本文接kafka三,代码实践kafkaStream的应用,用来完成流式计算。
kafkastream
关于流式计算也就是实时处理,无时间概念边界的处理一些数据。想要更有性价比地和java程序进行结合,因此了解了kafka。但是本人阅读了kafka地官网,觉得可阅读性并不是很高,当然是个人认为,就是界面做的就不是很舒服。
简介
简介一下kafkaStream
Kafka Stream的特点
-
Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
-
除了Kafka外,无任何外部依赖
-
充分利用Kafka分区机制实现水平扩展和顺序性保证(想要保证消息有序性就要设置一个分区)
-
通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
-
支持正好一次处理语义
-
提供记录级的处理能力,从而实现毫秒级的低延迟
-
支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
-
同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
关键概念
-
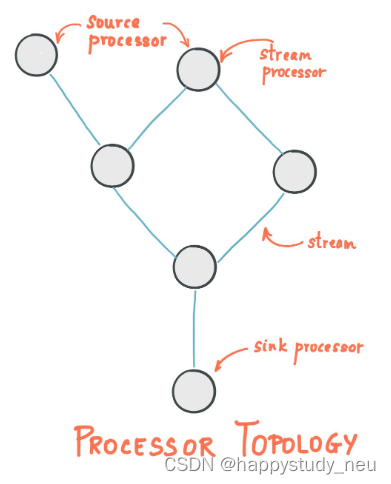
源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
-
Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
Kstream
(1)数据结构类似于map,key-value键值对
KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。 数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
为了说明这一点,让我们想象一下以下两个数据记录正在发送到流中:
(“ alice”,1)->(“” alice“,3)
如果流处理应用是要总结每个用户的价值,它将返回alice,4。因为第二条数据记录不会覆盖第一条,而是做了一个insert,累加。
代码实现
依赖
<!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId><exclusions><exclusion><artifactId>connect-json</artifactId><groupId>org.apache.kafka</groupId></exclusion><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency>
kafkaStream配置类
需要在nacos的配置里面配置hosts属性和group,本地等怎么配置都可以,只要能读取到就行。
/*** 通过重新注册KafkaStreamsConfiguration对象,设置自定配置参数*/@Setter
@Getter
@Configuration
@EnableKafkaStreams
@ConfigurationProperties(prefix="kafka")
public class KafkaStreamConfig {private static final int MAX_MESSAGE_SIZE = 16* 1024 * 1024;private String hosts;private String group;@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {Map<String, Object> props = new HashMap<>();props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);props.put(StreamsConfig.APPLICATION_ID_CONFIG, this.getGroup()+"_stream_aid");props.put(StreamsConfig.CLIENT_ID_CONFIG, this.getGroup()+"_stream_cid");props.put(StreamsConfig.RETRIES_CONFIG, 10);props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());return new KafkaStreamsConfiguration(props);}
}这里生产者和消费者我就不再举例子了,直接举中间这个stream怎么写。
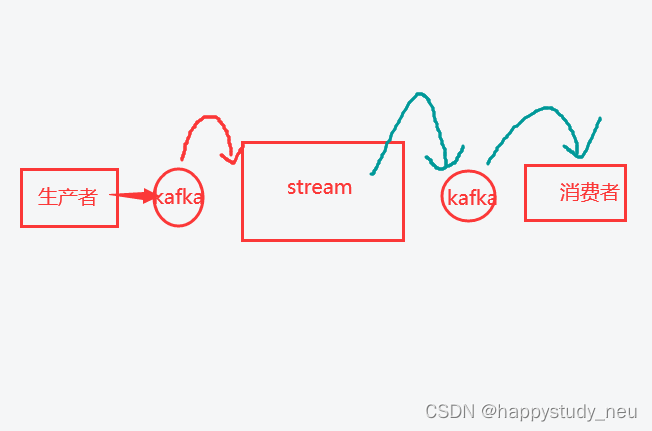
stream需要知道是谁发的,所以生产者和stream需要绑定一个相同的主题,而stream需要知道要给谁发送过去,消费者知道是谁发的,所以stream和消费者又有一个相同的主题。
streamhandler代码
具体的每一行代码的含义结合个人理解都在注释里面。
package com.neu.article.stream;import com.alibaba.fastjson.JSON;import com.neu.base.constants.HotArticleConstants;
import com.neu.base.model.mess.ArticleVisitStreamMess;
import com.neu.base.model.mess.UpdateArticleMess;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.time.Duration;@Configuration
@Slf4j
public class HotArticleStreamHandler {@Beanpublic KStream<String,String> kStream(StreamsBuilder streamsBuilder){//接收消息KStream<String,String> stream = streamsBuilder.stream(HotArticleConstants.HOT_ARTICLE_SCORE_TOPIC);//聚合流式处理stream.map((key,value)->{UpdateArticleMess mess = JSON.parseObject(value, UpdateArticleMess.class);//重置消息的key:1234343434(文章id) 和 value: likes:1 当前文章点赞一次//mess.getType().name():用于区分是点赞还是阅读 mess.getAdd():用于区分是加1还是减1return new