前言
大家好,我是秋意零。
上一篇结束了 Pod 对象的内容。
今天要探讨的内容是 “控制器”,它是 Kubernetes 编排最核心的功能。理解了 “控制器”,你就能理解 Deployment、StatefulSet、DaemontSet、Job、CroJob 控制器对象。
最近搞了一个扣扣群,旨在技术交流、博客互助,希望各位大佬多多支持!
获取方式:
- 1.在我主页推广区域,如图:
- 2.文章底部推广区域,如图:

👿 简介
- 🏠 个人主页: 秋意零
- 🧑 个人介绍:在校期间参与众多云计算相关比赛,如:🌟 “省赛”、“国赛”,并斩获多项奖项荣誉证书
- 🎉 目前状况:24 届毕业生,拿到一家私有云(IAAS)公司 offer,暑假开始实习
- 🔥 账号:各个平台, 秋意零 账号创作者、 云社区 创建者
- 💕欢迎大家:欢迎大家一起学习云计算,走向年薪 30 万

系列文章目录
【云原生|探索 Kubernetes-1】容器的本质是进程
【云原生|探索 Kubernetes-2】容器 Linux Cgroups 限制
【云原生|探索 Kubernetes 系列 3】深入理解容器进程的文件系统
【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎
【云原生|探索 Kubernetes 系列 5】简化 Kubernetes 的部署,深入解析其工作流程
更多点击专栏查看:深入探索 Kubernetes
文章目录
- 前言
- 系列文章目录
- 一、控制器模型
- 二、控制循环
- 总结
正文开始:
- 快速上船,马上开始掌舵了(Kubernetes),距离开船还有 3s,2s,1s…

一、控制器模型
在 Kubernetes中,控制器模式是一种用于管理和维护资源对象的模式。控制器模式基于 Kubernetes 的声明式配置和自动化管理原则,通过监视资源对象的状态和变化,以及根据期望状态进行调谐和调整,实现对应用程序的自动化部署、扩展、修复和管理。
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
更形象说明就是,“容器镜像” 虽然好用,但是容器这样一个 “沙盒” 的概念,对应用描述关联性来说,还是太简单了。好比,码头的集装箱好用,但是它四面都是光秃秃的,吊车怎么把它这个集装箱吊起来摆放好呢?(这个摆放过程可以看作编排)
因为,一个容器通常是一个应用 APP,但是现实中基本上不存在一个 APP 就能提供所有服务,必然要使用一些辅助程序,如:Redis、RabbitMQ、MySQL等等中间件;所以,对比到 “一个容器” ,它是不能满足现实中的情况的,因为需要辅助程序,这种情况下 Kubernetes 使用了 Pod。
Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架 “吊车”,可以更轻松地操作它。
而 Kubernetes 操作这些 “集装箱“ 的逻辑,都是控制器(Controller)负责完成。
现在,我们看一个 Deployment 控制器的栗子:
- Deployment 通过
