List拥有相同size并且每个元素都equals时返回true
// 如果o不是ArrayList(但仍是List)则使用迭代器遍历,如果是ArrayList的话,使用fori遍历
public boolean equals(Object o) {if (o == this) {return true;}if (!(o instanceof List)) {return false;}final int expectedModCount = modCount;boolean equal = (o.getClass() == ArrayList.class)? equalsArrayList((ArrayList<?>) o): equalsRange((List<?>) o, 0, size);checkForComodification(expectedModCount);return equal;
}// clear名为删除所有元素,在ArrayList中实现为将数组每个引用置空,使得将来可以复用数组
public void clear() {modCount++;final Object[] es = elementData;for (int to = size, i = size = 0; i < to; i++)es[i] = null;
}
还有几个可能稍微难理解一点的方法:
// 相当于删除在[lo, hi)间的元素
private void shiftTailOverGap(Object[] es, int lo, int hi) {System.arraycopy(es, hi, es, lo, size - hi);for (int to = size, i = (size -= hi - lo); i < to; i++)es[i] = null;
}// 当complement=false,删除在[from, end)间,且存在于c中的元素
// 当complement=true,删除在[from, end)间,且不存在于c中的元素
boolean batchRemove(Collection<?> c, boolean complement,final int from, final int end) {Objects.requireNonNull(c);final Object[] es = elementData;int r;// 确定从哪开始删除:这个for循环完了之后,r保存第一个将被删除元素的下标for (r = from;; r++) {if (r == end)return false;if (c.contains(es[r]) != complement)break;}// w保存将要保留的元素的下标// 这是实现删除数组中某些元素的时候常用的双指针算法,目的是保持数组元素连续:w和r分别为两个指针,r负责遍历(r无条件自增),当r指向的元素符合条件的时候存到w的位置,w自增(不符合条件的话w保持当前值)int w = r++;try {for (Object e; r < end; r++)if (c.contains(e = es[r]) == complement) // 遍历到要删除的元素es[w++] = e;} catch (Throwable ex) {// 如果contains抛异常,为了避免数组出现空洞做的善后处理// 放弃遍历[r, end)这堆没遍历完的元素,直接把他们前移到w指向的位置System.arraycopy(es, r, es, w, end - r);w += end - r;throw ex;} finally {modCount += end - w;// 处理完元素之后[w, end)这段会出现空洞,把[end, size)前移进来shiftTailOverGap(es, w, end);}return true;
}// 删除[i, end)区间中所有满足filter的元素
// 与batchRemove大同小异,不同之处只是在于条件通过filter.test判断
boolean removeIf(Predicate<? super E> filter, int i, final int end) {Objects.requireNonNull(filter);int expectedModCount = modCount;final Object[] es = elementData;// 确定从哪开始删除:这个for循环完了之后,i保存第一个将被删除元素的下标for (; i < end && !filter.test(elementAt(es, i)); i++);if (i < end) {// 与batchRemove的不同:先标记所有符合条件(将被删除)的元素,然后才删除// 这样做的原因在于:filter.test传入的是当前遍历到的列表元素,但其可能不仅依赖于传入的元素来决定返回值为true还是false,而是依赖于整个列表(也就是可能会依赖于其他的元素)。因此在要保证在filter遍历的过程中列表是可重入读的,即不能遇到filter.test返回true就立刻删除,这样对于下一次filter.test来说列表已经发生了改变。而是用deathRow先标记将要删除的元素,遍历完之后再一次性删除。final int beg = i;final long[] deathRow = nBits(end - beg);deathRow[0] = 1L;for (i = beg + 1; i < end; i++)if (filter.test(elementAt(es, i)))setBit(deathRow, i - beg);if (modCount != expectedModCount)throw new ConcurrentModificationException();modCount++;int w = beg;// 双指针w和ifor (i = beg; i < end; i++)if (isClear(deathRow, i - beg))es[w++] = es[i];shiftTailOverGap(es, w, end);return true;} else {if (modCount != expectedModCount)throw new ConcurrentModificationException();return false;}
}
第一个函数shiftTailOverGap不用多说
第二个函数batchRemove简单总结就是用来移除数组中包含于c/不包含于c中的元素,并且函数退出之后,数组不能出现空洞,即数组留下来的元素得保持连续,不然的话之后这个数组还怎么使用hhhhh。
第三个函数removeIf与batchRemove是一样的思想,只不过移除的是“符合条件的元素”,用途更为广泛一点。batchRemove相当于是其的一个特例,条件为“是否包含于/不包含于c”。然后还得保证predict(filter)的可重入性,也就是该方法对于调用者有一个规范/假设:对每个元素进行predict的时,列表结构不能发生改变,更具体的解释可以看注释。
至此,基本的方法介绍得差不多了,都比较简单,下面来看一下迭代器和子列表相关的东西。ArrayList没有使用AbstractList提供的默认迭代器类和子列表类,而是自己重新实现了一套,至于为什么,我想是为了直接操纵底层数组提高运行效率(注释也说了An optimized version of AbstractList.Itr)。
先看迭代器:
迭代器
private class Itr implements Iterator<E> {int cursor; // index of next element to returnint lastRet = -1; // index of last element returned; -1 if no suchint expectedModCount = modCount;// ...
}private class ListItr extends Itr implements ListIterator<E> {// ...
}
还是熟悉的配方。。。参考我JCF博客关于AbstractList.Itr和AbstractList.ListItr的分析就行了,大同小异。不同之处只是ArrayList直接访问底层数组,而AbstractList借助get方法访问。
迭代器是fail-fast的,意思是会在运行过程中检测结构性修改,如果有的话直接抛出ConcurrentModificationException异常,而不是继续迭代遍历。这一点其实在AbstractList.Itr也是一样的。
但注意ArrayList不是并发安全的,因此用户不能完全依赖于fail-test来判断有没有发生结构性修改,可能在某个时间点检查是正常的,在这个时间点之后发生了结构性修改无法再检测出来,fail-fast只是尽最大努力去发现结构性修改。总结下来即:抛异常则一定发生了结构性修改,但没抛异常不一定意味着没发生结构性修改,因此这个特性只能用来debug,或者说这个是一个heuristic的功能(启发式的,意味着不一定准确)。
子列表
private static class SubList<E> extends AbstractList<E> implements RandomAccess {private final ArrayList<E> root;private final SubList<E> parent;private final int offset;private int size;
}
成员变量还是熟悉的配方,里面的方法都与AbstractList.SubList的大同小异,基本上类似根据菜谱做菜(先放油、再放菜、放盐、放葱)那样,有的方法看着有点长,其实就是步骤比较多:先访问元素、修改指针、检查并发访问…就不再介绍了。
总结
整体来说ArrayList没什么难点,掌握核心思想,即:ArrayList就是对数组进行封装的类,并通过扩容机制(每次扩容1.5倍)实现了动态修改大小的特性。其中有的方法看起来很长,其实是维护变量罢了,理解核心思想的话,并不难分析。还有几个方法比如batchRemove、removeIf可能有些让人疑惑的点,比如双指针算法、标记删除法,读懂就好了。
最后ArrayList不是并发安全的,进一步来说,里面有的方法可能会抛出ConcurrentModificationException,但是不抛出这个异常的情况下,不代表着没有“异常”。
参考链接
「博客园」JCF相关基础类接口/抽象类源码阅读
「博客园」J源码中transient的用途
「Java全栈知识体系」Collection - ArrayList 源码解析