KeyValue<>(mess.getArticleId().toString(),mess.getType().name()+":"+mess.getAdd());})//按照文章id进行聚合.groupBy((key,value)->key)//时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))/*** 自行的完成聚合的计算*/.aggregate(new Initializer<String>() {/*** 初始方法,返回值是消息的value->aggValue,聚合之后的value* @return*/@Overridepublic String apply() {return "COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0";}/*** 真正的聚合操作,返回值是消息的value*/}, new Aggregator<String, String, String>() {/**** @param key 消息的key :mess.getArticleId().toString()* @param value 消息的value likes:1* @param aggValue 初始化消息聚合后的一个值 COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0* @return*/@Overridepublic String apply(String key, String value, String aggValue) {System.out.println(value);if(StringUtils.isBlank(value)){return aggValue;}String[] aggAry = aggValue.split(",");int col = 0,com=0,lik=0,vie=0;for (String agg : aggAry) {//agg遍历第一次的时候最开始为 COLLECTION:0String[] split = agg.split(":");//split[0] = COLLECTION split[1] = 0/*** 获得初始值,也是时间窗口内计算之后的值*/switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:col = Integer.parseInt(split[1]);break;case COMMENT:com = Integer.parseInt(split[1]);break;case LIKES:lik = Integer.parseInt(split[1]);break;case VIEWS:vie = Integer.parseInt(split[1]);break;}}/*** 累加操作 likes:1*/String[] valAry = value.split(":");//valAry[0] = likes valAry[1] = 1switch (UpdateArticleMess.UpdateArticleType.valueOf(valAry[0])){case COLLECTION:col += Integer.parseInt(valAry[1]);break;case COMMENT:com += Integer.parseInt(valAry[1]);break;case LIKES:lik += Integer.parseInt(valAry[1]);break;case VIEWS:vie += Integer.parseInt(valAry[1]);break;}//返回值是有要求的,必须与初始化apply方法的返回值形式一致String formatStr = String.format("COLLECTION:%d,COMMENT:%d,LIKES:%d,VIEWS:%d", col, com, lik, vie);System.out.println("文章的id:"+key);System.out.println("当前时间窗口内的消息处理结果:"+formatStr);return formatStr;}//Materialized.as("hot-atricle-stream-count-001"):用于指定六十处理的状态,字符串可以随便给,多个流处理的话不重复就行}, Materialized.as("hot-atricle-stream-count-001")).toStream().map((key,value)->{//key.key().toString():文章id,value:COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0return new KeyValue<>(key.key().toString(),formatObj(key.key().toString(),value));})//发送消息.to(HotArticleConstants.HOT_ARTICLE_INCR_HANDLE_TOPIC);return stream;}/*** 格式化消息的value数据* @param articleId* @param value* @return*/public String formatObj(String articleId,String value){ArticleVisitStreamMess mess = new ArticleVisitStreamMess();mess.setArticleId(Long.valueOf(articleId));//COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0String[] valAry = value.split(",");for (String val : valAry) {String[] split = val.split(":");switch (UpdateArticleMess.UpdateArticleType.valueOf(split[0])){case COLLECTION:mess.setCollect(Integer.parseInt(split[1]));break;case COMMENT:mess.setComment(Integer.parseInt(split[1]));break;case LIKES:mess.setLike(Integer.parseInt(split[1]));break;case VIEWS:mess.setView(Integer.parseInt(split[1]));break;}}log.info("聚合消息处理之后的结果为:{}",JSON.toJSONString(mess));return JSON.toJSONString(mess);}
}