1. 网站分析
想要的内容有标题、时间和帖子跳转链接
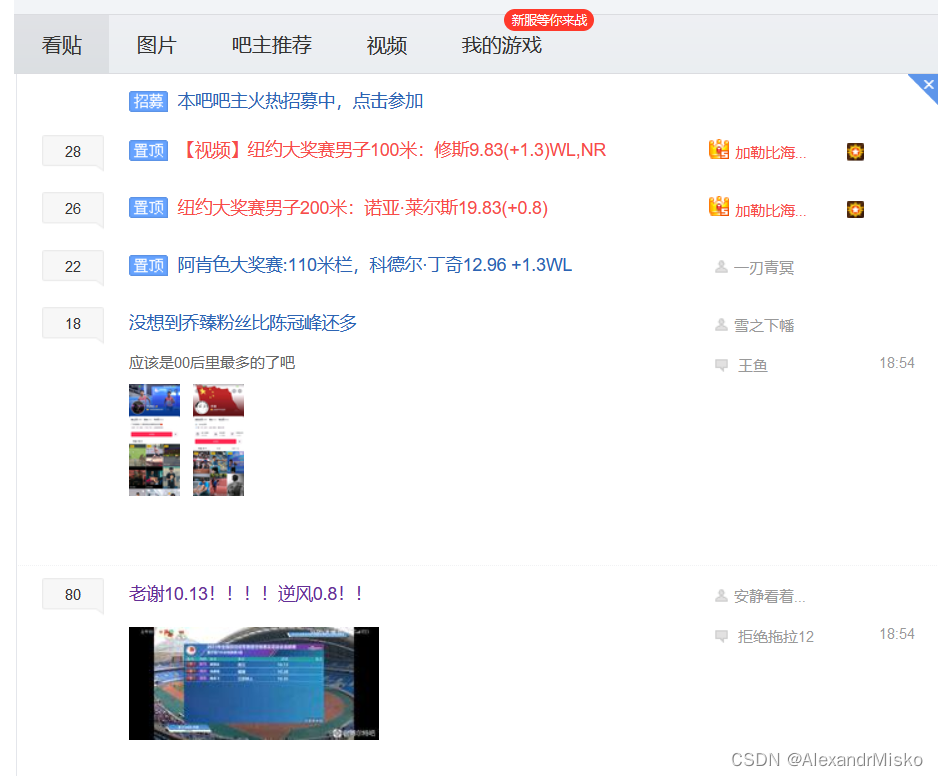
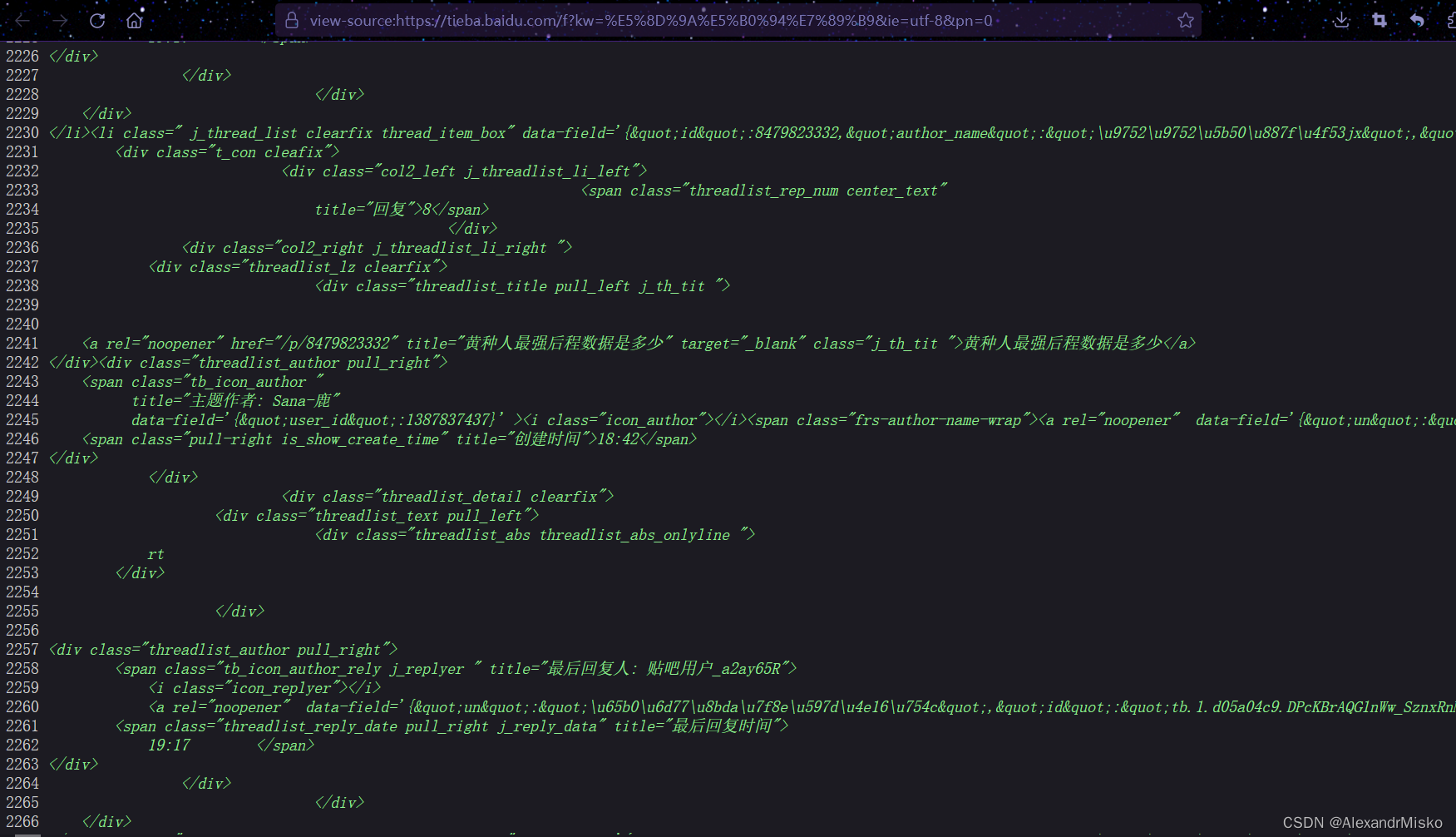
查看网站源代码,发现想要的内容就在里面,那就好办了,直接上正则,当然beautifulsoup也不是不可以
2. Python源码
import requests
import re
from prettytable import PrettyTableheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/114.0'