spec.selector.matchLabels携带了app=myapp标签与 Pod 绑定,这样 Deployment 就能控制于它具有相同标签的 Pod 了;通过spec.replicas指定 Pod 期望个数,Deployment 控制器会将 Pod 一直保持在 3 个,少了会创建,多了会删除。
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp-deploymentlabels:app: myapp
spec:replicas: 3 # 指定副本数量selector:matchLabels:app: myapp # 选择标签为`app: myapp`的Pod进行管理template:metadata:labels:app: myapp # Pod的标签spec:containers:- name: myapp-webimage: nginx # 指定应用程序的镜像imagePullPolicy: IfNotPresentports:- containerPort: 80 # 应用程序监听的端口号
验证
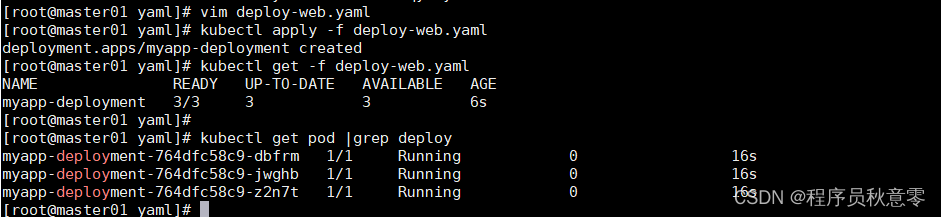
[root@master01 yaml]# kubectl apply -f deploy-web.yaml
deployment.apps/myapp-deployment created
[root@master01 yaml]# kubectl get -f deploy-web.yaml
NAME READY UP-TO-DATE AVAILABLE AGE
myapp-deployment 3/3 3 3 6s
[root@master01 yaml]#
[root@master01 yaml]# kubectl get pod |grep deploy
myapp-deployment-764dfc58c9-dbfrm 1/1 Running 0 16s
myapp-deployment-764dfc58c9-jwghb 1/1 Running 0 16s
myapp-deployment-764dfc58c9-z2n7t 1/1 Running 0 16s
二、控制循环
上述的控制操作,是 kube-controller-manager 组件负责的,而所有的控制器都在 kubernetes/pkg/controller 中,如图:
源码的 kubernetes/pkg/controller 目录下,保存的都是控制器。它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
Go 语言伪代码表示控制循环:
- 获取对象的两种状态的值,从而对两种状态的值做比较,等于什么都不做,不等于就让 Pod 保持到期望状态的个数。
for {实际状态个数 := 获取集群中对象X的实际状态(Actual State)期望状态个数 := 获取集群中对象X的期望状态(Desired State)if 实际状态个数 == 期望状态个数{什么都不做} else {执行编排动作,将实际状态调整为期望状态}
}
1.实际状态:
- 实际状态个数,就是 Kubernetes 集群中,真实运行的受 Deployment 控制器管理的 Pod 的个数。这个值可以通过 kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,来获取。
2.期望状态:
- 期望状态,来自于用户提交的 YAML 文件中的
spec.replicas字段的值。
现在,我们还是以 Deployment 为例,看看控制器实现过程:
- 1.Deployment 控制器从 Etcd 中获取所有携带 “app: myapp” 标签的 Pod,统计它们的数量,这就是实际状态个数。
- 2.获取 Deployment 对象的
spec.replicas字段的值,这就是期望状态个数。 - 3.Deployment 控制器将这两个状态的值做比较,根据是否相等来判断实际状态个数是否达到期望状态的个数,如果没有就判断是增加 Pod 还是删减 Pod。
可以看到,一个 Kubernetes 对象的主要编排逻辑,实际上是在第三步的 “对比” 阶段完成的。
这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。它们其实指的都是同一个东西:控制循环。
被这个循环控制的部分,是 Deployment 中的 spec.template 字段,template 字段这个在 Deployment 中是 PodTemplate(Pod 模板)。如下图所示,类似 Deployment 这样的一个控制器,实际上都是由上半部分的控制器定义(包括期望状态),加上下半部分的被控制对象的模板组成的。
下图中,Deployment (nginx-deployment)是直接控制 Pod(nginx)的吗?其实不是 Deployment 直接控制 ReplicaSet,ReplicaSet 再次控制 Pod 对象。

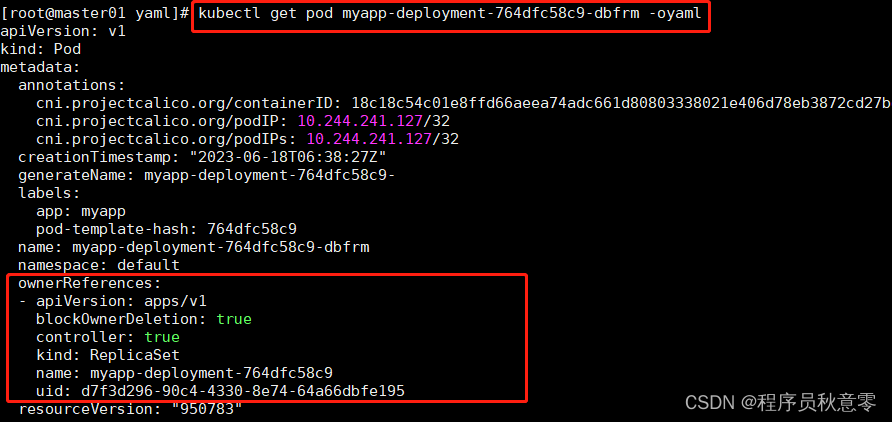
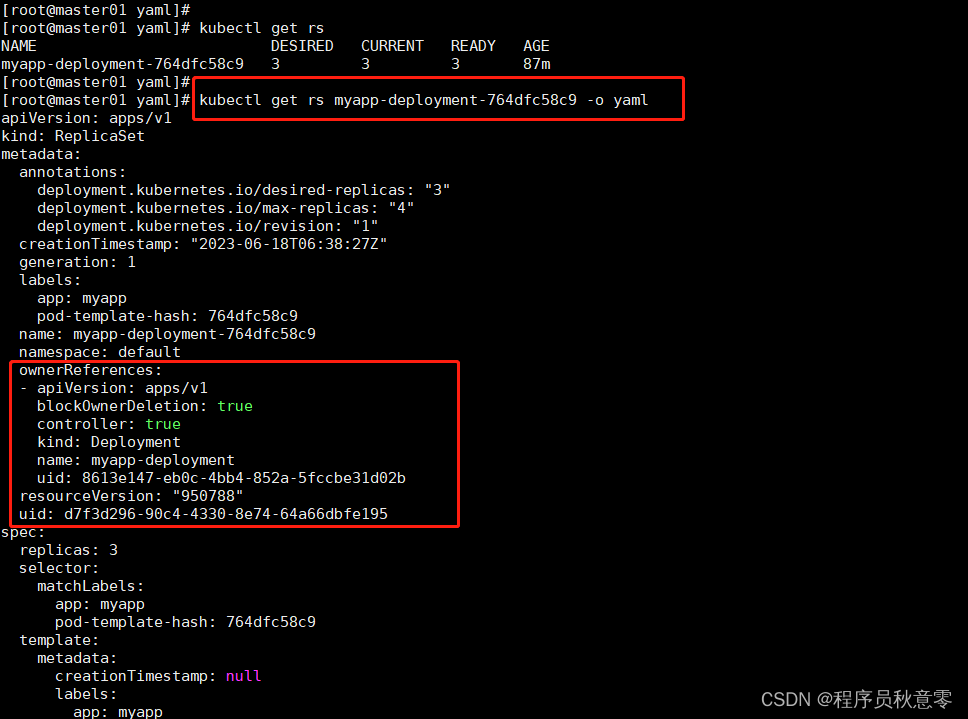
通过这种被谁是谁的控制对象的概念,其实是通过 API 对象的 Metadata 里,都有一个字段叫作 ownerReference, 用于保存拥有者 API 对象(Owner)的信息来分辨的。
- 图中,我们查看了,通过 Deployment 控制器所创建的 Pod 的信息,可以看到框出的部分 ownerReference 的 API 对象是 ReplicaSet。
- 我们再来验证查看 RplicaSet 的 ownerReference 是不是 Deployment,如图:
总结
今天,说明了 ”控制器模式“ 的方法。
如:Deployment 它的控制循环是如何工作的,这个部分我们介绍了一个 Go 语言的伪代码。
接着,简单介绍了,Kubernetes 是如何来区分谁是谁的控制对象的,答案是:使用 ownerReference 用于保存拥有者 API 对象(Owner)的信息来分辨的。
最后:技术交流、博客互助,点击下方或主页推广加入哦!!