}
x = PrettyTable(["标题", "时间", "链接"])
x.align["标题"] = "l"
// 这里会整合三页内容,想要多少页,就把101改成50*(页数-1)+1
for i in range(0, 101, 50):resp = requests.get(f'https://tieba.baidu.com/f?kw=%E5%8D%9A%E5%B0%94%E7%89%B9&ie=utf-8&pn={i}', headers=headers)with open(file='1.html', mode='w', encoding='utf-8') as f:f.write(resp.text)obj = re.compile('<a rel="noopener" href="/p/(?P<url>.*?)" title="(?P<title>.*?)".*?<span class="pull-right is_show_create_time" title="创建时间">(?P<time>.*?)</span>', re.S)title = obj.finditer(resp.text)for i in title:x.add_row([i.group('title'), i.group('time'), 'https://tieba.baidu.com/p/' + i.group('url')])
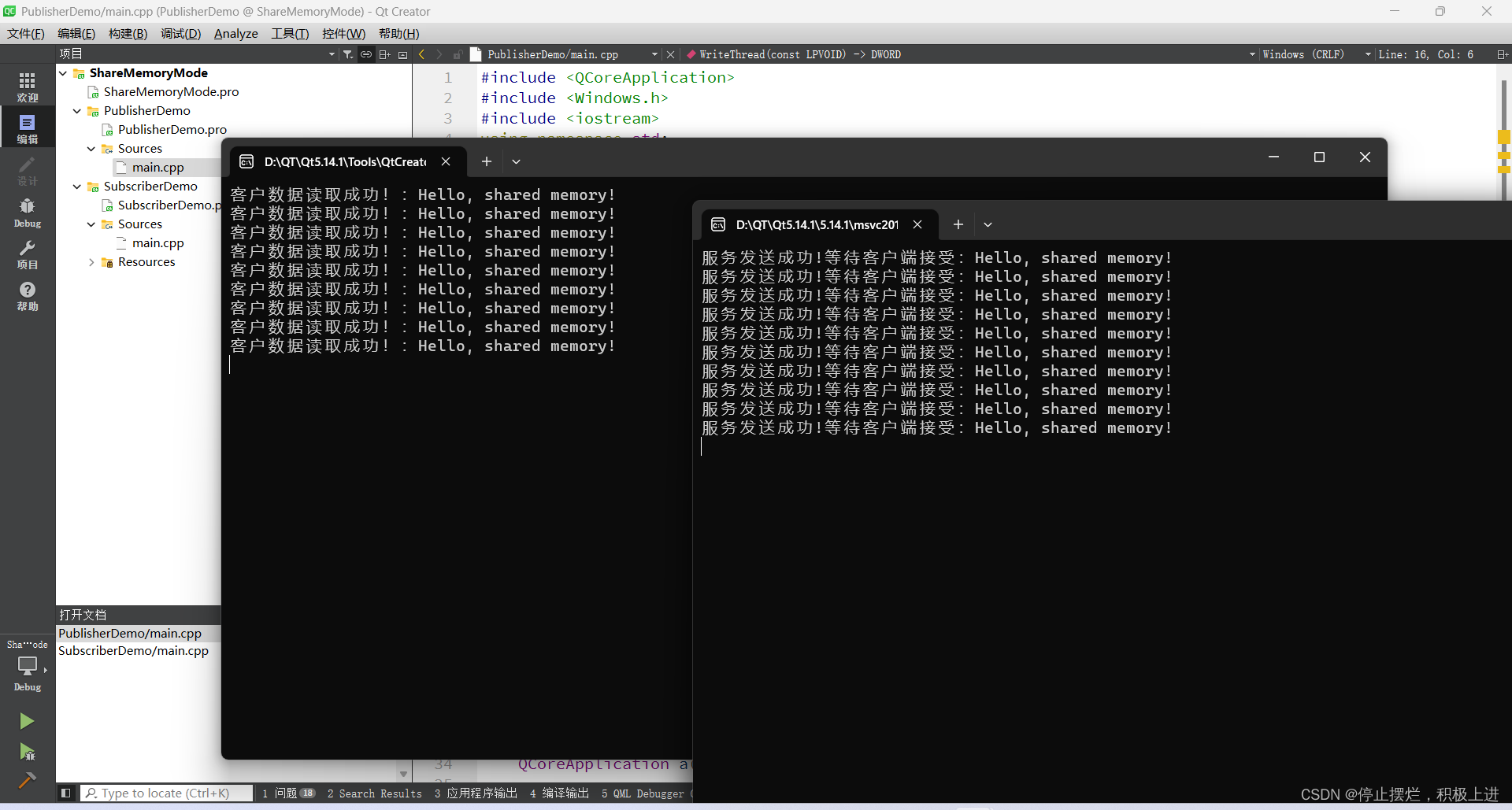
print(x)3. 效果展示
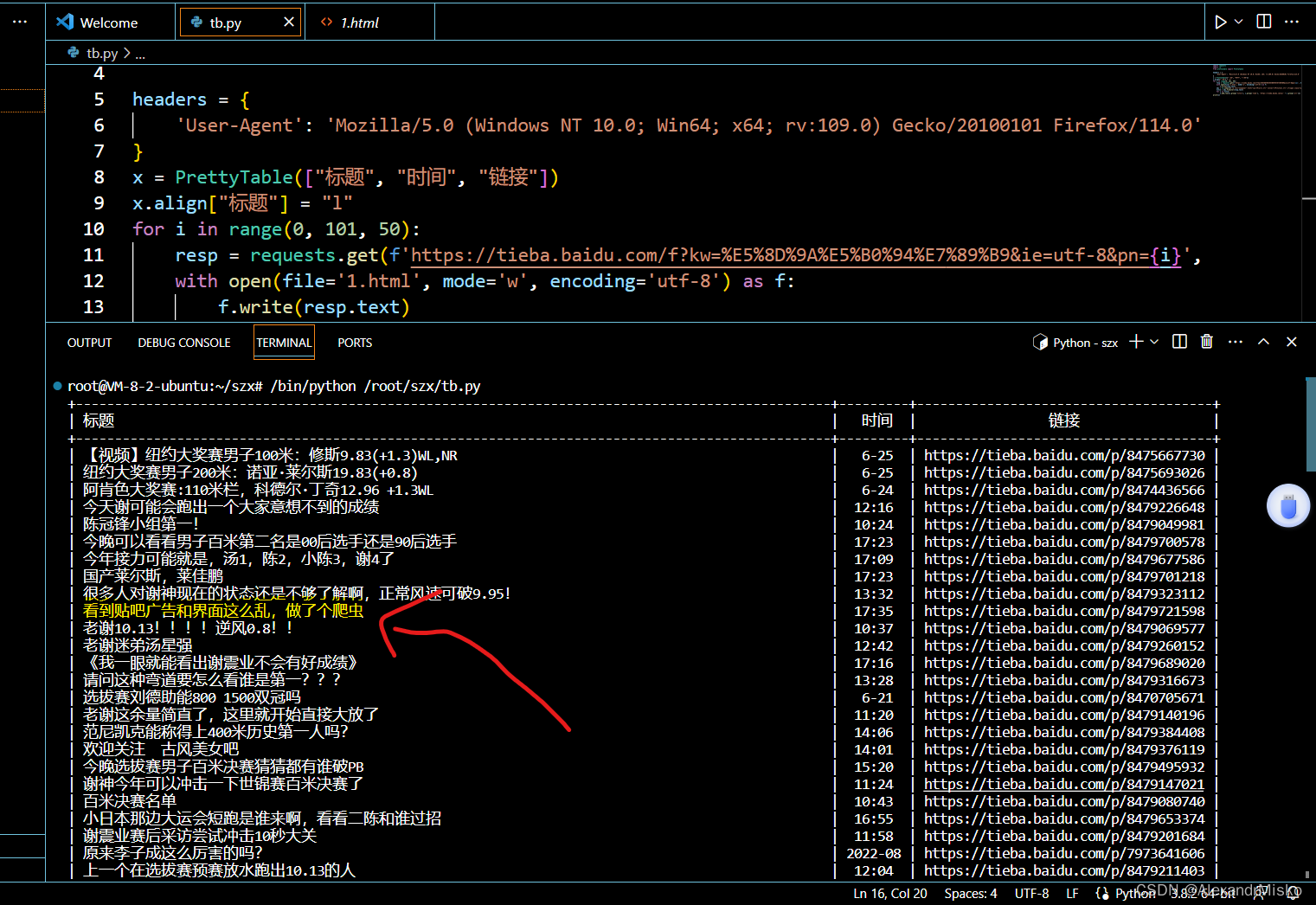
ps:好久没玩爬虫了,但是在网页版逛吧时看到很多广告让我很不爽,故写下此脚本。